







 本文详细介绍了对SLIC超像素算法的优化过程,包括交换循环层次以减少重复运算,创建查询表加速RGB到XYZ转换,以及对EnforceLabelConnectivity函数的循环合并。通过这些优化,平均耗时从17978ms降低到891ms,性能提升了20.17倍,尤其是在-O3编译基础上提高了4.17倍。尽管在某些部分并行优化受限,但整体效果显著。
本文详细介绍了对SLIC超像素算法的优化过程,包括交换循环层次以减少重复运算,创建查询表加速RGB到XYZ转换,以及对EnforceLabelConnectivity函数的循环合并。通过这些优化,平均耗时从17978ms降低到891ms,性能提升了20.17倍,尤其是在-O3编译基础上提高了4.17倍。尽管在某些部分并行优化受限,但整体效果显著。
题目
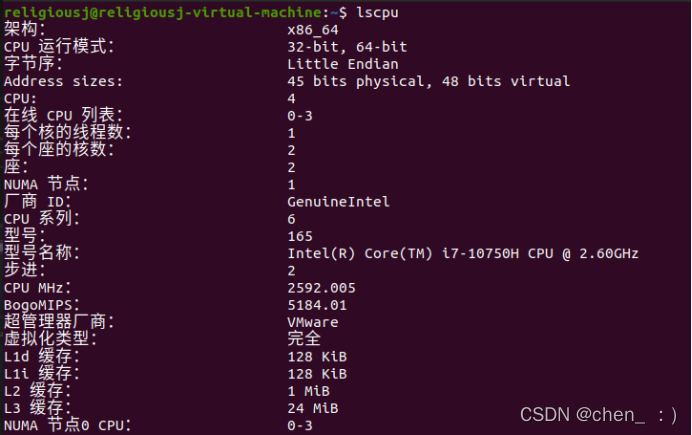
硬件环境:
初始测试:


Average: 17978 ms
编译选项: -O3优化

Baseline:
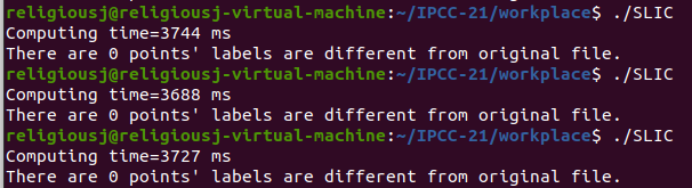 Average: 3719 ms
Average: 3719 ms
热点分析:
由于函数较多,先进行热点分析,确定主要优化函数
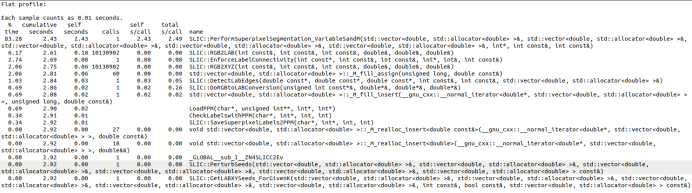

主要优化函数:
SLIC::PerformSuperpixelSegmentation_VariableSandM
SLIC::DoRGBtoLABConversion & SLIC::RGB2LAB & SLIC::RGB2XYZ
SLIC::EnforceLabelConnectivity
SLIC::DetectLabEdges
优化过程:
1.SLIC::PerformSuperpixelSegmentation_VariableSandM
(3) 对于n y x循环,交换n和y的循环层次,将方块形运算优化为长条形运算,减少重复运算,加大并行力度;
合并相同范围的循环结构;
进行除法优化;



(4) 删去并优化中间变量计算:disxy 和 maxxy;
优化代码实现;
进行循环展开;
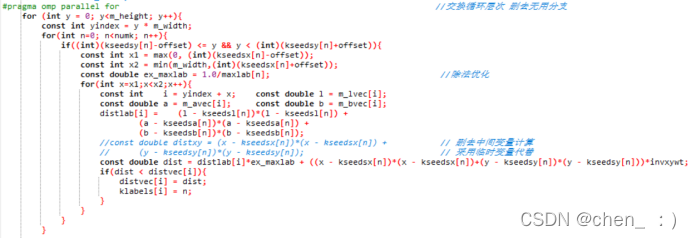



(5) 避免重复计算
优化代码结构



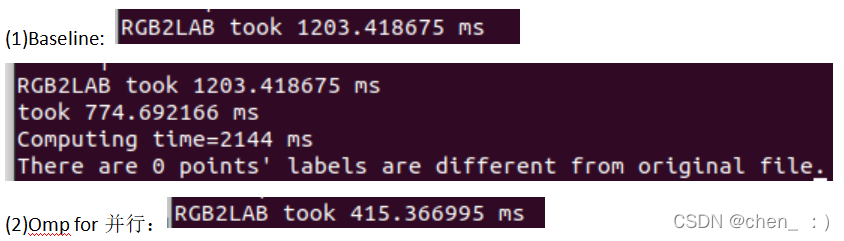
2.SLIC::DoRGBtoLABConversion & SLIC::RGB2LAB & SLIC::RGB2XYZ
ps.此处优化参照博客
并行计算 SLIC超像素算法(三) OpenMP优化(二)具体优化过程
为了方便之后的优化
将SLIC::RGB2LAB 和 SLIC::RGB2XYZ在SLIC::DoRGBtoLABConversion中展开:
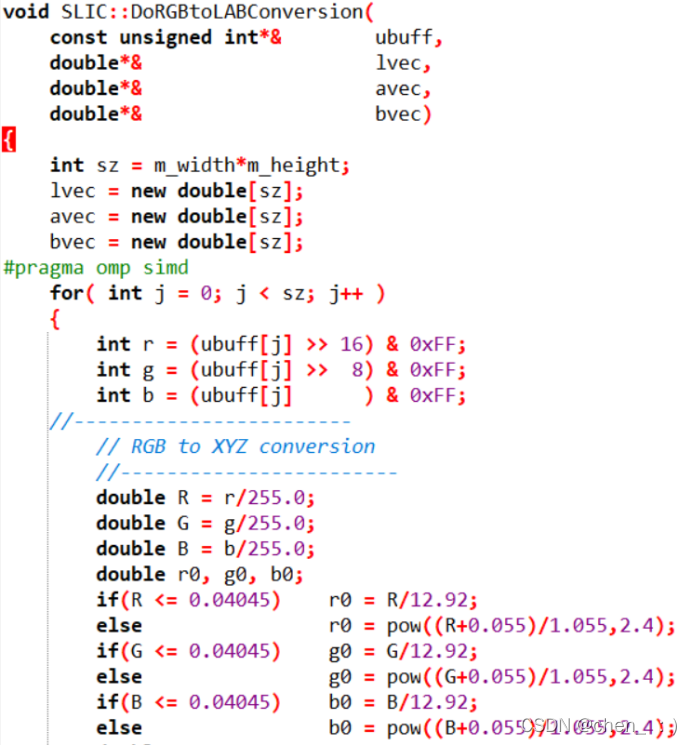
(3) 观察到rgb转换到XYZ过程中,三个变量处理的方法一致,且r, g, b三个变量的取值均为[0,255] (int),所以对于rgb的转换,我们可以先建立一个查询表将0~255取值的每种情况先算出并记录,当要转换rgb时直接查表即可。并进行向量化处理。
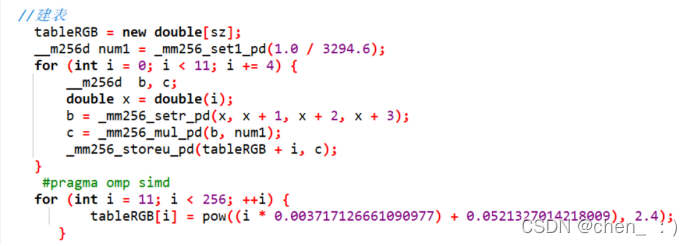
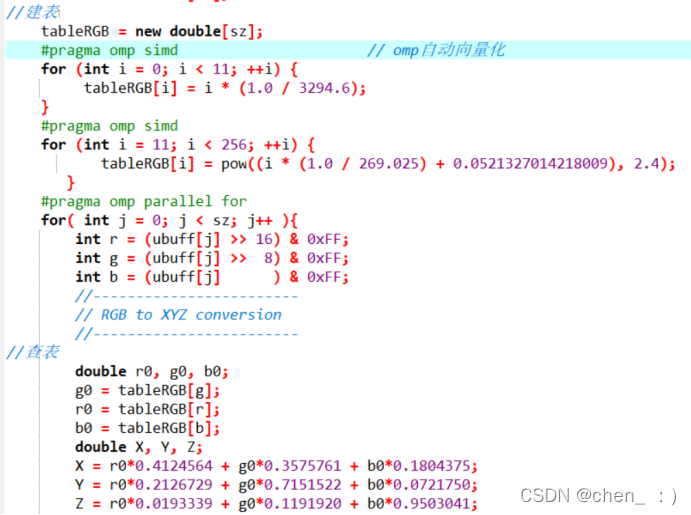
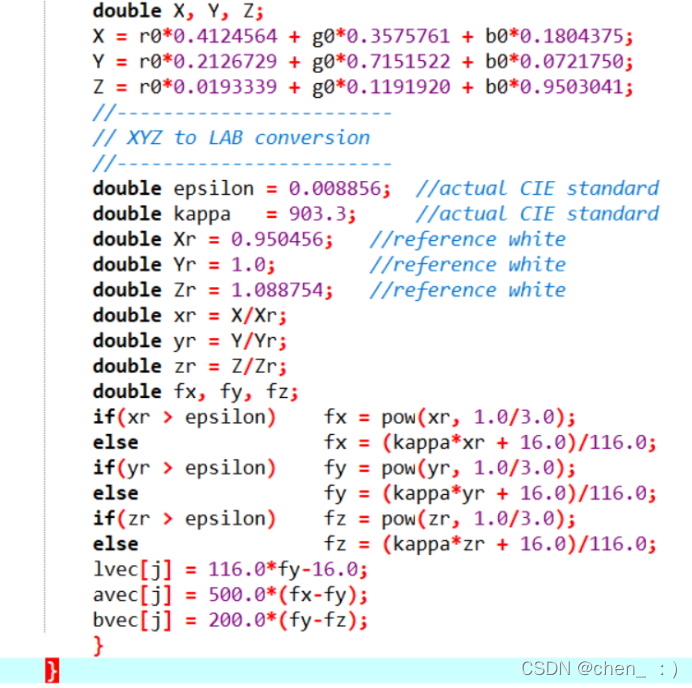
(4) 对于XYZ to LAB的过程,由于在计算过程中,XYZ的处理有所不同,且XYZ为double类型,范围较大,所以我们将中间过程量手动算出,只将其结果代入最后的运算,消除重复运算,并将耗时的除法运算消除。

3 . SLIC::PerturbSeeds & SLIC::DetectLabEdges
MISSING
4.SLIC::EnforceLabelConnectivity
这个部分并行程度较低,无法直接用omp进行优化,我们尝试过使用pbfs改进原算法,使用并行打标签,但多次尝试无果后选择放弃。目前我们只是合并了该函数的部分循环层次,优化效果不佳。

总结:
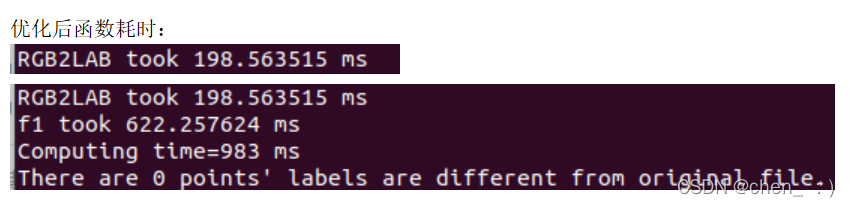
最终优化完成后的耗时:
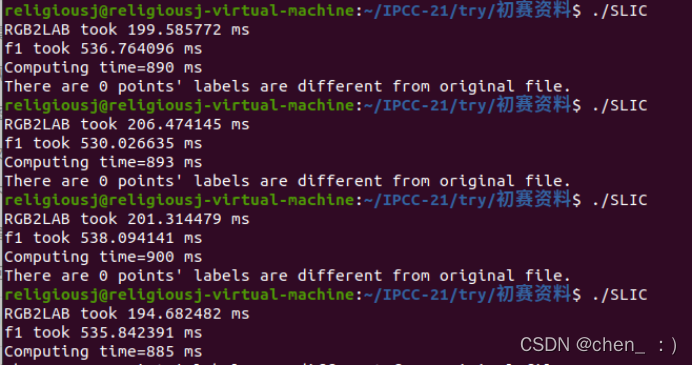 Average:891 ms
Average:891 ms
相比于最初耗时17978 ms 提升了20.17倍
相比于O3编译耗时 3719 ms 提升了4.17倍
Ps.(由于本机只有4个cpu,所以感觉并行力度不高)

















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









