






五.利用最大堆维护前K个最小元素
堆,是一种完全二叉树,其关注与数据的大和小,但不关心谁大,和谁比较大,就是说只关心根节点和孩子节点的大小关系,但不关心兄弟节点的大小关系。我们可以借助该种思想,去动态维护一个具有K个元素的堆,将元素在堆中过滤之后,就可以得到最小(最大)的K 个元素。
前K个最小元素需要用最大堆维护;前K个最大元素需要用最小堆维护。这也许是其中最关键、最核心的思想所在。
为什么呢?想象一个场景,堆顶元素永远是最大的,如果我们将前K个元素安排在堆中,堆中的元素就是最大的,在剩下的N-K个元素中,如果遇到一个元素小于堆顶,则将堆顶替换掉,然后下滤,将小元素沉在堆底,让大元素全都暴露在堆顶而被小元素替换掉。这样,通过每次替换掉较大元素,我们就就可以得到一个装载着数组中前K个小元素的堆,即完成了计数。如果是找最大的前K个数,则刚好相反。
上述算法在Mark Allen Weiss 所著的《数据结构与算法分析--C语言描述》中有所提及,部分原文如下:

C语言代码如下:
//
// Created by 周龙 on 2021/11/24.
//
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
/*
* 前K个最小元素需要用最大堆维护
* 前K个最大元素需要用最小堆维护
* 本文使用最大堆维护前K个最小元素
* 堆处理完成后 借助插入排序
* 对过滤完毕的含有前K个元素的堆进行排序
* 排序后得到的数据就是第K个元素的数据
* 适合处理小的顺序统计量
* 需要维护的堆的规模小 同时排序处理的堆规模也小
*/
#define MAXSIZE 1000
typedef int Item;//定义Item
//Max Heap ADT
typedef struct Element {
//也为树 也有内容
Item data;
} Element;
//按照线性表存储heap中的节点
//基于完全二叉树实现
typedef struct Heap {
int size;//大小
Element *element;//堆中存放的数据
} Heap;
//查找第K大的元素
Item Find(const Item *Data, int size, int k);
//选择排序算法
void SelectSort(Heap *heap);
//遍历堆中元素
void heap_traverse(Heap *heap);
//堆的初始化
Heap *Initial(Heap *heap);
//向下过滤
void PercolateDown(Heap *heap, int index, int data);
//建堆 Percolate down the every root node
Heap *BuildHeap(const Item *Data, int size);
//主函数 用于测试
int main(void) {
int array[]={98,1,2,345,12,12,67,3,43,3,11,11};
int size = sizeof array /sizeof array[0];
for (int i = 0; i < size; i++) {
printf("%d ", array[i]);
}
putc('\n', stdout);
Heap *heap = BuildHeap(array, size);
heap_traverse(heap);
printf("数组中的第%d个数为:%d\n\n",1, Find(array, size, 1));
printf("数组中的第%d个数为:%d\n",5, Find(array, size, 5));
return 0;
}
//堆的初始化
Heap *Initial(Heap *heap) {
//为heap分配内存空间
heap = (Heap *) malloc(sizeof(Heap));
if (heap == NULL) {
fprintf(stderr, "Fail to allocate the memory\n");
return heap;
}
heap->size = 0;
heap->element = (Element *) malloc(sizeof(Element) * MAXSIZE + 1);
//头节点作为哨兵使用 避免在上滤过程中增加条件的判断
heap->element[0].data = MAXSIZE;//最大堆
return heap;
}
//Percolate down the every root node
Heap *BuildHeap(const Item *Data, int size) {
Heap *heap = NULL;
//先构建Heap
heap = Initial(heap);
for (int i = 0; i < size; i++) {
heap->element[i + 1].data = Data[i];//按照顺序拷贝即可
}
heap->size = size;
//开始调整节点 从含有child的首个root开始
for (int i = heap->size / 2; i >= 1; i--) {
PercolateDown(heap, i, heap->element[i].data);//以该处的元素下滤 类似于插入排序
}
return heap;
}
//需要加入边界判断值 删除前是否为空 为空则无法删除 percolate down
void PercolateDown(Heap *heap, int index, int data) {
int child;
int i;
for (i = index; i * 2 <= heap->size; i = child) {
child = i * 2;//i的child
if (child != heap->size && heap->element[child].data < heap->element[child + 1].data) {
child++;//右侧节点存在且大于左侧 则更新child为待移动节点
}//向下调整最大堆
if (heap->element[child].data > data) {
heap->element[i].data = heap->element[child].data;
} else {
break;
}
}
//确保for外部就是待插入的位置
heap->element[i].data = data;
}
//查找第K大的元素
Item Find(const Item *Data, int size, int k) {
//以k建堆
Heap *heap = BuildHeap(Data, k);//建堆 以前k个元素建堆
//循环比对
for (int i = k; i < size; i++) {
//将剩下的元素和k-1位置比较
if(Data[i] < heap->element[1].data){
//以新元素下滤
heap->element[1].data = Data[i];
PercolateDown(heap, 1, Data[i]);
}
}
//返回的是前k小的元素
printf("堆过滤完毕:\n");
heap_traverse(heap);
SelectSort(heap);//再对该k小元素排序即可
printf("堆排序完毕:\n");
heap_traverse(heap);
//结束后heap中的数据只能是前k个元素 该顺序并没有一定的要求 这和堆不要求元素的有效性密切相关
return heap->element[heap->size].data;//末尾元素即是堆
}
//遍历堆中元素
void heap_traverse(Heap *heap) {
for (int i = 1; i <= heap->size; i++) {
printf("%d ", heap->element[i].data);
}
printf("\n");
}
//选择排序算法
void SelectSort(Heap *heap){
int size = heap->size;
for(int i=1;i<=size;i++){
int min=heap->element[i].data;
int min_site=i;
int j;
for(j=i;j<=size;j++){
if(heap->element[j].data<min){
min=heap->element[j].data;//记录最小元素
min_site=j;//记录最小元素的下标
}
}
//交换两者元素完成选择排序 改进则为堆排序
heap->element[min_site].data=heap->element[i].data;
heap->element[i].data=min;//元素值的交换
}
}
算法运行结果如下:
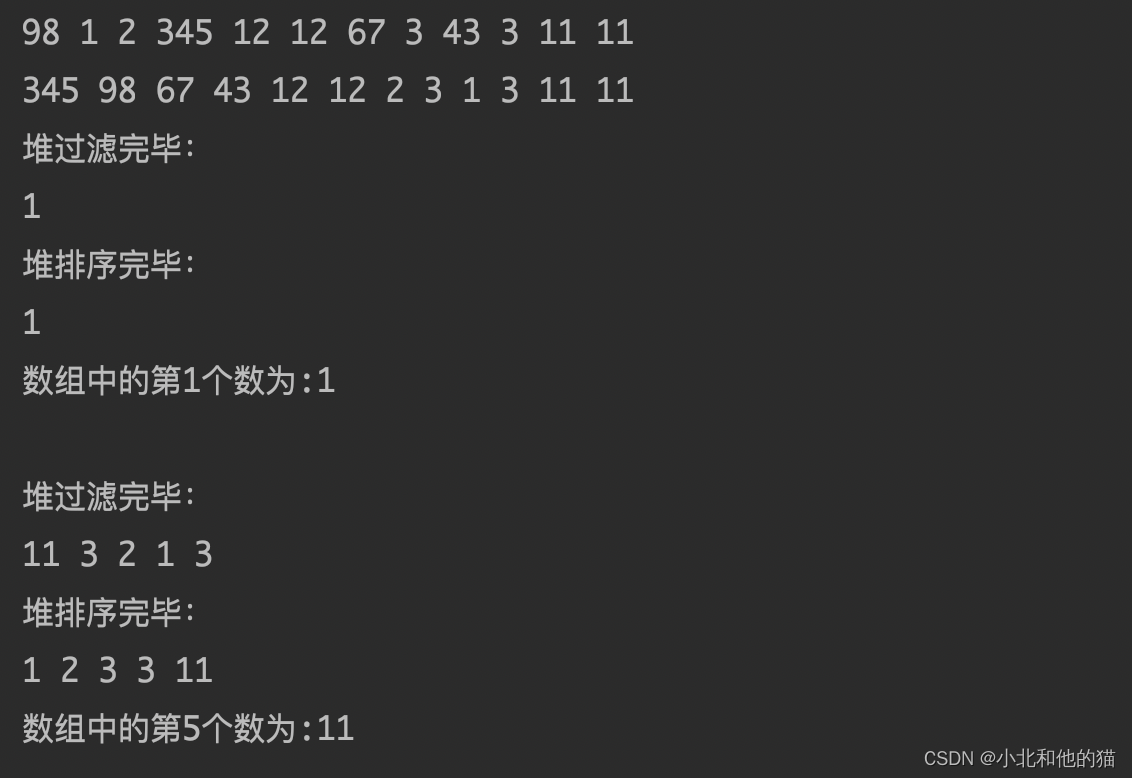
感谢大家的阅读和指正!

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









