






声明
菜鸟一个,为了完成作业故写下这篇blog,如果有错误的地方希望大佬们在评论区平和的指出,如果感觉这篇文章有帮助,希望能点点赞和收藏 ^_^
前言
什么是waf
waf是什么可以看这篇文章:WAF是什么?一篇文章带你全面了解WAF
总结就是一个防火墙可以阻拦掉绝大部分非法的访问,例如XSS攻击和SQL注入攻击都会通过发送一些不合法的请求来实现一些非法的攻击
IdentYwaf是什么
用python开发的用于识别waf的工具,其竞品主要有wafw00f,sqlmap以及nmap
IdentYwaf的github地址:https://github.com/stamparm/identYwaf.git
IdentYwaf源码分析
IdentYwaf实现流程
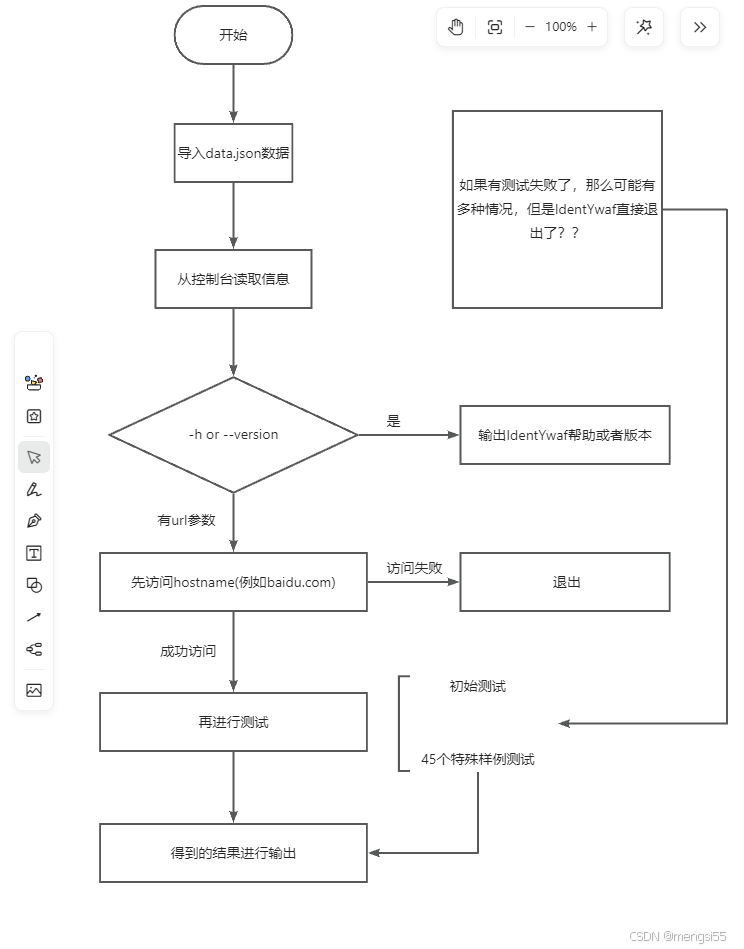
2024.11.22更新新的identYwaf流程图,之前的太简陋了(就不删了,留作纪念吧),这里更新一个新的流程图,详细一点
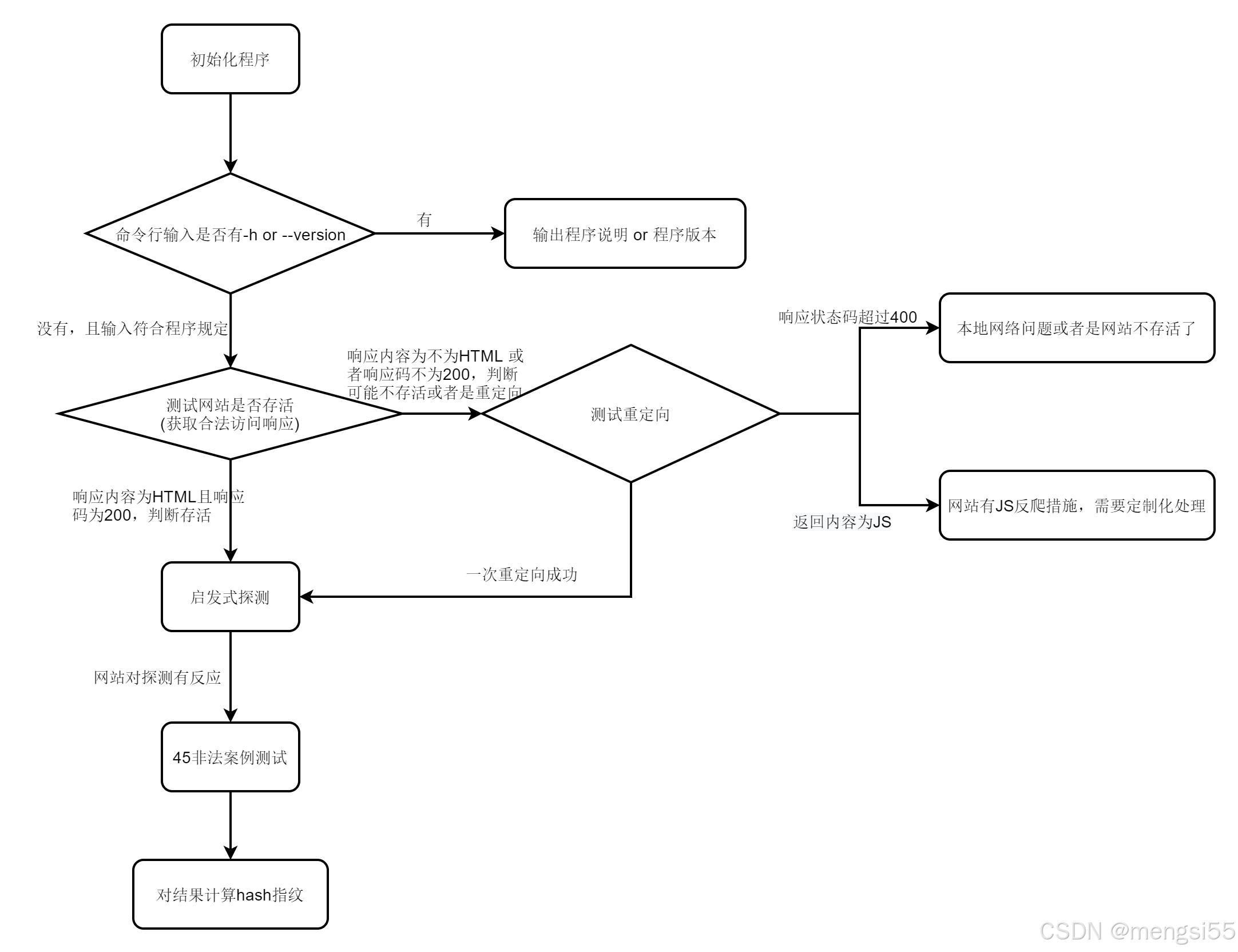
IdentYwaf文件目录
│
└─identYwaf-master
│ .travis.yml
│ data.json★
│ identYwaf.py★★
│ LICENSE
│ README.md
└─screenshots
IdentYwaf核心流程分析
data.json是关于各个WAF的指纹记录,还有关于测试payload的记录
{
"__copyright__": "Copyright (c) 2019-2021 Miroslav Stampar (@stamparm), MIT. See the file 'LICENSE' for copying permission",
"__notice__": "The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software",
"payloads": [
"HTML::<img>",
"SQLi::1 AND 1",
...
"XSS::<img src=x onerror=alert('XSS')>",
"XSS::<img onfoo=f()>",
"XSS::<script>",
"XSS::<script>alert('XSS')</script>",
...
"LDAPi::admin*)((|userpassword=*)",
"LDAPi::user=*)(uid=*))(|(uid=*",
...
"NOSQLi::true, $where: '1 == 1'",
...
],
"wafs": {
"360": {
"company": "360",
"name": "360",
"regex": "<title>493</title>|/wzws-waf-cgi/",
"signatures": [
"9778:RVZXum61OEhCWapBYKcPk4JzWOpohM4JiUcMr2RXg1uQJbX3uhdOnthtOj+hX7AB16FcPxJPdLsXo2tKaK99n+i7c4VmkwI3FZjxtDtAeq+c36A5chW1XaTC",
"9ccc:RVZXum61OEhCWapBYKcPk4JzWOpohM4JiUcMr2RXg1uQJbX3uhdOnthtOj+hX7AB16FcPxJPdLsXo2tKaK99n+i7c4VmkwI3FZjxtDtAeq+c36A4chW1XaTC"
]
},
...
....
}
}
identYwaf.py就是IdentYwaf工具的核心
主函数
def main():
if "--version" not in sys.argv:
print(BANNER)
parse_args()
init()
run()
load_data()
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
exit(colorize("\r[x] Ctrl-C pressed"))
显然首先是load_data()
再parse_args
再init()
再run()
load_data()
其中load_data()就是为全局变量
SIGNATURES = {}
DATA_JSON = {}
WAF_RECOGNITION_REGEX
赋值,
def load_data():
global WAF_RECOGNITION_REGEX
if os.path.isfile(DATA_JSON_FILE):
with codecs.open(DATA_JSON_FILE, "rb", encoding="utf8") as f:
DATA_JSON.update(json.load(f))
WAF_RECOGNITION_REGEX = ""
for waf in DATA_JSON["wafs"]:
if DATA_JSON["wafs"][waf]["regex"]:
WAF_RECOGNITION_REGEX += "%s|" % ("(?P<waf_%s>%s)" % (waf, DATA_JSON["wafs"][waf]["regex"]))
for signature in DATA_JSON["wafs"][waf]["signatures"]:
SIGNATURES[signature] = waf
WAF_RECOGNITION_REGEX = WAF_RECOGNITION_REGEX.strip('|')
flags = "".join(set(_ for _ in "".join(re.findall(r"\(\?(\w+)\)", WAF_RECOGNITION_REGEX))))
WAF_RECOGNITION_REGEX = "(?%s)%s" % (flags, re.sub(r"\(\?\w+\)", "", WAF_RECOGNITION_REGEX)) # patch for "DeprecationWarning: Flags not at the start of the expression" in Python3.7
else:
exit(colorize("[x] file '%s' is missing" % DATA_JSON_FILE))
其中SIGNATURES用来存每个WAF在data.json文件中记录的哈希值(这个哈希值后面我会提到怎么计算的,它有一个calc_hash函数来计算这个), DATA_JSON显然是把整个data.json存了进去,WAF_RECOGNITION_REGEX则是存了每个WAF对应的正则表达式。WAF_RECOGNITION_REGEX和SIGNATURES是后面用来识别WAF用的
parse_args()
def parse_args():
global options
parser = optparse.OptionParser(version=VERSION)
parser.add_option("--delay", dest="delay", type=int, help="Delay (sec) between tests (default: 0)")
parser.add_option("--timeout", dest="timeout", type=int, help="Response timeout (sec) (default: 10)")
parser.add_option("--proxy", dest="proxy", help="HTTP proxy address (e.g. \"http://127.0.0.1:8080\")")
parser.add_option("--proxy-file", dest="proxy_file", help="Load (rotating) HTTP(s) proxy list from a file")
parser.add_option("--random-agent", dest="random_agent", action="store_true", help="Use random HTTP User-Agent header value")
parser.add_option("--code", dest="code", type=int, help="Expected HTTP code in rejected responses")
parser.add_option("--string", dest="string", help="Expected string in rejected responses")
parser.add_option("--post", dest="post", action="store_true", help="Use POST body for sending payloads")
parser.add_option("--debug", dest="debug", action="store_true", help=optparse.SUPPRESS_HELP)
parser.add_option("--fast", dest="fast", action="store_true", help=optparse.SUPPRESS_HELP)
parser.add_option("--lock", dest="lock", action="store_true", help=optparse.SUPPRESS_HELP)
# Dirty hack(s) for help message
def _(self, *args):
retval = parser.formatter._format_option_strings(*args)
if len(retval) > MAX_HELP_OPTION_LENGTH:
retval = ("%%.%ds.." % (MAX_HELP_OPTION_LENGTH - parser.formatter.indent_increment)) % retval
return retval
parser.usage = "python %s <host|url>" % parser.usage
parser.formatter._format_option_strings = parser.formatter.format_option_strings
parser.formatter.format_option_strings = type(parser.formatter.format_option_strings)(_, parser)
for _ in ("-h", "--version"):
option = parser.get_option(_)
option.help = option.help.capitalize()
try:
# 获取所有options 以及 参数列表
# 为了方便我们调试,我们把这个先写死
# Input = ['baidu.com']
options, _ = parser.parse_args()
# {'delay': None, 'timeout': None, 'proxy': None, 'proxy_file': None, 'random_agent': None, 'code': None, 'string': None, 'post': None, 'debug': None, 'fast': None, 'lock': None}
# ['baidu.com']
print(options, _)
except SystemExit:
raise
# 因为我们不再从控制台输入扫描网址,所以这里我们得手动给它加上这个网址
# sys.argv += ['baidu.com']
if len(sys.argv) > 1:
url = sys.argv[-1]
if not url.startswith("http"):
url = "http://%s" % url
options.url = url
else:
parser.print_help()
raise SystemExit
for key in DEFAULTS:
if getattr(options, key, None) is None:
setattr(options, key, DEFAULTS[key])
# print(type(options), options)
这个函数就是读入我们从控制台的参数,但是比较恶心的是,下面是它的-h
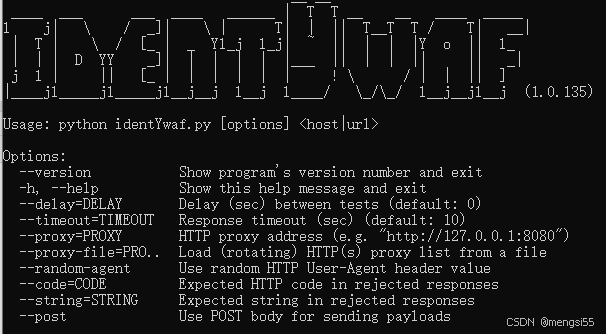
我们可以看到,在代码中有的一些参数在-h中是没有的,点名fast参数以及lock参数,所以我其实也不太知道这个fast还有lock是做什么的,这两玩意我就不分析了,哈哈
在parse_args函数中,它主要干了以下几个操作:
- 读入参数
- 处理url,如果输入的url没有添加https://或者http://,~~默认给https://~~默认给http://
- 把参数赋值给全局变量options
init()
def init():
os.chdir(os.path.abspath(os.path.dirname(__file__)))
# Reference: http://blog.mathieu-leplatre.info/python-utf-8-print-fails-when-redirecting-stdout.html
if not PY3 and not IS_TTY:
sys.stdout = codecs.getwriter(locale.getpreferredencoding())(sys.stdout)
print(colorize("[o] initializing handlers..."))
# Reference: https://stackoverflow.com/a/28052583
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
if options.proxy_file:
if os.path.isfile(options.proxy_file):
print(colorize("[o] loading proxy list..."))
with codecs.open(options.proxy_file, "rb", encoding="utf8") as f:
proxies.extend(re.sub(r"\s.*", "", _.strip()) for _ in f.read().strip().split('\n') if _.startswith("http"))
random.shuffle(proxies)
else:
exit(colorize("[x] file '%s' does not exist" % options.proxy_file))
cookie_jar = CookieJar()
opener = build_opener(HTTPCookieProcessor(cookie_jar))
install_opener(opener)
if options.proxy:
opener = build_opener(ProxyHandler({"http": options.proxy, "https": options.proxy}))
install_opener(opener)
if options.random_agent:
revision = random.randint(20, 64)
platform = random.sample(("X11; %s %s" % (random.sample(("Linux", "Ubuntu; Linux", "U; Linux", "U; OpenBSD", "U; FreeBSD"), 1)[0], random.sample(("amd64", "i586", "i686", "amd64"), 1)[0]), "Windows NT %s%s" % (random.sample(("5.0", "5.1", "5.2", "6.0", "6.1", "6.2", "6.3", "10.0"), 1)[0], random.sample(("", "; Win64", "; WOW64"), 1)[0]), "Macintosh; Intel Mac OS X 10.%s" % random.randint(1, 11)), 1)[0]
user_agent = "Mozilla/5.0 (%s; rv:%d.0) Gecko/20100101 Firefox/%d.0" % (platform, revision, revision)
HEADERS["User-Agent"] = user_agent
colorize函数不重要,就一上色的,后面也不会分析它
这个函数主要干了三件事:
- 如果我们选择读入代理文件配置代理池或者直接配置代理,就读入代理文件配置号代理池
- cookie_jar = CookieJar()及下面两行是cookie自动更新,也就是说访问那些set-cookie改变cookie值我们都不用管了,例如session会话维持这个就很重要,不过如果是通过JS来处理cookie的网站这个就废了,所以IdentYwaf第一个雷点就是这里!!
- 然后就是伪随机user-agent,我们控制台希望随机user-agent,它直接在init()这里固定了一个user-agent,也就是说我们发包的agent和默认agent不同,但是后续发包将一直是这个agent,我还以为是每次发包都会有一个新的user-agent(毕竟后面会有一个45案例测试,它们将使用同一个agent,被检测然后不回复或者回复不是html的可能性太高了,第二个雷点!!)
run()是最重要的部分
run函数这部分我们将重点关注两个函数:retrieve()和check_payload()函数,并简单介绍一下calc_hash函数
最后我将介绍整个run函数的流程
retrieve()
def retrieve(url, data=None):
global proxies_index
retval = {}
if proxies:
while True:
try:
opener = build_opener(ProxyHandler({"http": proxies[proxies_index], "https": proxies[proxies_index]}))
install_opener(opener)
proxies_index = (proxies_index + 1) % len(proxies)
urlopen(PROXY_TESTING_PAGE).read()
except KeyboardInterrupt:
raise
except:
pass
else:
break
try:
req = Request("".join(url[_].replace(' ', "%20") if _ > url.find('?') else url[_] for _ in xrange(len(url))), data, HEADERS)
# 这里如果没有获取到内容就会进入except里面
resp = urlopen(req, timeout=options.timeout)
# 顺利获取到内容就往下面执行
# retval存储有:URL、HTML文本、HTTP响应状态码、HTML请求RAW型式
retval[URL] = resp.url
retval[HTML] = resp.read()
retval[HTTPCODE] = resp.code
retval[RAW] = "%s %d %s\n%s\n%s" % (httplib.HTTPConnection._http_vsn_str, retval[HTTPCODE], resp.msg, str(resp.headers), retval[HTML])
except Exception as ex:
# 请求超时或者直接就是请求失败
# 尝试给retval存储:URL(从报错内容中获取url)、HTTP响应状态码,表示请求的结果(例如,200表示成功,404表示未找到)(从报错内容中获取)、尝试获取HTML内容(如果报错内容可以直接read那么就直接read,不能就看有没有返回msg内容,这些都失败了即获取HTML内容失败了,那么就置HTML内容为空)
retval[URL] = getattr(ex, "url", url)
retval[HTTPCODE] = getattr(ex, "code", None)
try:
retval[HTML] = ex.read() if hasattr(ex, "read") else getattr(ex, "msg", str(ex))
except:
retval[HTML] = ""
retval[RAW] = "%s %s %s\n%s\n%s" % (httplib.HTTPConnection._http_vsn_str, retval[HTTPCODE] or "", getattr(ex, "msg", ""), str(ex.headers) if hasattr(ex, "headers") else "", retval[HTML])
for encoding in re.findall(r"charset=[\s\"']?([\w-]+)", retval[RAW])[::-1] + ["utf8"]:
encoding = ENCODING_TRANSLATIONS.get(encoding, encoding)
try:
retval[HTML] = retval[HTML].decode(encoding, errors="replace")
break
except:
pass
match = re.search(r"<title>\s*(?P<result>[^<]+?)\s*</title>", retval[HTML], re.I)
retval[TITLE] = match.group("result") if match and "result" in match.groupdict() else None
retval[TEXT] = re.sub(r"(?si)<script.+?</script>|<!--.+?-->|<style.+?</style>|<[^>]+>|\s+", " ", retval[HTML])
match = re.search(r"(?im)^Server: (.+)", retval[RAW])
retval[SERVER] = match.group(1).strip() if match else ""
return retval
retval是用来存储访问返回的包的信息的,这些信息主要有:
- URL:
○ 键:URL(注意:在您的代码中,URL应该被引号括起来,即’URL’)
○ 值:最终请求的URL,可能是经过重定向后的URL。- HTML:
○ 键:HTML(同样,应该使用’HTML’)
○ 值:从服务器返回的HTML内容。在异常情况下,它可能是异常消息或尝试从异常对象中读取的内容(如果可用)。此外,代码还尝试根据响应内容中的字符集编码对HTML内容进行解码。- HTTPCODE:
○ 键:HTTPCODE(应为’HTTPCODE’)
○ 值:HTTP响应状态码,表示请求的结果(例如,200表示成功,404表示未找到)。- RAW:
○ 键:RAW(应为’RAW’)
○ 值:一个包含HTTP版本、状态码、响应消息、头部信息和HTML内容的字符串,格式类似于HTTP响应的原始格式。这对于调试和日志记录非常有用。- TITLE:
○ 键:TITLE(应为’TITLE’)
○ 值:从HTML内容中提取的页面标题(标签中的内容)。如果找不到标题,则为None。 - TEXT:
○ 键:TEXT(应为’TEXT’)
○ 值:HTML内容中的文本部分,去除了所有HTML标签、脚本、样式和注释。这对于文本分析很有用。- Server:
○ 键:SERVER(应为’SERVER’)
○ 值:从HTTP响应头部中提取的服务器信息(Server:字段的内容)。如果找不到服务器信息,则为空字符串。
retrieve函数第一部分就是实现代理,然后就会进行请求访问,然后把访问的内容进行处理存储到retval,且处理了访问失败的情况。
这里雷点太多了,这一部分整一个就是处理HTML的操作,虽然处理的很好,但是现在访问网站如果不带正确的cookie很多都是返回一个js文件让我们处理出cookie才能获取到正确的html,IdentYwaf有一步正常访问的操作,很多时候正常访问失败后面run函数就会非常干脆的exit(),真的无力吐槽(不过老东西了,干不过现在的情况也算正常)
check_payload()
def check_payload(payload, protection_regex=GENERIC_PROTECTION_REGEX % '|'.join(GENERIC_PROTECTION_KEYWORDS)):
global chained
global heuristic
global intrusive
global locked_code
global locked_regex
time.sleep(options.delay or 0)
if options.post:
_ = "%s=%s" % ("".join(random.sample(string.ascii_letters, 3)), quote(payload))
intrusive = retrieve(options.url, _)
else:
_ = "%s%s%s=%s" % (options.url, '?' if '?' not in options.url else '&', "".join(random.sample(string.ascii_letters, 3)), quote(payload))
intrusive = retrieve(_)
if options.lock and not payload.isdigit():
if payload == HEURISTIC_PAYLOAD:
match = re.search(re.sub(r"Server:|Protected by", "".join(random.sample(string.ascii_letters, 6)), WAF_RECOGNITION_REGEX, flags=re.I), intrusive[RAW] or "")
if match:
result = True
for _ in match.groupdict():
if match.group(_):
waf = re.sub(r"\Awaf_", "", _)
locked_regex = DATA_JSON["wafs"][waf]["regex"]
locked_code = intrusive[HTTPCODE]
break
else:
result = False
if not result:
exit(colorize("[x] can't lock results to a non-blind match"))
else:
result = re.search(locked_regex, intrusive[RAW]) is not None and locked_code == intrusive[HTTPCODE]
elif options.string:
result = options.string in (intrusive[RAW] or "")
elif options.code:
result = options.code == intrusive[HTTPCODE]
else:
result = intrusive[HTTPCODE] != original[HTTPCODE] or (intrusive[HTTPCODE] != 200 and intrusive[TITLE] != original[TITLE]) or (re.search(protection_regex, intrusive[HTML]) is not None and re.search(protection_regex, original[HTML]) is None) or (difflib.SequenceMatcher(a=original[HTML] or "", b=intrusive[HTML] or "").quick_ratio() < QUICK_RATIO_THRESHOLD)
if not payload.isdigit():
if result:
if options.debug:
print("\r---%s" % (40 * ' '))
print(payload)
print(intrusive[HTTPCODE], intrusive[RAW])
print("---")
if intrusive[SERVER]:
servers.add(re.sub(r"\s*\(.+\)\Z", "", intrusive[SERVER]))
if len(servers) > 1:
chained = True
single_print(colorize("[!] multiple (reactive) rejection HTTP 'Server' headers detected (%s)" % ', '.join("'%s'" % _ for _ in sorted(servers))))
if intrusive[HTTPCODE]:
codes.add(intrusive[HTTPCODE])
if len(codes) > 1:
chained = True
single_print(colorize("[!] multiple (reactive) rejection HTTP codes detected (%s)" % ', '.join("%s" % _ for _ in sorted(codes))))
if heuristic and heuristic[HTML] and intrusive[HTML] and difflib.SequenceMatcher(a=heuristic[HTML] or "", b=intrusive[HTML] or "").quick_ratio() < QUICK_RATIO_THRESHOLD:
chained = True
single_print(colorize("[!] multiple (reactive) rejection HTML responses detected"))
if payload == HEURISTIC_PAYLOAD:
heuristic = intrusive
return result
这个函数就是测试非法访问的主力,非常非常重要!!
intrusive在这里就是存储retrieve函数获取的非法访问结果的,自然,它也是基于HTML的
然后下面这部分就是判断是否存在WAF的代码:
if options.lock and not payload.isdigit():
if payload == HEURISTIC_PAYLOAD:
match = re.search(re.sub(r"Server:|Protected by", "".join(random.sample(string.ascii_letters, 6)), WAF_RECOGNITION_REGEX, flags=re.I), intrusive[RAW] or "")
if match:
result = True
for _ in match.groupdict():
if match.group(_):
waf = re.sub(r"\Awaf_", "", _)
locked_regex = DATA_JSON["wafs"][waf]["regex"]
locked_code = intrusive[HTTPCODE]
break
else:
result = False
if not result:
exit(colorize("[x] can't lock results to a non-blind match"))
else:
result = re.search(locked_regex, intrusive[RAW]) is not None and locked_code == intrusive[HTTPCODE]
elif options.string:
result = options.string in (intrusive[RAW] or "")
elif options.code:
result = options.code == intrusive[HTTPCODE]
else:
result = intrusive[HTTPCODE] != original[HTTPCODE] or (intrusive[HTTPCODE] != 200 and intrusive[TITLE] != original[TITLE]) or (re.search(protection_regex, intrusive[HTML]) is not None and re.search(protection_regex, original[HTML]) is None) or (difflib.SequenceMatcher(a=original[HTML] or "", b=intrusive[HTML] or "").quick_ratio() < QUICK_RATIO_THRESHOLD)
重点在最下面的这段代码(前面的分支正常都不会进去)
result = intrusive[HTTPCODE] != original[HTTPCODE] or
(intrusive[HTTPCODE] != 200 and intrusive[TITLE] != original[TITLE]) or
(re.search(protection_regex, intrusive[HTML]) is not None and re.search(protection_regex, original[HTML]) is None) or
(difflib.SequenceMatcher(a=original[HTML] or "", b=intrusive[HTML] or "").quick_ratio() < QUICK_RATIO_THRESHOLD)
我们把代码分成四个部分来看,original是我们在run函数刚开始就会执行的正常访问的结果
第一个部分:
如果非法访问的结果状态码和正常访问的结果状态码不同,那么直接判断为True,即该网站部署了WAF
这里有一雷,时代发展到现在,直接正常访问很多时候和直接非法访问结果是一样的,比如cloudflare,因为我们只要没有逆向cloudflare的cookie加密策略,就不可能正常得到一个200的html访问,那么这里的判断就失效了。
第二个部分:
非法访问状态码不是200,那么大概就是被WAF拦截了
为了保障判断是准确的,identYwaf又做了一个保险:如果非法访问的TITLE和正常访问的TITLE也不一样那么真的大概率是被WAF拦截了
第三个部分:
GENERIC_PROTECTION_KEYWORDS = ("rejected", "forbidden", "suspicious",
"malicious", "captcha", "invalid",
"your ip", "please contact", "terminated",
"protected", "unauthorized", "blocked",
"protection", "incident", "denied", "detected",
"dangerous", "firewall", "fw_block",
"unusual activity", "bad request", "request id",
"injection", "permission", "not acceptable",
"security policy", "security reasons")
总之第三个部分就是把请求到的内容进行正则匹配,看上面的这些内容能不能被匹配到,匹配到就不是None,匹配不到就是None,大概率匹配到,小概率匹配不到,因为intrusive[HTML]是攻击包获取的,攻击包访问容易返回denied,rejected等信息。而后面的original[HTML]是不容易返回上面这些内容的(因为original就是正常访问houstname),这里所以这里的意思就是看看网站是否有waf对正常访问以及非法访问进行识别,如果这里是True,那么就说明这个网站有waf
第四个部分:
这里和第三个部分是相似的,如果正常访问和非法访问相似度很高,说明没有WAF,这不好,
值的意义:quick_ratio() 返回的值越接近 1,表示两个序列越相似;值越接近 0,表示两个序列越不相似。
默认的QUIK_RATIO_THRESHOLD = 0.2
所以小于0.2时说明非常不相似,那么大概率该网站就有WAF保护
紧跟着判断的是一段输出和数据存储,不重要,跳
if payload == HEURISTIC_PAYLOAD:
heuristic = intrusive
最后这个就是用一个全局变量heuristic来存储intrusive,后面run函数用得到heuristic
最后return results,表示该网站是否有WAF,判断results那部分确实落后了,现在只要正常访问返回不是html的基本可以判断网站部署了WAF了,没有必要在那比来比去的。
run函数主函数
def run():
global original
hostname = options.url.split("//")[-1].split('/')[0].split(':')[0]
if not hostname.replace('.', "").isdigit():
print(colorize("[i] checking hostname '%s'..." % hostname))
try:
socket.getaddrinfo(hostname, None)
except socket.gaierror:
exit(colorize("[x] host '%s' does not exist" % hostname))
results = ""
signature = b""
counter = 0
original = retrieve(options.url)
if 300 <= (original[HTTPCODE] or 0) < 400 and original[URL]:
original = retrieve(original[URL])
options.url = original[URL]
if original[HTTPCODE] is None:
exit(colorize("[x] missing valid response"))
if not any((options.string, options.code)) and original[HTTPCODE] >= 400:
non_blind_check(original[RAW])
if options.debug:
print("\r---%s" % (40 * ' '))
print(original[HTTPCODE], original[RAW])
print("---")
exit(colorize("[x] access to host '%s' seems to be restricted%s" % (hostname, (" (%d: '<title>%s</title>')" % (original[HTTPCODE], original[TITLE].strip())) if original[TITLE] else "")))
challenge = None
if all(_ in original[HTML].lower() for _ in ("eval", "<script")):
match = re.search(r"(?is)<body[^>]*>(.*)</body>", re.sub(r"(?is)<script.+?</script>", "", original[HTML]))
if re.search(r"(?i)<(body|div)", original[HTML]) is None or (match and len(match.group(1)) == 0):
challenge = re.search(r"(?is)<script.+</script>", original[HTML]).group(0).replace("\n", "\\n")
print(colorize("[x] anti-robot JS challenge detected ('%s%s')" % (challenge[:MAX_JS_CHALLENGE_SNAPLEN], "..." if len(challenge) > MAX_JS_CHALLENGE_SNAPLEN else "")))
protection_keywords = GENERIC_PROTECTION_KEYWORDS
protection_regex = GENERIC_PROTECTION_REGEX % '|'.join(keyword for keyword in protection_keywords if keyword not in original[HTML].lower())
print(colorize("[i] running basic heuristic test..."))
if not check_payload(HEURISTIC_PAYLOAD):
check = False
if options.url.startswith("https://"):
options.url = options.url.replace("https://", "http://")
check = check_payload(HEURISTIC_PAYLOAD)
if not check:
if non_blind_check(intrusive[RAW]):
exit(colorize("[x] unable to continue due to static responses%s" % (" (captcha)" if re.search(r"(?i)captcha", intrusive[RAW]) is not None else "")))
elif challenge is None:
exit(colorize("[x] host '%s' does not seem to be protected" % hostname))
else:
exit(colorize("[x] response not changing without JS challenge solved"))
if options.fast and not non_blind:
exit(colorize("[x] fast exit because of missing non-blind match"))
if not intrusive[HTTPCODE]:
print(colorize("[i] rejected summary: RST|DROP"))
else:
_ = "...".join(match.group(0) for match in re.finditer(GENERIC_ERROR_MESSAGE_REGEX, intrusive[HTML])).strip().replace(" ", " ")
print(colorize(("[i] rejected summary: %d ('%s%s')" % (intrusive[HTTPCODE], ("<title>%s</title>" % intrusive[TITLE]) if intrusive[TITLE] else "", "" if not _ or intrusive[HTTPCODE] < 400 else ("...%s" % _))).replace(" ('')", "")))
found = non_blind_check(intrusive[RAW] if intrusive[HTTPCODE] is not None else original[RAW])
if not found:
print(colorize("[-] non-blind match: -"))
for item in DATA_JSON["payloads"]:
info, payload = item.split("::", 1)
counter += 1
# IS_TTY = True
if IS_TTY:
sys.stdout.write(colorize("\r[i] running payload tests... (%d/%d)\r" % (counter, len(DATA_JSON["payloads"]))))
sys.stdout.flush()
if counter % VERIFY_OK_INTERVAL == 0:
for i in xrange(VERIFY_RETRY_TIMES):
if not check_payload(str(random.randint(1, 9)), protection_regex):
break
elif i == VERIFY_RETRY_TIMES - 1:
exit(colorize("[x] host '%s' seems to be misconfigured or rejecting benign requests%s" % (hostname, (" (%d: '<title>%s</title>')" % (intrusive[HTTPCODE], intrusive[TITLE].strip())) if intrusive[TITLE] else "")))
else:
time.sleep(5)
# IS_TTY = False
last = check_payload(payload, protection_regex)
non_blind_check(intrusive[RAW])
signature += struct.pack(">H", ((calc_hash(payload, binary=False) << 1) | last) & 0xffff)
results += 'x' if last else '.'
if last and info not in blocked:
blocked.append(info)
_ = calc_hash(signature)
signature = "%s:%s" % (_.encode("hex") if not hasattr(_, "hex") else _.hex(), base64.b64encode(signature).decode("ascii"))
print(colorize("%s[=] results: '%s'" % ("\n" if IS_TTY else "", results)))
hardness = 100 * results.count('x') // len(results)
print(colorize("[=] hardness: %s (%d%%)" % ("insane" if hardness >= 80 else ("hard" if hardness >= 50 else ("moderate" if hardness >= 30 else "easy")), hardness)))
if blocked:
print(colorize("[=] blocked categories: %s" % ", ".join(blocked)))
if not results.strip('.') or not results.strip('x'):
print(colorize("[-] blind match: -"))
if re.search(r"(?i)captcha", original[HTML]) is not None:
exit(colorize("[x] there seems to be an activated captcha"))
else:
print(colorize("[=] signature: '%s'" % signature))
if signature in SIGNATURES:
waf = SIGNATURES[signature]
print(colorize("[+] blind match: '%s' (100%%)" % format_name(waf)))
elif results.count('x') < MIN_MATCH_PARTIAL:
print(colorize("[-] blind match: -"))
else:
matches = {}
markers = set()
decoded = base64.b64decode(signature.split(':')[-1])
for i in xrange(0, len(decoded), 2):
part = struct.unpack(">H", decoded[i: i + 2])[0]
markers.add(part)
for candidate in SIGNATURES:
counter_y, counter_n = 0, 0
decoded = base64.b64decode(candidate.split(':')[-1])
for i in xrange(0, len(decoded), 2):
part = struct.unpack(">H", decoded[i: i + 2])[0]
if part in markers:
counter_y += 1
elif any(_ in markers for _ in (part & ~1, part | 1)):
counter_n += 1
result = int(round(100.0 * counter_y / (counter_y + counter_n)))
if SIGNATURES[candidate] in matches:
if result > matches[SIGNATURES[candidate]]:
matches[SIGNATURES[candidate]] = result
else:
matches[SIGNATURES[candidate]] = result
if chained:
for _ in list(matches.keys()):
if matches[_] < 90:
del matches[_]
if not matches:
print(colorize("[-] blind match: - "))
print(colorize("[!] probably chained web protection systems"))
else:
matches = [(_[1], _[0]) for _ in matches.items()]
matches.sort(reverse=True)
print(colorize("[+] blind match: %s" % ", ".join("'%s' (%d%%)" % (format_name(matches[i][1]), matches[i][0]) for i in xrange(min(len(matches), MAX_MATCHES) if matches[0][0] != 100 else 1))))
print()
我们先来看第一部分
global original
hostname = options.url.split("//")[-1].split('/')[0].split(':')[0]
if not hostname.replace('.', "").isdigit():
print(colorize("[i] checking hostname '%s'..." % hostname))
try:
socket.getaddrinfo(hostname, None)
except socket.gaierror:
exit(colorize("[x] host '%s' does not exist" % hostname))
results = ""
signature = b""
counter = 0
original = retrieve(options.url)
if 300 <= (original[HTTPCODE] or 0) < 400 and original[URL]:
original = retrieve(original[URL])
options.url = original[URL]
if original[HTTPCODE] is None:
exit(colorize("[x] missing valid response"))
if not any((options.string, options.code)) and original[HTTPCODE] >= 400:
non_blind_check(original[RAW])
if options.debug:
print("\r---%s" % (40 * ' '))
print(original[HTTPCODE], original[RAW])
print("---")
exit(colorize("[x] access to host '%s' seems to be restricted%s" % (hostname, (" (%d: '<title>%s</title>')" % (original[HTTPCODE], original[TITLE].strip())) if original[TITLE] else "")))
challenge = None
if all(_ in original[HTML].lower() for _ in ("eval", "<script")):
match = re.search(r"(?is)<body[^>]*>(.*)</body>", re.sub(r"(?is)<script.+?</script>", "", original[HTML]))
if re.search(r"(?i)<(body|div)", original[HTML]) is None or (match and len(match.group(1)) == 0):
challenge = re.search(r"(?is)<script.+</script>", original[HTML]).group(0).replace("\n", "\\n")
print(colorize("[x] anti-robot JS challenge detected ('%s%s')" % (challenge[:MAX_JS_CHALLENGE_SNAPLEN], "..." if len(challenge) > MAX_JS_CHALLENGE_SNAPLEN else "")))
这部分就是我们的第一步:先访问hostname(例如baidu.com)
显示检测连接是否有效,然后用retrieve存下正常访问的结果到original,之后进行一次盲猜,如果访问异常就直接退出???雷点+1
接着往下看,后面就是测试的部分:
protection_keywords = GENERIC_PROTECTION_KEYWORDS
protection_regex = GENERIC_PROTECTION_REGEX % '|'.join(keyword for keyword in protection_keywords if keyword not in original[HTML].lower())
print(colorize("[i] running basic heuristic test..."))
if not check_payload(HEURISTIC_PAYLOAD):
check = False
if options.url.startswith("https://"):
options.url = options.url.replace("https://", "http://")
check = check_payload(HEURISTIC_PAYLOAD)
if not check:
if non_blind_check(intrusive[RAW]):
exit(colorize("[x] unable to continue due to static responses%s" % (" (captcha)" if re.search(r"(?i)captcha", intrusive[RAW]) is not None else "")))
elif challenge is None:
exit(colorize("[x] host '%s' does not seem to be protected" % hostname))
else:
exit(colorize("[x] response not changing without JS challenge solved"))
if options.fast and not non_blind:
exit(colorize("[x] fast exit because of missing non-blind match"))
if not intrusive[HTTPCODE]:
print(colorize("[i] rejected summary: RST|DROP"))
else:
_ = "...".join(match.group(0) for match in re.finditer(GENERIC_ERROR_MESSAGE_REGEX, intrusive[HTML])).strip().replace(" ", " ")
print(colorize(("[i] rejected summary: %d ('%s%s')" % (intrusive[HTTPCODE], ("<title>%s</title>" % intrusive[TITLE]) if intrusive[TITLE] else "", "" if not _ or intrusive[HTTPCODE] < 400 else ("...%s" % _))).replace(" ('')", "")))
found = non_blind_check(intrusive[RAW] if intrusive[HTTPCODE] is not None else original[RAW])
if not found:
print(colorize("[-] non-blind match: -"))
for item in DATA_JSON["payloads"]:
info, payload = item.split("::", 1)
counter += 1
# IS_TTY = True
if IS_TTY:
sys.stdout.write(colorize("\r[i] running payload tests... (%d/%d)\r" % (counter, len(DATA_JSON["payloads"]))))
sys.stdout.flush()
if counter % VERIFY_OK_INTERVAL == 0:
for i in xrange(VERIFY_RETRY_TIMES):
if not check_payload(str(random.randint(1, 9)), protection_regex):
break
elif i == VERIFY_RETRY_TIMES - 1:
exit(colorize("[x] host '%s' seems to be misconfigured or rejecting benign requests%s" % (hostname, (" (%d: '<title>%s</title>')" % (intrusive[HTTPCODE], intrusive[TITLE].strip())) if intrusive[TITLE] else "")))
else:
time.sleep(5)
# IS_TTY = False
last = check_payload(payload, protection_regex)
non_blind_check(intrusive[RAW])
signature += struct.pack(">H", ((calc_hash(payload, binary=False) << 1) | last) & 0xffff)
results += 'x' if last else '.'
if last and info not in blocked:
blocked.append(info)
先初始化正则匹配表达式
然后检测HEURISTIC_PAYLOAD非法访问结果怎么样,
如果返回结果是True,这个分支不用管了
如果返回结果是False,这个分支就要进入里面了
因为默认情况是https://访问的,换成http://试一下
依然失败那么估计就是不行了
我没有配置过fast,接着往下走
可以看到,是存在没有返回值的情况,这种百分百是有WAF的,有呢?打印一下呗
然后盲猜一波
然后开始45案例测试(这里使得IdentYwaf的速度慢了下来)
注意这个循环中的所有check_payload的protection_regex不是默认的,而是去除了在正常访问情况出现过的词的
每测试5个案例,试一下弱非法访问(基本上就是合法访问),如果识别不出WAF,说明网站可能封了我们的request,所以睡眠一会,再试,试够3次还不行就退出。说真的测试45个案例,被WAF检测出来封IP不是很正常吗?当然,应该可以通过配置代理来缓解这个问题,但是没钱搞代理呀我!
后面就是正常check_payload,顺便计算hash值和记访问结果,如果识别到waf结果对应payload位置就打一个x
循环结束后计算hash值和输出结果
calc_hash()
def calc_hash(value, binary=True):
value = value.encode("utf8") if not isinstance(value, bytes) else value
result = zlib.crc32(value) & 0xffff
if binary:
result = struct.pack(">H", result)
return result
后面就是一些输出匹配处理,就不详细介绍了。
总结
IdentYwaf确实有一些操作,但是也存在不少问题。最大的雷点集中表现在retrieve上面,整个工具大量使用retrieve来实现很多操作,但是retrieve却处理html返回,放到现在显然是不够的。它开发在2019年,虽然有更新,但是2024年的今天,绝大多数网站都已经有了更加强大的js反爬措施,没有js处理函数显然是这个工具的一个缺陷。
并且45案例测试如果不配置代理就非常容易输出:
[x] host ‘ip’ seems to be misconfigured or rejecting benign requests
且45案例测试非常慢,用时太久了
改进方向:并行运行45个测试案例
封ip确实没什么办法,这东西应该是只能用代理池来过。
一句话,IdentYwaf和wafw00f比较差的有点远了,wafw00f簿杀IdentYwaf
2024.11.22更新部分优化内容
优化
我对identYwaf进行了一些优化,当然不是优化它的处理策略(我对WAF识别实际上懂得并不多),我的优化方式是把45个案例串行测试给优化成了并行测试(当然,还有把urllib库的使用通通换成了requests库,额肯定会有兄弟对requests库怎么做到并行有疑虑的,给大哥们推荐一篇文章:《asyncio 系列》7. 在 asyncio 中引入多线程 )
当然,也不是所有地方我都直接使用的requests库,单纯图不用改库方便(urllib改requests简单,直接改aiohttp太难了,当然requests改aiohttp其实挺简单的,不过我改完urllib成requests就没什么动力改aiohttp了)
我对identYwaf的优化:mengsiIdentYwaf
优化代码我上传github了,还有不少bug和问题,估计是不会大维护了,作业毕竟还有几天才检查,所以这段时间如果还有什么问题我能看到,可能会去改一改吧,后面肯定是不会再回来弄这个项目的,毕竟我改的挺垃圾的,第一次分享github,就当练练手了[捂脸]。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









