







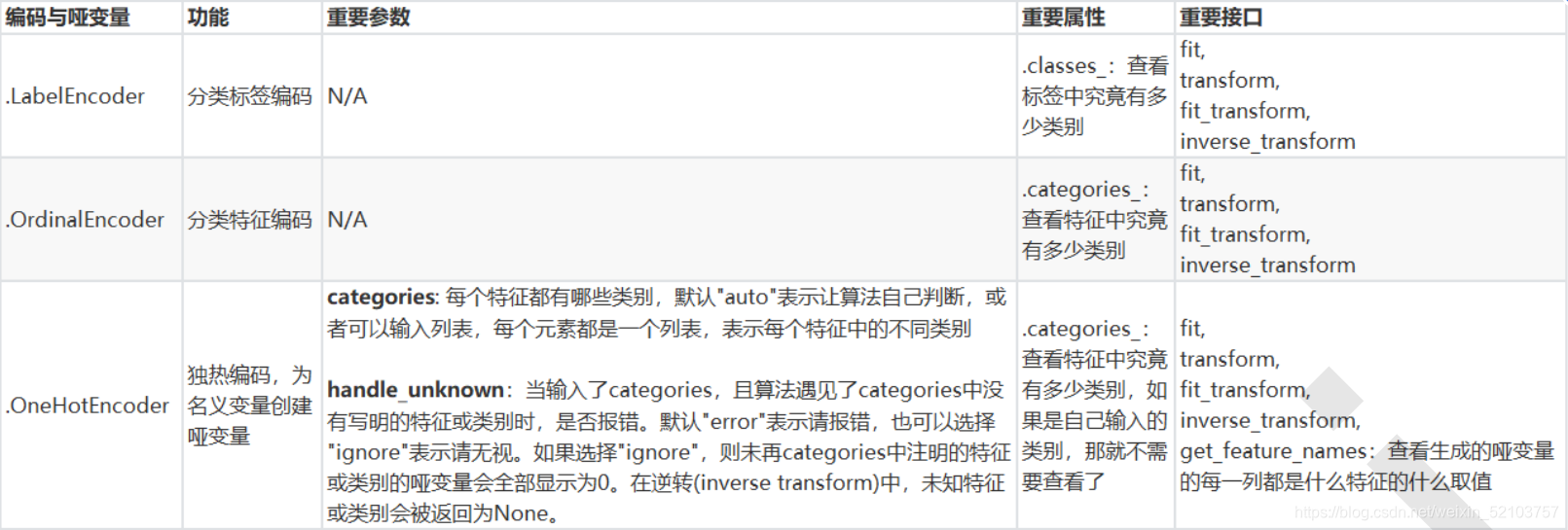
LabelEncoder(标签专用,把分类转换成数值分类)
from sklearn.preprocessing import LabelEncoder
# 找出数据中的一列特征
y = data.iloc[:, -1]
# 使用LabelEncoder
le = LabelEncoder() # 初始化
le = le.fit(y)
label = le.transform(y)
######################### 一步到位
le.fit_transform(y)
#########################
# 覆盖
data.iloc[:, -1] = label
# 查看类别多少
le.classes_
######################################## 真正的一步到达位
data.iloc[: -1] = LabelEncoder().fit_transform(data.iloc[:, -1])
OrdinalEncoder(特征专用,将分类特征转换为分类数值)
from sklearn.preprocessing import OrdinalEncoder
# 同上面一样的步骤
data_ = data.copy() # 先复制出来不要破坏原数据集
# 使用OrdinalEncoder
Ord = OrdinalEncoder()
Ord = Ord.fit(data_)
Ord = Ord.transform(data_)
# 一步到位
data_ = OrdinalEncoder().fit_transform(data_)
# 查看目录(展示从第一列开始的特征类别和数据类型)
OrdinalEncoder().fit(data_).categories_
OneHotEncoder(独热编码创建哑变量)
from sklearn.preprocessing import OneHotEncoder
x = data.iloc[:, 1:-1]
# 使用 OneHotEncoder
enc = OneHotEncoder(categories='auto').fit(x) # 让它自己看有多少特征属性
result = enc.transform(x).toarray()
# 可以还原
olddata = enc.inverse_transform(result)
pd.DataFrame(olddata)
# 跨行合并,左右表连接,axis=0 就是上下合并
newdata = pd.concat([data, pd.DataFrame(result)], axis=1)
# 删除原来的列
newdata.drop(["name1", "name2"], axis=1, inplace=True)
# 换columns
newdata.columns = ["columns1"...]
-
处理连续型特征:二值化与分段
Binarizer
将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。
# 年龄二值化
from sklearn.preprocessing import Binarizer
# 不能用一维数组,特征专用
x = data.iloc[:, 0].values.reshape(-1, 1)
transformer = Binarizer(threshold=阈值).fit_transform(x) # 一步到位
# 替换
data.iloc[:, 0] = transformer
KBinsDiscretizer
将连续性变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。
三个参数。

from sklearn.preprocessing import KBinsDiscretizer
# 实例化
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(x)
# 查看箱(onehot的话没有办法使用)降维函数
set(trans.fit_transform(num.reshape(-1, 1)).ravel()) # 利用set去重
# onehot 使用:箱变成了哑编码
est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform') #查看转换后分的箱:变成了哑变量
est.fit_transform(X).toarray()


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











