




系列文章目录
什么是 Cloud Run
Cloud Run 是一项完全托管的服务,它允许用户通过编写任何编程语言的代码并将其容器化,然后将容器镜像部署到 Google Cloud 上来运行应用程序。您无需创建集群或管理基础设施。
运行容器的实例可根据负载情况自动扩展,在不处理时将实例数量缩减为 0。
由于可以将应用程序从容器镜像中部署出来,因此具有很高的执行环境灵活性,应用场景广泛。
您可以参考官方文档中介绍的一些使用场景,例如网站和移动后端等(请参阅官方文档)。
此外,Cloud Run 基于开源软件 Knative(请参阅Knative),后者可以在 Kubernetes 上构建无服务器计算基础架构。
Cloud Run 的基础知识
两种使用方法
Cloud Run 提供了两种使用方式:Cloud Run 服务和Cloud Run 任务。有时它们也会被分别称为 Cloud Run (services) 和 Cloud Run (jobs)。
可以理解为在作为 Google Cloud 产品之一的“Cloud Run”中,可以创建“Cloud Run 服务(services)”和“Cloud Run 任务(jobs)”这两种资源。
本文主要介绍 Cloud Run 服务。
Cloud Run 服务 (services)
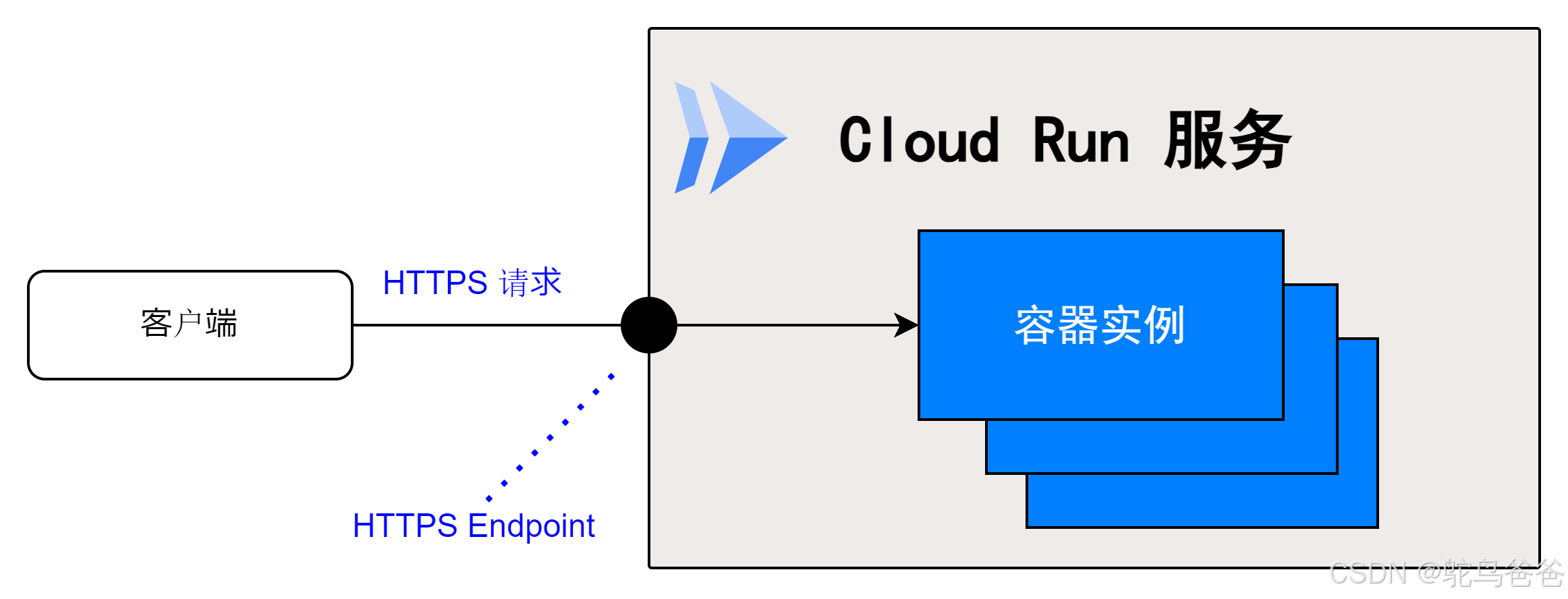
在Cloud Run服务中,只需部署容器镜像,即可获得容器运行环境(容器实例)和接收HTTPS请求的端点。
它用于接收请求并返回响应的网站和API接口等场景。
- 参考资料:资源模型
Cloud Run 任务 (jobs)
在 Cloud Run 任务中,可以使用容器实例来运行用户编写的代码,而无需以 HTTP 请求为触发点,而是作为 任务 来执行。
任务可以在任意时间点执行,并且通过组合多个容器实例运行,可以实现超过60分钟的任务执行或并行处理。
如果您希望使用高效的资源管理方式进行批处理,并且选择一种无服务器的容器执行环境,那么Cloud Run将是一个合适的选择。
有关 Cloud Run jobs 的更多信息,请参阅以下文章。
动态缩放
为了处理通过HTTPS端点接收到的请求,Cloud Run服务会自动扩展容器实例。
容器实例默认可以扩展到最多 1000 个,当没有请求时,实例数量会缩减至 0 个。
服务冗余
Cloud Run 服务将在特定区域内创建,并且为了实现高可用性和故障转移,该服务会自动复制到区域内的多个可用区。
Cloud Run 是一种“区域性服务”。这意味着你可以选择使用哪个区域,但不需要选择具体的可用区。换句话说,用户无需关心可用区的分配,系统会自动进行合理的负载均衡,并且能够自动应对可用区出现的故障。
- 参考资料:为云基础设施中断设计灾难恢复
部署
用于部署的容器映像。
部署到 Cloud Run 的容器镜像应存储在 Google Cloud 的托管容器注册表中,即 Container Registry 或 Artifact Registry。
您也可以使用其他项目中的容器镜像。
通过使用无服务器的CI/CD平台——Cloud Build,当代码推送到Git仓库时,也可以实现持续部署到Cloud Run(参考)。
容器要求。
要在Cloud Run上运行的容器需要满足一些要求。
有关详细要求,请参阅官方文档。
- 容器映像中的可执行文件必须针对 Linux 64 位编译。
- 需要监听地址为 0.0.0.0 的请求,端口为请求发送目标端口(默认端口为 8080)。
- 从收到请求开始,需要在指定的超时时间内返回响应。
流量迁移和回滚
部署或重新配置服务时,会创建一个新的版本。
创建新版本时,可以选择是立即还是分阶段将所有流量迁移到现有版本。
此外,您还可以在多个版本之间分配流量,或者回滚到早期版本(参考:说明文档)。
构成
端点 URL
默认情况下,Cloud Run 服务使用 *.run.app 域的唯一子域作为服务的 HTTPS 终端端点 URL。
当你部署一个 Cloud Run 服务时,会生成两种类型的网址:确定性网址(Deterministic URL) 和 非确定性网址(Non-deterministic URL) 。前者是根据服务名称和区域唯一确定的网址,而后者则包含随机哈希值,其具体网址在部署之前是不确定的。
# Deterministic URL 格式
https://{服务名}-{Project ID}.{Region}.run.app
# Non-deterministic URL 格式
https://{服务识别子}.run.app
您还可以使用 全球外部HTTPS负载均衡器或 Firebase Hosting 来设置自定义域。
- 参考 : 通过 HTTPS 请求进行调用
- 参考:映射自定义网域
容器实例的最大和最小数量
动态伸缩的最大实例数和最小实例数都可以预先设置。
最大实例数量默认为 100,上限是 1000,并且可以申请提升上限。
最小实例数默认为 0,在没有请求时,实例数量会缩减至 0。
冷启动及应对措施
当Cloud Run服务接收到请求而实例数量为0时,启动实例会花费一定时间,导致处理延迟。这种情况被称为冷启动。
通过将最小实例数设置为1或更多,可以保持容器实例处于预热状态(随时可调用的状态),从而能够立即处理请求。
如果最小实例数设置为1或更多,那么指定数量的容器实例将始终处于空闲状态并运行,即使它们没有处理请求,也会产生费用。
不过,处于空闲状态的实例所产生的费用比实际处理请求时的费用要低。具体费用请参阅价格表。
以下文章进一步探讨了冷启动及其应对措施。
- Cloud Run 的冷启动(待续)
- Cloud Run 最小实例数(待续)
Startup CPU boost
为了应对冷启动问题,即从零规模启动容器或在请求量上升需要扩容时快速启动容器,存在一种名为“启动CPU增益”(Startup CPU boost)的功能。
文将对此进行详细说明。
- Cloud Run 的 Startup CPU boost 解说(待续)
CPU 和内存
在部署服务时,您可以设置分配给 Cloud Run 容器实例的 CPU 数量和内存容量的上限。部署完成后,您仍然可以进行修改。
CPU 的数量决定了可分配的内存容量范围。
| CPU(个) | 内存容量 |
|---|---|
| 1 未满(最小 0.08) | 128 MiB ~ 512 MiB(CPU 为 0.08) |
| 1 | 128 MiB ~ 4 GiB |
| 2 | 128 Mib ~ 8 Gib |
| 4 | 2 GiB ~ 16 GiB |
| 6 | 4 GiB ~ 24 GiB |
| 8 | 4 GiB ~ 32 GiB |
请求超时
您可以设置处理 Cloud Run 服务端点收到的请求的可用时间。
默认值为 300 秒,可设置范围为 1~3600 秒。
参考:设置请求超时(服务)
每个容器实例的最大同时请求数
您可以设置一个容器实例可同时处理的请求数。
默认值为 80,可设置的范围为 1 到 1000。
始终分配CPU资源的Cloud Run服务
始终分配 CPU 云运行服务
通过将Cloud Run服务配置为“始终分配CPU”,即使在没有请求的情况下,也可以为容器实例分配CPU,从而执行短期的后台任务和异步处理任务。
通常情况下,Cloud Run服务仅在处理请求时分配CPU,并根据分配的时间收费。但如果选择始终分配CPU,则会从容器实例启动到生命周期结束都分配CPU,并按照整个生命周期进行收费。不过,这种情况下,单价会相对便宜一些(具体请参阅价格表)。
至于是否应该启用“始终分配CPU”的设置,可以参考 Recommender 提供的建议。Recommender会基于过去一个月内Cloud Run服务的流量情况,推荐在能够降低费用的情况下启用该设置。
- 相关资料:CPU 分配(服务)
- 相关资料:使用 Recommender 进行优化
容器执行环境(世代)
在选择Cloud Run的容器运行环境时,可以选用第一代或第二代环境。默认设置下,Cloud Run服务将使用第一代运行环境。
不同代际的特性和适用场景如下:
- 参考 : 执行环境简介
| 世代 | 特点 | 使用场景 |
|---|---|---|
| 第 1 代 | ・高速冷启动 | ・当预计会出现对 Cloud Run 服务的突发流量时。 ・应用程序容易受到冷启动影响时。 ・对 Cloud Run 服务没有持续流量,并且容器实例数量经常缩至零时。 ・希望使用少于 512 MiB 的内存(第 2 代最低为 512 MiB)。 |
| 第 2 代 | ・支持网络文件系统 ・完全兼容 Linux(所有系统调用、命名空间和 cgroup 均可用) ・CPU 和网络性能提升 | ・当应用程序需要使用网络文件系统时。 ・对 Cloud Run 服务存在持续流量,并且可以接受稍微慢一些的冷启动时。 ・需要高性能 CPU 和网络的工作负载时。 ・ 需要使用第一代不支持的操作系统的系统调用时(参考) ・需要使用 Linux 的 cgroup 功能时。 |
服务联动(触发)
在Cloud Run服务中,除了通过HTTPS请求接收客户端调用外,还支持使用gRPC和WebSocket进行通信,以及其他Google Cloud服务的调用。
你可以利用Google Cloud的多种服务来进行调用,例如Pub/Sub、Cloud Scheduler、Cloud Tasks、Eventarc和Workflows等。
网络访问限制
对 Cloud Run 服务的连接
默认情况下,在网络层面上,可以从任何来源访问 Cloud Run 服务。
通过更改上行(内向)设置,可以对访问来源进行三级限制。
- 参考 : 限制 Cloud Run 的网络入站流量
| 设定名 | 允许访问的来源。 |
|---|---|
| 内部 (Internal) | • 内部应用程序负载均衡器 • VPC Service Controls 边界内的资源 • 同一项目的 VPC • Eventarc、Pub/Sub、工作流 |
| 内部 (Internal) 与 Cloud Load Balancing | • 内部(Internal)被允许的来源 • 外部应用程序负载均衡器 |
| 全部 (All) | • 全部 |
Cloud Run 服务与 VPC 网络的连接
与GKE集群等不同,Cloud Run服务是在VPC网络之外创建的,因此默认情况下无法通过私有IP(内部IP)访问VPC中的资源。
通过使用无服务器VPC访问或直接VPC出口(Direct VPC Egress) 功能,可以使用专用IP访问VPC资源。
以下是介绍无服务器VPC访问和直接VPC出口的文章:
- Cloud Run 的 Direct VPC Egress 解说(待续)
认证
私有服务的认证
在应用程序级别,Cloud Run 服务默认会部署为私有。
对于私有服务,在请求时会使用IAM认证信息来调用服务。也就是说,没有持有IAM认证信息的人或程序发出的请求将不会被接受。
在从其他 Google Cloud 服务调用 Cloud Run 服务时,需要使用具有 Cloud Run Invoker(roles/run.invoker) 角色或拥有同等权限的自定义角色的服务账户进行认证。
Workload Identity 联合还能使用支持 OpenID Connect (OIDC) 或 SAML 2.0 的外部身份供应商进行身份验证。
- 参考资料:身份验证概览
允许公共访问
如果部署的服务是公开API或网站,请允许公开访问。
通过控制台或命令行界面(CLI),只需为 allUser 成员类型分配 Cloud Run Invoker(roles/run.invoker) 角色,即可允许未认证的服务调用。
- 参考资料:允许公开(未通过身份验证)访问
用户认证
如果您希望仅允许经过授权的最终用户访问服务,请使用 Identity Platform。
Identity Platform 是一个独立的 Google Cloud 产品,与 Cloud Run 是不同的产品。
通过 Identity Platform,可以实现基于电子邮件和密码、电话号码,以及 Google、Facebook、GitHub 等社交提供商或自定义认证机制的用户认证。
- 参考 : Identity Platform
费用
费用体系
在Cloud Run中,根据不同的情况会有不同的计费方式:一种是在处理请求时才分配CPU,另一种是始终分配CPU。
- 参考 : Cloud Run 价格
Cloud Run 服务在处理请求期间分配 CPU 的情况
在容器实例处理请求期间,所分配的CPU和内存使用时间按100毫秒的粒度进行计费。
如果最小实例数设置为1或以上,则这些实例即使处于空闲状态也会产生费用。
此外,对于部署的Cloud Run服务的请求数量,每100万次请求按单位计费。
| CPU | 内存 | 请求数 | |
|---|---|---|---|
| 免费额度 | 每月前180,000 vCPU秒 | 每月前360,000 GiB秒 | 每月前200万次请求 |
| 标准费率 | 每vCPU秒0.00002400美元 闲置状态下每vCPU秒0.00000250美元(当最小实例数为1或以上时) | 每GiB秒0.00000250美元 闲置状态下每GiB秒0.00000250美元(当最小实例数为1或以上时) | 每100万次请求0.40美元 |
| 承诺使用折扣 | 每vCPU秒0.00001992美元 | 每GiB秒0.000002075美元 | 每100万次请求0.332美元 |
*以上数据为2023年4月东京地区的信息。
vCPU秒:单个vCPU在一个实例上运行1秒的时间。
GiB秒:内存容量为1GiB的实例运行1秒的时间。
闲置状态:保持最低实例数处于温运行状态。
始终分配 CPU 的 Cloud Run 服务
如果始终分配 CPU,那么就不会按照请求次数来计费,而是按照 CPU 和内存的使用时间来计费。也就是说,在容器实例启动到终止期间,资源使用费是持续产生的。
由于资源的永久性分配,单位成本相对较低。
以下为不同资源分配的成本(基于2023年4月东京地区的数据):
| CPU | 内存 | |
|---|---|---|
| 免费额度 | 每月前 240,000 vCPU 秒 | 每月前 450,000 GiB 秒 |
| 标准费率 | $0.00001800 / vCPU 秒 | $0.00000200 / GiB 秒 |
| 预定使用折扣 | $0.00001494 / vCPU 秒 | $0.00000166 / GiB 秒 |
请注意:以上信息适用于东京地区,截至2023年4月。
与其他服务的比较
计算产品概念
谷歌云提供的各种计算产品(为程序运行提供平台的产品,如计算引擎、GKE、Cloud Run 等)在构建灵活性和运维负荷方面各有不同。
例如,计算引擎是一种虚拟服务器服务,可以自由定制操作系统和中间件等。这虽然提供了较高的灵活性,但同时也会增加运行负载。
相比之下,Cloud Run 在灵活性和运行负载方面处于计算产品的中间位置。
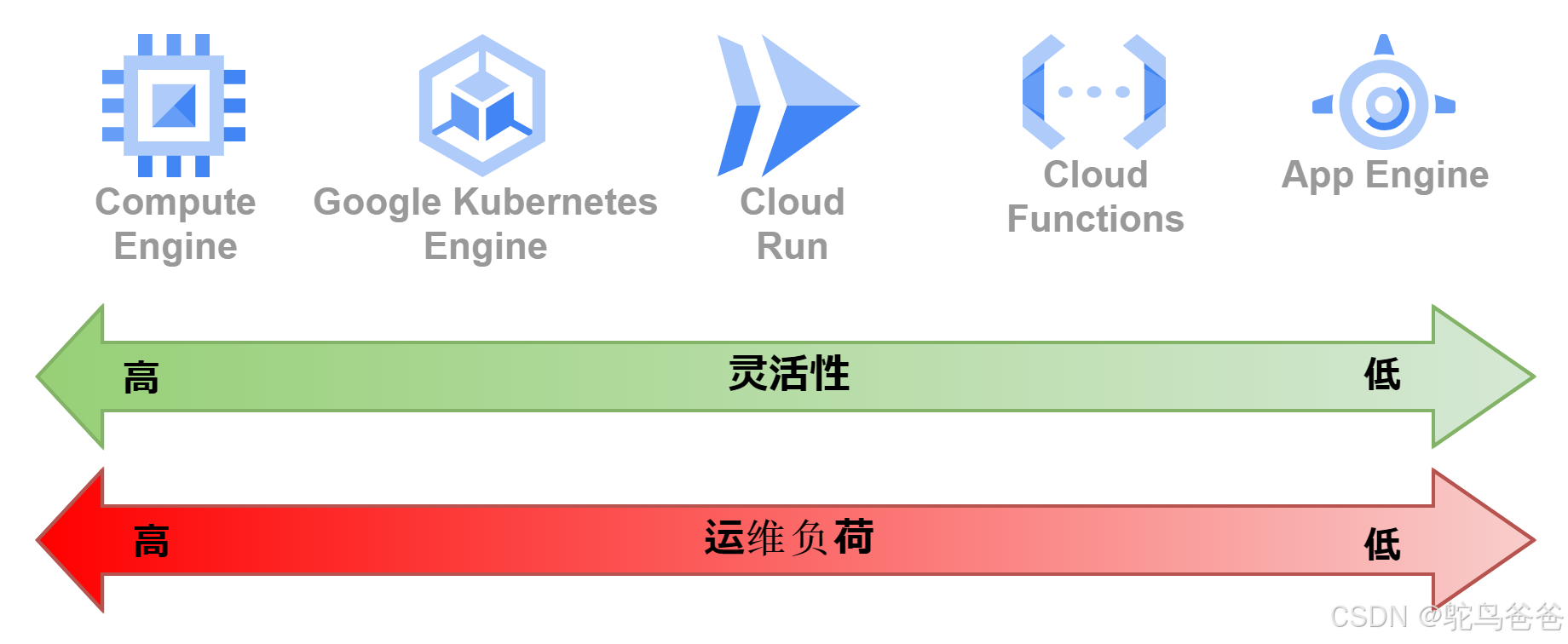
选择合适的计算服务时,需考虑所需灵活性及希望减轻的运行负荷。例如,某些场景可能更需要高度灵活的定制,而其他场景则可能更倾向于减少管理开销。
通过综合考量这些因素,可以选择最适合特定需求的计算服务。
关于如何选择计算服务的方法,下文将进一步探讨。本文将重点介绍 Cloud Run 的特点,同时也推荐您阅读相关文章以获得全面的理解。
- Google Cloud 计算产品比较(待续)
Cloud Run 和 Compute Engine 的区别
Compute Engine (GCE) 是 Google Cloud VPC 内提供的一种 IaaS(基础设施即服务)产品,允许用户构建虚拟机。
在所有的计算产品中,GCE 提供了最高的灵活性,如果某些组件可以部署在其他产品中,同样也可以部署在 GCE 上。
不过,在使用 GCE 时,用户需要自行构建和管理从虚拟机操作系统开始的一切内容。
此外,由于它并不是像 Cloud Run 这样的无服务器架构,因此即使虚拟机在闲置时没有执行任何操作,您仍然会被持续计费。
有关 Compute Engine 的更多信息,请参考以下文章。
- Compute Engine 彻底解说(基础篇)(待续)
Cloud Run 和 Google Kubernetes Engine 之间的区别
Google Cloud 的代表性容器服务 Google Kubernetes Engine (GKE) ,要求用户自行管理部署容器的 Kubernetes 集群。然而,与全托管的 Cloud Run 相比,GKE 允许用户更加灵活地配置操作系统、CPU、GPU、磁盘、内存和网络等。
此外,GKE 还提供了一种称为 Autopilot 模式的功能,允许用户将 Kubernetes 集群的大部分管理工作交给谷歌云来处理。
Cloud Run 与 GKE 的主要区别如下:
- 当没有请求时,GKE 无法缩放至零实例,而 Cloud Run 则可以。
- GKE 支持复杂配置,例如微服务架构。相比之下,Cloud Run 仅支持部署单个容器镜像。
- GKE 可在 VPC 中运行,这使得它能够轻松地直接访问 VPC 内的资源。而使用 Cloud Run 时,如果需要与 VPC 内的资源通信,则需要进行额外的配置,如设置无服务器 VPC 访问。
尽管 Cloud Run 和 GKE 都提供了容器执行环境,但它们有着不同的定位:GKE 是一种“能够实现高级容器编排的服务”,而 Cloud Run 则是一种“以无服务器方式轻松运行容器的服务”。
请参阅以下有关 GKE 的文章以获取更多信息。
- Google Kubernetes Engine(GKE)彻底解说(待续)
Cloud Run 和 App Engine 之间的区别
Google App Engine (GAE) 是一项与 Cloud Run 概念类似的服务。
通过 GAE,只需部署代码和配置文件即可轻松运行应用程序。
标准环境中的 GAE 有开发语言限制,但与 Cloud Run 一样,当没有请求时,实例会缩放为 0。
GAE 和 Cloud Run 的主要区别如下:
- GAE 只需要代码和配置文件即可部署,这使得它更容易运行应用程序,而不是像 Cloud Run 那样拥有一个不那么灵活的执行环境。
- GAE 通过 Identity Aware Proxy (IAP) 支持身份验证;Cloud Run 也可以使用 IAP,但需要将其与 Serverless NEG 绑定,且作为其前端的负载均衡器会产生额外费用。
GAE 柔性环境的缺点包括:由于基于虚拟机的执行环境,扩展速度较慢,而且无法扩展到 0。
与 GAE 相比,GAE 在部署简便性方面更胜一筹,而 Cloud Run 则在环境灵活性方面更胜一筹。
另请参阅以下关于 GAE 的文章。
- Google App Engine(GAE)彻底解说(待续)
Cloud Run 和 Cloud Functions之间的区别
除了 Cloud Run 之外,作为提供无服务器计算服务的谷歌云服务的代表,还有 Cloud Functions。
Cloud Functions 最大的特点在于仅需提供源代码即可进行部署,这与 Cloud Run 的操作方式有所不同。
Cloud Functions 适合通过简单的代码实现易于部署的简单处理。它具有很高的执行环境灵活性,而 Cloud Run 则能够处理长时间运行的复杂任务。
Cloud Functions 与 Cloud Run 的主要区别如下
| 比较观点 | Cloud Run | Cloud Functions |
|---|---|---|
| 部署 | 容器镜像 | 源代码 |
| 开发语言 | 无限制 | 有限制 |
| 最长执行时间 | 60分钟 | (在第二代情况下) 对于HTTP函数为60分钟 对于事件驱动函数为10分钟 |
另请参阅以下关于 Cloud Functions 的文章。
Cloud Run for Anthos
Anthos 是一种由 Google Cloud 提供的服务,它通过 Kubernetes 对基础架构层进行抽象化,使得容器应用程序能够在谷歌云之外的各种云平台和企业内部环境中构建和运行。
Anthos 使您能够在谷歌云控制台的单一界面上管理不同的平台上的 Kubernetes 集群,包括“本地部署”、“AWS”和“谷歌云”。
Cloud Run for Anthos 是 Anthos 提供的一项服务,它使您能够在 Anthos 集群上构建谷歌管理的 Knative,从而利用无服务器容器执行(参考资料)。这使得一些普通 Cloud Run 无法实现的用例成为可能,例如:
- 在没有无服务器 VPC 访问的情况下连接到 VPC 网络
- 在同一个服务中运行多种类型的容器
- 利用 GPU 实现高性能计算
这些功能为用户提供了更多的灵活性和性能优化的机会,满足了更广泛的业务需求和技术要求。


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











