







1,示例
(1) 给DataFrame设置别名(一行代码一行代码运行)
val rdd=sc.makeRDD(Seq(("Jack",24),("Mary",34)));
val df1 = rdd.toDF();
val df2 = rdd.toDF("name","age");
df1.show();
df2.show();
运行结果:


(2)使用SqlContext执行SQL语句 (继续上面的代码运行)
df2.createOrReplaceTempView("person");
val sqlContext = spark.sqlContext
sqlContext.sql("select * from person").show();
运行结果:

(3)Scala代码将RDD转成Bean
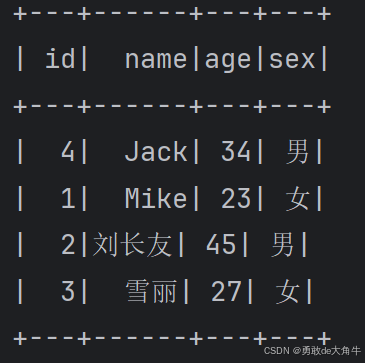
在D:/a路径下面,创建stud.txt文件,文件内容:
4 Jack 34 男
1 Mike 23 女
2 刘长友 45 男
3 雪丽 27 女
在pom.xml文件中添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId> <version>3.1.1</version>
</dependency>
运行代码
package org.hadoop.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object RddToBean1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf();
conf.setMaster("local[*]");
conf.setAppName("RDDToBean");
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate();
val sc: SparkContext = spark.sparkContext;
//读取文件
import spark.implicits._;
//步2:读取文件
val rdd: RDD[String] = sc.textFile("file:///D:/a/stud.txt");
//步3:第一次使用map对每一行进行split,第二次使用map将数据封装到Bean中,最后使用toDF转换成DataFrame
val df = rdd.map(_.split("\\s+")).map(arr => {
Stud(arr(0).toInt, arr(1), arr(2).toInt, arr(3));
}).toDF();
//步4:显示或是保存数据
df.show();
spark.close();
}
/** 步1:声明JavaBean,并直接声明主构造方法 * */
case class Stud(id: Int, name: String, age: Int, sex: String) {
/** 声明无参数的构造,调用主构造方法 * */
def this() = this(-1, null, -1, null);
}
}
运行结果
(4)WordCount示例
- 直接使用groupBy进行count计算
val rdd = sc.textFile("hdfs://localhost:9000/input/notes.txt")
val df3 = rdd.flatMap(_.split("\\s+")).toDF("str");
df3.groupBy("str").count().show();//运行结果见1图
运行结果

- 指定排序规则
df3.groupBy("str").count().sort("str").show();//对字符进行排序

- 直接使用SQL语句
df3.createOrReplaceTempView("words");
spark.sql("select count(str),str from words group by str").show

(5)Scala代码示例
- 运行SparkSQL.scala

- 运行SparkSQL2.scala
2,Read和Write
read方法介绍
可以读取的数据类型
csv format jdbc json load option options
orc parquet schema table text textFile

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









