






注意这一篇属于是学习代码随想录的前置课程笔记,刷完这个再去刷代码随想录!
找了好多的教程,感觉目前的C++似懂非懂的,还不是很系统。
先跟着卡哥刷题,后面再跟着阿秀补充理论部分。链接分别如下:
编程语言基础课 | 代码随想录 (programmercarl.com)![]() https://programmercarl.com/qita/language.htmlC++学习路线 | 阿秀的学习笔记 (interviewguide.cn)
https://programmercarl.com/qita/language.htmlC++学习路线 | 阿秀的学习笔记 (interviewguide.cn)![]() https://interviewguide.cn/notes/02-learning_route/02-language/01-C++.html目前的想法是基础课每天刷1节,不知道这个月做得完不,前面的看起来还挺简单哈哈哈哈。接下来每天都会更新刷题的章节,不更新已掌握的,只更新一些理解不了的地方,以希望以后有空解决。
https://interviewguide.cn/notes/02-learning_route/02-language/01-C++.html目前的想法是基础课每天刷1节,不知道这个月做得完不,前面的看起来还挺简单哈哈哈哈。接下来每天都会更新刷题的章节,不更新已掌握的,只更新一些理解不了的地方,以希望以后有空解决。
至于学python还是C++,我个人的思考和阿秀一样,详情参考上面的链接。我觉得python在使用chatgpt的情况下,马上就能掌握基本的数据爬虫用法(至少在数学建模中使用的时候毫无问题)。python在自动驾驶的应用场景太少了,还是C++的应用场景更多,并且为了结合linux的使用,缓解内存压力,我最终决定系统地学习C++。只剩不到一年了,得好好努力!
关于在windows上配置C++编译环境,看这个可以:
基于 VS Code 搭建编程环境——C/C++ 篇 - 知乎![]() https://zhuanlan.zhihu.com/p/77074009注意,他最后生成的是可执行的exe。
https://zhuanlan.zhihu.com/p/77074009注意,他最后生成的是可执行的exe。
以下是这篇文章的目录,终于完结啦!
目录
0.对命名空间的思考【最后学】
为什么要引入using namespace std?可以看这个链接学习一下。
1. A+B问题I
这一节不难,主要需要注意定义头文件
#include<iostream>
using namespace std;这两个直接背下来就行,std是里面的一个库,里面有cin和cout,主要负责数据的输入输出。
最终答案是:
#include<iostream>
using namespace std;
int main(){
int a, b;
while(cin >> a >> b){
int result = a + b;
cout << result << std::endl;
}
return 0;
}2.A+B问题II
++i和i++
++i和i++的执行顺序不一样,前者是先自增后运算,后者是先运算后自增.

同时学习了三种循环语句。
for语句
for(初始化语句;条件判断;操作) {
// 代码块
}
// 示例如下
for(int i = 0; i < n; i++) {
cin >> a >> b; // 接收 a和b的输入
cout << a + b << endl; // 输出结果并换行
}while语句
while 循环中, while(0) 会终止循环, 因为0可以转换成false, false代表条件为假,循环结束。
while(条件) {
// 当条件为真时,就会一直执行
}
// 示例
while (n--) {
cin >> a >> b;
cout << a + b << endl;
}do while语句
do while会先循环再判断。
do {
// 循环体(代码块)
} while (条件判断);
//示例
do {
sum = sum + i; // 将 sum + i的值赋值给sum
i++; // i的值自增
} while (i <= 10);3.A+B问题III
主要涉及条件语句if和两种跳出循环的语句break和continue。
if语句
if (条件为真再执行) {
// 执行代码块
}break语句
break就是用来终止离它最近的while、do while、for语句的,break之后的代码都不会再执行。
#include<iostream>
using namespace std;
int main() {
int a, b;
while (cin >> a >> b) {
if (a == 0 && b == 0) {
// 结束循环
break;
}
cout << a + b << endl;
}
}continue语句
continue也可以用于控制跳出循环,同样的,它也只能出现在for、while和do while循环的内部,只不过它的用法是在执行过程中跳过当前循环迭代的剩余部分,然后继续下一次迭代, 通常用于在某个特定条件下,跳过某些特定的迭代操作,但仍然继续循环。
while (cin >> a >> b)
if (a == 0 && b == 0) {
// 跳出循环
continue;
}
// 不再执行后续操作
cout << a + b << endl;
}4. A+B问题IV
余数操作
这个之前还从来没有注意过取的是余数,可以在这里注意一下这个细节。
int e = 21 % 6;
// 结果是3, 意思是计算两个整数相除所得的余数,参与取余运算的运算对象必须是整数类型累加运算符
按顺序计算,先出现+号就先加,再=。
sum -= i; // 等价于 sum = sum - i;
sum *= i; // 等价于 sum = sum * i;
sum /= i; // 等价于 sum = sum / i;
sum %= i; // 等价于 sum = sum % i;5.A+B问题VIII
用的基本上是前面的知识,但是要注意输出格式
if条件语句的另外写法
if (n != 0) cout << endl;6.数组的倒序与隔位输出
每种数据结构都具有一些特点,我们假设用“班级”这种组织的形式来简单阐述数组的特点:
- 固定大小:数组一旦声明,其大小通常是固定的,不能在运行时动态更改。就好比开设了一个30人的班级,班级大小已经固定,不能再改变班级的规模。
- 相同数据类型: 数组中的所有元素必须具有相同的数据类型,假设这个班都是男生或者都是女生,只能有一种性别存在。
- 连续存储: 数组的元素在内存中是连续存储的,班级里的同学按照顺序就坐,中间没有留空位。
- 下标访问: 数组中的元素通过下标(索引)进行访问,每个人都有一个学号,学号就是自己的座位,这个学号被称为索引,但是数组里的索引是从0开始的,也就是说,第一个元素的索引是0,第二个元素的索引是1,依次类推
vector容器类
os:终于到了大名鼎鼎的vector了。
如果想要使用vector, 必须包含头文件vector
#include <vector>
using std::vector;还有一些定义方式
vector<int> myVector = {1, 2, 3, 4, 5}; // 创建一个包含整数元素的容器并初始化元素
vector<int> myVector(10); // 创建一个包含10个元素的容器,元素为int类型(值被系统默认初始化为0)
vector<int> myVector(10, -1); // 创建一个包含10个重复元素的容器,每个元素的值都是-1vector可以动态调整大小,这种调整是通过vector内置的方法push_back动态添加元素来实现的。
vector<int> myVector = {1, 2, 3, 4, 5};
myVector.push_back(6); // 往容器的最末端添加数字6还有一些函数,我很疑惑这些函数怎么记得下来、、、
myVector.pop_back(); // 删除vector末尾的元素
myVector.clear(); // 清空vector中的所有元素
myVector.empty(); // 判断vector是否不含有任何元素,如果长度为0,则返回真,否则,返回假7.打印正方形
主要涉及二维数组和循环嵌套的问题。
昨天因为一些问题耽误了更新,非常抱歉。但我学会了一个为人处事的原则:
a. 要宽容大度。从人生的长河来看,此时遇到的任何难处都不算什么,年轻气盛的时候总想争个输赢,但是未免伤了和气。如果可以容忍的事情尽量容忍,因为人品低劣的人走不长远。
b. 遇到事情要冷静,任何对话要文字留痕,防止对方变卦
c. 要做勇敢的人。实在是无法容忍,当自己的权利受到侵害的时候,需要敢于发声(前提是你真的拥有这个权利)
d. 不要将鸡毛蒜皮的小事舞到领导面前。能私下解决就私下解决。
e. 不要将同事当真心朋友,同事就是同事,要界限分明。毕竟同事都避免不了竞争,你拿他当朋友,他却计算着你的利益。
f. 不要热衷于替朋友打抱不平,虽然重来一次我还是会这么做。但我告诉自己要智取,不要盲目的一腔热血。
希望自己谨记这次经验教训!做一个踏踏实实的人。
----------------------------------------------------------------------------------------------------------------------分界线
对于这个问题,主要是两个循环,外面循环是行,里面循环是列。
标准答案是将一维的数组推到了二维。
# include <iostream>
using namespace std;
int main(){
int i,j , n;
cin >> n;
for( i = 1; i <= n; i++){
for( j = 1; j <= n; j++){
if( i == 1 || j == 1 || i == n || j == n ){
cout << "*";
}
else{
cout << " ";
}
}
cout <<endl;
}
}
8.平均绩点
这里主要讲了string的使用
string语句
头文件声明
#include <string>
using std::string;下面是声明和初始化string变量
string s1; // 默认初始化,s1是一个空的字符串
string s2 = "hello"; // 初始化一个值为hello的字符串
string s3(5, 'a') // 连续5个字符a组成的串,即'aaaaa'拼接操作
string s1 = "hello";
string s2 = "world";
string s3 = s1 + " " + s2; // 对字符串进行连接,拼接之后的字符串是"hello world", 中间加了空格使用size()获取字符串的长度
int length = s1.size(); // 字符串的长度即字符串中字符的个数,"hello"的长度为5利用char代表字符串类型,用下标访问具体的字符串
char c1 = s1[1]; // 下标从0开始,表示字符串的第一个字符使用empty()来判断字符串是否为空
if (s1.empty()) {
// 如果字符串为空则返回true, 否则返回false
}在使用cin读取字符串的时候,遇到空格就会停止,但有的时候我们想读取完整的一行,这就要求我们的读取不会在空格处停止,这种情况下可以使用到getline(),它会一直读取字符,直到遇到换行符(Enter键)或文件结束符(如果从文件读取)才结束。
写法如下
getline(cin, line);这节题目难点还有很多
float类型和printf语句
是一种浮点类型,可以定义带小数的变量,输出使用printf语句
float sum = 0;
printf("%.2f\n", sum / count);/ 号的特别注意
如果想要输出的时候保留小数,至少需要除号式子中有一个float类型的变量,就像上面这个代码框里一样。
9.句子缩写
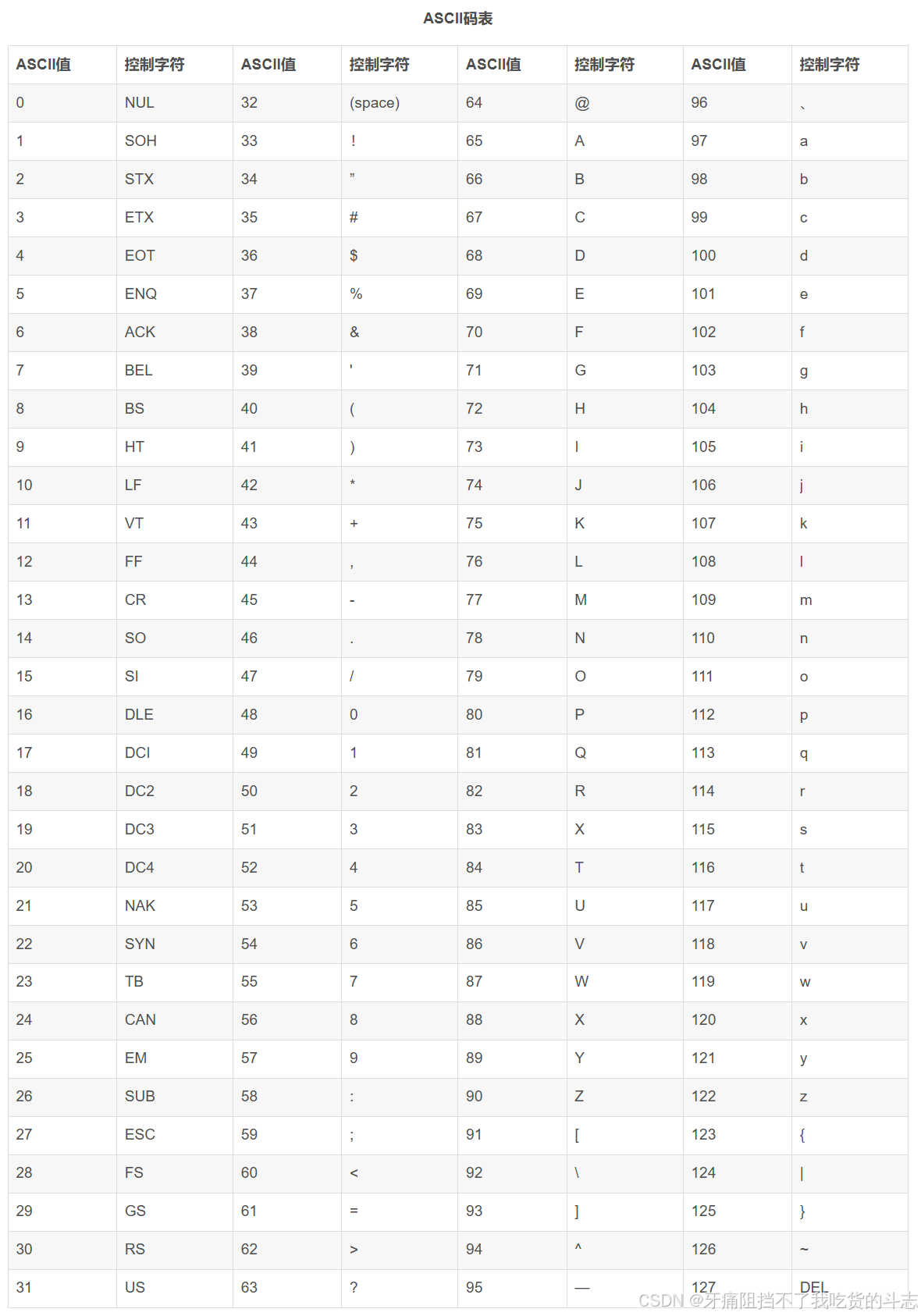
涉及到字符串,以及ASCII码的问题
小写字母从 'a' 到 'z' 对应的ASCII码值是从 97 到 122,而大写字母从 'A' 到 'Z' 对应的ASCII码值是从 65 到 90, 大小写字母之间的差值为32,所以可以通过数学运算将大写字符加上32后转换为小写字符。
ASCII码需要记吗?
getchar语句
这个语句是用来吸收回车符,这样可以继续读取下一行。
#include<iostream>
#include<string>
using namespace std;
int main() {
int n;
string s;
cin >> n;
getchar(); // 吸收一个回车,因为输入n之后,要输入一个回车
while (n--) {
getline(cin, s); // 接收新的一行
string result;
后面略。子函数的写法

上图展示的是标准函数的写法。
// char代表返回类型,changeChar代表函数名称,char a表示函数接收一个字符a作为参数
char changeChar(char &a) {
if (a >= 'a' && a <= 'z') a -= 32;
// 返回类型为char, 最终还要返回a
return a;
}解释如下:
- 返回类型:返回结果是经过转换后的大写字符,所以返回类型为
char - 函数名:可以自定义,这里使用
changeChar作为函数的名称 - 形参列表:之前的形参列表为空,而一般的形参列表通常包括参数类型和参数名称。参数类型表示参数的数据类型,可以是内置数据类型(例如整数、字符、浮点数等)、用户自定义的数据类型。参数名称通常是用来描述参数的有意义的名称,可以在函数体内部使用,这里接收一个字符作为输入,所以形参列表类型为
char, 参数名称可以用a表示, 引用传递&意味着函数可以修改传递给它的参数。
这个指针的地方没有听懂?但我大概看了一下它的意思,应该是函数体里面修改了变量的话,只要加了引用传递&便可以影响实参。
10.链表的基本操作
什么是链表
这一节比较难,我是找了好多资料来看才看懂。可以参考这个书写格式。
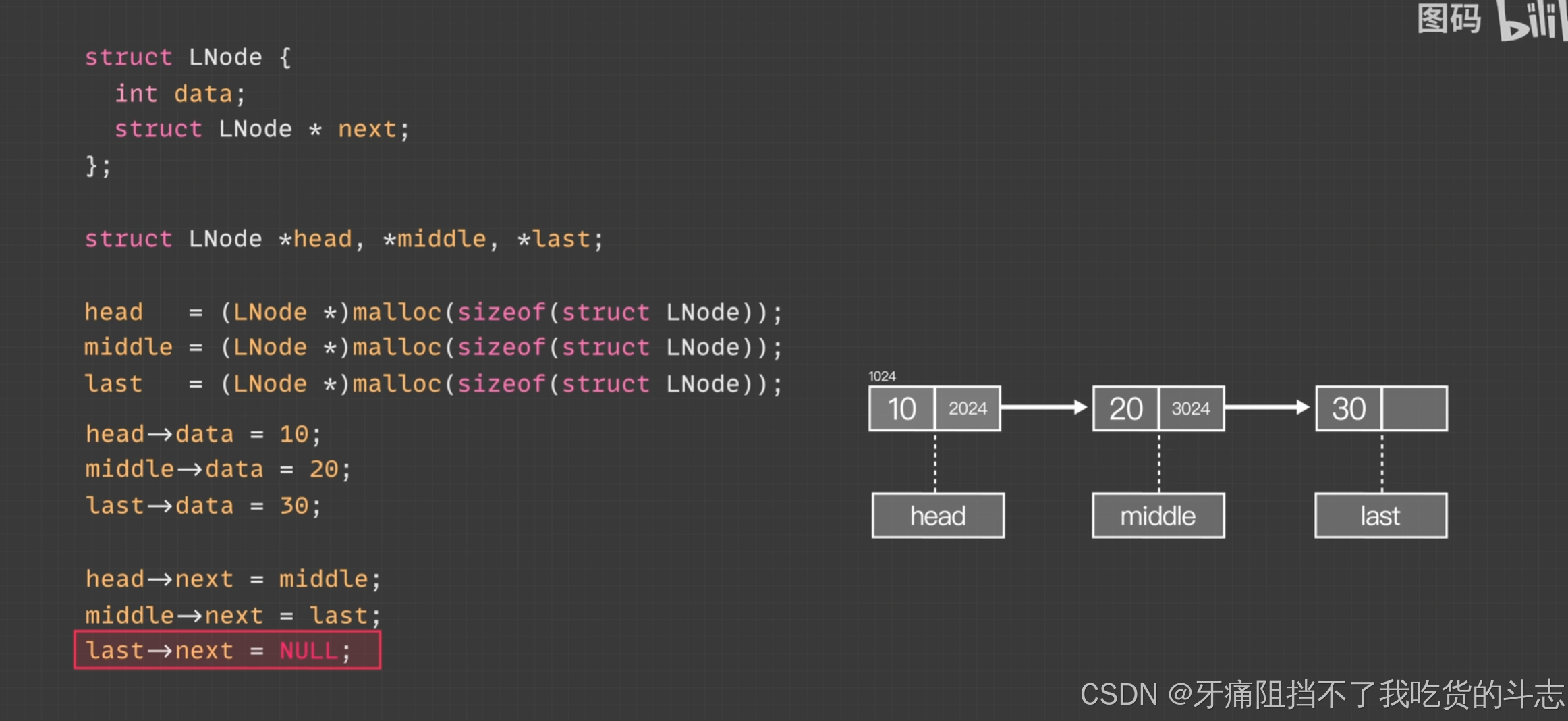
来自:
链表 数据结构与算法,完整代码动画版,附在线数据结构交互式工具_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1ea4y1r75V?spm_id_from=333.788.videopod.sections&vd_source=e36a6897298a11f7d0fa45eb9aec3639需要把这个合集里面关于单链表的全部看完,带头不带头的都要看,才能写得出来题目.
https://www.bilibili.com/video/BV1ea4y1r75V?spm_id_from=333.788.videopod.sections&vd_source=e36a6897298a11f7d0fa45eb9aec3639需要把这个合集里面关于单链表的全部看完,带头不带头的都要看,才能写得出来题目.
链表基本结构如下
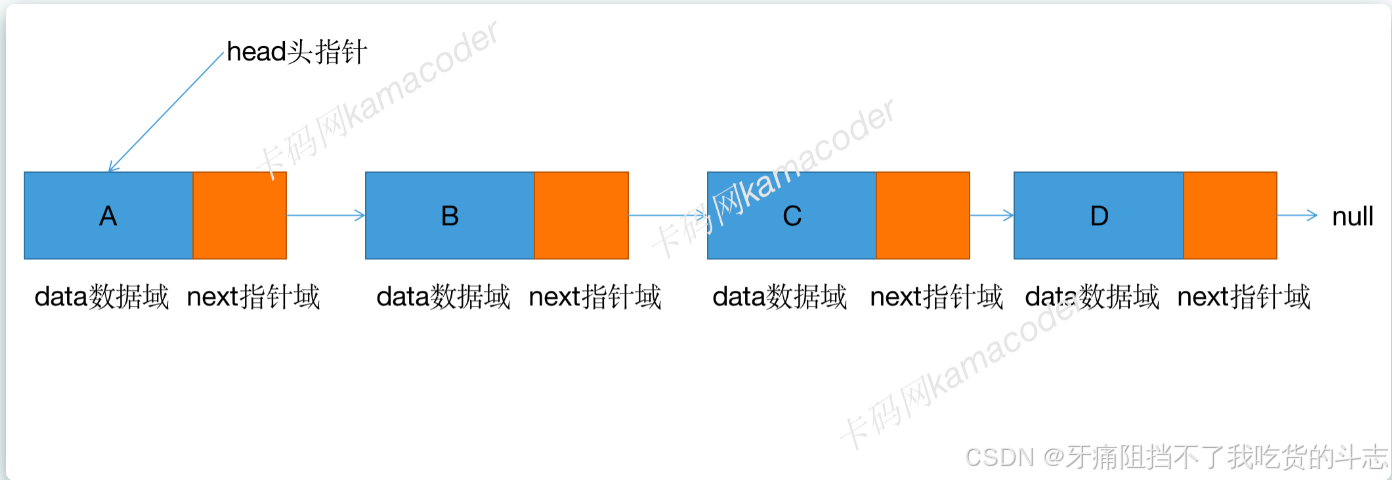
带头与不带头:为了简化链表的插入和删除操作,我们经常在链表的第一个节点前添加一个节点,称为虚拟头节点(dummyNode),头节点的数据域可以是空的,但是指针域指向第一个节点的指针。头节点是为了方便操作添加的,不存储实际数据,头节点不一定是链表必须的
使用结构体struct来定义链表
// 链表节点结构体
struct ListNode {
int val; // 存储节点的数据
ListNode *next; // 下一个节点也是链表节点,所以也是ListNode类型,*表示指针(地址),next是名称
}初始化结构体的方式有很多,这里我们使用构造函数的方式来进行,构造函数的名称与结构体的名称相同,和其他函数不一样的是,构造函数没有返回类型,除此之外类似于其他的函数,构造函数也有一个(可能为空)的参数列表和一个函数体(可能为空)。链表结构体的构造函数代码如下:
ListNode(int x) : val(x), next(nullptr) {}这里的ListNode(int x)表示定义一个接收整数参数 x的名称为ListNode的构造函数(名称和结构体相同),:表示初始化列表的开始,val(x)表示链表数据域的值被初始化为传递的参数 x ,next(nullptr)则表示next指针被初始化为nullptr,表示没有下一个节点。
下面的完整代码定义了一个名为ListNode的结构体,用于表示链表中的一个节点,包含存储节点数据的数据域和存储下一个节点地址的指针域。
// 链表节点结构体
struct ListNode {
int val; // 存储节点的数据
ListNode *next; // 指向下一个节点的指针
// 构造函数,用于初始化节点, x接收数据作为数据域,next(nullptr)表示next指针为空
ListNode(int x) : val(x), next(nullptr) {}
};指针的语法结构
想要声明指针,需要使用*符合,比如下面的代码。
int *ptr; // 声明一个指向整数的指针
// 也可以这样写
int* ptr;指针想要存放某个变量的地址,需要先使用取地址符&获取地址
int x = 10;
int *ptr = &x; // 将指针初始化为变量x的地址想要获取这个地址值,需要使用*符号来访问, 这个过程称为解引用
int value = *ptr; // 获取ptr指针指向的值(等于x的值,即10)指针和数组之间有密切的关系,数组名本质上是一个指向数组第一个元素的指针。
int arr[3] = {1, 2, 3};
int *ptr = arr; // 数组名arr就是指向arr[0]的指针指针还可以执行加法、减法等算术操作,以访问内存中的不同位置。
int arr[5] = {1, 2, 3, 4, 5};
int *ptr = arr; // 指向数组的第一个元素
int value = *(ptr + 2); // 获取数组的第三个元素(值为3)除此之外,还有一个特殊的空指针值,通常表示为nullptr,用于表示指针不指向任何有效的内存地址。
int *ptr = nullptr; // 初始化为空指针new语句
new是一个运算符,它的作用就是在堆内存中动态分配内存空间,并返回分配内存的地址,使用方式一般为指针变量 = new 数据类型, 比如下面的代码
int *arr = new int[5]; // 分配一个包含5个整数的数组的内存空间,并返回一个地址,指针arr指向这个地址比如可以用于创建虚拟头节点
ListNode *dummyHead = new ListNode(0); // 定义了虚拟头结点,dummyNode指向它的地址刷题感想:慢慢有点理解链表了,需要背下来 结构体定义链表的语法。并且注意用if判断来限制cur不能是虚拟头指针(即链表为空),和cur不能指向null(即已经查找到最后一个)
【特别注意】struct后面有分号;
增删查打操作
增:主要思想是使前置节点等于后置节点的后置。cur->next = cur->next ->next
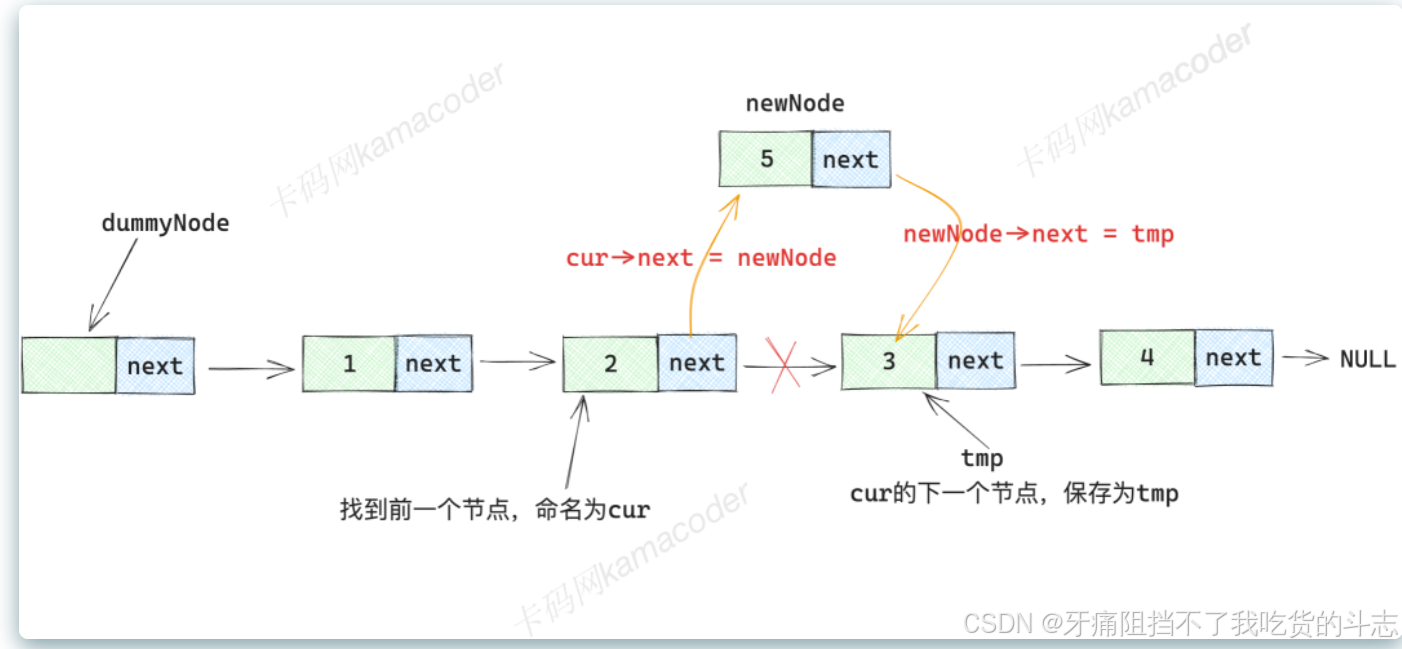
主要步骤:
- 找到要插入的位置的前一个节点,将之命名为
cur, 要插入的位置的下一个节点,将之命名为tmp, 它们之间的关系是cur -> next = tmp - 创建一个新的链表
newNode, 将cur的next指针指向newNode, 即cur -> next = nowNode - 将
newNode的next指针指向tmp, 即newNode -> next = tmp
// 创建了一个新的 ListNode 结构的节点,值为x, 并将其地址赋给指针 newNode
ListNode *newNode = new ListNode(x);
// 创建了一个名为 tmp 的指针,临时存储当前节点 cur 的下一个节点的地址。
ListNode *tmp = cur ->next;
// 将当前节点 cur 的 next 指针更新为指向新节点 newNode,将新节点插入到当前节点后面。
cur->next = newNode;
// 将新节点 newNode 的 next 指针设置为指向之前临时存储的节点 tmp
newNode->next = tmp;删:只需要找到删除节点的前一个节点cur, 并将其next 指针设置为指向当前节点的下下个节点,从而跳过了下一个节点,实现了节点的删除操作。
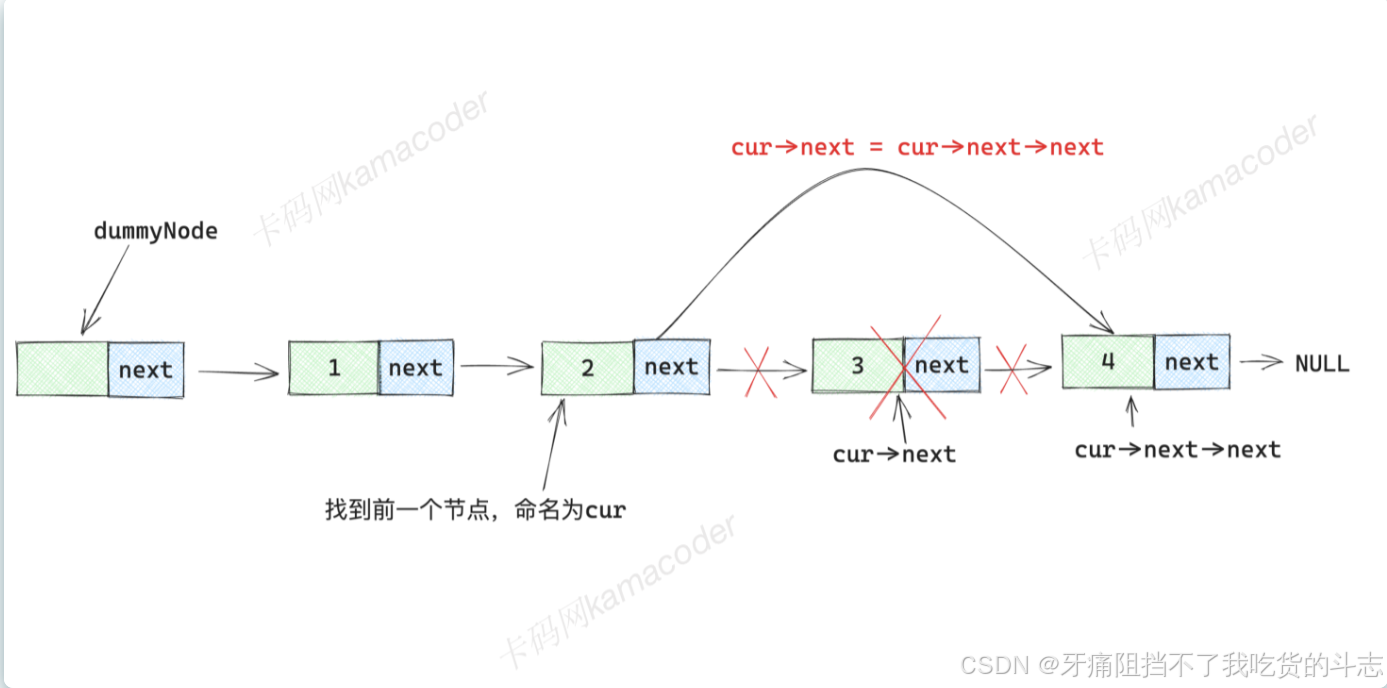
// cur->next 表示当前节点 cur 的下一个节点
// cur->next->next 表示要删除的节点的下一个节点
// 当前节点 cur 的 next 指针不再指向要删除的节点,而是指向了要删除节点的下一个节点
cur->next = cur->next->next;查:需要先设置cur等于虚拟头节点,并开始循环,使cur=cur->next
打:打印链表的话,其实也是承接了查的操作,可以定义为一个函数专门用来打印链表。
// 打印链表
void printLinklist(ListNode* dummyHead) {
ListNode* cur = dummyHead;
while (cur->next != NULL) {
cout << cur->next->val << " ";
cur = cur -> next;
}
cout << endl;
}11.哈希表/散列表
哈希表常使用的数据结构有数组、set集合、map映射。
数组的大小问题
需要特别注意,数组的定义中,[10]指的数组是从0数到9.
int record[26] = {0};像这个地方是从0开始,数到25.
set集合
其实我并没有深究它的原理,我感觉得从集合的基本概念开始学,但是太慢了。这里先留个坑。
目前我是把他当成一个库函数来学习。与set集合相关的有:unordered-set、multiset。这里涉及到红黑树,我也不懂,需要后面恶补。
引入头文件
// 引入<unordered_set>头文件
#include <unordered_set>
// 引入set头文件
#include <set>创建集合
// 创建一个存储整数的无序集合
unordered_set<int> mySet;
// 创建一个存储整数的set
set<int> mySet;
// 创建一个存储整数的 multiset
multiset<int> myMultiSet; 插入元素
// 向集合中插入元素
mySet.insert(1);
mySet.insert(2);
mySet.insert(3);删除元素
mySet.erase(1);find() 方法用于查找特定元素是否存在于集合中,如果 find() 方法找到了要查找的元素,它会返回指向该元素的迭代器,如果未找到要查找的元素,它会返回一个指向集合的 end() 的迭代器,表示未找到。通过比较find()方法返回的迭代器是否等于 end(),可以确定集合中是否有查找的元素。
// 判断元素是否在集合中, 只要不等于end(), 说明元素在集合中
if (mySet.find(i) != mySet.end()) {
}迭代器iterator
迭代器iterator提供了一种类似指针的接口,可以用来遍历访问容器(比如数组、集合)中的元素,并执行各种操作。
可以理解为,迭代器和下标运算符的作用一样,用来访问容器中的元素,并且迭代器可以从一个元素移动到另外一个元素。
迭代器都拥有名为begin()和end()的成员,表示指向第一个元素和最后一个元素的下一个元素的迭代器(尾后迭代器),如果容器为空,则begin和end返回的是同一个迭代器。
可以使用比较运算符来判断两个迭代器是否相等,如果迭代器想要从一个元素移动到另外一个元素,可以使用递增++运算符和递减--运算符,表示向前(后)移动一个位置。
通过解引用*可以获取迭代器所指的对象,下面的示例表示了vector的遍历。
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> myVector = {1, 2, 3, 4, 5};
// 使用迭代器遍历容器
// vector<int>::iterator it 用于创建一个能读取<vector>int 元素的迭代器it,最初指向begin()
// ++it表示迭代器的移动
for (vector<int>::iterator it = myVector.begin(); it != myVector.end(); ++it) {
cout << *it << " "; // 通过解引用获取迭代器所指的对象
}
cout << endl;
return 0;
}map映射
大概看懂了,就是存储的是“键值对”,每pair包含key和value,是一一对应的。
然后区分了三种map
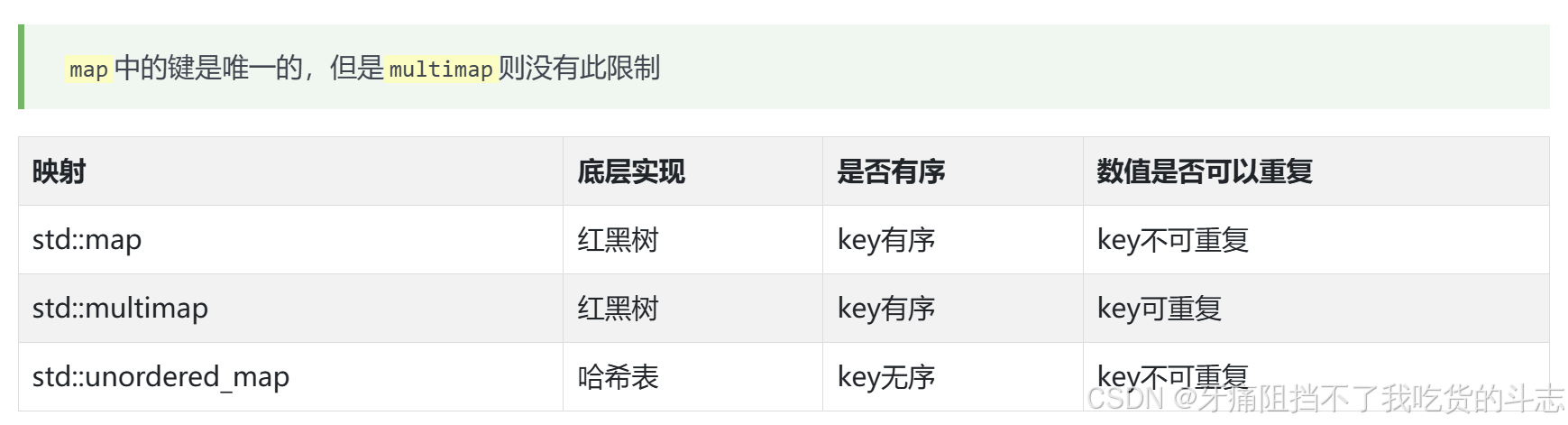
那么怎么使用呢?我还是沿袭了前面set的学法,将其当做一个库函数来处理
头文件:使用映射容器需要引入头文件<unordered_map>或者<map>
// 引入unordered_map头文件,包含unordered_map类型
#include <unordered_map>
// 引入map头文件,包含map类型和multimap类型
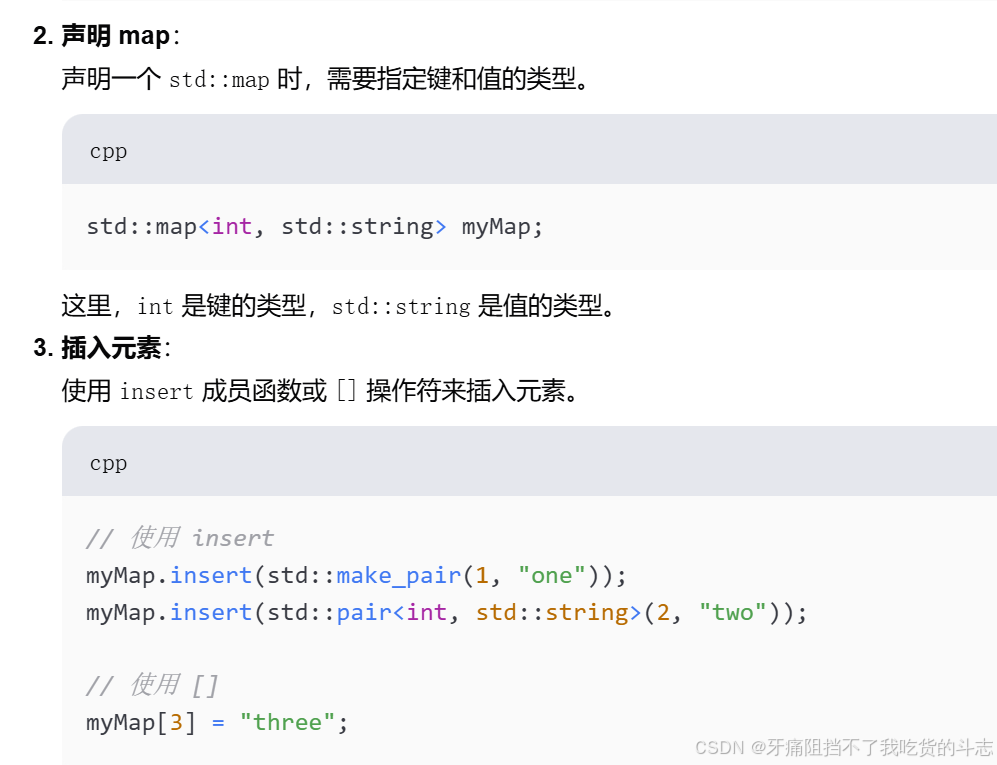
#include <map>初始化:想要声明map映射关系,需要指定键的类型和值的类型。
// 声明一个整数类型映射到整数类型的 无序映射
unordered_map<int, int> uMap;
// 声明一个将字符串映射到整数的`map`,可以这样声明:
map<string, int> myMap;插入元素:想要插入键值对key-value, 需要使用insert()函数或者使用[]操作符来插入。如果键不存在,[]操作符将会创建一个新的键值对,将其插入到map中,并将值初始化为默认值(对于整数来说,默认值是0)。
uMap[0] = 10;
uMap[10] = 0;
myMap["math"] = 100;
myMap["english"] = 80;补充:insert函数
查找某个元素是否在集合里:可以使用find函数来检查某个键是否存在于map中,它会返回一个迭代器。如果键存在,迭代器指向该键值对,否则指向map的末尾。
if (myMap.find("math") != myMap.end()) {
// 键存在
} else {
// 键不存在
}遍历所有键值对:使用范围for循环
for(const pair<int,int> &kv : umap) {
// 检查当前键值对中的值是否等于x
if (kv.second == x) {
cout << kv.first << endl;
// 如果找到了匹配的键值对,将键kv.first输出到标准输出,并换行
flag = false;
break;
}范围for循环-C++11新引入
C++11引入了范围for循环,用于更方便地遍历容器中的元素。这种循环提供了一种简单的方式来迭代容器中的每个元素,而不需要显式地使用迭代器或索引。
for (类型 变量名 : 容器) {
// 在这里使用一个变量名,表示容器中的每个元素
}举例如下:
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 使用范围for循环遍历向量中的元素
for (int num : numbers) {
std::cout << num << " ";
}需要注意的是:范围for循环不会修改容器中的元素,它只用于读取元素。如果需要修改容器中的元素,需要使用传统的for循环或其他迭代方式。
此外,还可以使用auto关键字来让编译器自动推断元素的类型,这样代码会更通用,也就是把int替换为auto。
12.栈
这里只需要理解一下什么是栈:栈的操作实际上和洗盘子的过程是类似的,洗盘子的过程中,会拿出待清洗那一摞盘子的最顶端的那个盘子,清洗之后将其放在已清洗区域,这对于待清洗盘子来说是出栈,对于已清洗区域来说,是入栈(进栈),具体的过程可以看下面的图示
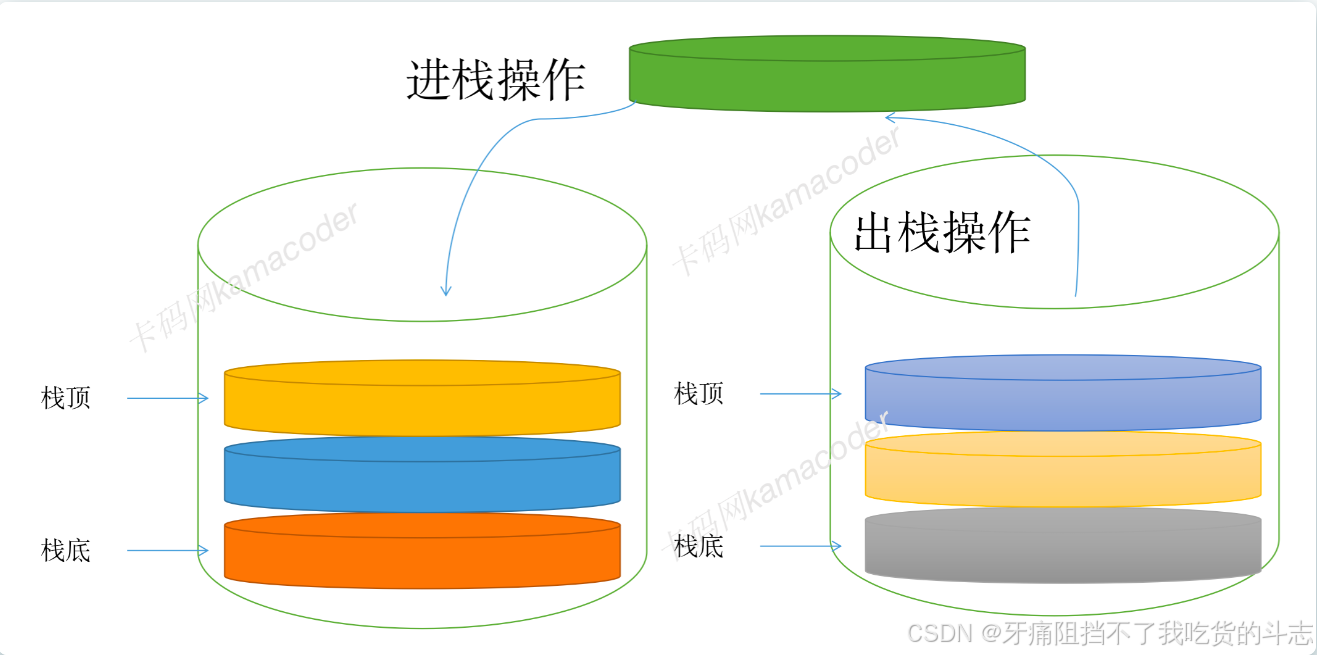
栈这种结构只能在一侧(栈顶那一侧)进行插入和删除操作,而且是后进先出LIFO(Last in first out-后进入栈的元素离栈顶比较近,先出来),允许进行插入和删除的那一端是栈顶,与之对应的另一端是栈底, 如果一个栈不包含任何元素,这个栈被称为空栈。
它的操作我也把他简化了,也当做库函数来学习。
添加头文件
#include <stack> // 引入stack头文件初始化:通过stack数据类型 栈名称这样的形式来创建一个栈并进行操作了
stack<int> st; // 创建一个int类型的栈栈的常用操作主要有以下几种:
empty(): 判断栈是否为空栈,如果为空栈返回true, 否则或者falsepush(): 进栈操作,将新的元素放入到栈中,新的元素成为栈顶元素。pop(): 出栈操作,栈顶元素从栈中离开top(): 获取栈顶元素,但是不会移除它size(): 获取栈的长度,即栈中元素的数量
st.push(1);
st.push(10);
st.push(100); // 往栈中添加元素,现在栈底元素是1,栈顶元素是100
st.pop(); // 移除栈顶元素100,新的栈顶元素是10
int topNumber = st.top(); // 获取栈顶元素10
bool isEmpty = st.empty(); // 如果栈为空,返回true;否则返回false
int stackSize = st.size(); // 获取栈的长度(元素数量)需要特别注意要判断是否是空栈,不然就会报错。
// 如果指令为1,并且栈不为空的话,才弹出栈顶元素。
if (opt == 1 && !st.empty()) st.pop();13.队列
队列,顾名思义,和排队的队列结构是类似的,在排队的过程中,想要加入队列,需要在队伍的最后一位(也被称为队尾)入队,想要离开队列,需要从队伍的第一位(也被称为队头)出队。
我把它理解为打保龄球,先进先出,后进后出。

从图中可以看出,队列在队尾那一侧进行插入操作(入队),在队头那一侧进行删除操作(出队),而且是先进先出FIFO(最先进入队列的元素将首先被移除)。
和前面的栈一样的操作,非常类似。
定义头文件:
// 引入queue头文件
#include <queue>初始化队列
queue<string> q; // 创建一个字符串类型的队列队列的常用操作主要有以下几种:
empty(): 判断队列是否为空,如果队列为空返回true, 否则返回falsepush(): 入队操作,将新的元素添加到队列的尾部。pop(): 出队操作,移除队列的头部元素。front(): 访问队列的头部元素,但不会将其移除。size(): 获取队列的长度,即队列中元素的数量。
q.push("Jack");
q.push("Mike"); // 入队了两个名称字符串
q.pop(); // 移除队列头部的元素
string name = q.front(); // 获取队列头部的元素但是不会将其移除
bool isEmpty = q.empty(); // 如果队列为空,返回true;否则返回false
int queueSize = q.size(); // 获取队列中元素的数量14.继承和类
封装类
封装类时,隐藏对象中一些不希望被外部所访问到的属性或方法。
- 将对象的属性名,设置为
private,只能被类所访问 - 提供公共的
get和set方法来获取和设置对象的属性
class Circle {
// 私有属性和方法
private:
int radius; // 将圆的半径设置为私有的
// 公有属性和方法
public:
// setXX方法设置属性
void setRadius(int r) {
// 对输入的半径进行验证,只有半径大于0,才进行处理
if (r >= 0) {
radius = r;
} else {
cout << "半径不能为负数" << endl;
}
}
// getXXX方法获取属性
int getRadius() {
return radius;
}
};构造函数
类的构造函数和之前结构体的构造函数类似,用于初始化对象的成员变量,构造函数与类同名,没有返回类型,并且在对象创建时自动调用。其基本语法包括:
- 函数名:与类名相同
- 参数列表:可以有零个或多个参数,用于在创建对象时传递初始化信息。
- 函数体: 用于执行构造函数的初始化逻辑。
const string& personName表示对string类型对常量引用,你可以传递字符串参数,但是不能在函数中修改这个参数的值。
class Person {
private:
int age;
string name;
public:
// 默认构造函数
Person() {
age = 20;
name = "Tom"
}
// 带参数的构造函数
Person(int personAge, const string& personName) {
age = personAge;
name = personName
}
}
int main() {
// 使用默认构造函数创建对象
Person person1;
// 使用带参数的构造函数创建对象
Person person2(20, "Jerry");
return 0;
}此外,还有构造函数的成员初始化列表写法,这种写法允许在进入构造函数主体之前对类成员进行初始化,比如下面的示例。
Person(int personAge, const string& personName) : age(personAge), name(personName) {
}在上面的代码中, Person 类的构造函数接受一个 string 类型的参数 persnName和一个int类型的参数personAge,并通过成员初始化列表初始化了 成员变量。在这里,: age(personAge), name(personName) 表示将 personAge 的值赋给 age 成员变量, 将 personName 的值赋给 name , 从而完成了成员变量初始化。
继承
假设,我们有一个图形类Shape, 它具有一个属性和一个方法,属性为类型,方法为求图形的面积
class Shape {
protected:
string type; // 形状类型
public:
// 构造函数
Shape(const string& shapeType) : type(shapeType) {}
// 求面积的函数
double getArea() const {
return 0.0;
}
// 获取形状类型
string getType() const {
return type;
}
};在上面的代码中,getArea函数使用const用来修饰,是用来表示该函数不会修改对象的状态,使用const能保证对对象的访问是安全的。
double getArea() const {
// 不会修改对象的状态
return 0.0;
}要想实现继承,我们还需要一个关于圆的类Circle,它继承自Shape类。下面的示例代码中,图形类拥有shape属性和getArea、getType方法,而子类在父类这些属性和方法的基础上新增了radius属性和getRadius方法,并且在子类和父类中都有getArea这个方法,这被称为方法的重写,方法的重写需要override关键字,其意思是子类重写父类的方法,并提供自己的实现。
// Circle 类,继承自 Shape
class Circle : public Shape {
private:
int radius; // 圆的半径
public:
// 构造函数, 调用Shape的构造函数,初始化了类型为"circle"
Circle(int circleRadius) : Shape("Circle"), radius(circleRadius) {}
// 重写基类的方法
double calculateArea() const override{
return 3.14 * radius * radius; // 圆的面积公式
}
// 获取半径
int getRadius() const {
return radius;
}
};多态-虚函数
多态常常和继承紧密相连,它允许不同的对象使用相同的接口进行操作,但在运行时表现出不同的行为。多态性使得可以使用基类类型的指针或引用来引用派生类的对象,从而在运行时选择调用相应的派生类方法。
C++中实现多态性的方法是通过virtual虚函数
class Shape {
public:
virtual double calculateArea() const = 0;
};
class Circle : public Shape {
private:
int radius;
public:
double calculateArea() const override {
return 3.14 * radius * radius;
}
};
class Rectangle : public Shape {
private:
int width;
int height;
public:
// 构造函数,用于初始化 width 和 height
Rectangle(int w, int h) : width(w), height(h) {}
// width * height 的结果是整数,但 calculateArea 方法的返回类型是 double
// 为了确保结果是一个浮点数,使用 static_cast<double> 将其显式转换为 double 类型
double calculateArea() const override {
return static_cast<double>(width * height);
}
};这里使用virtual在父类中定义了一个虚函数,而= 0表示这是一个纯虚函数,即定义的函数在基类中没有实现,但是要求它的派生类都必须提供这个函数的实现,这种抽象的方法使得 Shape 类成为一个抽象基类,不能被实例化,只能被用作派生其他类的基类。
然后两个派生类 Circle 和 Rectangle则是重写了 calculateArea 方法,它们提供了各自的实现,有着不同的计算逻辑。
int main() {
std::vector<Shape*> shapes;
shapes.push_back(new Rectangle(4, 5));
shapes.push_back(new Circle(3));
for (const Shape* shape : shapes) {
std::cout << "Area: " << shape->calculateArea() << std::endl;
}
return 0;
}之后我们创建了一个容器shapes,包含不同类型的图形对象,然后循环遍历该容器并为每一个shape对象调用 calculateArea 方法,尽管方法名称相同,但实际调用的方法是根据对象的类型动态确定的,这其实就是多态的概念。
对于vector定义为指向类的时候为什么要定义指针形式。
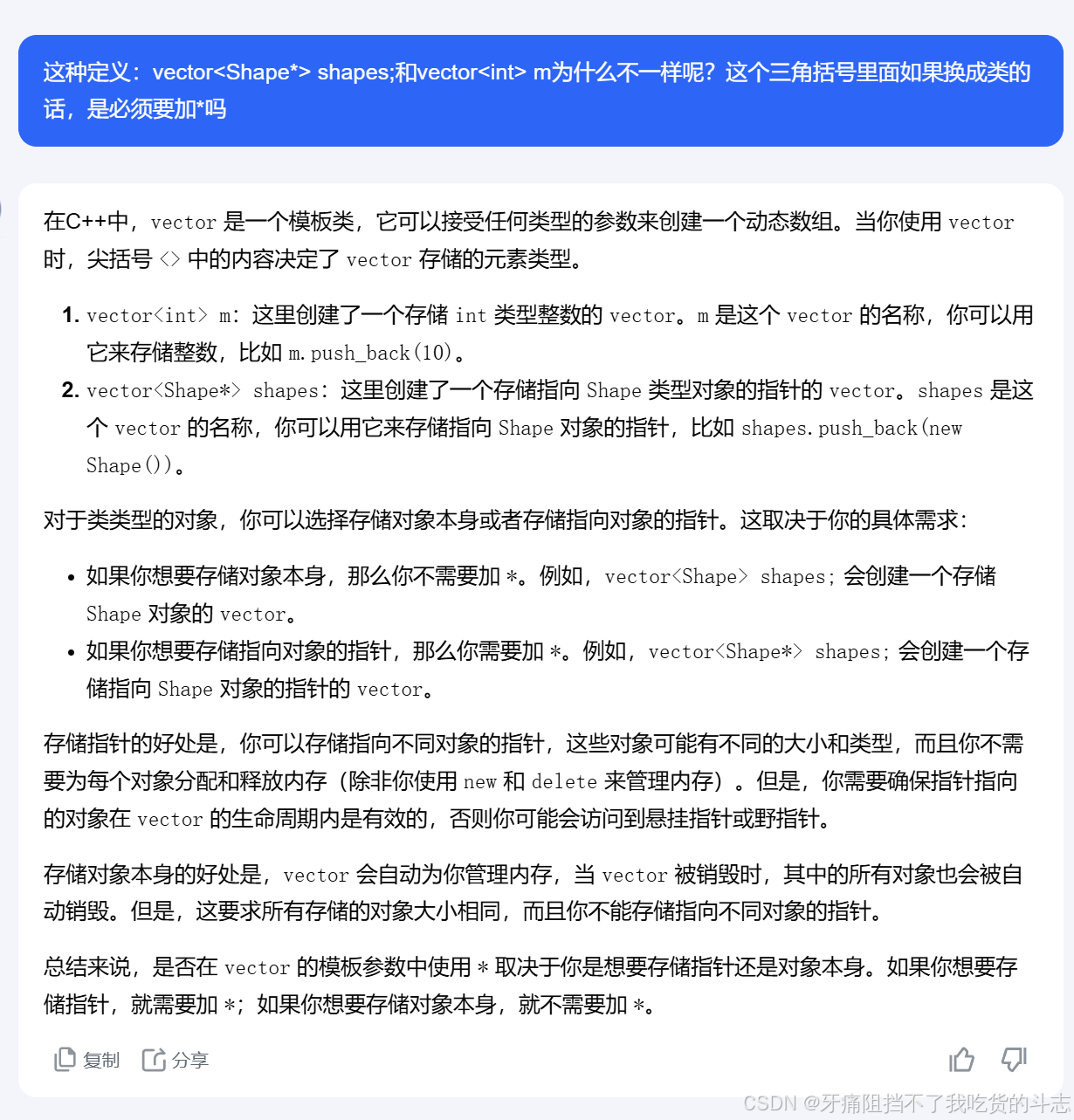
为什么要使用new来创建对象,因为你此时在创建对象!必须要分配内存。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









