







 本文详细介绍了数据仓库的分层理论,包括ODS、DWD、DWS、DWT和ADS层的作用及命名规范。同时,讨论了数据集市与数据仓库的概念,强调了分层的重要性和好处。此外,文章还涵盖了数仓命名规范,以及范式理论,如第一范式到第三范式,探讨了关系建模和维度建模的区别,强调了维度表和事实表在数据仓库中的角色。
本文详细介绍了数据仓库的分层理论,包括ODS、DWD、DWS、DWT和ADS层的作用及命名规范。同时,讨论了数据集市与数据仓库的概念,强调了分层的重要性和好处。此外,文章还涵盖了数仓命名规范,以及范式理论,如第一范式到第三范式,探讨了关系建模和维度建模的区别,强调了维度表和事实表在数据仓库中的角色。
文章目录
第一章 数仓分层
一、为什么要分层
(1)数据仓库分层
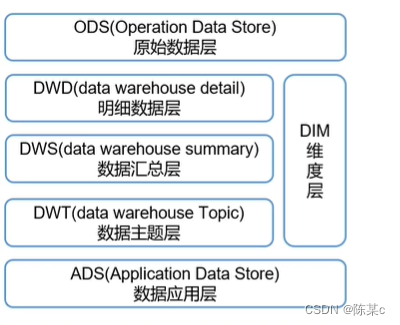
- ODS层:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
- DWD层:对ODS层数据进行清洗(去空值,脏数据,超过极限范围的数据)、脱敏等。保存业务事实明细,一行信息代表一次业务行为,列如一次下单。
- 以DWD为基础,按天进行轻度汇总。一行信息代表一个主题对象一天的汇总行为,例如一个用户一天下单次数
- 以DwS为基础,对数据进行累积汇总。一行信息代表一个主题对象的累积行为,例如一个用户从注册那天开始至今一共下了多少次单
- ADS层,为各种统计报表提供数据
(2)数据仓库为什么要分层
- 把复杂问题简单化:将复杂的任务分解成多层来完成,每一层只处理简单的任务,方便定位问题。
- 减少重复开发:规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性
- 隔离原始数据: 不论是数据的异常还是护具的敏感性,是真实数据与统计数据解耦开。
二、数据集市与数据仓库概念
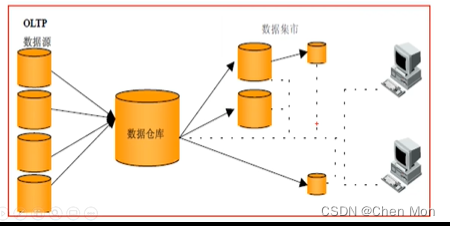
- 数据集市(Data Mart),现在市面上的公司和书籍都对数据集市有不同的概念。
- 数据集市则是一种微型的数据仓库,它通常有更少的数据,更少的主题区域,以及更少的历史数据,因此是部门级,一般只能位为某个局部范围内的管理人员服务。
- 数据仓库是企业级的,能为整个企业各个部门的运行提供决策支持手段
-
从属型数据集市:数据仓库的数据来自业务系统,而数据集市的数据来自数据仓库
-
独立性数据集市:独立性是没有数据仓库的它是直接从业务系统直接获取数据。
-
从属型数据集市的优点:各个部门的数据集市都来自于中央数据仓库,所以说各个部门取到的数据都是经过统一处理之后的数据。所以每个部门获取到的数据是一致的。
-
从属型数据集市的优点:搭建一个从属型数据集市开发周期是比较长的,首先必须要有一个中央的数据仓库
-
独立性数据集市的优点:开发周期更短,不需要搭建中央的数据仓库
-
独立性数据集市的缺点:每个部门获取或者处理逻辑的不尽相同,这样一来就会导致每个部门之间的数据一致性相对来说是比较差的,这样就会导致一个现象数据孤岛
三、数仓命名规范
(1)表命名
- ODS层命名为ods_表名
- DIM层命名为dim_表名
- DWD层命名为dwd_表名
- DWS层命名为dwd_表名
- DWT层命名为dwt_表名
- ADS层命名为ads_表名
- 临时表命名为tmp_表名
(2)脚本命名
- 数据源_to_目标_db/log.sh
- 用户行为脚本以log为后缀;业务数据脚本以db为后缀。
(3)表字段类型
- 数量类型位bigint
- 金额类型位decimal(16,2),表示:16位有效数字,期中小数部分2位
- 字符串(名字,描述信息等)类型位string
- 主键外键类型位string
- 时间戳类型位bigint
第二章 数仓理论
一、范式理论
(1)范式概念
- 定义:数据建模必须遵循一定的规则,在关系建模中,这种规则就是范式。
- 目的:采用范式,可以降低数据的冗余性。
- 为什么要降低数据冗余性?
(1)十几年前,磁盘很贵,为了减少磁盘存储。
(2)以前没有分布式系统,都是单机,只能增加磁盘
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









