







两张3090 24G跑deepseek 70b还挺流畅_哔哩哔哩_bilibili
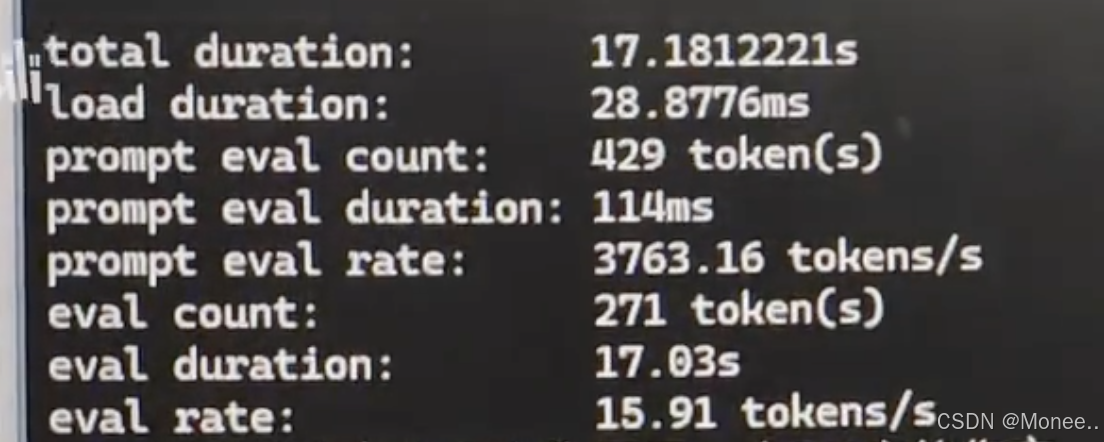
双4090部署Deepseek-R1 每秒130tokens_哔哩哔哩_bilibili
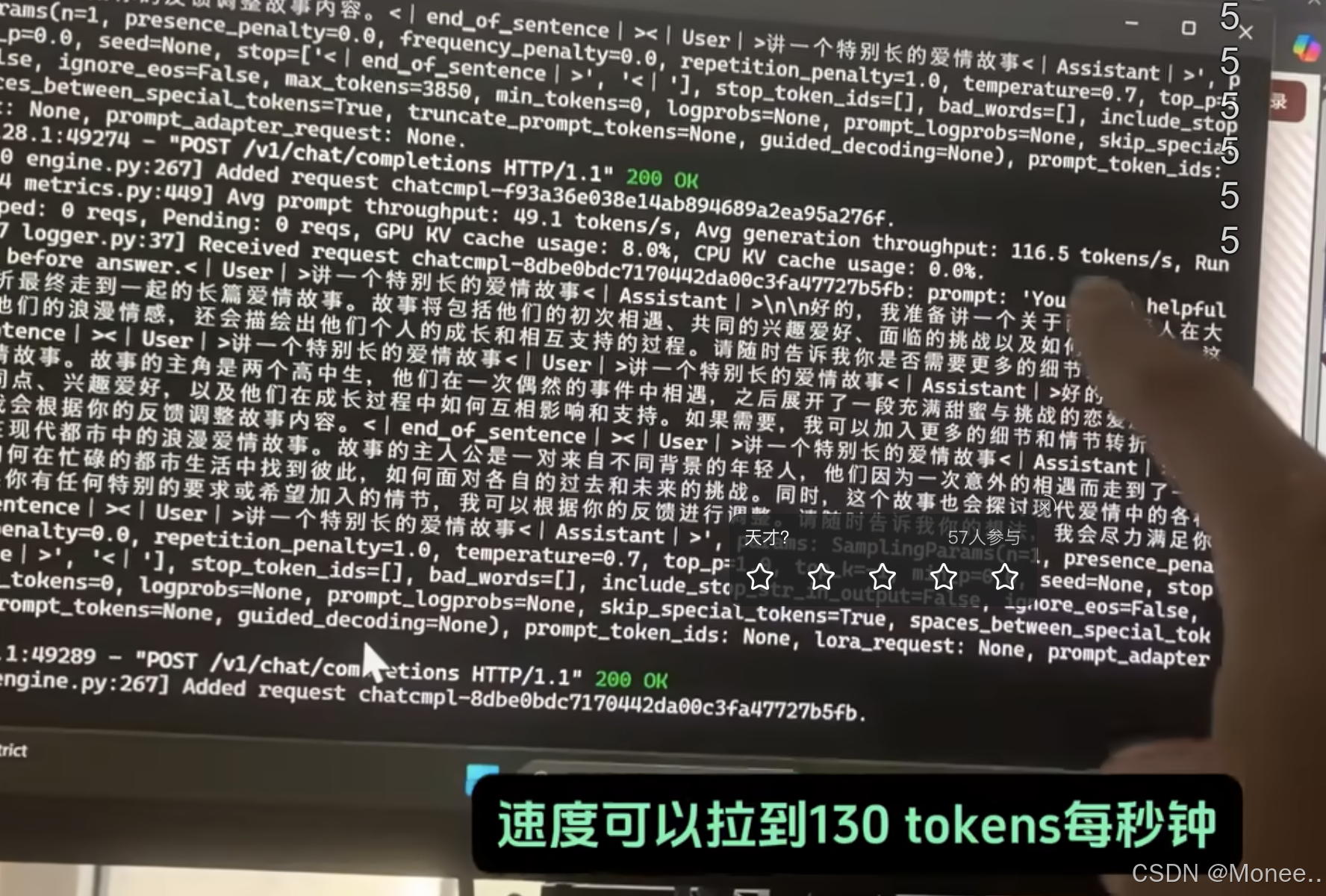
万元服务器运行满血DeepSeek!全网最全低成本部署方案+硬件采购避坑指南!KTransformers方案+Unsloth动态量化方案详解!_哔哩哔哩_bilibili
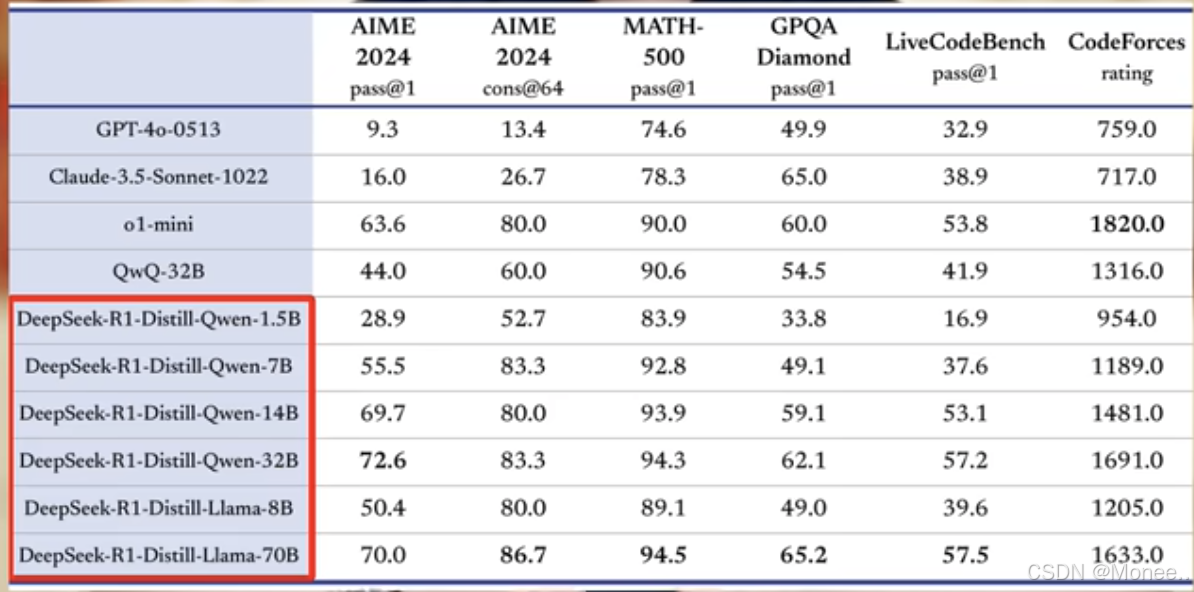
总结:
看需求
- 如果只是想自己部署玩玩,2x24的3090或4090就够
- 如果是小团队用,4x4090
- 如果是追求响应速度和高并发,建议最少a100x2或h800x2
总之,显存不够内存来凑,跑是都能跑起来,主要看每秒输出token数。


















 4313
4313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









