






 本文介绍了回归分析在深度学习中的应用,包括股价预测、自动驾驶及推荐系统等场景,并详细讲解了模型设计、函数优度评估及寻找最佳函数的过程。通过Pokemons案例展示了不同阶次多项式函数的表现,并探讨了过拟合问题及解决方法。
本文介绍了回归分析在深度学习中的应用,包括股价预测、自动驾驶及推荐系统等场景,并详细讲解了模型设计、函数优度评估及寻找最佳函数的过程。通过Pokemons案例展示了不同阶次多项式函数的表现,并探讨了过拟合问题及解决方法。
哦吼,深度学习开始了,要加油啊!早一点把模型搞懂,老师就不用push我了,哭哭!
目录
(1)Stock Market Forecast——股价预测
一、Regression回归
1、应用场景
(1)Stock Market Forecast——股价预测
(2)Self-driving Car——自动驾驶
(3)Recommendation——推荐系统
2、步骤
(1)给一个Model
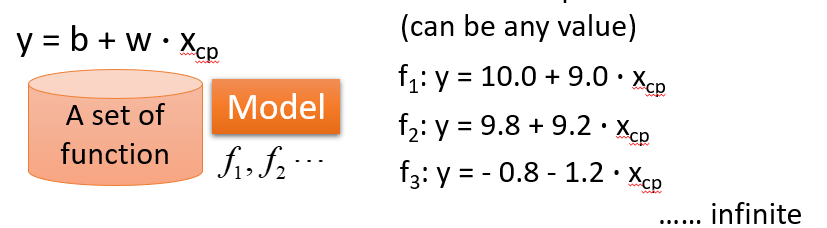
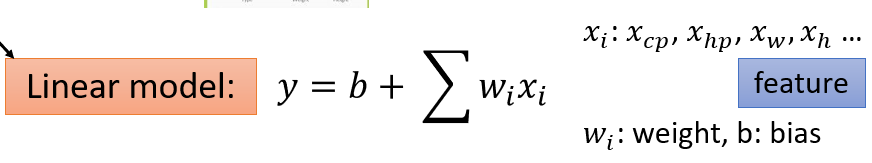
(2)Goodness of Function(函数优度)
输入:a function一个函数
输出:loss funchtion——how bad it is
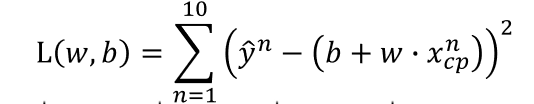
(3)Find the best function
梯度下降:初试化w和b这两个参数,不断迭代更新,知道找到最优解,也就是使损失值达到最小的参数值
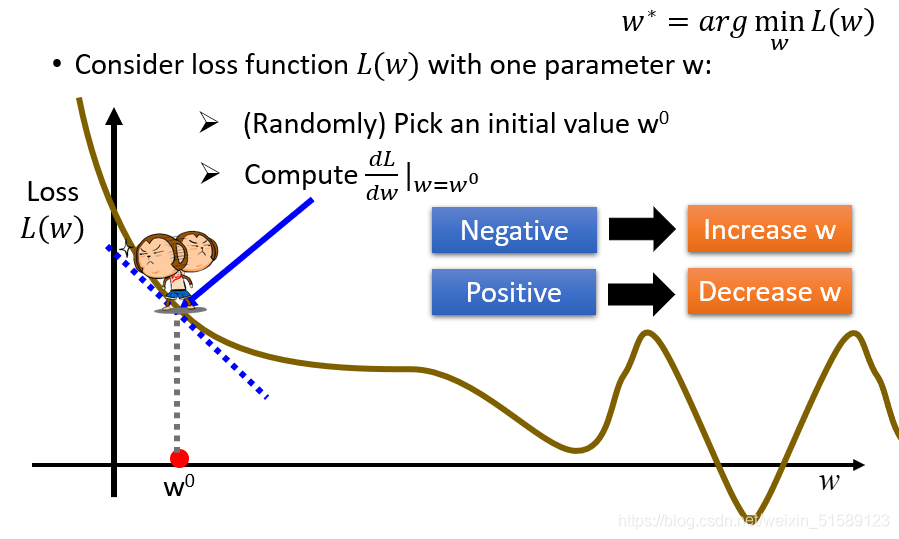
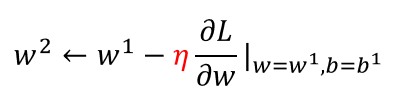
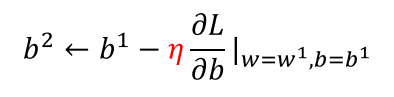
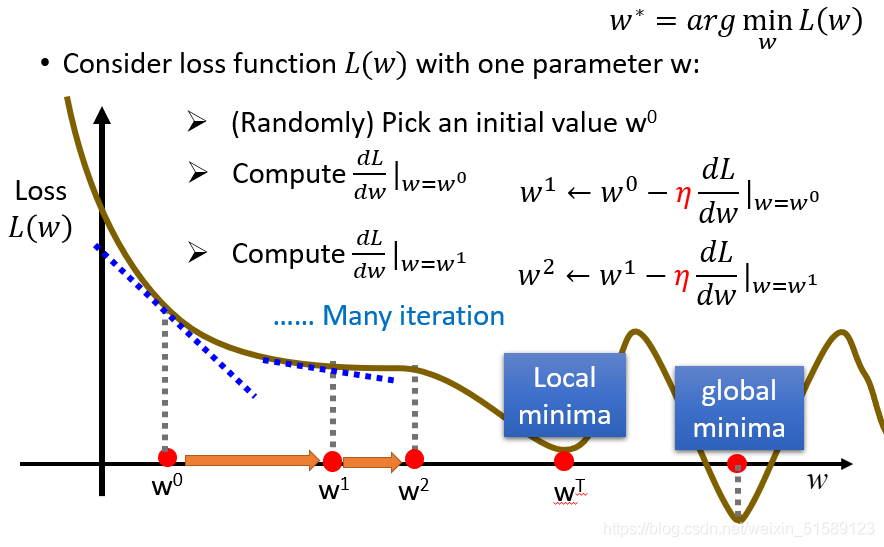
有可能会在局部最小值处停止
在线性回归里,是不需要担心找不到全局最优解的,因为其三维图形是一圈一圈的等高线,不管从哪个方向都可以找到最优解
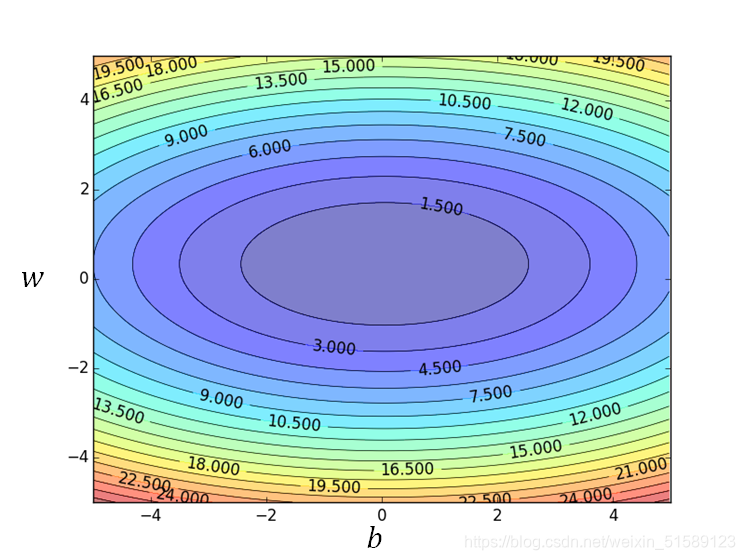
二、案例——pokemons
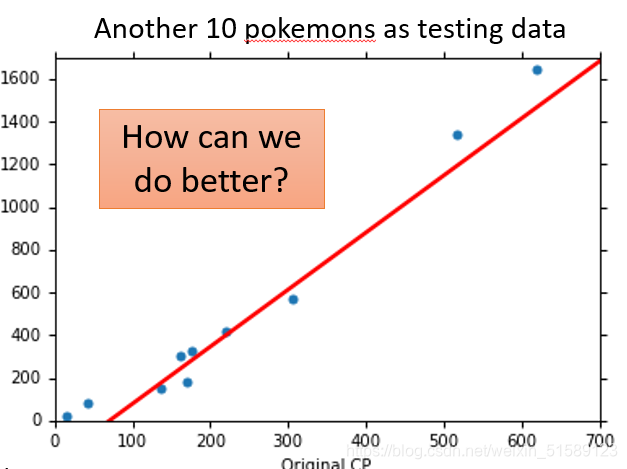
how's the results?
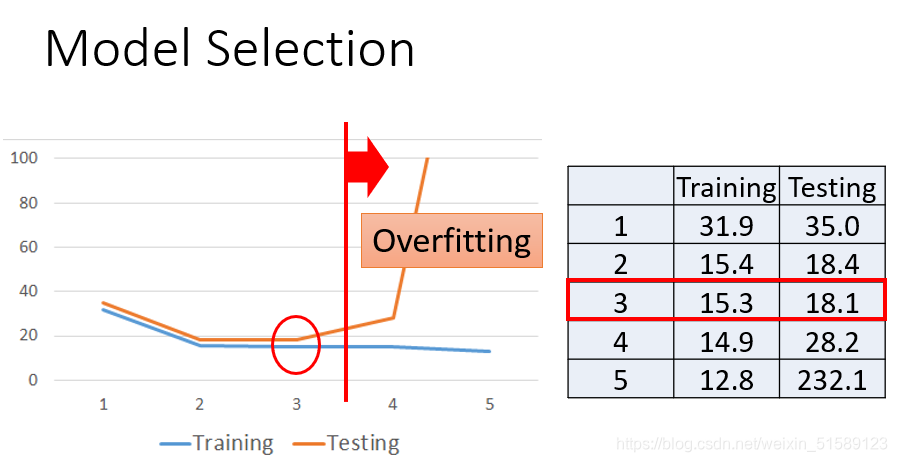
训练的目的是损失值最小,但是通过训练集得到的损失值是比测试集得到的损失值小的,为了减少误差,我们需要改进模型——引入了二次方、三次方和四次方的函数
(1)一次方函数式实验结果:
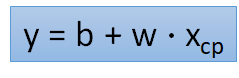
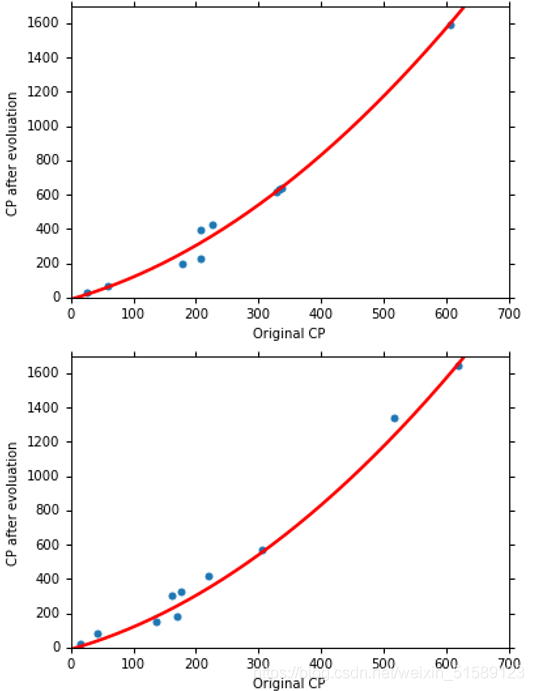
(2)二次方函数式实验结果:
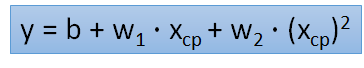
训练集和测试集的结果
(3)三次方函数式实验结果:
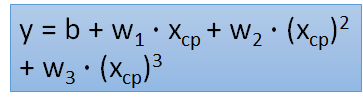
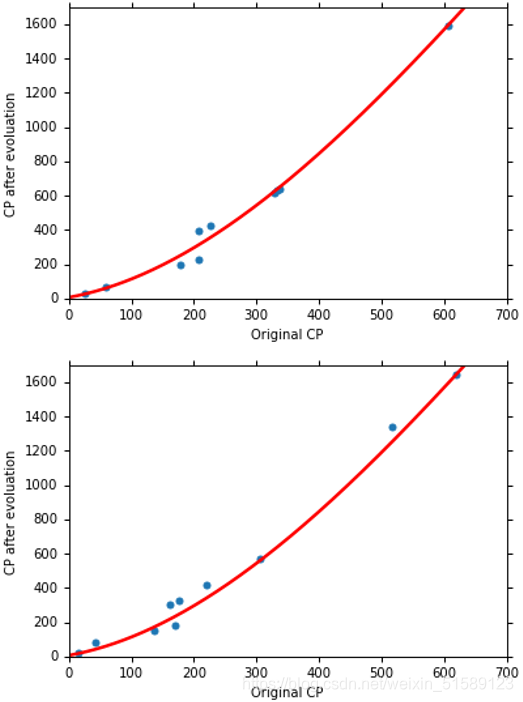
(4)四次方函数式实验结果:
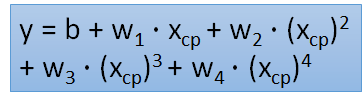
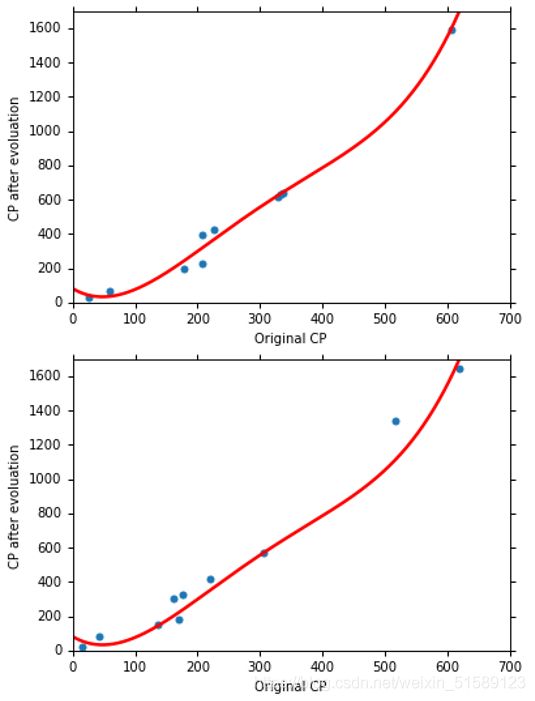
(5)五次方函数式实验结果:
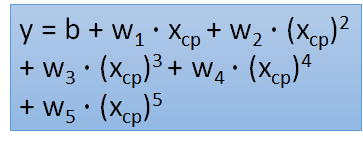
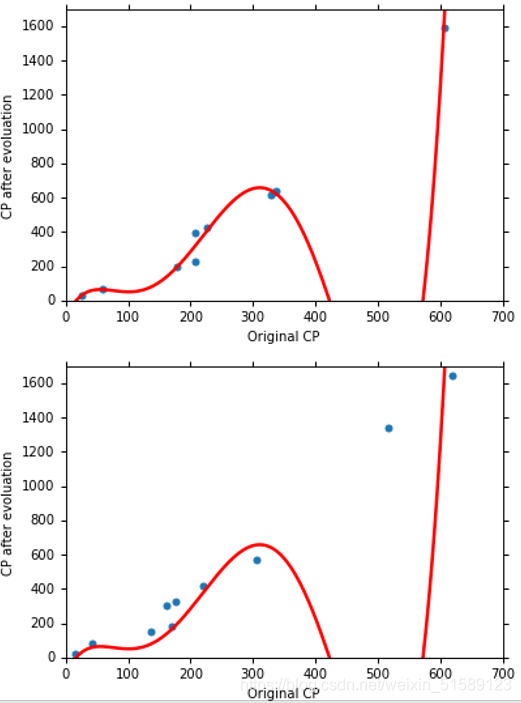
overfitting——更复杂的模型会得到更不好的结果,所以模型并不是越复杂越好。
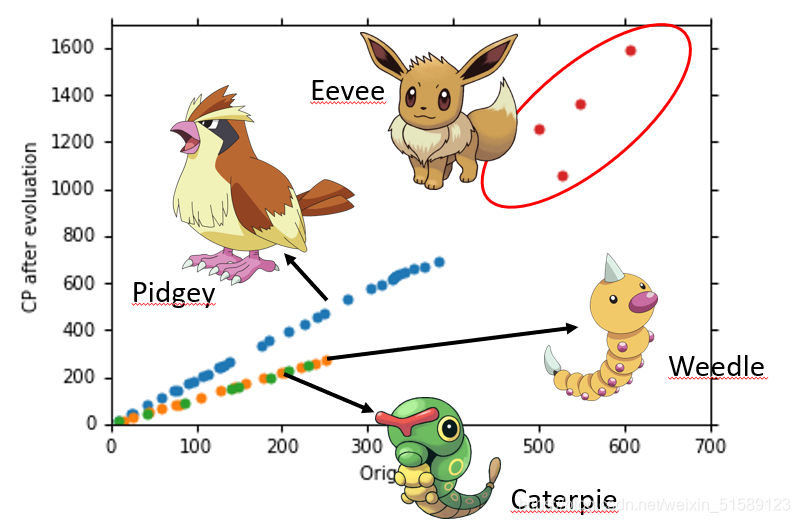
what are the hidden factors——pokemon的物种会影响他们值
Let’s collect more data
收集更多的数据,考虑更多影响因素——物种
回到第一步,建立模型

根据不同的输入值,对不同的物种设置不同 的权重,此时仅设置了输入值的一次方,还可以考虑输入值的二次方函数
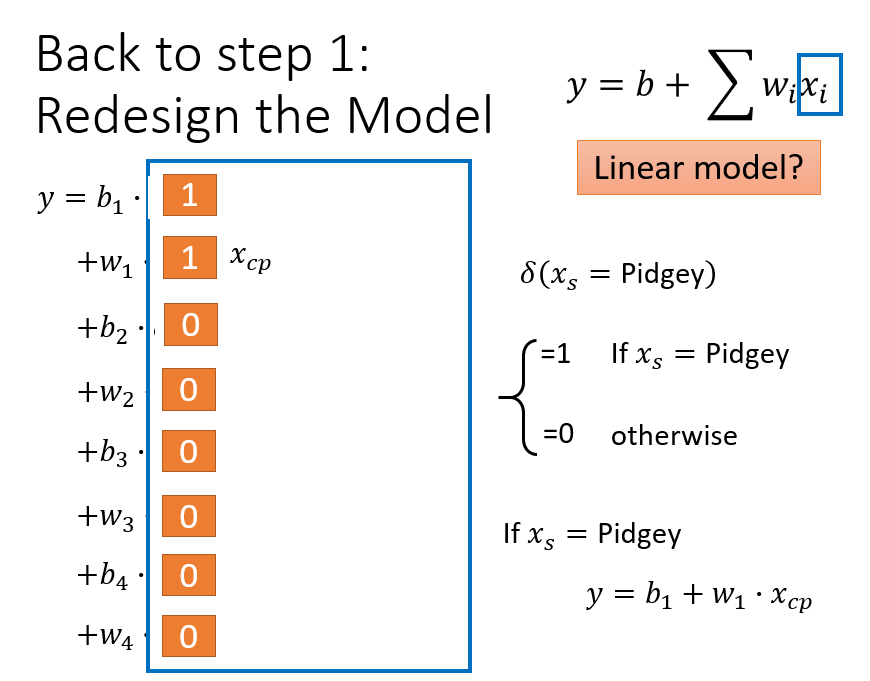
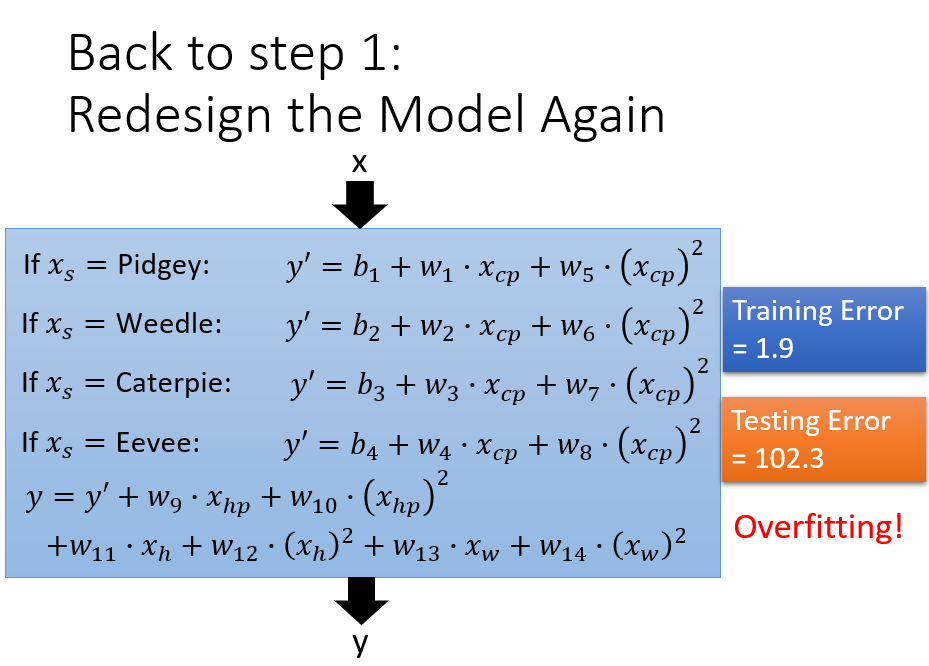
重新设计模型,考虑二次方、三次方等高次方情况
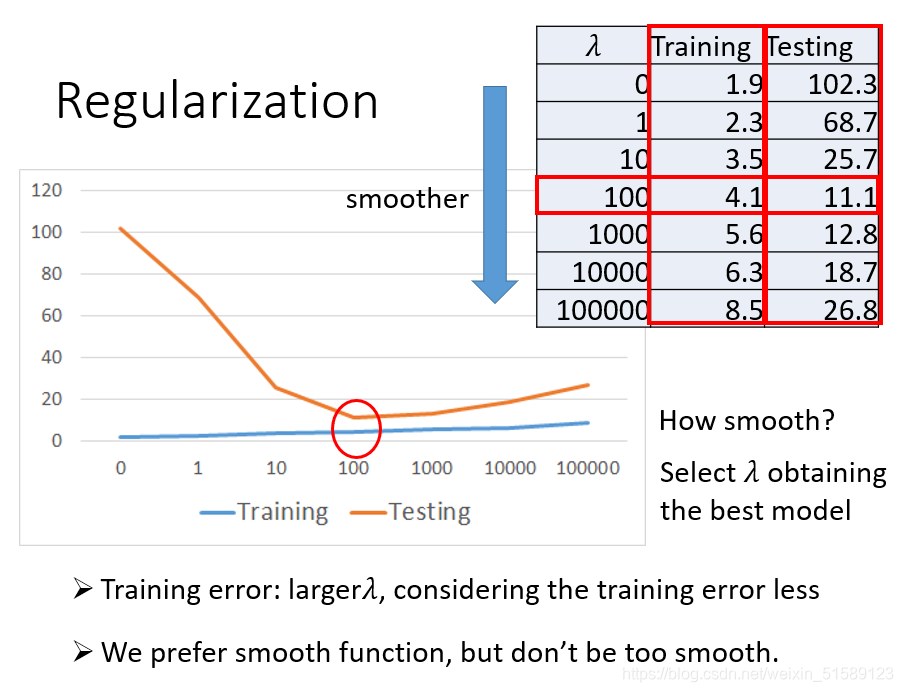
Regularization

选择合适的系数值
设置较为平缓的曲线,由于w的值大于零小于1,当其越接近于0,结果是越为平缓的,前面的系数越大,代表我们越考虑smooth,越可以较多得关注参数w本身的值
三、基本概念
bias&variance
误差来源于两个——一个是bias,还有一个是variance。出现bias是由于开始就没有瞄准靶心;出现vaiance是由于瞄准了靶心,但是发射的时候出现了偏离。我们的目标是低bias和低variance。
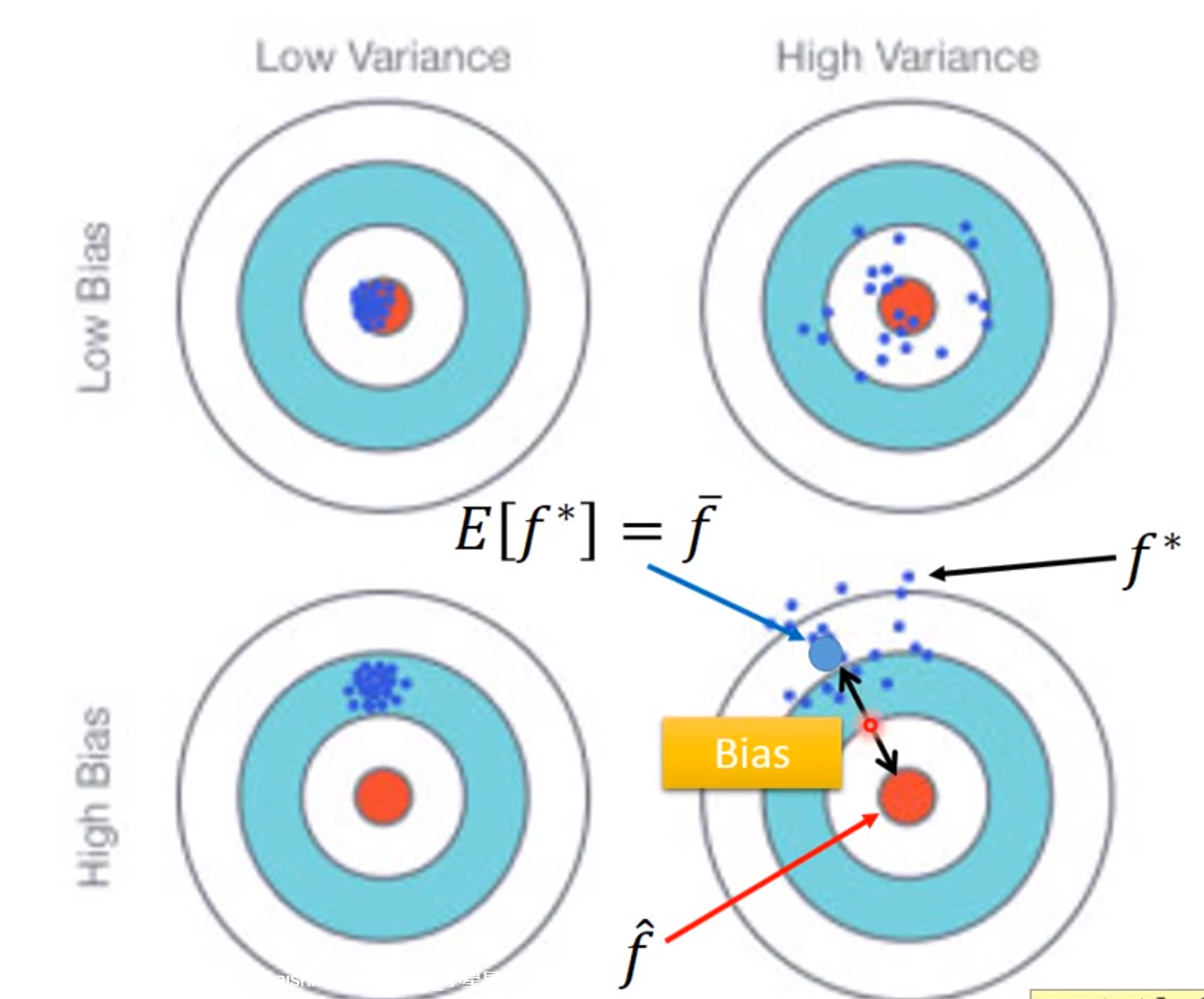
红色的部分是分别在考虑输入值一次方、三次方和五次方函数进行5000次实验的结果,蓝色的线条是将5000次实验结果进行平均即结果
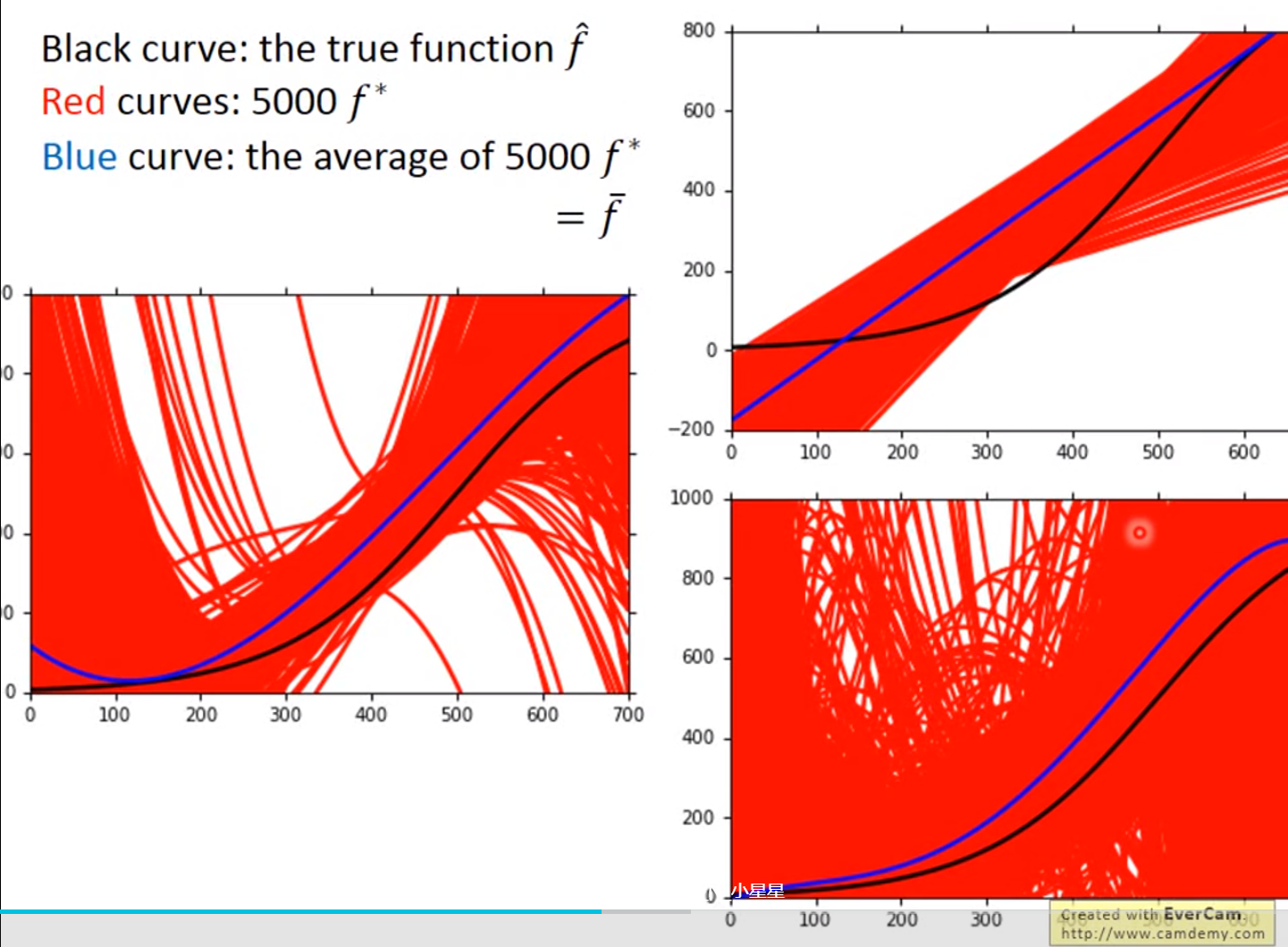
我们可以得出结果,模型过于简单的时候,可能会出现较大的bias,模型比较复杂的时候,variance较大,但是实验结果进行平均之后,值接近于期望值
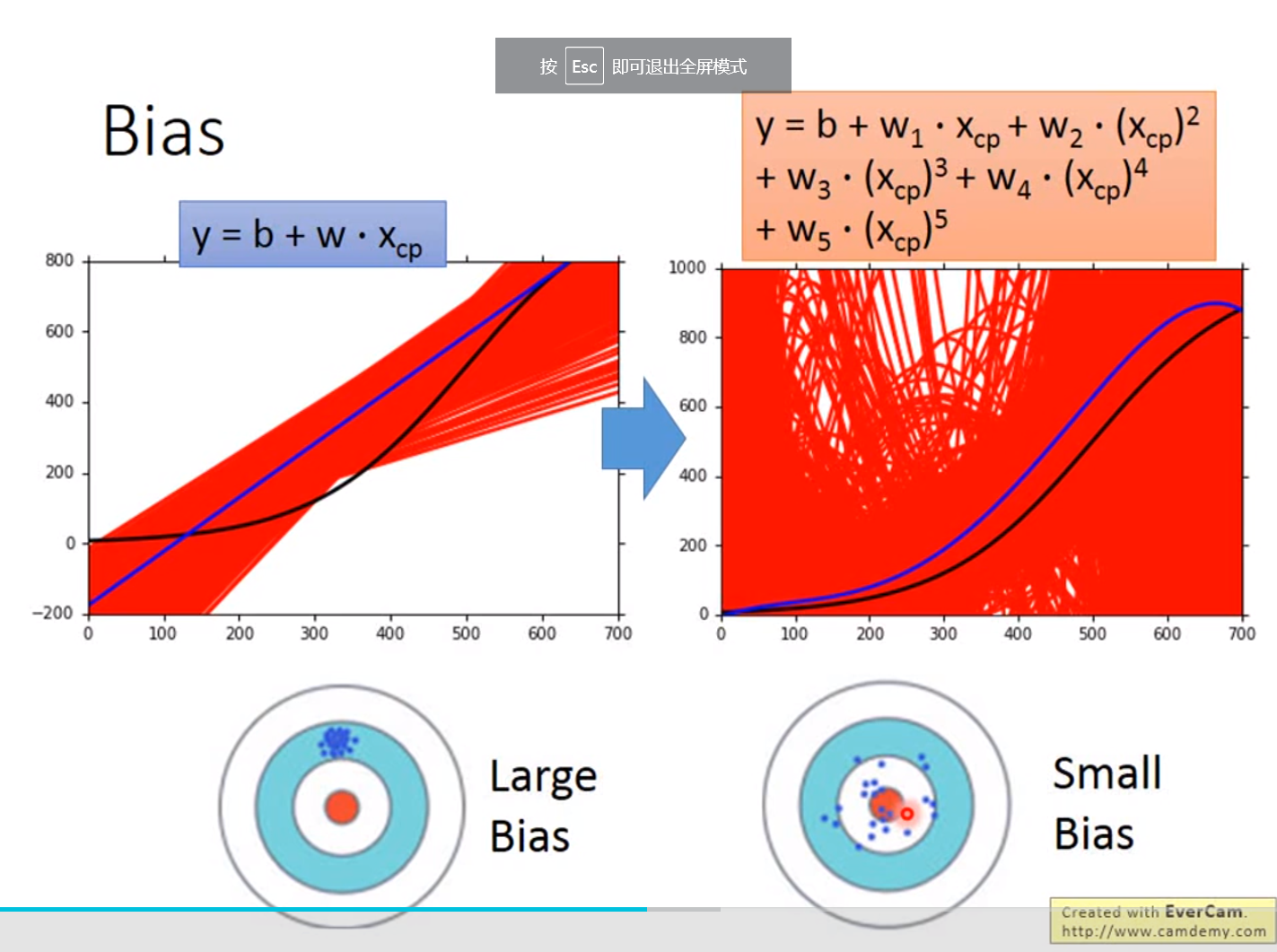
越简单的模型,bias越大,variance比较小;反之,模型越复杂,variance越大,但是平均值却比较接近于期望值
bias较大的情况,问题出现在underfitting;
Diagnosis:
(1)当模型不能拟合训练集时,我们有较大的bias;
(2)当模型可以集合训练集,但是在测试集上出现了较大的损失值,则很大可能上有较大的variance,variance较大的情况,问题出现在overfitting
解决方案:
for bias, redesign模型:
(1)add more feature as input
(2)a more complex model
for variance
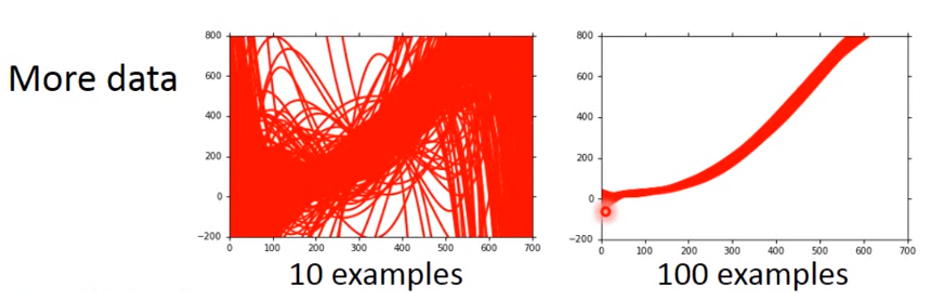
(1)more data(增加每次实验的样本量)
(2)Regularization我们希望曲线越平缓越好
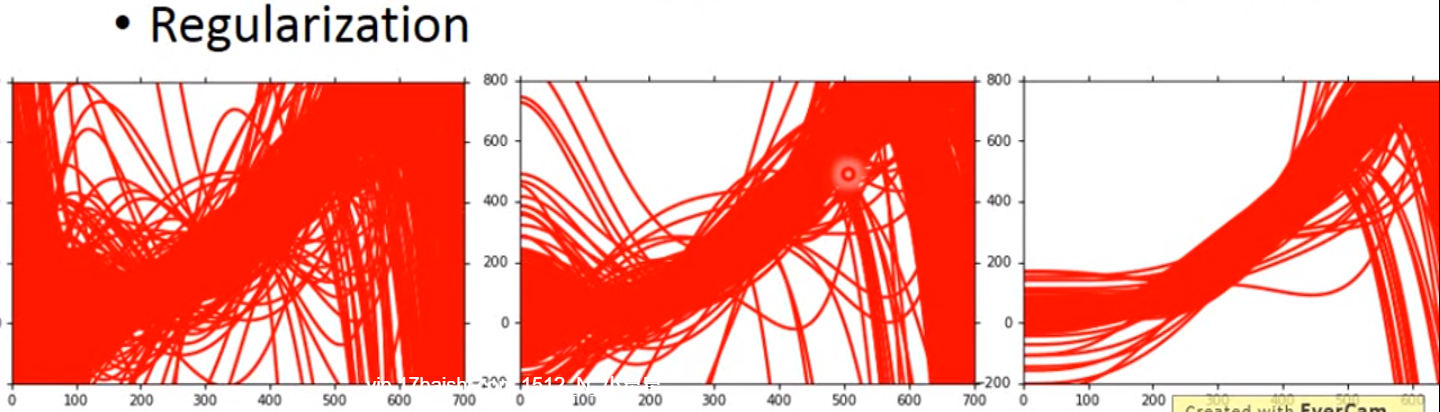
伤害:只包含了比较平滑的曲线,在取值上产生了较大的bias
model selection:
我们想要找到合适的bias和variance来得到最小的损失值

















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









