




文章目录
摘要
GRU是RNN的一个优秀的变种模型,继承了大部分RNN模型的特性;在本次学习中,简单学习了GRU的基础知识,展示了GRU的手动推导过程,用代码逐行模拟实现LSTM的运算过程,并与Pytorch API输出的结验证是否保持一致。
Abstract
GRU is an excellent variant model of RNN, inheriting most of the characteristics of RNN model. In this study, I simply learned the basic knowledge of GRU, demonstrated the manual derivation process of GRU, simulated the operation process of LSTM with code line by line, and verified whether it was consistent with the junction output of Pytorch API.
GRU
GRU(Gate Recurrent Unit)门控循环单元,是循环神经网络(RNN)的变种,与LSTM类似通过门控单元解决RNN中不能长期记忆和反向传播中的梯度等问题。与LSTM相比,GRU内部的网络架构较为简单。
1.1 GRU网络的基本结构
GRU 网络内部包含两个门使用了更新门(update gate)与重置门(reset gate)。重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。这两个门控向量决定了哪些信息最终能作为门控循环单元的输出。这两个门控机制的特殊之处在于,它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。 GRU门控结构如下图所示:
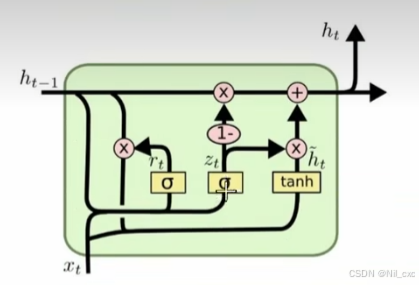
- 重置门:
重置门(reset gate),记为 r t r_t rt,这个门决定了上一时间步的记忆状态如何影响当前时间步的候选记忆内容。计算时会结合前一时间步的隐藏状态 h t − 1 和 x t h_{t-1}和x_t ht−1和xt,输出是一个0到1之间的值。值越接近1表示越多地保留之前的状态,越接近0表示遗忘更多旧状态。对应的数学表达如下:
r t = σ ( W r ∗ [ h t − 1 , x t ] ) r_t = \sigma(Wr*[h_{t-1},x_t]) rt=σ(Wr∗[ht−1,xt])
-
更新门:
更新门(update gate),记为 z t z_t zt,这个门决定了上一时间步的记忆状态有多少需要传递到当前时间步,以及当前的输入信息有多少需要加入到新的记忆状态中,同样,它也是基于前一时间步的隐藏状态 h t − 1 和 x t h_{t-1}和x_t ht−1和xt计算得到的。对应的数学表达如下:
z t = σ ( W z ∗ [ h t − 1 , x t ] ) z_t = \sigma(Wz*[h_{t-1},x_t]) zt=σ(Wz∗[ht−1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2645
2645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









