






简单记录学习~
Residual:
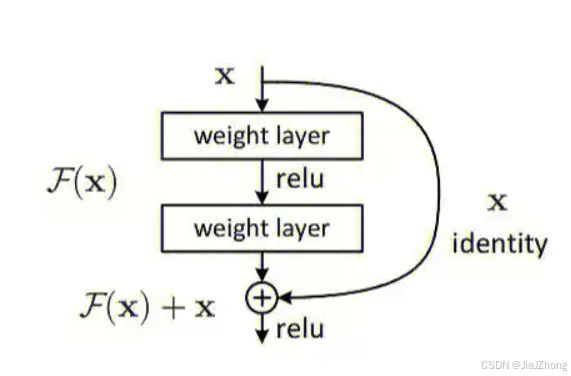
为什么说模型学到的是残差 y−x
-
模型的核心学习内容是 F(x):
- 在残差网络中,F(x) 是通过深层网络(非线性变换)学习到的结果,它是输入 x 经过一个或多个网络层(如卷积、激活函数等)计算得到的输出。
- 这个 F(x) 反映了网络实际学习的内容。
-
残差的叠加:
- 最终的输出 y 是 F(x) 和输入 x 的叠加: y = F(x) + x
- 由于 x 是直接通过 shortcut 跳过中间层传递的,因此网络实际上是通过 F(x) 来补充或修正 x 的信息,从而得到目标输出。
-
为什么说是残差?
- 从公式上看: F(x)=y−x 所以,网络的学习任务是找出 y 和 x 的差异部分,也就是所谓的残差。模型并不需要完全从零学习输出 y,而是将任务分解为两部分:
- 恒等映射 x(通过 shortcut 直接传递)。
- 修正部分 F(x)(通过深层网络学习)。
- 因此,残差网络的本质就是“学习残差”。
- 从公式上看: F(x)=y−x 所以,网络的学习任务是找出 y 和 x 的差异部分,也就是所谓的残差。模型并不需要完全从零学习输出 y,而是将任务分解为两部分:
-
总的概括:
- F(x) 是模型经过网络层学习到的内容。
- 然后在最后将 F(x) 和 x 相加得到输出 y。
- 这就是为什么我们说网络学习的是残差(即 y−x),因为 x 是直接加上的,模型真正需要训练和调整的只有 F(x)。
残差学习的好处
-
简化学习任务:
网络不需要学习整个 y,而只需学习 x 和 y 的差异,降低了优化的复杂度。 -
更高效的训练:
恒等映射(x)通过 shortcut 直接传递,确保梯度可以无障碍地从后向前传播,缓解梯度消失问题。 -
适应深层网络:
如果某些层对最终输出没有贡献,模型可以通过学习 F(x) ≈ 0 自动跳过这些层,而不影响整体性能。
总结
- 模型的核心是学习 F(x),即输入 x 和输出 y 的差异,也就是残差 y−x 。
- 最终的叠加只是为了将残差补充到输入 x 上,使网络能够更高效地学习复杂映射。

















 2451
2451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









