







 该研究提出了一种结合Transformer和V-Net的半监督分割网络,利用注意力机制的鉴别器(DAM)学习策略,有效提升3D左心房分割的准确性和鲁棒性。实验表明,即使在少量标注数据下,模型也能快速收敛并达到与标注数据相当的性能。
该研究提出了一种结合Transformer和V-Net的半监督分割网络,利用注意力机制的鉴别器(DAM)学习策略,有效提升3D左心房分割的准确性和鲁棒性。实验表明,即使在少量标注数据下,模型也能快速收敛并达到与标注数据相当的性能。
基于上下文感知融合Transformer和V-Net的三维左心房半监督分割网络Context-aware network fusing transformer and V-Net for semi-supervised
研究背景及动机
背景:
1 对于医学专家而言,绘制可靠标注的工作繁琐且耗时,而且由于专家的主观性,人工标注也可能造成一定的分割差异
2 医疗机构中通常存在大量的未标记数据,充分发挥未标记数据的作用
动机:
1 3D医学图像包含一组切片:模型要学习的不仅是一个切片中的上下文信息,还包括不同切片之间的上下文信息(不同组织,不同部位的关联信息)
2 现有方法很少同时利用两种信息
主要贡献
1 将Transformer融合到VNet中
2 设计带有注意机制的鉴别器,引入强形状和位置先验信息
3 显著提高了LA分割的准确性和鲁棒性,但也存在参数过多等潜在问题
方法
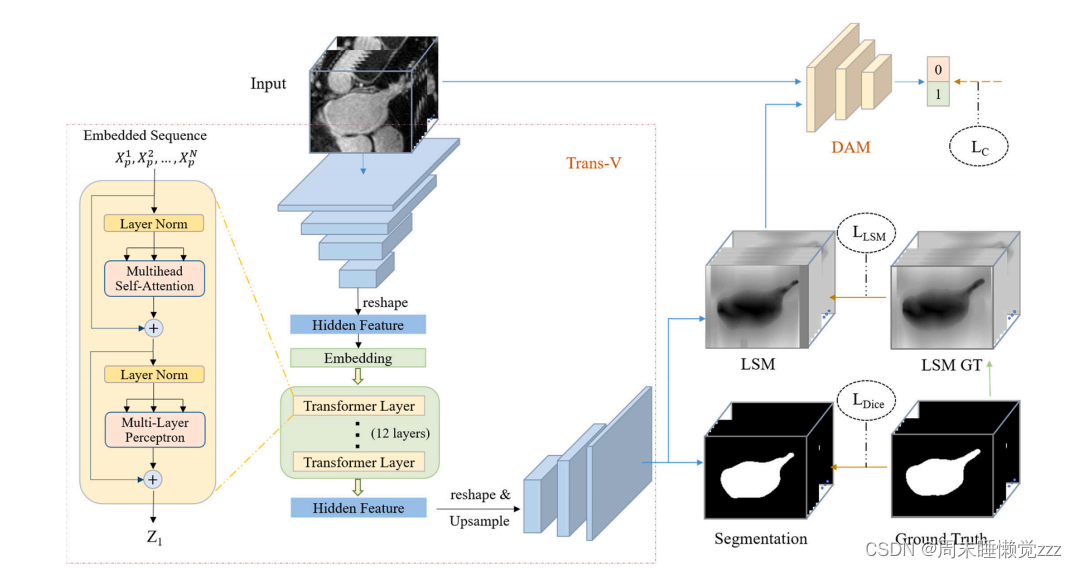
在VNet瓶颈使用Transformer提取全局上下文信息
def TransformerLayer(self, features):
x5 = features[4]
embedding_output = self.embeddings(x5)
transformer_output, attn_weights = self.transformer(embedding_output)
detransformer_output = self.detransformer(transformer_output)
features[4] = detransformer_output
return features
将编码器最后一层的输出x5进行位置编码,编码后的输出经过12层的Transformer再经过编码器得到分割结果。
DAM(discriminator with attention mechanism)带有注意力机制的鉴别器
由5个卷积层和一个MLP组成,在原有的5层卷积之后加入一个改进的SENet来提高鉴别器的性能。
class FC3DDiscriminator(nn.Module):
def __init__(self, num_classes, ndf=64, n_channel=1):
super(FC3DDiscriminator, self).__init__()
# downsample 16
self.conv0 = nn.Conv3d(num_classes, ndf, kernel_size=4, stride=2, padding=1)
self.conv1 = nn.Conv3d(n_channel, ndf, kernel_size=4, stride=2, padding=1)
self.conv2 = nn.Conv3d(ndf, ndf*2, kernel_size=4, stride 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4512
4512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











