






(AAAI 2023)论文阅读——Yet Another Traffic Classifier: A Masked Autoencoder Based Traffic Transformer with Multi-Level Flow Representation
文章基本信息
作者:Ruijie Zhao et al.(上交薛质团队)
代码:code
文章:paper
摘要
- 存在问题:
- 流量表示仅由原始数据包生成,导致没有重要信息;
- 直接应用深度学习算法的模型结构不考虑流量特征;
- 特定场景中的分类器训练通常需要大量人力与时间来标记数据。
- 研究目标:加强流量表征效果、使用大量无标签的数据对分类器进行预训练,再使用少量有标签的数据进行微调。
- 核心思想:同时考虑流量中的数据包级数据和流级数据,使用无监督预训练+有监督微调的基于transformer的掩码自动编码器(MAE)进行流量分类任务。(整体是基于ViT结构,将流量数据处理为相似的图片进行表征)
方法概述
三个核心过程:
- 构建多级流表示矩阵 MFR(multi-level flow representation matrix)对原始流量进行建模。
- 使用MAE对构建的MFR进行无监督特征提取,主要通过重建任务来学习流量数据的潜在表示。
- 将训练好的encoder参数加载到transformer中,再使用少量有标签样本进行有监督微调。
整体流程:MFR矩阵构建>MAE特征提取>transformer分类器训练
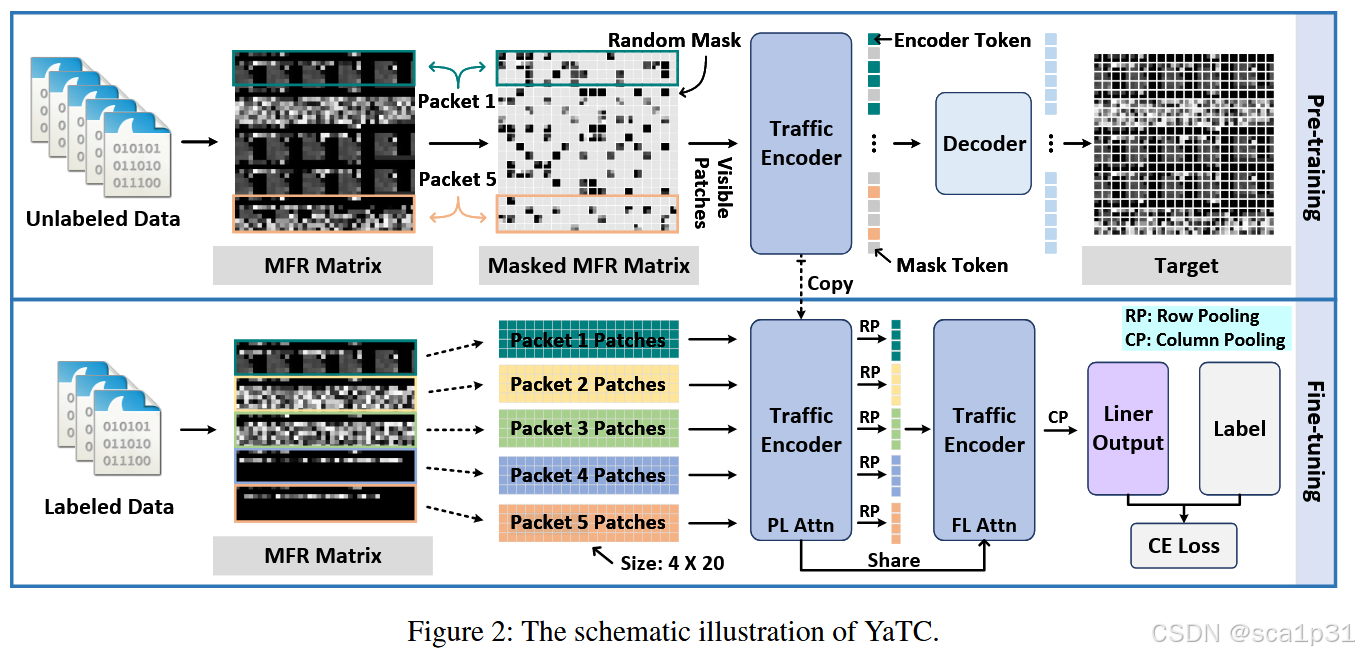
MFR矩阵的构建
MFR矩阵的构建主要是为了提取多级流量特征,由于目前大部分流量数据的处理方式就是截取或者padding到一个固定大小的二维方阵(如28*28)。然而有的流中第一个包的长度过程,这样处理就会造成信息丢失等问题,所以本文提出了MFR矩阵构建来处理数据。处理过程如下图(注意,本文的流量处理后还是以灰度图像的形式作为输入):
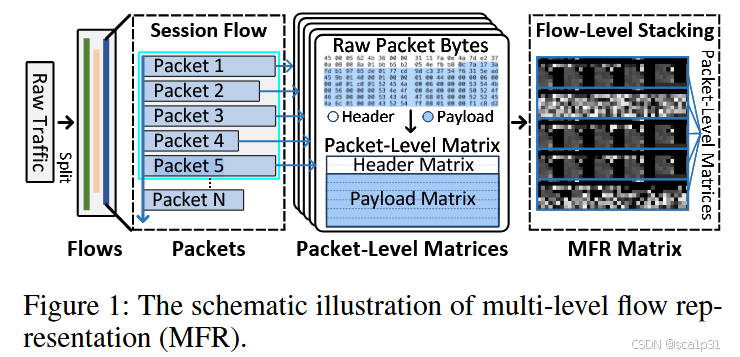
首先根据IP地址、端口号和协议类型将原始流量分为流(会话),并且删除可能带来噪音的以太网头、将端口都设置为0、使用随机地址替换IP地址但是保留会话间通信的方向。最后,将流量中的M相邻数据包捕获,并格式化为大小H ∗ W的二维矩阵,作为该流量的表示。文章仍然使用了原始字节作为初始特征,即流量表示矩阵中的每一个点,但采用了以下的设计来捕获原始流量的多级信息:
- 字节级Byte-level:流量表示矩阵的每一行仅包含一种类型的流量字节,分为标题行和有效载荷行。
- 数据包级Packet-level:每个数据包由标头矩阵和有效载荷矩阵表示,形成一个大小H/M ∗ W的数据包级矩阵。
- 流级Flow-level:由于流由有序数据包组成,因此将相邻数据包级矩阵堆叠在第二维中,以形成最终的MFR矩阵。
细节:每个级别的信息都是固定的,并且在较低级别不会溢出,从而导致较高级别的信息丢失。文章将MFR矩阵设置为包含5个数据包级矩阵,总计40行,每行包含40个字节。每个数据包的标头由2个标头行表示,具有80个字节,具有包含IP层标头(20个字节),TCP标头(20个字节)或UDP标头(8个字节)和可选标头的功能。我们分配了6个有效载荷行以容纳每个数据包的有效载荷,并在超过240字节时执行拦截。请注意,如果有效字节的数量不足,它将用0个字节填充以形成固定大小的表示矩阵。
(也就是说,最后形成的灰度图像是40*40的大小,并且每一个流只使用了流中的前五个包,其余的都进行了截断)
流量Transformer的设计
流量transformer由嵌入模块、数据包级注意力模块和流级注意力模块三部分组成。
嵌入模块:由于MFR矩阵是一个高为H,宽为W的矩阵,嵌入模块使用patch embedding的方式进行处理。选取patch大小为2*2,而MFR是一个40*40的矩阵,所以得到了40*40/(2*2)=400个不重叠的二维patch。然后将这些patch通过一个线性层映射到192维的向量中,这是因为后续要用Transformer的自注意力机制对这些patch进行建模,需要把每一个patch映射为一个定长的向量(也叫做token)。在ViT中也会有这样一个线性层将每个patch投影到D维向量空间,本文中的192也是一个超参数。由于Transformer本身是对序列位置不敏感的,注意力机制不包含显式的顺序信息,所以本文要给这些patch embedding加上位置编码也就是position embedding:
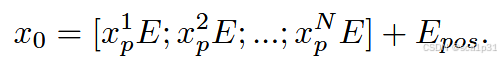
数据包级注意力模块:本文参考ViT的架构,也使用多头自注意力机制。为了优先考虑单个数据包中header中的patch或者payload中的patch之间的关系,仅在单个数据包内使用多头注意力,而不是整个MFR矩阵。将输入的patch embedding(同一个包的所有patch)同时投影到多个注意力头上,每个头在不同的子空间里学习补充的依赖关系。最后再将多个头的输出拼接(Concat)起来,通过一个线性映射获得最终的输出表示。这样每一个头都可以学习到不同的注意力模式,比如某个头专注于header-header之间的关联,而另一个就专注于header-payload之间的关联。文中使用了16个头和4个交替层。
流级注意力模块:在包级注意力模块后,每个包中的重要信息已经被提取出来,这些特征可以用来进一步建模包与包之间的关系,尤其是跨包党的长距离依赖。在流级的建模中,不需要再像包级那样使用细粒度的patch,而是使用更加粗粒度的特征来进行建模。通过对包级的patch特征进行了行池化。行池化操作会聚合(mean-pool)同一行的多个patch特征,生成新的"行patch"。这种方法使得每一个新的"行patch"表示整个包的一部分信息,但不再关注每一个patch的细节。这样我们知道每一个数据包都包含1个header 行patch和3个payload行patch(因为最开始的patch是2*2的,所以MFR中的两行才满足一个"行patch")
YaTC预训练阶段
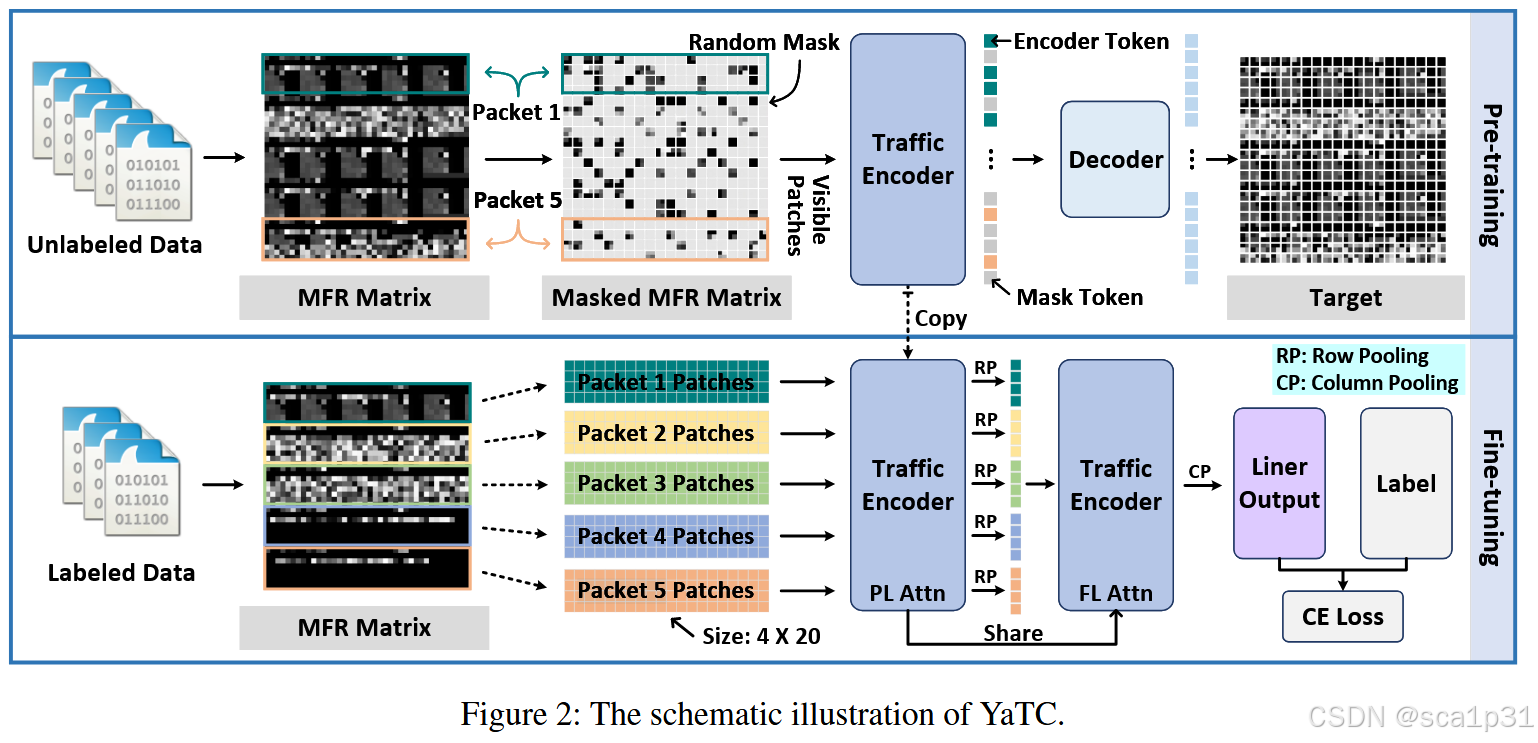
YaTC的预训练阶段使用MAE架构,也就是不对等的encoder-decoder架构来重建MFR中的原始字节。MFR中的patch绝大部分都被随机掩盖掉,只有一小部分patch输入到了模型中。之后,流量encoder提取这部分patch的有效特征,输出encoder的token。最后一个小的decoder用encoder输出的token和随机掩盖后的token进行重建工作,重建MFR的掩盖区域。MAE的训练通过一个重建损失MSE进行,即ground-truth和预测的像素之间的均方误差得到。经过预训练后,流量encoder可以提高特征提取的质量。
预训练不需要是无监督的过程,因此可以使用来自真实场景的大量未标记数据。此外由于预训练过程中高比率的随机掩盖,意味着仅有少数patch可见,因此在预训练过程中不使用包级注意力和流级注意力,而是使用全局注意力。这样可以保证流量encoder能够在包级和流级层面上捕获更细节的信息。
YaTC微调阶段
在下游任务中,将预训练的流量encoder参数加载到流量transformer中的数据包级注意力模块和流级注意力模块中,并用于提取包级和流级的特征。为了进行分类,每个patch的特征在"行pool(RP)和列pool(CP)"中进行均值平均化,用作MFR矩阵的分类特征,这个特征再被展平输入到MLP中,以获得预测分布,然后计算交叉熵损失。并且为了加速收敛并减少模型大小,在两个流量encoder之间共享参数。

















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









