




 本文详细介绍了常见的排序算法,如插入排序(包括希尔排序)、选择排序、堆排序、冒泡排序和快速排序,以及它们的时间复杂度、辅助存储和稳定性。通过实例演示和理论分析,深入探讨了各种排序方法在实际应用中的优劣。
本文详细介绍了常见的排序算法,如插入排序(包括希尔排序)、选择排序、堆排序、冒泡排序和快速排序,以及它们的时间复杂度、辅助存储和稳定性。通过实例演示和理论分析,深入探讨了各种排序方法在实际应用中的优劣。
数据结构课程设计之排序算法的应用及效率的比较。
对于排序算法,首先我们需要知道的是常见的排序方法有哪些?
常见的排序方法主要分为四类,插入排序、选择排序、交换排序以及归并排序。
其中插入排序包括直接插入排序和希尔排序,选择排序包括直接选择排序和堆排序,交换排序包括冒泡排序和快速排序。
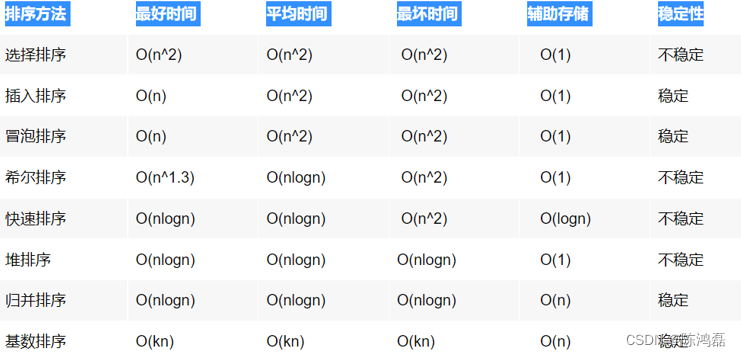
并且对于每一种排序方法的时间复杂度、辅助存储以及稳定性,我们也是需要了解的。
我们按照顺序来讲解每一种排序方法。
直接插入排序:
对于一组数据,5、7、9、4、3、8。我们使用插入排序算法对其进行排序。

那么我们是如何实现插入的呢?
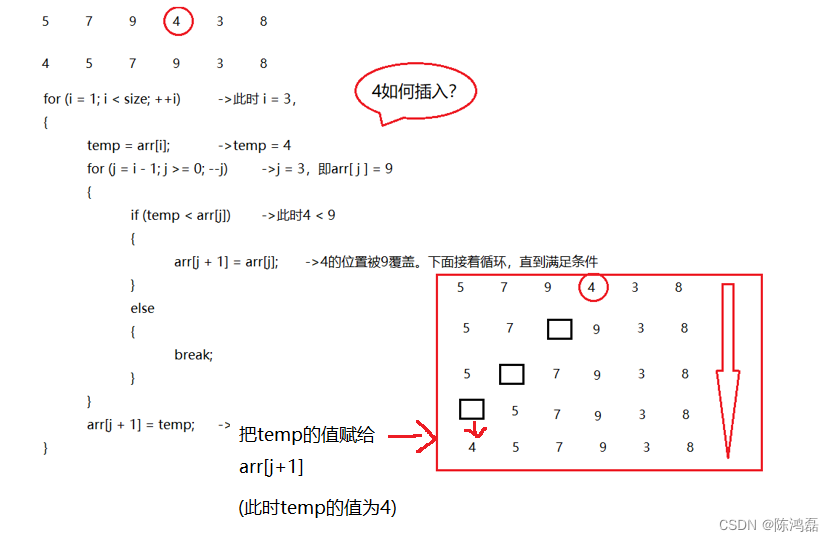
插入排序最好的情况是:
即数组已经排好序的情况,在下面这段代码中,里面的for循环有O(1)的时间复杂度(因为在以及排好序的情况下,每次只需要判断一次即可退出循环,所以时间复杂度为O(1)),所以该最好的情况的时间复杂度为O(N)。
void Insert_Sort(int arr[], int size)
{
int i;
int j;
int temp; //进行存储
for (i = 1; i < size; ++i)//1、从第二个元素插入
{
temp = arr[i]; //保存需要插入的元素
for (j = i - 1; j >= 0; --j)//在已经有序的数列中,进行比较。
{
if (temp < arr[j]) //进行升序排序。如果待插入的元素小于它前一个元素arr[j],
//就把带插入元素向前移动,那么 j 位置的元素
//就需要向后移动一个位置,直接覆盖就好,因为已经保存了
{
arr[j + 1] = arr[j];
}
else //如果带插入元素不大于前一个元素,就停止
{
break;
}
}
arr[j + 1] = temp;//即为被插入元素的位置
}
}
希尔排序(插入排序的优化算法):
希尔排序是插入排序的一种优化,直接插入排序的遍历的间隔为1,而希尔排序的遍历的间隔不为1,它是遍历的间隔逐渐缩小直到为 1 的一种排序。当遍历的间隔不为 1 的时候,都是预排序。第一次的遍历的间隔是数据长度的三分之一再加一。
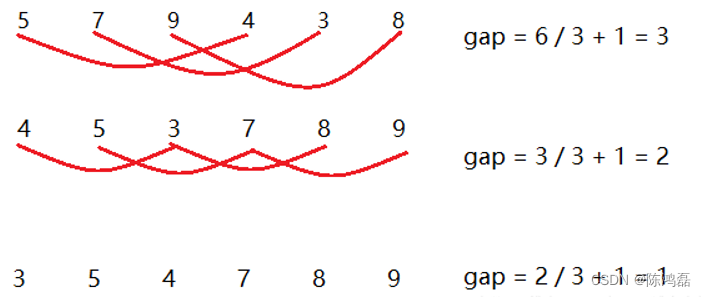
希尔排序最好的情况是:
即数组已经排好序的情况,当n在某个特定范围时,希尔排序的时间复杂度约为O(n^1.3)(具体是如何计算出来的,在此不作概述,有兴趣的可以去查阅)。
希尔排序是插入排序的的优化算法,希尔排序的平均时间复杂度是O(nlogn),最坏的情况是O(n^2)。
void InsertSortWithgap(int arr[], int size, int gap)
{
int i;
int j;
int temp;
for (i = gap; i < size; ++i)//从下标为gap的元素作为带插入元素
{
temp = arr[i];//存储gap下标的元素
for (j = i - gap; j >= 0; j -= gap)//从第 0 个元素进行比较
{
if (temp > arr[j])//降序
{
arr[j + gap] = arr[j];//gap位置的元素换成 j 所在下标的元素
}
else
{
break;
}
}
arr[j + gap] = temp;//j所在下标位置存储temp
}
}
void ShellSort(int arr[], int size)
{
int gap = size;
while (1)
{
gap = gap / 3 + 1;//改变gap的值,直至1.
InsertSortWithgap(arr, size, gap);
if (gap == 1)
{
break; //gap的值为一时停止
}
}
}
选择排序:
对于一组数据,29、18、87、56、3、27。
我们对其进行n轮的比较。经过第一轮比较得到最小的记录,然后将记录与第一个记录的位置进行交换;接着对不包括第一个记录以外的其他记录进行第二轮排序,得到最小的记录并与第二个记录进行位置交换;重复该过程,直到进行比较的记录只有一个为止。
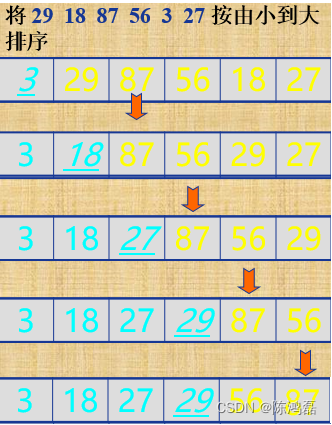
选择排序的最坏,平均,最坏情况均为:
O(n^2).
对于选择排序来说,在排好序的情况,也要将两层for进行完,所以最坏,平均,最好是没有区别的。
(注:上述图解是找一个最小的放最前面,下面的代码是找一个最大的放最后面)
void ChoiceSort(int arr[], int size)
{
for (int i = 1; i < size; ++i)
{
int max = 0;
for (int j = 1; j <= size - i; ++j)
{
if (arr[j] > arr[max])//比较
{
max = j;
}
}
int temp = arr[size - i];//交换
arr[size - i] = arr[max];
arr[max] = temp;
}
}
堆排序:
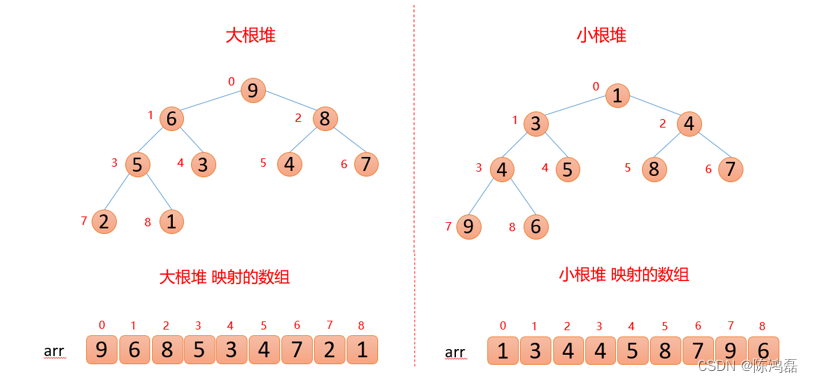
堆的结构可以分为大根堆和小根堆,是一个完全二叉树。
性质:每个结点的值都大于其左孩子和右孩子结点的值,称之为大根堆;每个结点的值都小于其左孩子和右孩子结点的值,称之为小根堆。
数组最终的排序方法:升序建大堆,降序建小堆。
堆排序步骤:
第一步,将无序数组构造成一个大根堆。
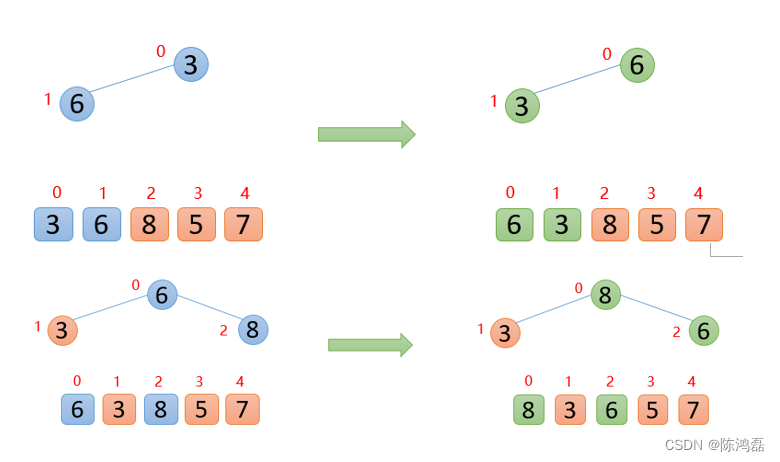
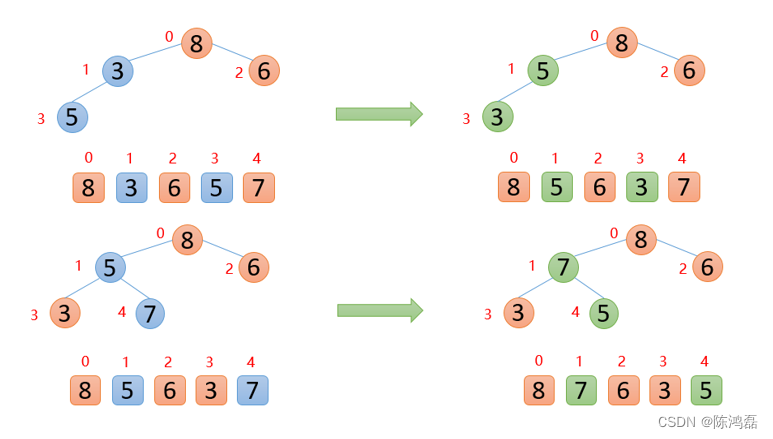
第二步,进行堆排序。
将顶端的数与最后一位数交换,然后将剩余的数再构造成一个大根堆。
然后再将顶端的数与最后一位数交换,然后将剩余的数再构造成一个大根堆。
重复执行上面的操作,最终会得到有序数组。
交换:
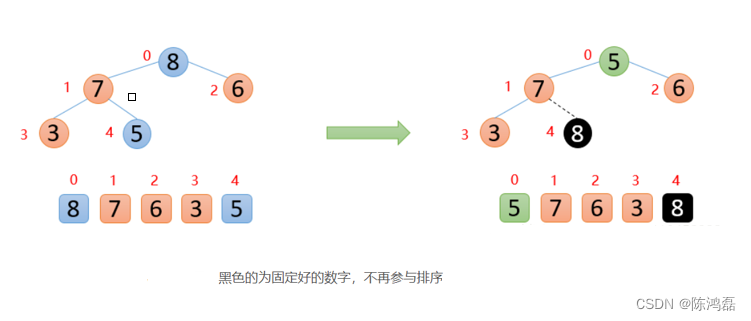
重新构造大根堆:
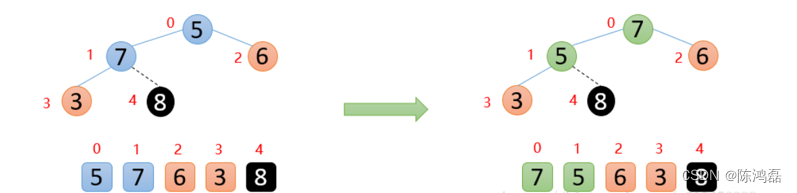
交换:

直至得到有序数组。
堆排序的时间复杂度分析:
堆排序分为两个步骤:第一步是将序列变成一个有序堆。
第二步是不断交换堆顶元素和堆底元素。
其中第一步的时间复杂度为O(n),第二步的时间复杂度为O(nlogn)。
最终的时间复杂度:O(n)+O(nlogn)=O(nlogn)。
堆排序的最好,平均,最坏时间复杂度均为O(nlogn)。
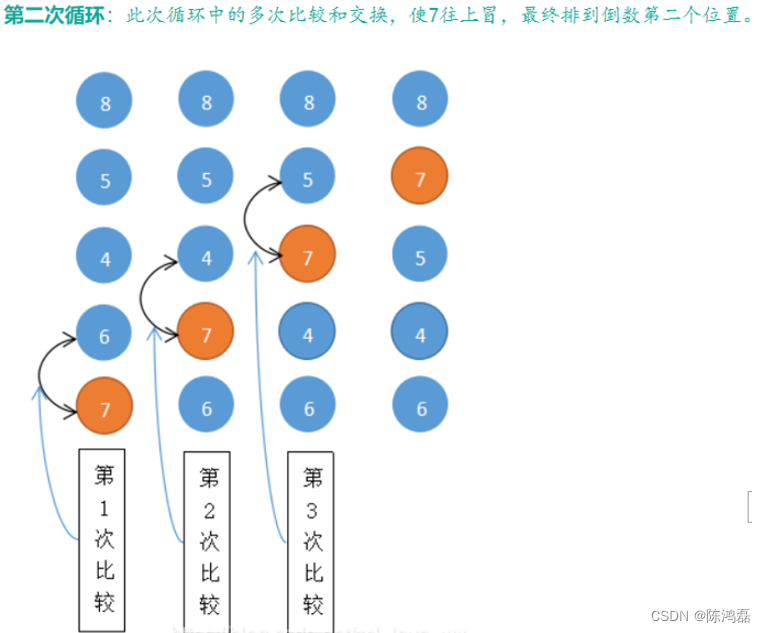
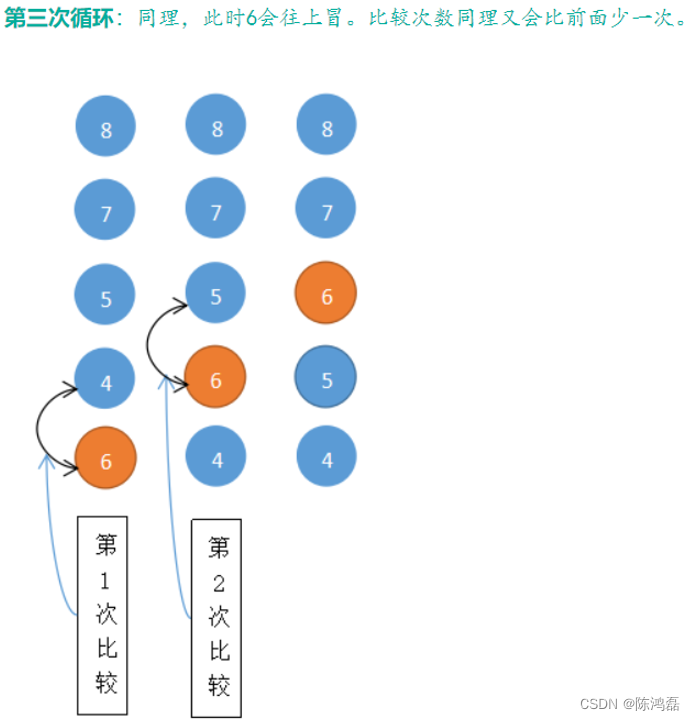
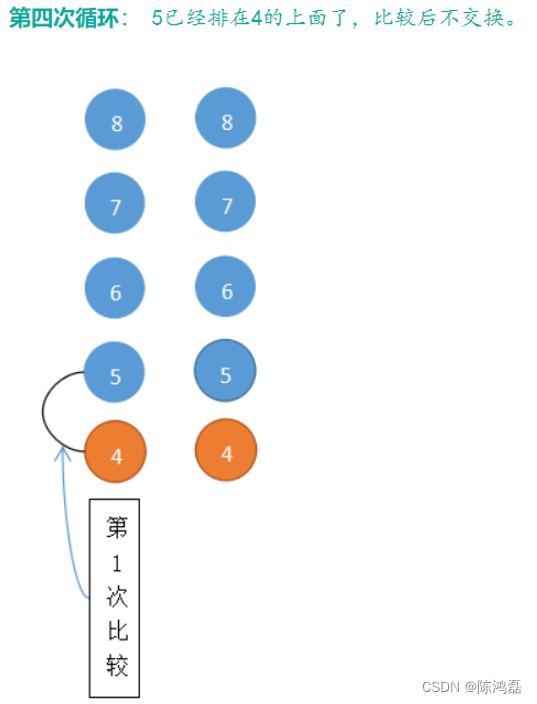
冒泡排序:
对于给定的一组数据,从第一个数开始,和第二个数比较,如果满足条件,就进行交换,然后第二个数和第三个数进行比较,如果满足条件,就进行交换,直到最后一个数,这是第一个“泡”已经冒出。然后从第二个数开始进行冒泡,一直到从最后一个数开始进行冒泡,直至全部的泡冒出。
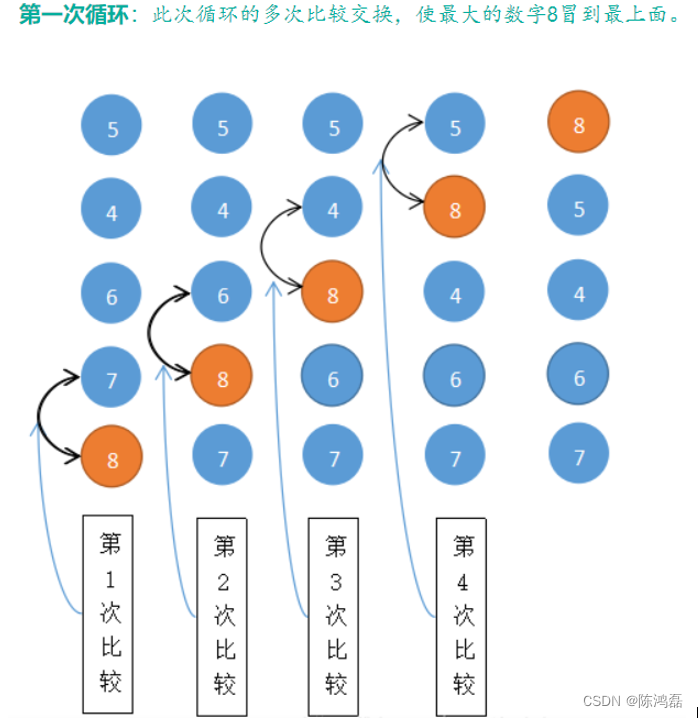
冒泡排序的时间复杂度分析:
正常情况下,冒泡排序的最好,最坏,平均时间复杂度均为:
O(n^2)。
但是如果在算法中加入flag标记,如果循环没有进行交换,可以理解为数组已经排好序,同时退出排序,此时最好情况为数组已经排好序,时间复杂度为O(n)。
void Bubble_Sort(int arr[], int size)
{
for(int row = 0; row < size - 1; ++row)
{
int flag = 1;
for(int col = 0; col < size - row - 1; ++col)
{
if (arr[col] < arr[col + 1])
{
//满足条件,进行交换。
int temp = arr[col + 1];
arr[col + 1] = arr[col];
arr[col] = temp;
flag = 0;
}
}
//数组为排好序的情况,退出排序。
if (flag == 1)
{
break;
}
}
}
快速排序:
对于一组数据6、1、2、7、9、3、4、5、10、8,分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。
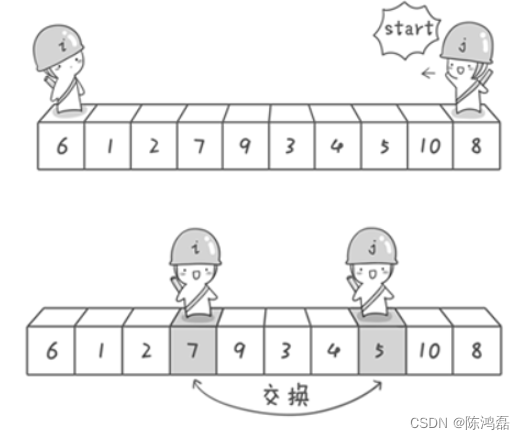
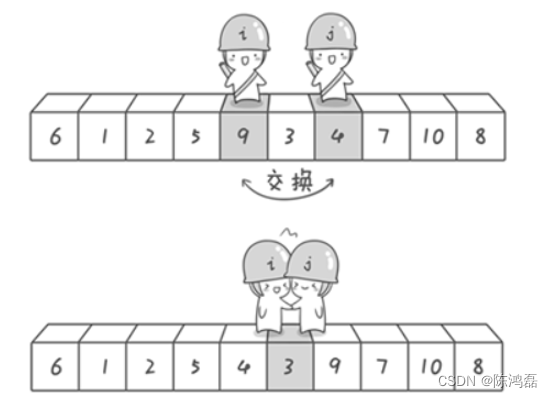
当哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下。

现在左边比6小,右边比6大。
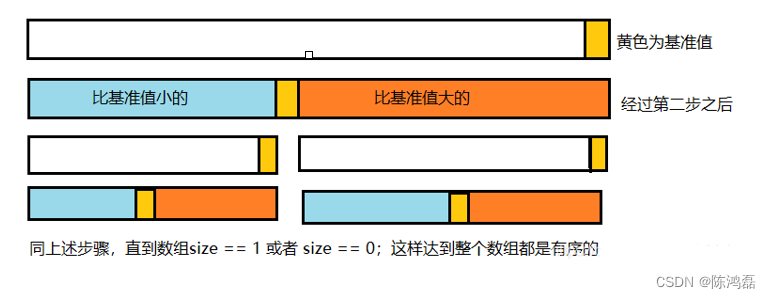
快速排序的时间复杂度分析:
快速排序的最好情况是:每次取到的元素都刚好能平分整个数组,此时时间复杂度为O(nlogn)。
平均情况也是O(nlogn)。
快速排序的最坏情况是:每次取到的元素都是最大或者最小的元素,这种情况其实就相当于是冒泡排序(每一次都排好一个元素的序列),时间复杂度为O(n^2)。
int partition(int arr[], int left, int right)
{
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end && arr[begin] <= arr[right])
{
++begin;
}
while (begin < end && arr[end] >= arr[right])
{
--end;
}
int temp = arr[begin]; //交换两个哨兵
arr[begin] = arr[end];
arr[end] = temp;
}
int temp = arr[begin];
arr[begin] = arr[right];
arr[right] = temp;//交换基准值和探测终点
return begin;//返回基准值下标
}
void QuickSort(int arr[], int left, int right)
{
if (left >= right)
{
return;
}
int povit = partition(arr, left, right);
//递归
QuickSort(arr, left, povit - 1);
QuickSort(arr, povit + 1, right);
}
归并排序:
对于一组数据5、7、8、9、4、1、3、2、6、10。
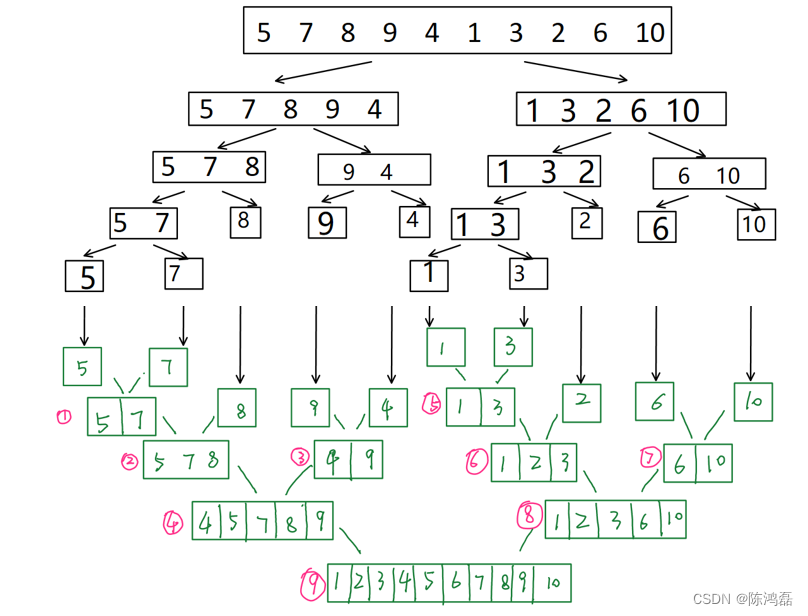
归并排序时间复杂度分析:
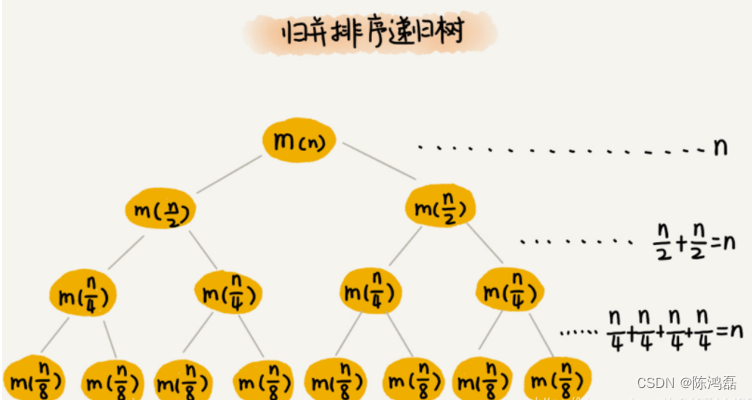
在归并排序算法中,每一次分解(归)的时间复杂度为O(1),比较耗时的是并操作,也就是把两个子数组合并成为一个大数组。从图中我们可以看出,每一层并操作消耗的时间总和是一样的,跟要排序的数据规模有关。我们把每一层归并操作消耗的时间记作 n。
设这棵树的高度 h,用高度 h 乘以每一层的时间消耗 n,就可以得到总的时间复杂度 O(n∗h)。
从归并排序的原理和递归树,可以看出来,归并排序递归树是一棵满二叉树。满二叉树的高度大约是 log2n,所以,归并排序递归实现的时间复杂度就是 O(nlogn)。
最好,最坏,平均时间复杂度均为O(nlogn)。
void MergeSort(int numbers[], int length, int temp[], int begin, int end)
{
if (end - begin == 0) return;
//分解
int middle = ((end - begin) / 2 ) + begin;
MergeSort(numbers, length, temp, begin, middle);
MergeSort(numbers, length, temp, middle + 1, end);
//合并
Merge(numbers, length, temp, begin, end, middle);
}
void Merge(int numbers[], int length, int temp[], int begin, int end, int middle)
{
int leftIndex = begin; //左序列的开始(左序列的结尾是middle)
int rightIndex = middle + 1;//右序列的开始(右序列的结尾是end)
int tempIndex = begin;
while (leftIndex <= middle && rightIndex <= end)
{
//两两比较,大的放入辅助数组,同时指针后移
if (numbers[leftIndex] < numbers[rightIndex])
temp[tempIndex] = numbers[leftIndex++];
else
temp[tempIndex] = numbers[rightIndex++];
//更新辅助数组下标
++tempIndex;
}
//当左边或右边子序列尚未到头时,放入辅助数组。
while (leftIndex <= middle)
temp[tempIndex++] = numbers[leftIndex++];
while (rightIndex <= end)
temp[tempIndex++] = numbers[rightIndex++];
//将辅助数组中已经有序的元素覆盖掉原数组中无序的元素,使原数组变成部分有序
for (int i = begin; i <= end; ++i)
numbers[i] = temp[i];
}
基数排序:
对于一组数据23、1、4、9、98、132、42。

基数排序的时间复杂度分析:
基数排序每一位的比较可以使用线性排序,比如桶排序或者计数排序,当然需要保证如计数排序的稳定性。每次排序时间复杂度O(n),那么如果有k位,则时间复杂度为O(k*n)。
最好,平均,最坏均为O(k*n)。
//求数据的最大位数,决定排序次数
int maxbit(int data[], int n)
{
int d = 1;
int p = 10;
for(int i = 0; i < n; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;
}
void radixsort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int tmp[n];//辅助数组
int count[10]; //count数组用来保存data数组中数据的位数0-9的数量
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) //进行d次排序
{
//每次分配前将count数组的值均赋为0
for(j = 0; j < 10; j++)
count[j] = 0;
//获取数据的位数,并更新count数组
for(j = 0; j < n; j++)
{
//k为数据的位数
k = (data[j] / radix) % 10;
//更新该位数的数量
count[k]++;
}
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j];
for(j = n - 1; j >= 0; j--)
{
//k为数据的位数
k = (data[j] / radix) % 10;
//依次将data数组的值赋给辅助数组tmp
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) //更新data数组
data[j] = tmp[j];
radix = radix * 10;//更新基数
}
}
(注:图片来源于网络,侵权必删。)


















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











