



当我们直接使用ultralytics的yolo跑完模型通常会出现这样的结果,但是但是对于很多新手来说都不是很友好,现在我就简单的介绍一下每一张图的意思,以及代表的含义,方便其能够更快的上手yolo来了解每一个图所代表的指标含义
数据来源:数据来源
@misc{
detecting-diseases_dataset,
title = { Detecting diseases Dataset },
type = { Open Source Dataset },
author = { Artificial Intelligence },
howpublished = { \url{ https://universe.roboflow.com/artificial-intelligence-82oex/detecting-diseases } },
url = { https://universe.roboflow.com/artificial-intelligence-82oex/detecting-diseases },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2025-07-29 },
}
训练代码:
import os
from ultralytics import YOLO
# 解决OpenMP错误
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def main():
# 加载预训练模型
model = YOLO('yolo11n.pt')
# 开始训练
print("开始训练...")
results = model.train(
data='data/data.yaml', # 你的数据配置文件
epochs=100, # 训练轮数
imgsz=640, # 图像尺寸
batch=8, # 批次大小
device=0, # 使用GPU
project='runs/train', # 保存目录
name='crop_disease', # 运行名称
)
print("训练完成!")
print(f"模型保存在: runs/train/crop_disease/weights/best.pt")
if __name__ == "__main__":
main()
等待我们训练完成之后就会看到
一、标签统计图
labels.jpg
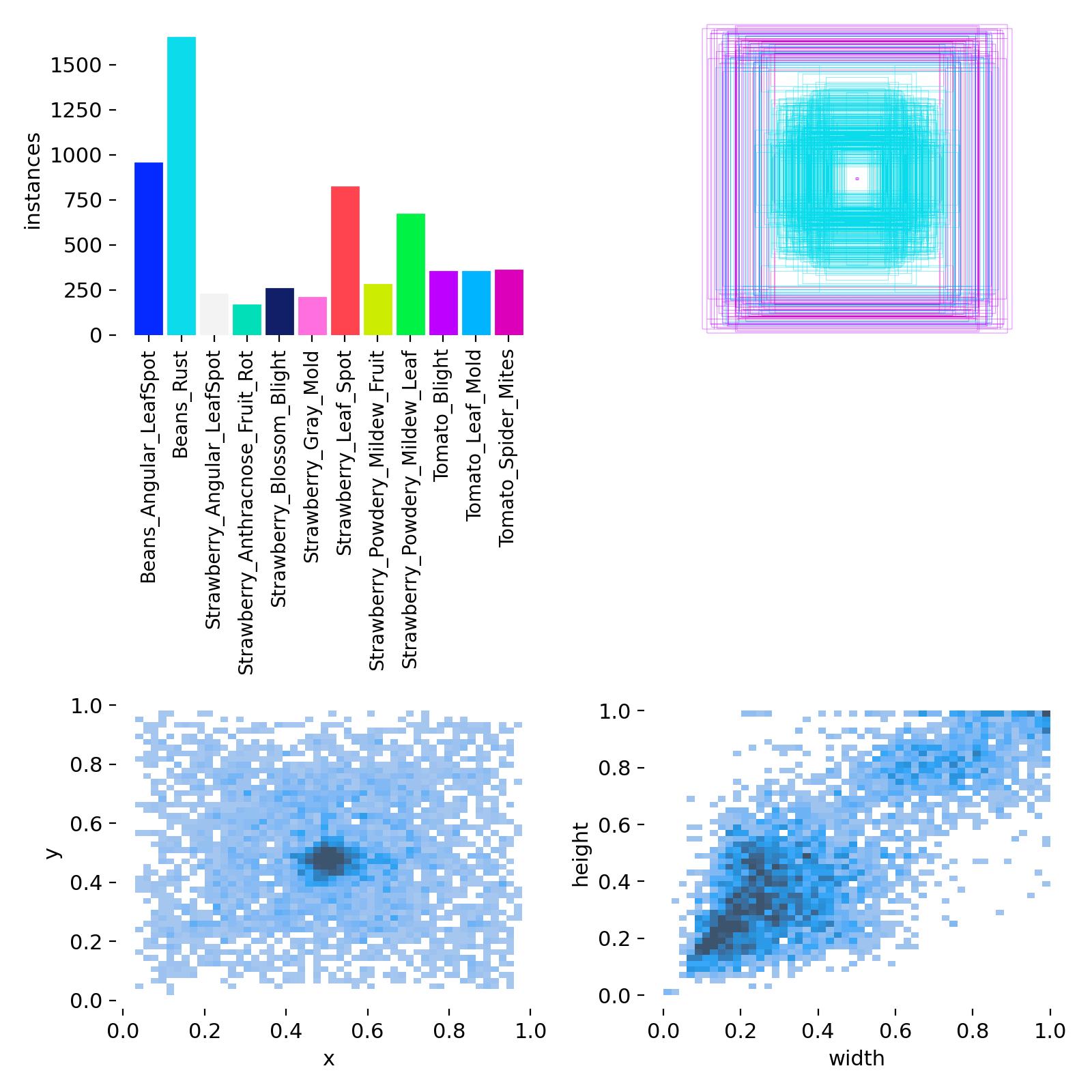
左上:这里就是我类别的统计,主要就是去看看有没有类别不平衡的问题,比如说我们的第二个类别,现在他是明显高于其他的标签,有可能对于他的标签利好,在第一次训练的时候如果效果不好,我就会去降低他的权重,什么意思呢
如果你现在有100个标签,女生 90 男生 10
正常来说我们都会好好的去学习特征,但是模型不会,如果他有可能会把这个标签全部预测为女生,他的准确率就直接90%
所以一般训练的时候会观察一下,然后加入预训练权重
或者对于对于样本不足的
右上:这个其实就是将我们所有的框全部都叠在了一起,不同的颜色代表着不同类别的框,这里我们可以明显看出来紫色类别的框相对于其他颜色的框标记范围会更大
左下:中心点相对于整幅图的位置,边界框中心点在图像中的位置分布情况【这里我们详细来看看yolo的标签格式】统计的就是这里
右下:边界框的宽度和边界框的高度
弄清楚我们的左下和右下,其实就能明白我们yolo标记的原理【选择类别 找中心点 找到之后画长和宽】
9 0.5012019230769231 0.4891826923076923 0.984375 0.9651442307692307
9【类别id对应 data.yaml】 0.5012019230769231【中心点的x坐标】 0.4891826923076923【中心的y坐标】 0.984375【宽度】 0.9651442307692307【高度】
labels_correlogram.jpg
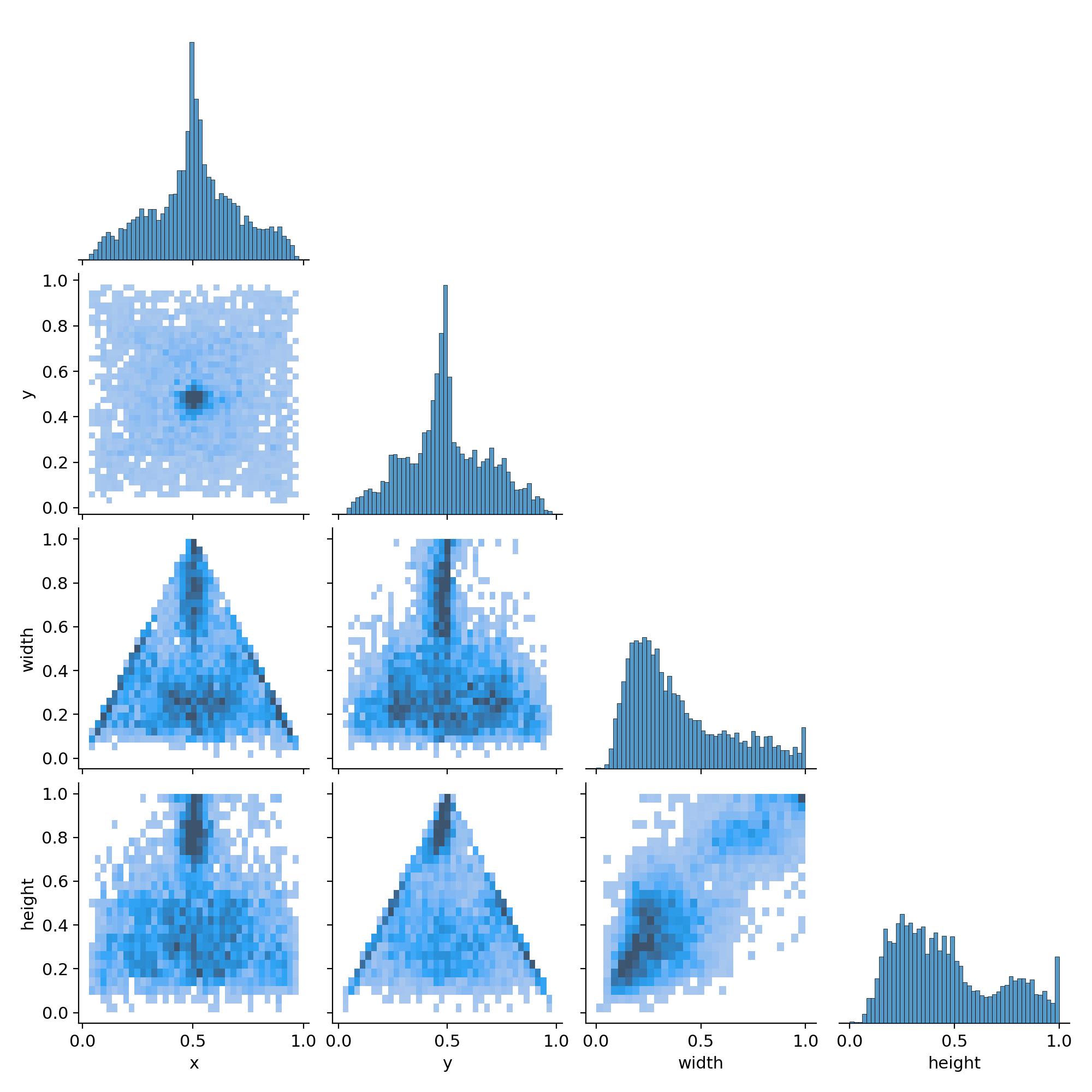
这里图主要就是去看我们行列之间对应的热力关系
比如我们第一行的第一列,就是x和y的一个热力分布关系【可以去看labels.jpg的右上】
这个图主要就是看类别分布不均衡或者我们图是不是存在一些异常分布
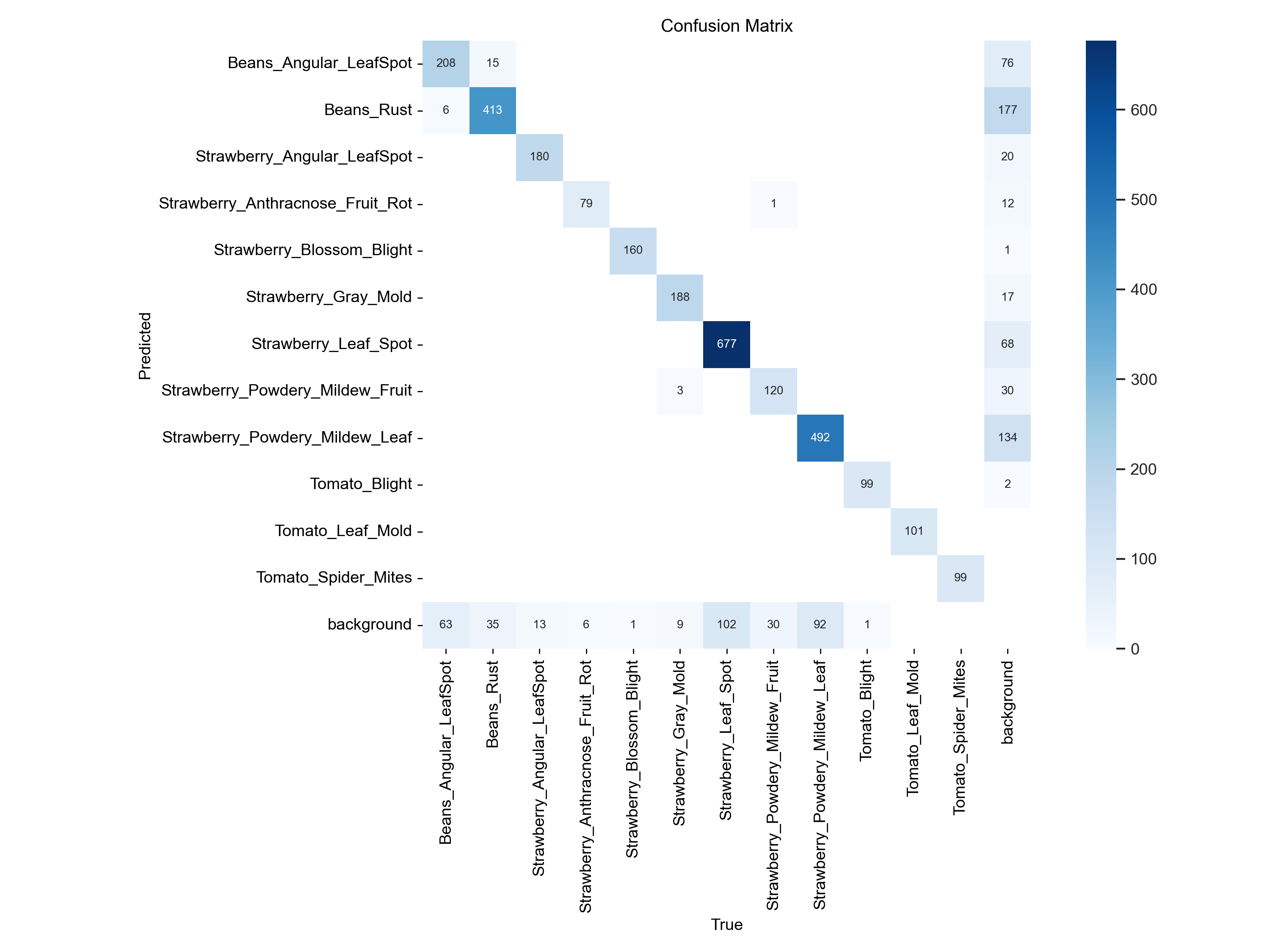
二、混淆矩阵
confusion_matrix.png
confusion_matrix_normalized.png
normalized意思就是标准的,简单的来说,就是将confusion_matrix里面的数据全部规范到了0-1的区间,方便我们去查看概率
预测概率越高的颜色会越深
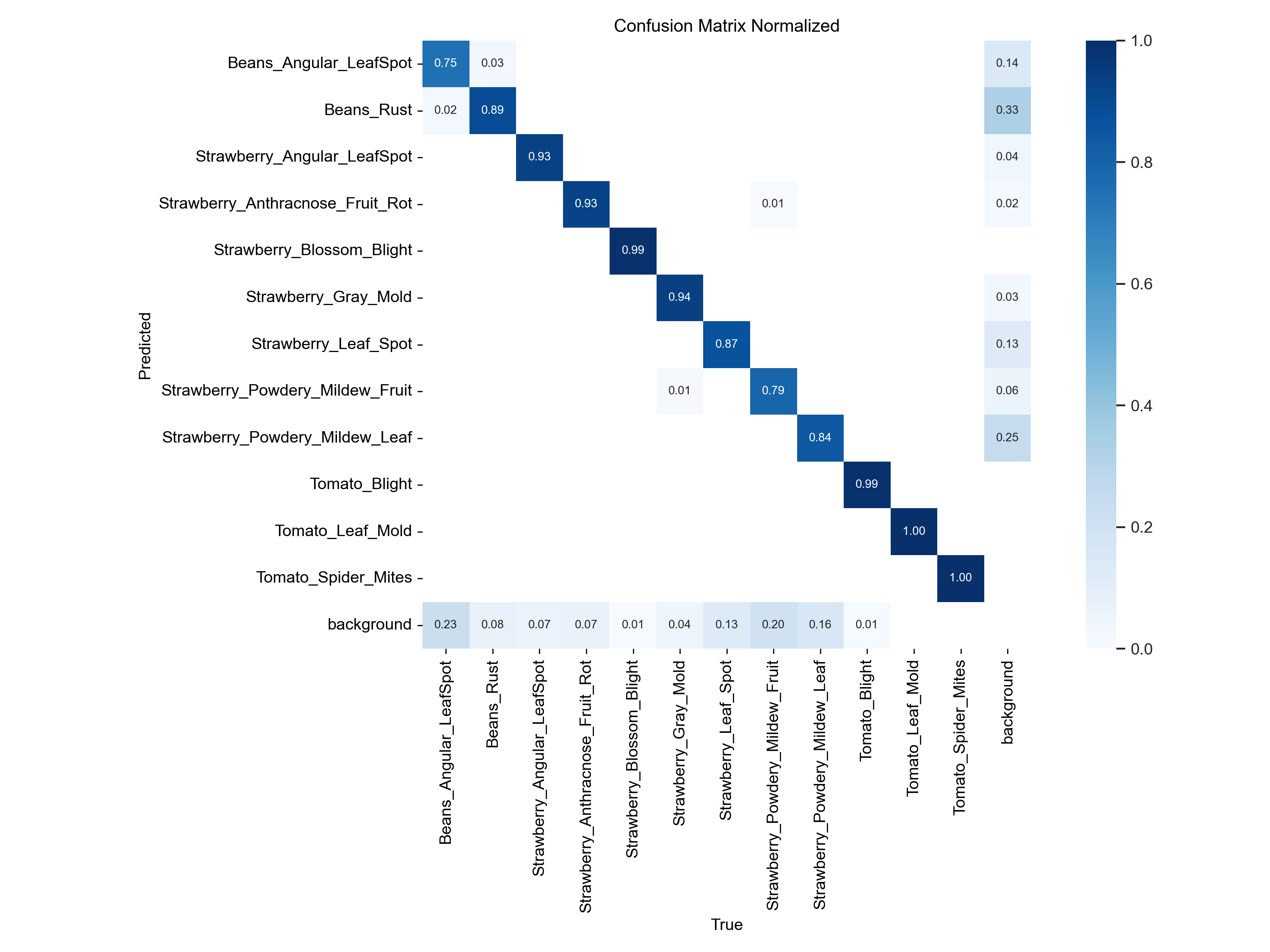
我们来查看的时候我们都是一数列一数列的来看
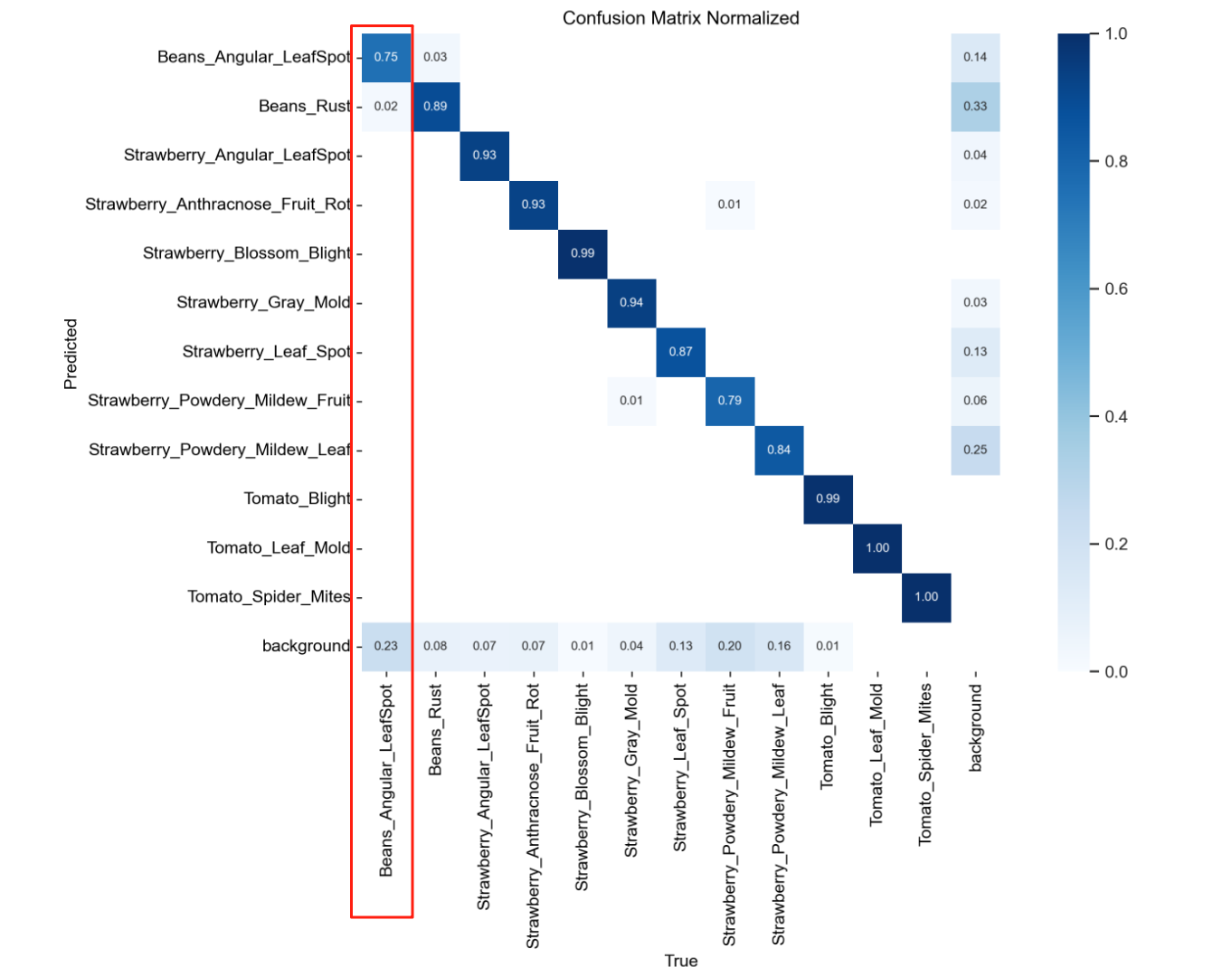
我们看的时候基本上就是看对角线上【他自己对于他自己内别的预测】的数值
比如我们的第一个内别
他被预测为第一个类别【正确标签】的概率为0.75
预测为第二个标签的概率为0.02
还有预测为背景的概率是0.23
合计就是概率1
就是在有些情况下,我们的类别1会有0.23的概率会被识别为背景
我们可能需要加入一些没有标签的样本
让他去学习背景的特征
然后他类别1预测为第二个标签的概率为0.02
这个其实很正常
如果差距再大一点,我们就需要去考虑是不是样本比较相似
或者说两者样本出现不平衡的问题
三、结果图
results.png
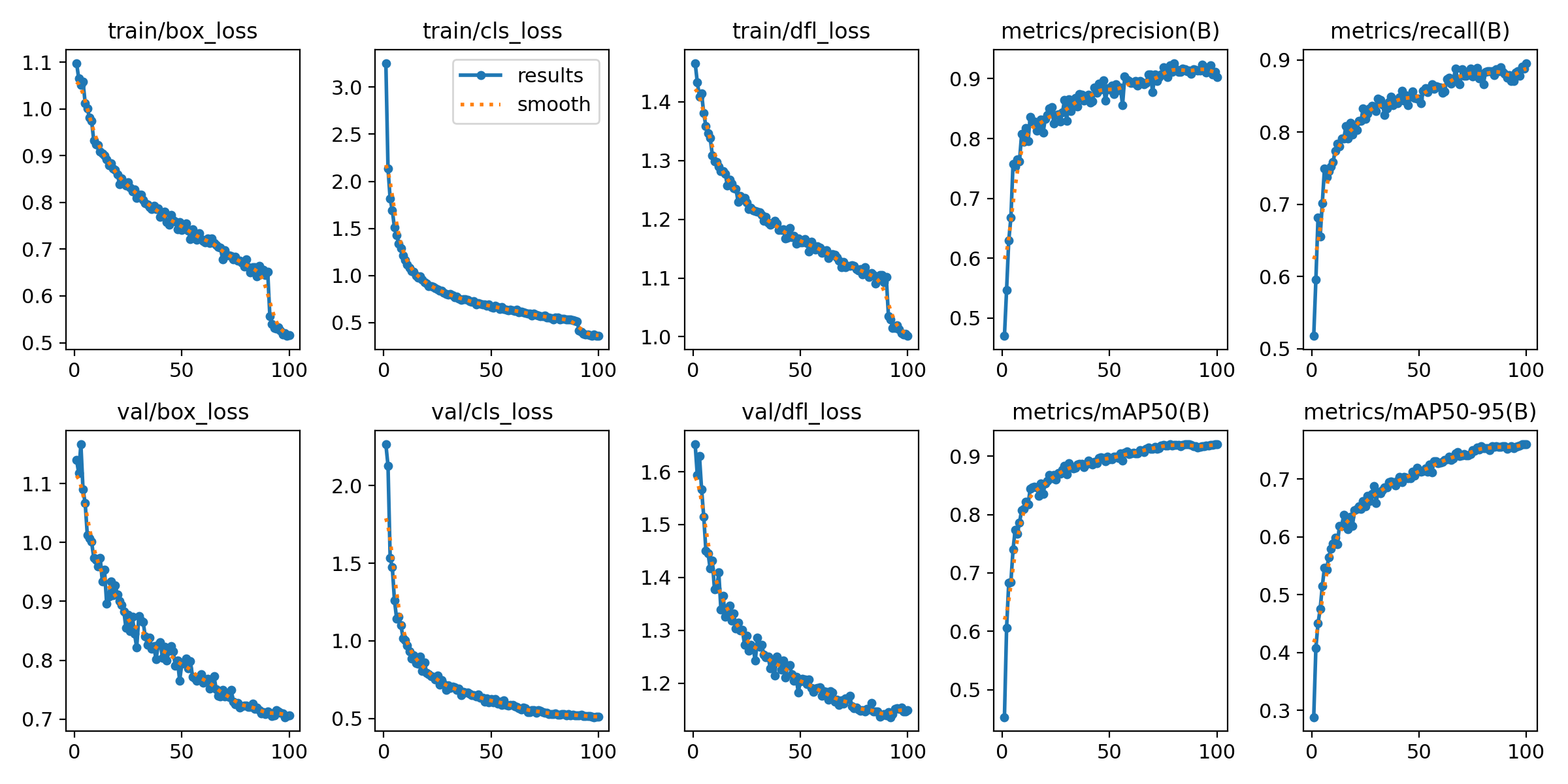
定位损失(box_loss)
边界框的预测和标准之间的损失
分类损失(cls_loss)
预测类别和真实类别之间的损失
分布式焦点损失(dfl_loss )
边界框位置概率分布优化的损失
精度(Precision)
P(精度)=TP(正检)/ TP(正检)+FP(误检)
召回率( Recall)
R(召回)=P(正检)/ TP(正检)+FN(漏检)
平均精度(mAP)
MAP50 阈值设为 0.5 时的平均精度
MAP50-95 IoU=0.5 到 0.95的多个阈值的平均精度
基本上只要你的损失在往下降,准确率在提高,问题就不是很大,有波动很正常
但是我们要注意就是当你验证集准确率上升到一个瓶颈
并且你验证集的损失在下降的时候就要小心过拟合了
一般而言我会跑个100轮左右
然后用启动早停机制去看大概在哪一个epoch拉满
如果你的准确率一直上不去
可以去检查一下你的数据集
有很大一部分有可能是数据集的问题
如果检测了没有问题
就可能需要去优化网络结构了
主干网络 注意力机制 损失函数
四、F1曲线
F1_curve.png
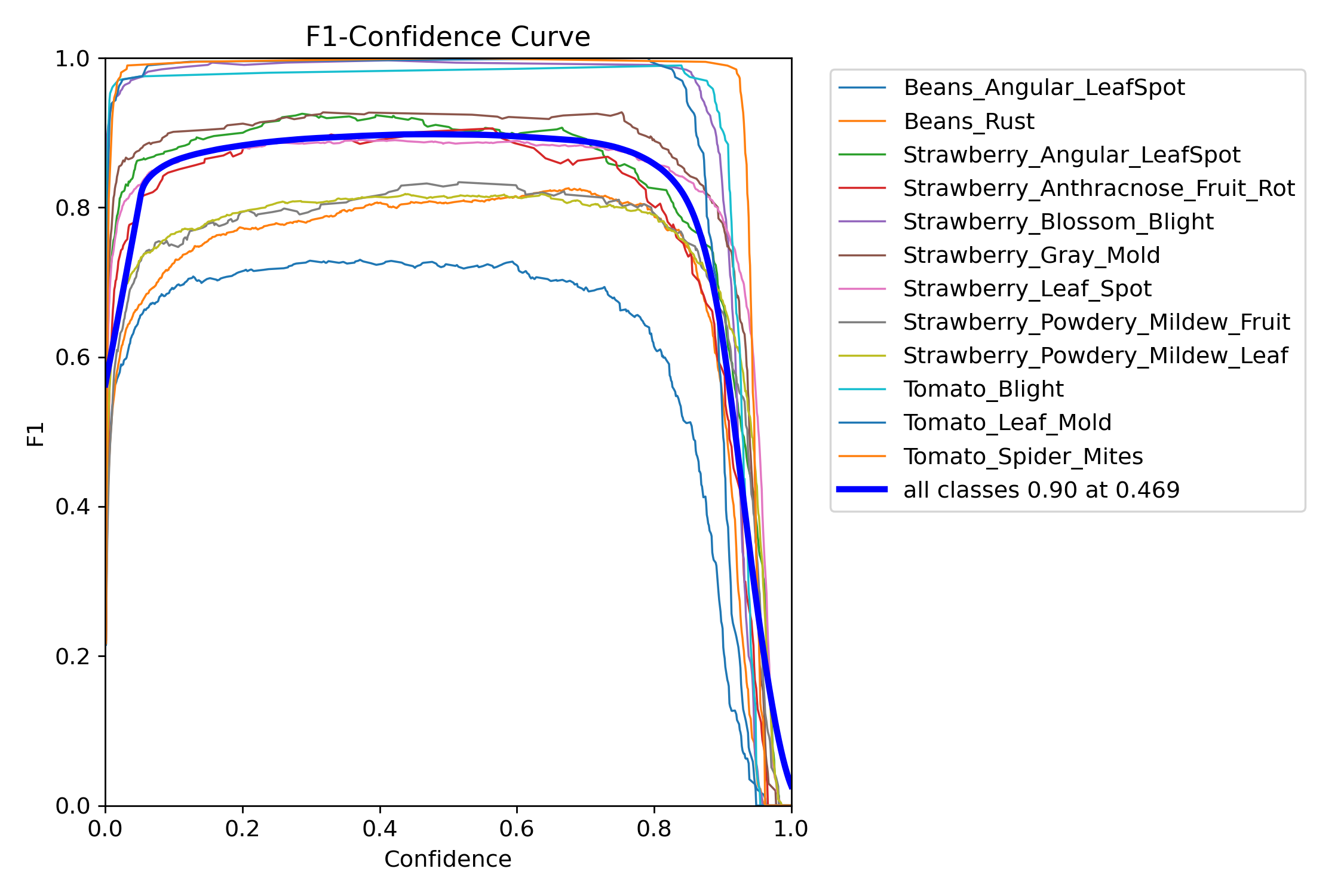
这个就是精确率(Precision)和召回率(Recall)的调和平均数
就是精准率和召回率动态博弈的过程
曲线越高:整体性能越好(F1分数高)
曲线平缓:模型对阈值变化不敏感,鲁棒性较强
陡峭下降:阈值选择对性能影响大,需谨慎调参
然后在这里可以看到我们如果需要对我们的模型进行预测,可以看到我们阈值选取的一个大致范围,用于推理阶段的检测框过滤,比如像这里,我就会选择0.8的置信度
五、R_curve曲线
R_curve.png
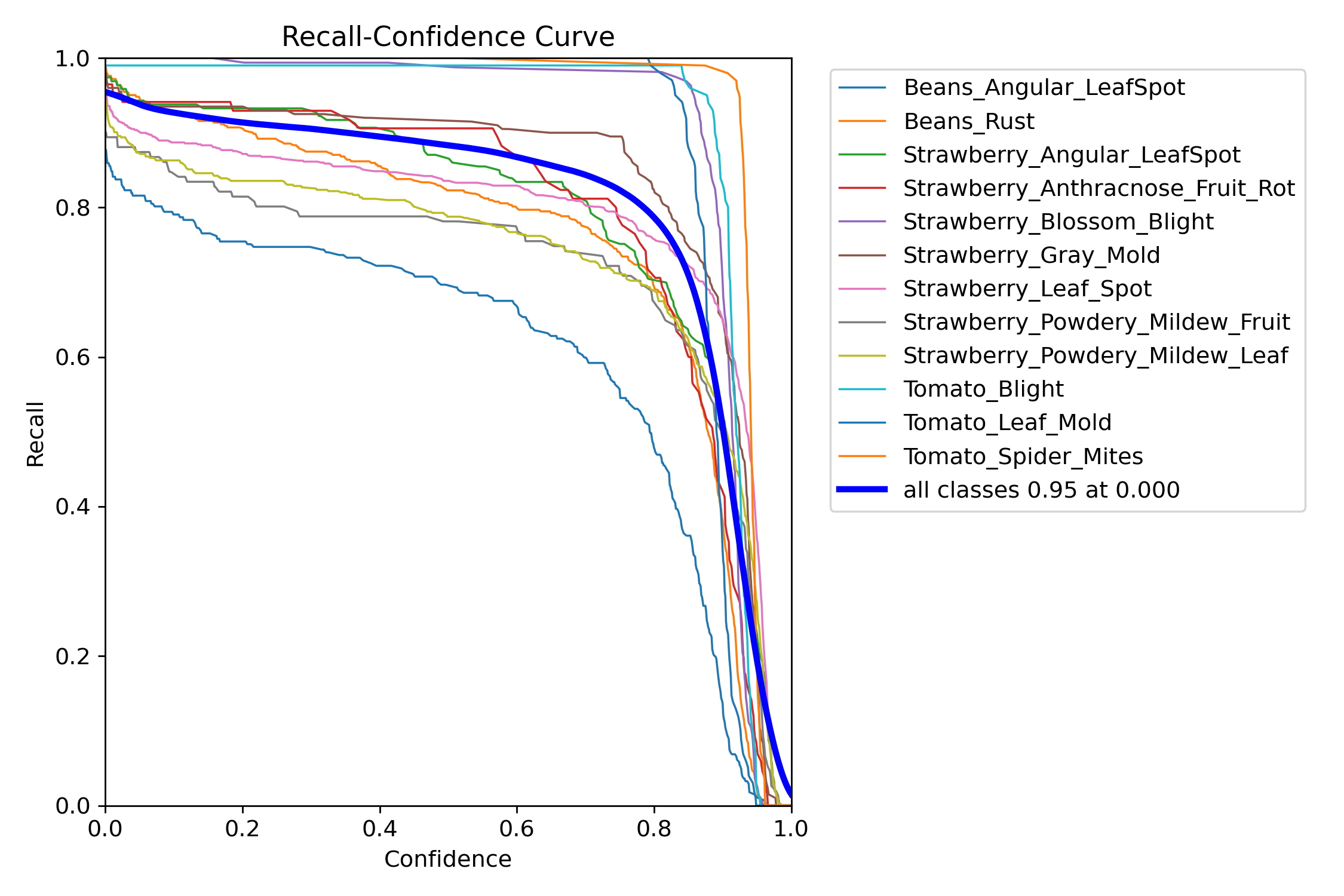
这个曲线的意义就是随着我置信度变化,我的召回率的变化
我们看一开始的时候,直接看两个端点
0端点
当我0的时候都可以,这个时候我的屏幕会是满屏的框,你的召回率自然而然就高了

1端点
当我要求置信度为1的时候,由于我的要求严格,有一点点偏差,只要不是100%就会被我pass,预测出来的框会很少,所以我的召回率就会变低
六、P_curve曲线
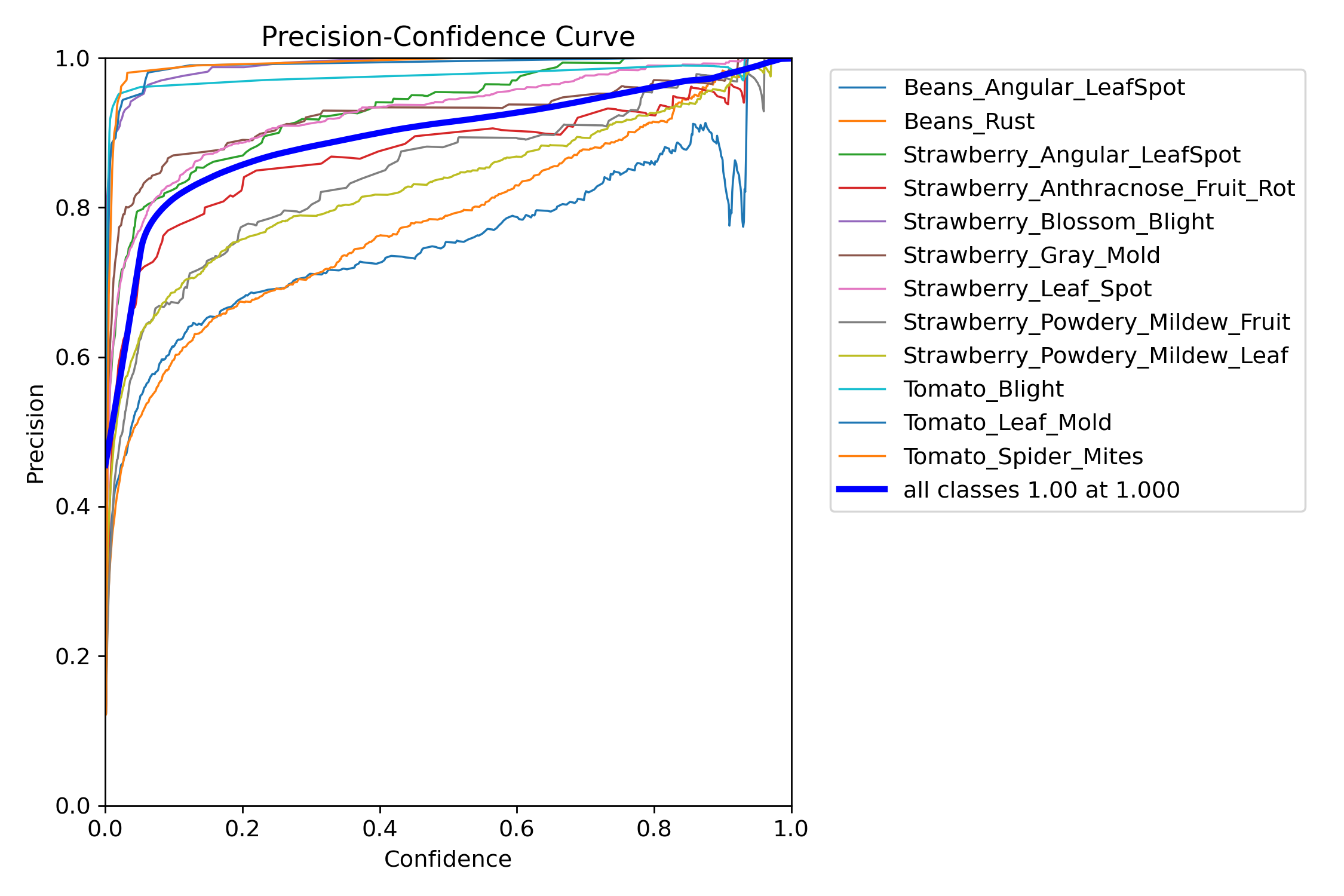
这个曲线的意义就是随着我置信度变化,我的准确率的变化
一开始为0的时候相当于我满屏都是框,但是我的准确率没有办法得到保障,所以我们准确率就会下降
然后到了为1的之后,只有当我非常确定以及肯定的时候,我才会框选
我的准确率自然就搞了
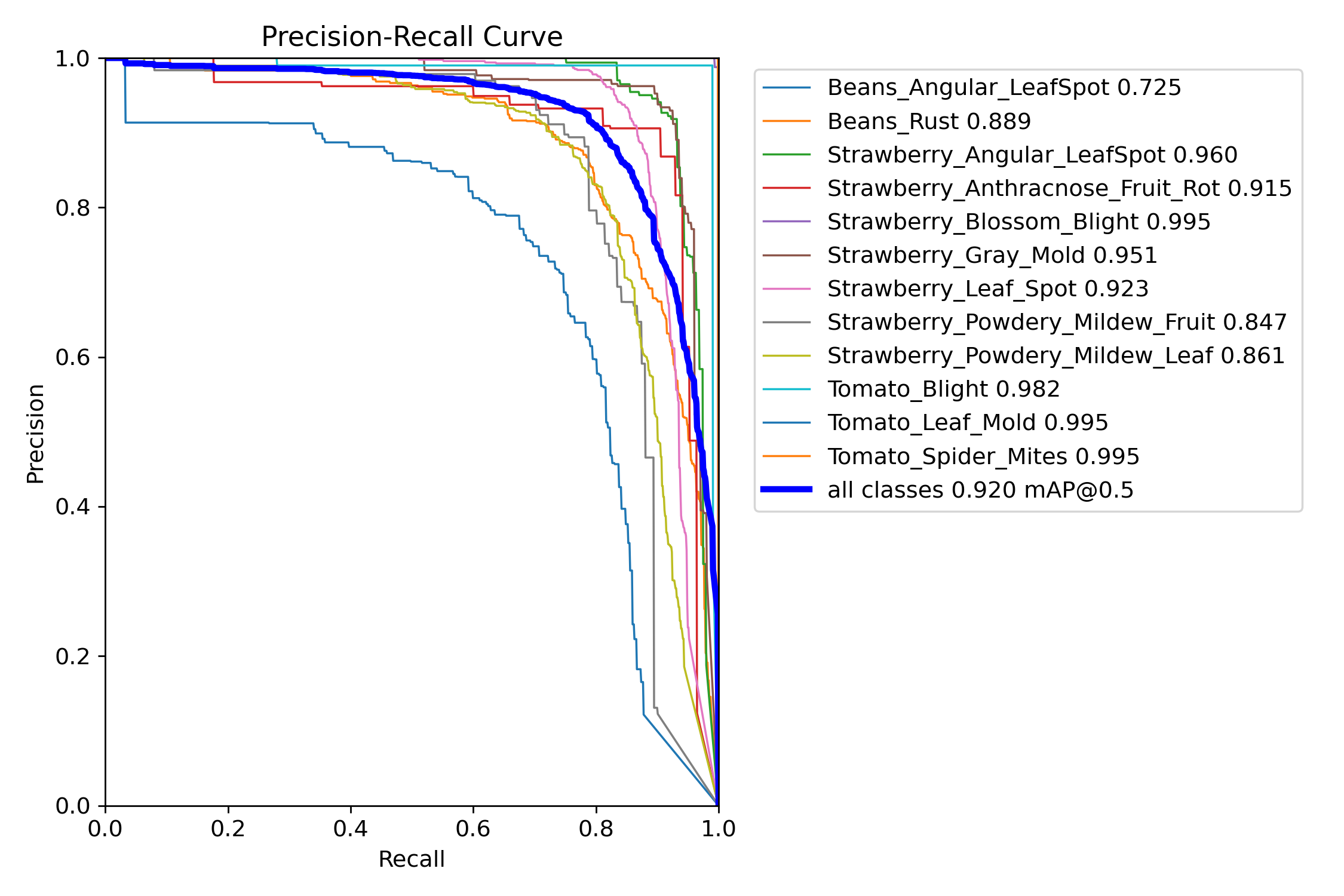
七、PR_curve
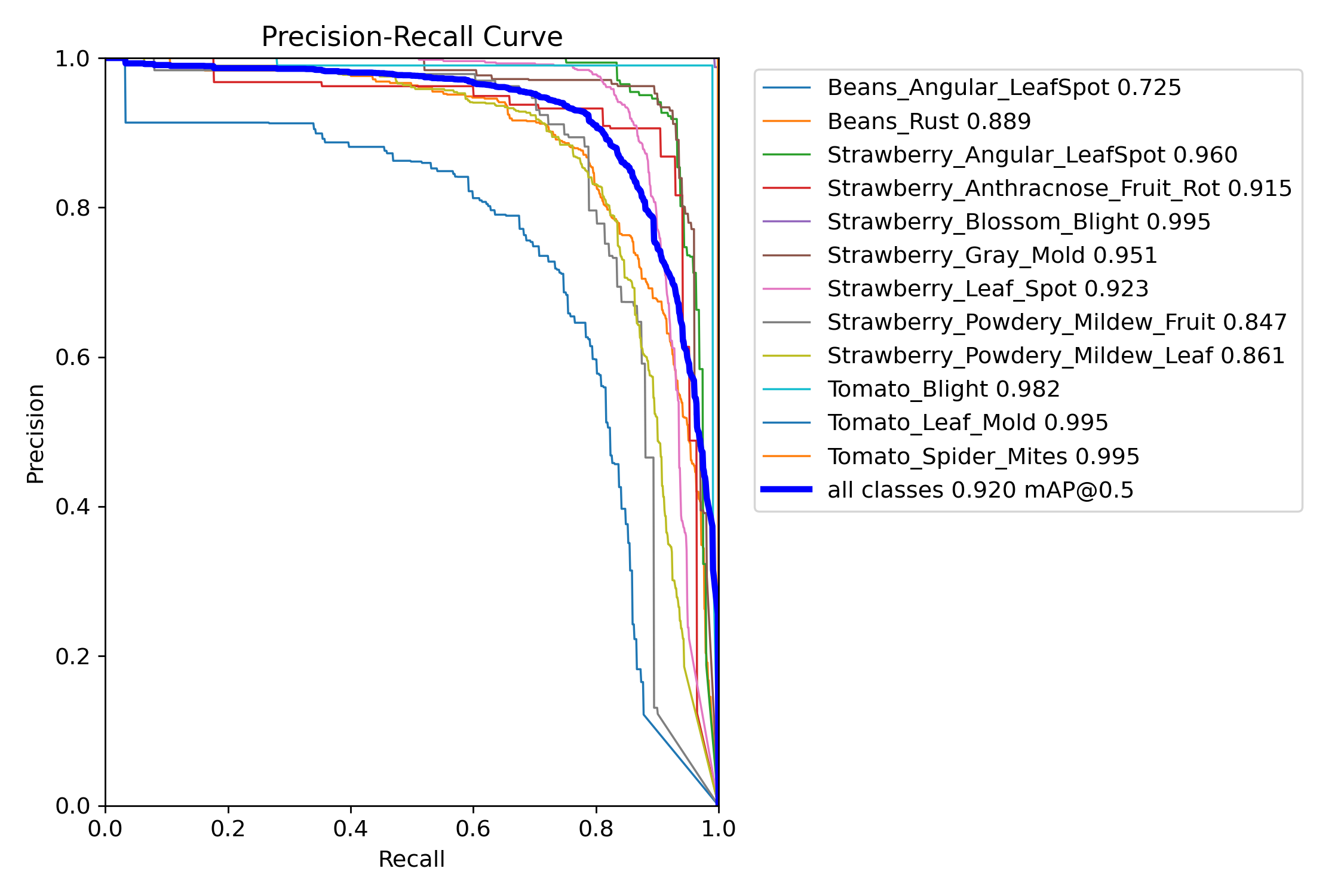
曲线越靠近右上角,模型性能越好(高Precision + 高Recall)。
曲线接近对角线(从(0,0)到(1,1)):模型性能接近随机猜测。
曲线波动剧烈:可能在不同阈值下Precision不稳定(常见于小数据集或困难样本)
直接去计算我们pr曲线的面积就好了



















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











