







引言
随着深度学习的快速发展,传统的音频处理技术逐渐被智能化算法所替代,尤其是在音乐和语音领域。DDSP(Differentiable Digital Signal Processing)作为一种新兴的音频处理框架,突破了传统数字信号处理(DSP)方法的限制,通过将经典DSP与深度学习技术相结合,开创了一个全新的音频生成与处理的范式。
本文将详细讲解DDSP的基本原理、核心技术、实际应用以及未来发展趋势,帮助读者更深入地理解这一前沿技术。
1. DDSP的基本原理
1.1 传统数字信号处理(DSP)
数字信号处理(DSP)是音频和语音处理领域中经典的技术。它包括信号的采样、变换、滤波等过程,通常使用固定的数学模型和算法。例如,常见的音频信号处理任务包括频谱分析、滤波器设计和混响效果处理等。
然而,传统的DSP方法通常缺乏灵活性,因为它们依赖于手工设计的滤波器和变换,无法自适应复杂的音频输入,且在处理复杂信号(如音乐、自然语言等)时,通常需要大量的专业知识来调优算法。
1.2 DDSP的创新
DDSP(Differentiable Digital Signal Processing)通过将深度学习与经典DSP技术结合,使得数字信号处理变得可微分,从而能够利用梯度下降等优化方法进行端到端训练。这意味着,DDSP不仅能够保留经典DSP方法中的优点,还能通过学习过程自动调节参数,提高音频处理的效果和灵活性。
DDSP的关键创新在于将传统的音频合成模型(如基于振荡器的声音合成)与神经网络相结合。例如,DDSP将频率、振幅、相位等信号参数通过神经网络进行建模,结合经典的DSP组件(如滤波器和振荡器),实现更高质量的音频生成。
1.3 数学模型
在DDSP模型中,音频信号通常被表示为频谱的幅度和相位信息。假设一个音频信号 x(t) 可以通过以下形式表示:
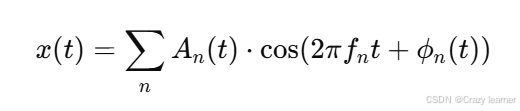
其中,A n (t) 是信号的幅度,f n是频率,ϕn (t) 是相位,t 是时间。
DDSP的神经网络通过学习这些信号参数的时间变化规律来预测每个频率成分的幅度、相位等,从而生成或修改音频信号。通过将这些计算与经典的信号处理模块(如滤波器和合成器)结合,DDSP能够同时发挥神经网络的自适应性和传统DSP的高效性。
2. DDSP的应用领域
2.1 音乐生成
DDSP的最重要应用之一是音乐合成。传统的音乐合成方法(如加法合成和振荡器合成)依赖于手工设计的参数和规则,难以捕捉复杂的音频特性。而DDSP通过神经网络自动学习音频的结构和规律,从而能够生成更加多样化和高质量的音乐。
举例:音乐生成系统
假设一个任务是生成钢琴音符的声音。传统的合成方法可能需要手动设置多个振荡器和滤波器,以模拟钢琴的音色。而DDSP则通过一个训练好的神经网络直接学习钢琴音色的频谱特征,自动生成音符对应的音频信号。该系统能够生成更加真实、自然的音色,并且不需要人工干预。
2.2 音频修复与编辑
DDSP技术也广泛应用于音频修复和编辑领域。例如,当音频录制时出现噪声或音质损坏,传统的音频修复方法可能无法完全恢复原始音质。而DDSP可以通过学习音频信号的频谱特征,在不损失音质的情况下,修复音频信号。
举例:音频降噪
在噪声环境下录制的音频往往包含了背景噪声,这些噪声往往难以通过传统的滤波器消除。DDSP可以通过学习音频的频谱特征和噪声模式,在音频的修复过程中进行有效的噪声去除,同时保留音频的原始细节。
2.3 语音合成
在语音合成(TTS,文本转语音)领域,DDSP也展现出巨大的潜力。传统的TTS系统通常依赖于复杂的声学模型和语音合成器,需要大量的语音数据来训练。而DDSP可以通过学习语音信号的频谱和时域特征,生成更加自然和流畅的语音。
举例:语音转换
假设我们有一个语音合成系统,要求将某个说话人的语音样本转换成另一个说话人的声音。传统方法通常需要在声学模型中对说话人的声音特征进行强烈的建模,而DDSP通过训练一个可微分的神经网络,可以自动学习不同说话人的频谱特征,进行声音的转换,甚至可以让合成的语音更加接近目标说话人的音色。
2.4 音频效果处理
DDSP还可以用于音频效果的生成和处理。例如,在混响、延迟、均衡等音频效果的设计中,DDSP可以通过神经网络自动学习效果的参数,而无需手动调整复杂的滤波器和混响算法。
举例:数字混响
混响是音频处理中的常见效果,传统方法通常依赖于固定的滤波器和算法来模拟房间的声学特性。而DDSP通过神经网络来学习混响效果的动态变化,可以实现更精确、自然的混响效果,使得音频在不同环境中表现得更加真实。
3. DDSP技术的挑战与发展趋势
3.1 挑战
尽管DDSP技术有着显著的优势,但它也面临着一些挑战:
训练数据的需求:DDSP的效果很大程度上依赖于大量高质量的训练数据。对于某些特定的音频类型(如稀有的乐器音色或特定的语音模式),可能很难获得足够的数据来训练模型。
模型复杂度高:虽然DDSP可以提供高质量的音频合成和修复效果,但其训练过程通常较为复杂,且对计算资源的需求较高,可能不适用于所有场景。
泛化能力:DDSP虽然能够在特定的音频数据集上表现优异,但对于新的、未见过的音频模式,模型的泛化能力可能存在一定限制。
3.2 发展趋势
随着深度学习技术的不断发展,DDSP的应用和性能也在不断提升,未来的发展趋势包括:
更高效的训练方法:随着计算资源的提升和优化算法的进步,DDSP的训练速度将进一步提高,尤其是在处理大规模数据集时。
多模态融合:未来的DDSP系统可能不仅仅局限于音频处理,还能够融合视觉、触觉等其他模态的信息,从而实现更为智能的音频生成和处理。
实时音频处理:随着硬件加速技术的发展,DDSP有望实现实时的音频生成和处理,广泛应用于直播、游戏、语音助手等实时交互场景。
个性化音频生成:DDSP能够根据个人的声音特征进行定制化生成。未来,个性化音频生成将成为音频处理中的一个重要发展方向。
4. 总结
DDSP(Differentiable Digital Signal Processing)技术通过结合深度学习与传统数字信号处理方法,开创了音频生成和处理的新纪元。它不仅能够自动化音频处理任务,还能在音乐生成、语音合成、音频修复等多个领域展现出巨大的潜力。尽管存在训练数据需求大和模型复杂度高等挑战,但随着技术的不断发展,DDSP无疑将在未来的音频处理领域产生更加深远的影响。


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









