







- 实验目的
编程实现K-means,对所提供数据(data.txt)进行聚类,cluster数量为3
- 实验内容:
1、数据中含有“[”,“]”python读入时不能自己处理,所以使用f.readlines将内容读为字符串,遍历每一行,去除行末回车和左右中括号,数据转为float类型,数据放到data中并转array返回。
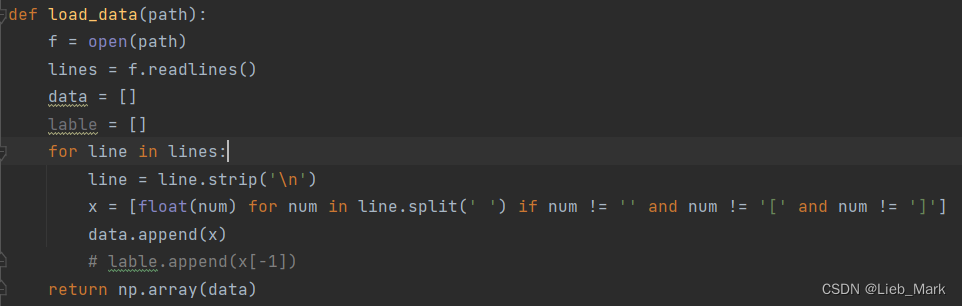
2、首先根据cluster数使用random.choice在0到n-1中随机选择k个作为初始的簇中心,所有点标签都置为0。
接着根据k-means算法,计算每个点到哪个簇中心最近(欧氏距离),把该点的标签换为这个簇的序号。然后对每个更新后的簇求平均,更新簇均值向量。然后再进行循环,直到三个均值向量不再变化。
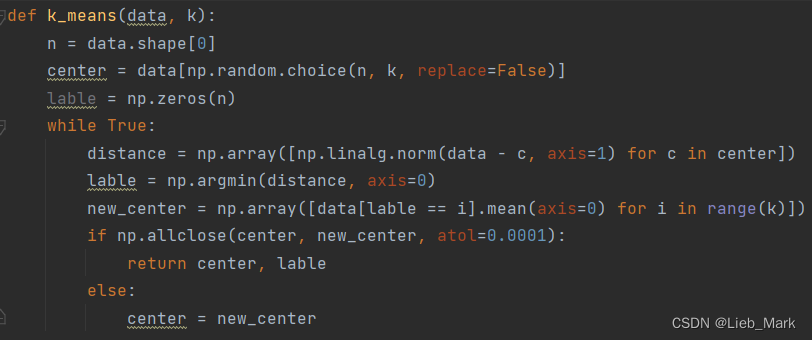
这里使用了np.linalg.norm计算二范数即欧氏距离,遍历每一个簇中心,利用广播机制,直接对data – c求二范数就得到了所有点到该簇中心的距离,形状为(90,)。一共三个簇中心,得出的结果是(3,90)的,每一列是每个点到三个簇中心的距离。使用列方向上的np.argmin,可以得到距离最近的簇中心的下标,作为其标签。这样做使用矩阵运算,省去了多层for循环。
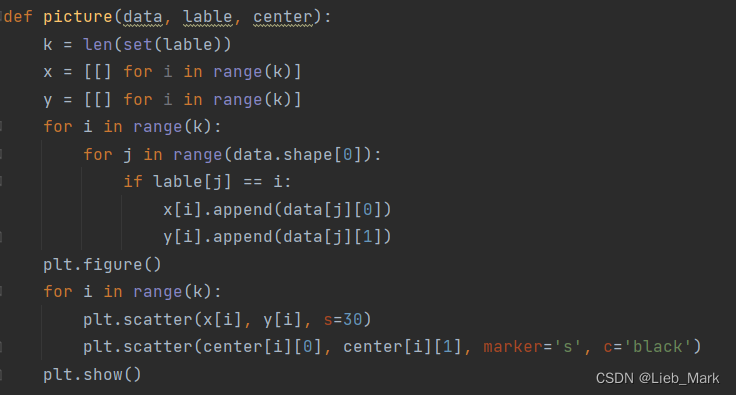
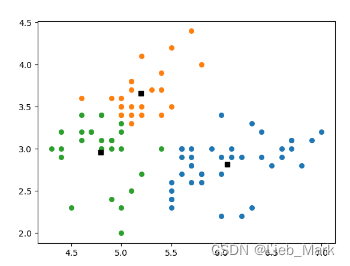
3、最后使用matplotlib对聚类结果可视化。分别将所有点按照聚类标签分别涂为不同颜色,聚类中心使用黑色方块标出。
实验结果:
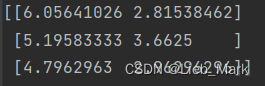
聚类中心
可视化
- 实验原理:



- 心得体会:
通过这次实验,让我对k-means的掌握更加扎实。k-means算法作为经典的聚类算法,不光在机器学习中有很大的用处,在深度学习中同样用处很大。无监督学习发展迅猛,聚类算法可以不用标签,根据样本的特征值进行类型划分。
在实验中,整体算法比较简单,但是按照思路一个个计算距离需要写两层for循环,比较繁琐。使用广播机制、np.linalg.norm、argmin等,通过矩阵运算,可以大大减小代码复杂成度。
巩固了所学知识,为以后的学习打下坚实的基础。
import numpy as np
import matplotlib.pyplot as plt
def load_data(path):
f = open(path)
lines = f.readlines()
data = []
lable = []
for line in lines:
line = line.strip('\n')
x = [float(num) for num in line.split(' ') if num != '' and num != '[' and num != ']']
data.append(x)
# lable.append(x[-1])
return np.array(data)
def k_means(data, k):
n = data.shape[0]
center = data[np.random.choice(n, k, replace=False)]
lable = np.zeros(n)
while True:
distance = np.array([np.linalg.norm(data - c, axis=1) for c in center])
lable = np.argmin(distance, axis=0)
new_center = np.array([data[lable == i].mean(axis=0) for i in range(k)])
if np.allclose(center, new_center, atol=0.0001):
return center, lable
else:
center = new_center
def picture(data, lable, center):
k = len(set(lable))
x = [[] for i in range(k)]
y = [[] for i in range(k)]
for i in range(k):
for j in range(data.shape[0]):
if lable[j] == i:
x[i].append(data[j][0])
y[i].append(data[j][1])
plt.figure()
for i in range(k):
plt.scatter(x[i], y[i], s=30)
plt.scatter(center[i][0], center[i][1], marker='s', c='black')
plt.show()
data = load_data(r'data.txt')
center, lable = k_means(data, 3)
picture(data, lable, center)
print(center)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









