 AI驱动生物信息学十年展望
AI驱动生物信息学十年展望





要点
❶ 将人工智能(AI)技术分为3大核心支柱。传统机器学习适用于特征明确的分析任务。深度学习(尤其是基于 Transformer 的模型,如 AlphaFold2)通过从海量数据中自动学习,在序列分析和结构预测领域取得了革命性突破。强化学习通过试错优化策略,在药物分子从头设计等探索性任务中发挥关键作用。
❷ 展示了 AI 在解决生物信息学核心问题中的广泛应用。例如,精准识别基因组学中的功能元件(如 DNABERT)、实现蛋白质组学中的高精度结构预测与设计(如 AlphaFold)、高效处理单细胞分析中的高维数据(如 scGPT),以及加速从靶点发现到候选药物筛选的全流程。
❸ 指出了 AI 应用面临的多项严峻挑战。数据层面,生物数据普遍存在噪声、稀疏性和批次效应,严重影响模型性能。模型与算法层面,高效处理超长生物序列(如人类基因组)、有效整合多模态异质性数据(如基因组学与影像数据),是尚未解决的关键技术瓶颈。
❹ 展望,未来的核心机遇在于构建生物信息学领域的大规模基础模型(Foundation Models)。通过在海量生物数据上进行预训练,这些模型能够学习可泛化、可迁移的生物学原理,从而极大推动创新药物发现与精准个性化医疗的发展。
❺ 强调,推动领域发展离不开开放协作的研究生态系统。这需要共享高质量数据与模型,促进生物学家、计算机科学家和临床医生之间的紧密跨学科协作,共同加速科学发现与技术转化。
引言
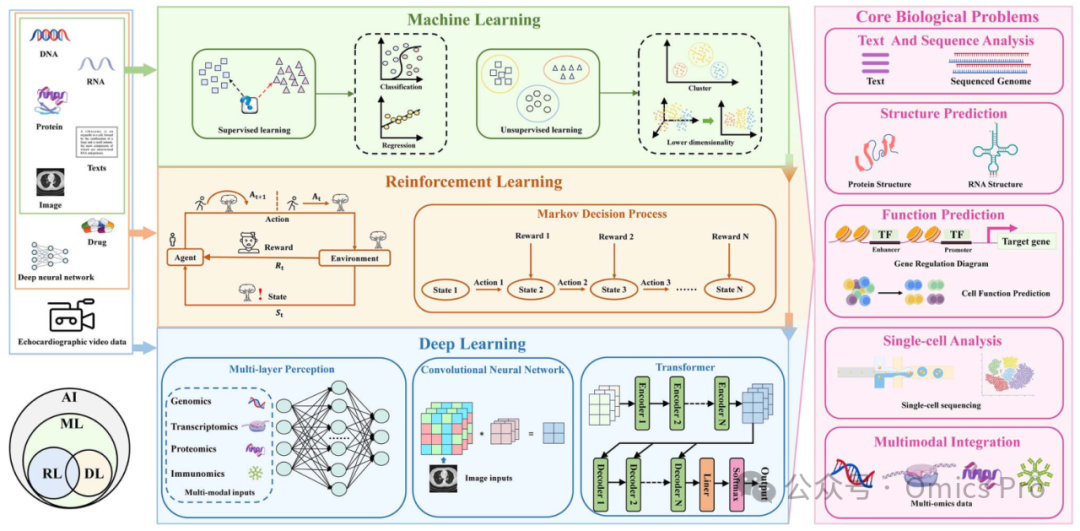
图1
生物信息学中的人工智能利用机器学习、强化学习和深度学习分析多模态输入(如基因组序列、医学影像和化学结构),以解决从蛋白质结构预测、基因调控到单细胞分析和分子从头设计等核心生物学问题。
生物信息学中的AI技术
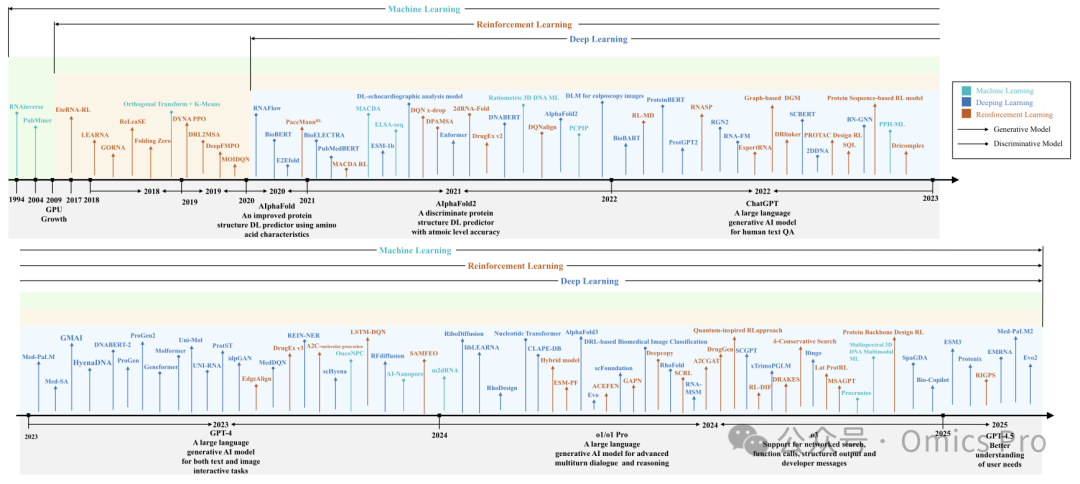
图2
该时间线展示了 2004 年至 2025 年 AI 在生物信息学中的发展历程,重点标注了从早期机器学习应用到 AlphaFold、BioBERT 等先进深度学习模型的关键里程碑。
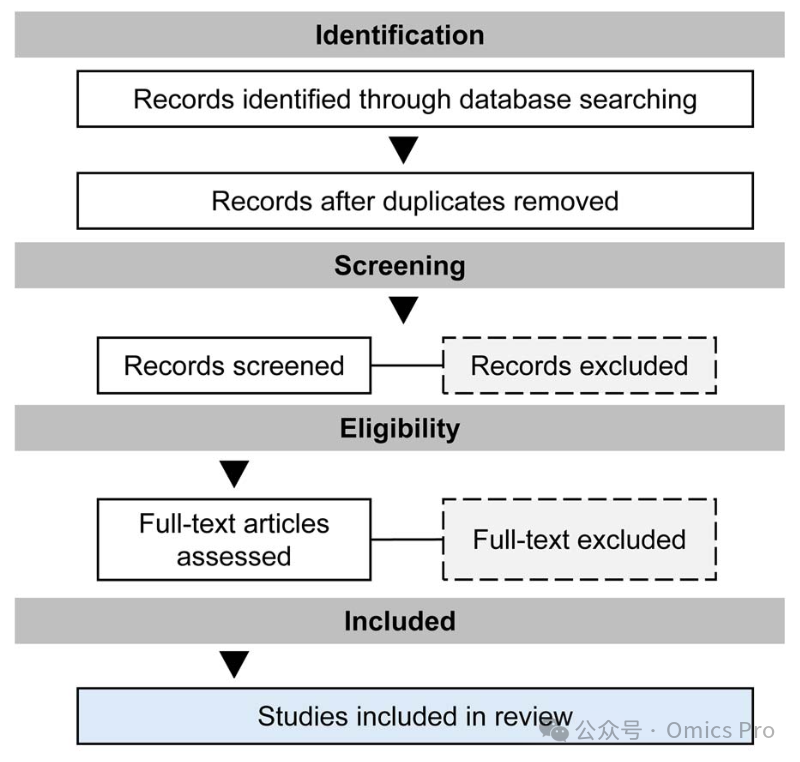
图3 文献筛选的PRISMA流程图
表1 本文使用的缩写及任务-指标对应表
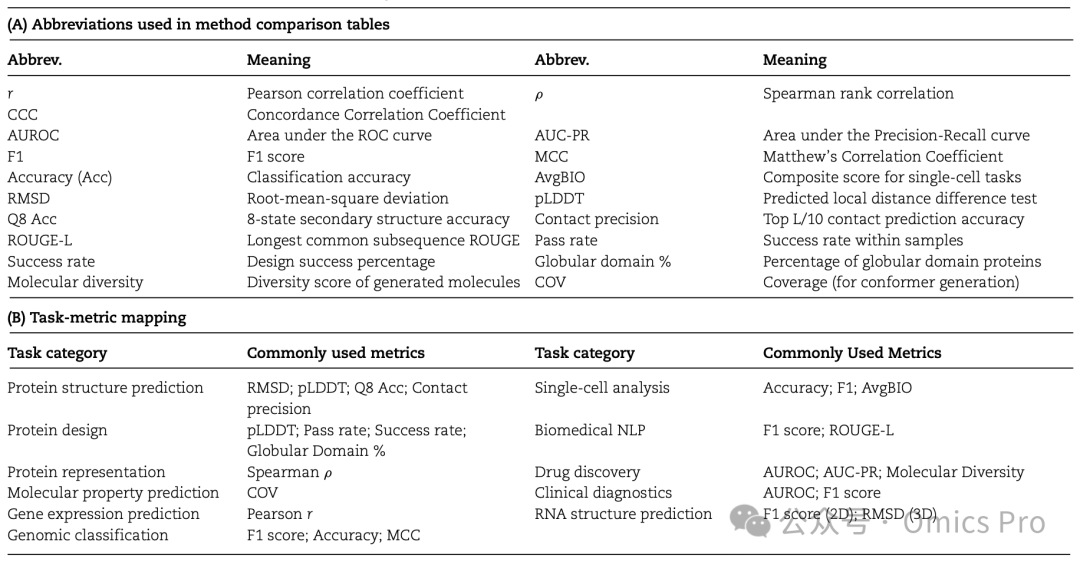
表2 代表性AI方法(含数据集、应用领域、指标及核心成果)
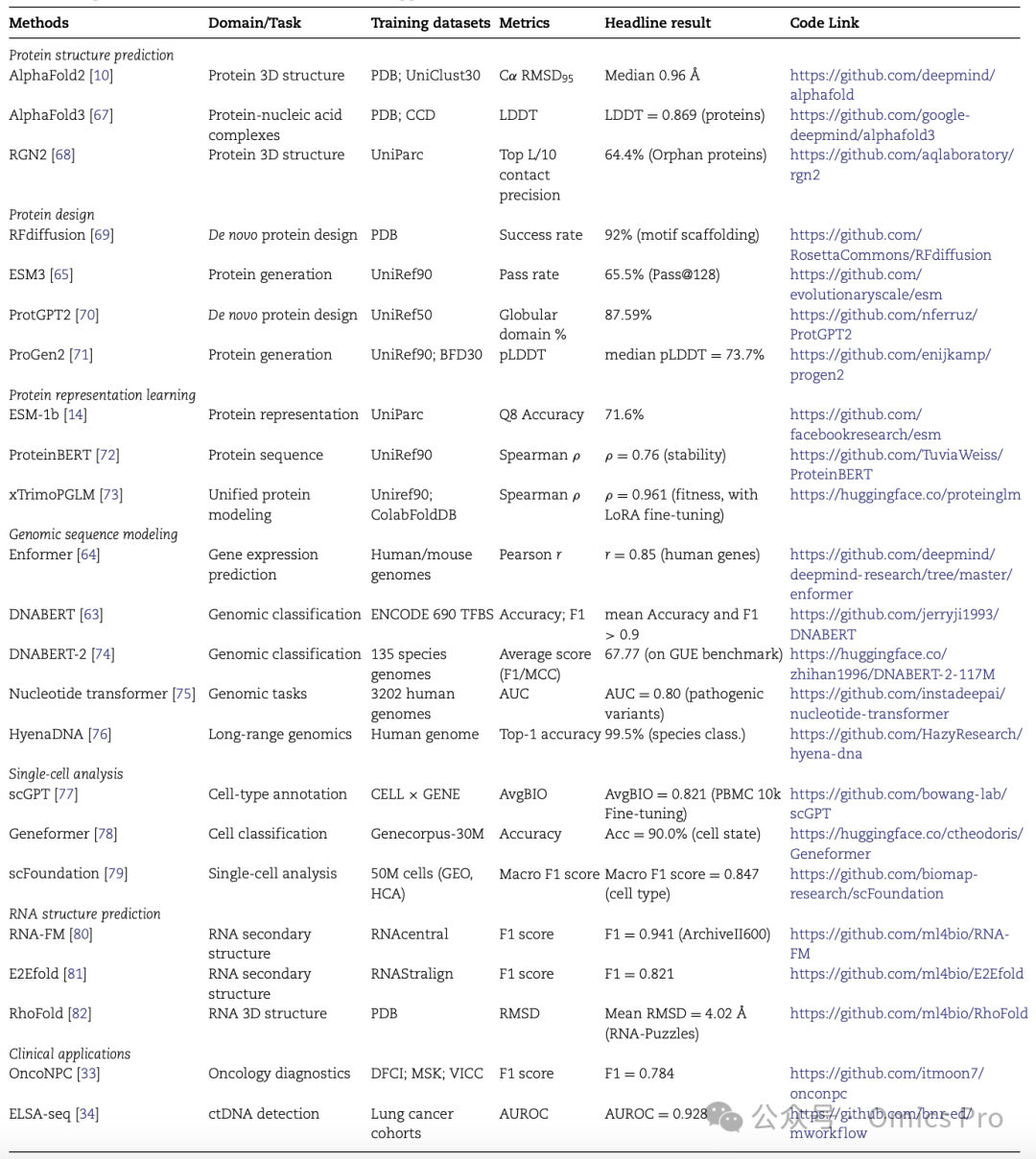
表3 代表性AI方法(第3部分:生物医学自然语言处理与药物发现)
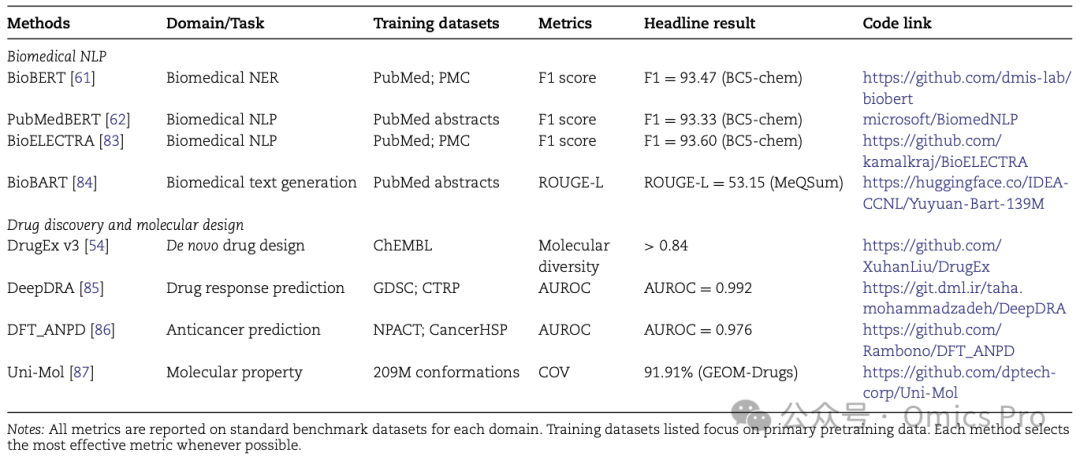
表4
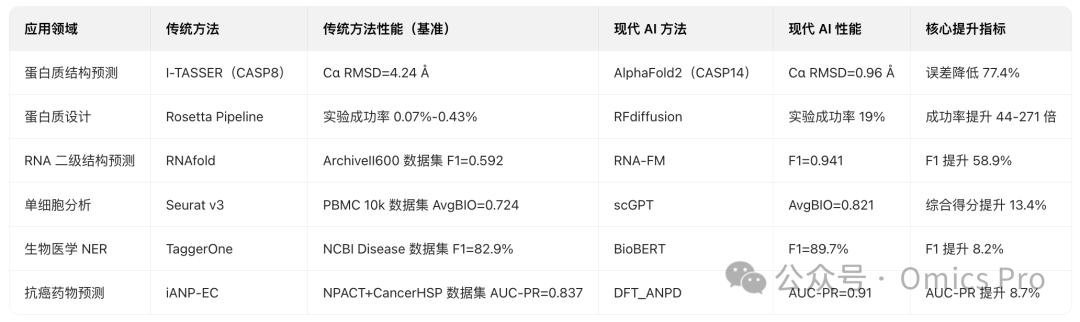
该基准表基于表 2 和表 3 定义的核心生物医学领域,每个领域选取 1 个代表性案例,全面对比传统方法与现代深度学习方法的性能。
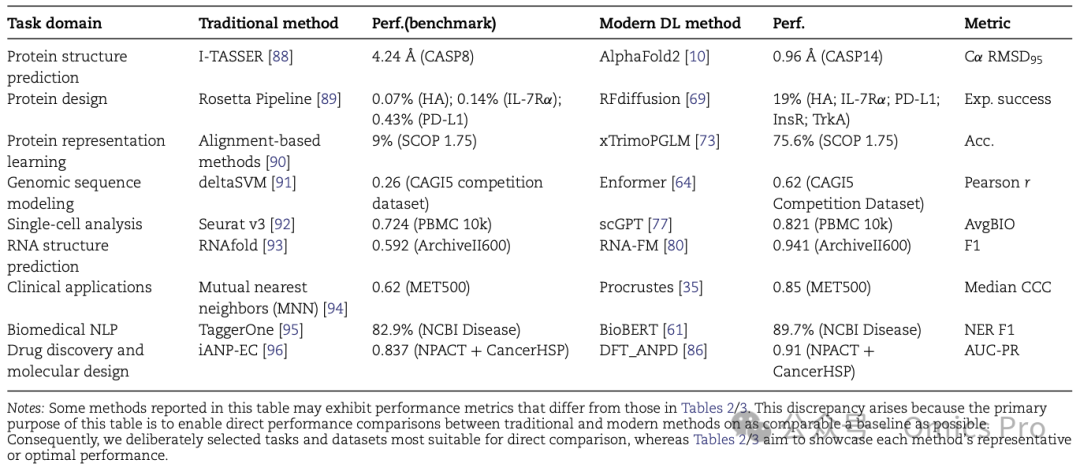
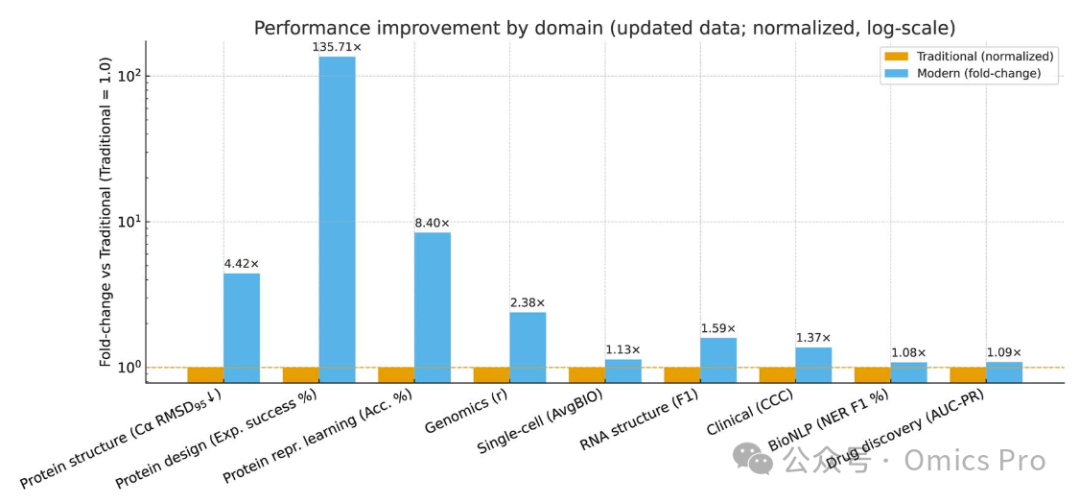
图4 该图表以对数尺度量化现代深度学习相对传统方法的性能提升倍数
将传统方法性能归一化为 1.0,根据指标类型(“越高越好”,如实验成功率、准确率;“越低越好”,如 Cα 原子均方根偏差)采用特定公式计算。需明确说明:这类跨代比较(如 CASP8 与 CASP14)仅在特定任务内有效,不可跨领域直接对比
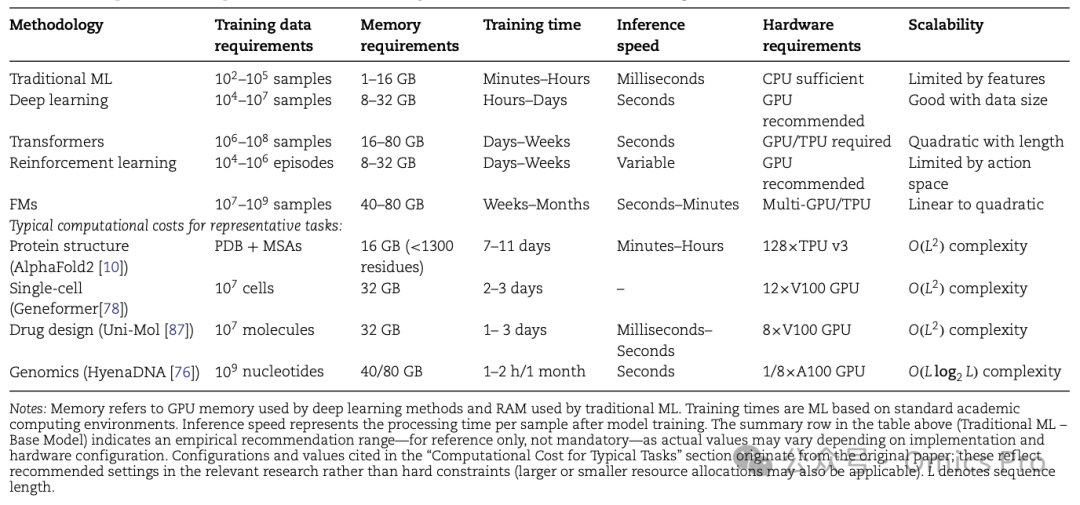
表5 生物信息学中AI方法的计算需求与可扩展性特征
挑战
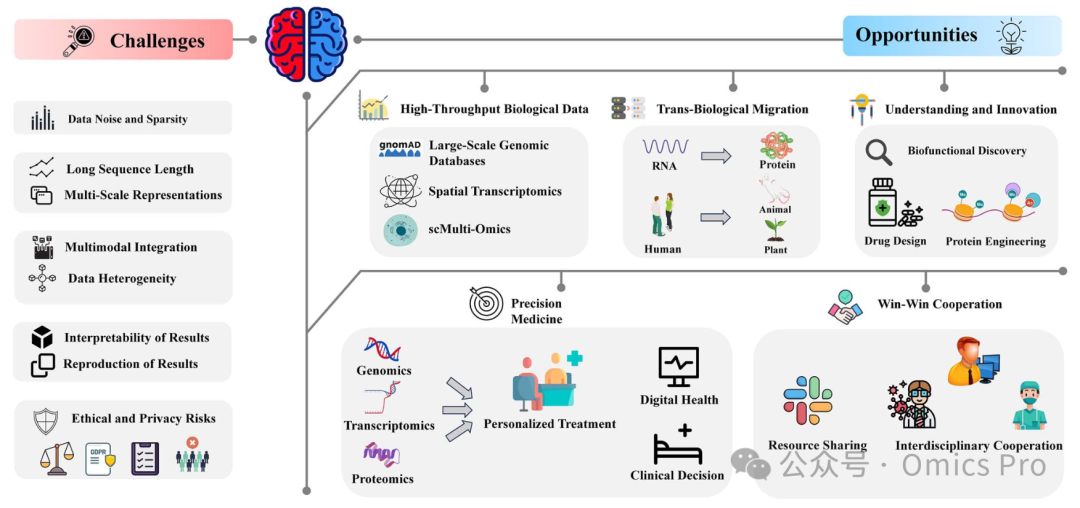
图5
挑战源于数据处理的复杂性(如噪声、长序列、多模态整合、可解释性、隐私问题),而机遇在于利用高通量数据、提升模型泛化能力、解析生物学功能、创新药物发现,以及实现个性化医疗与精准诊断。
详细总结
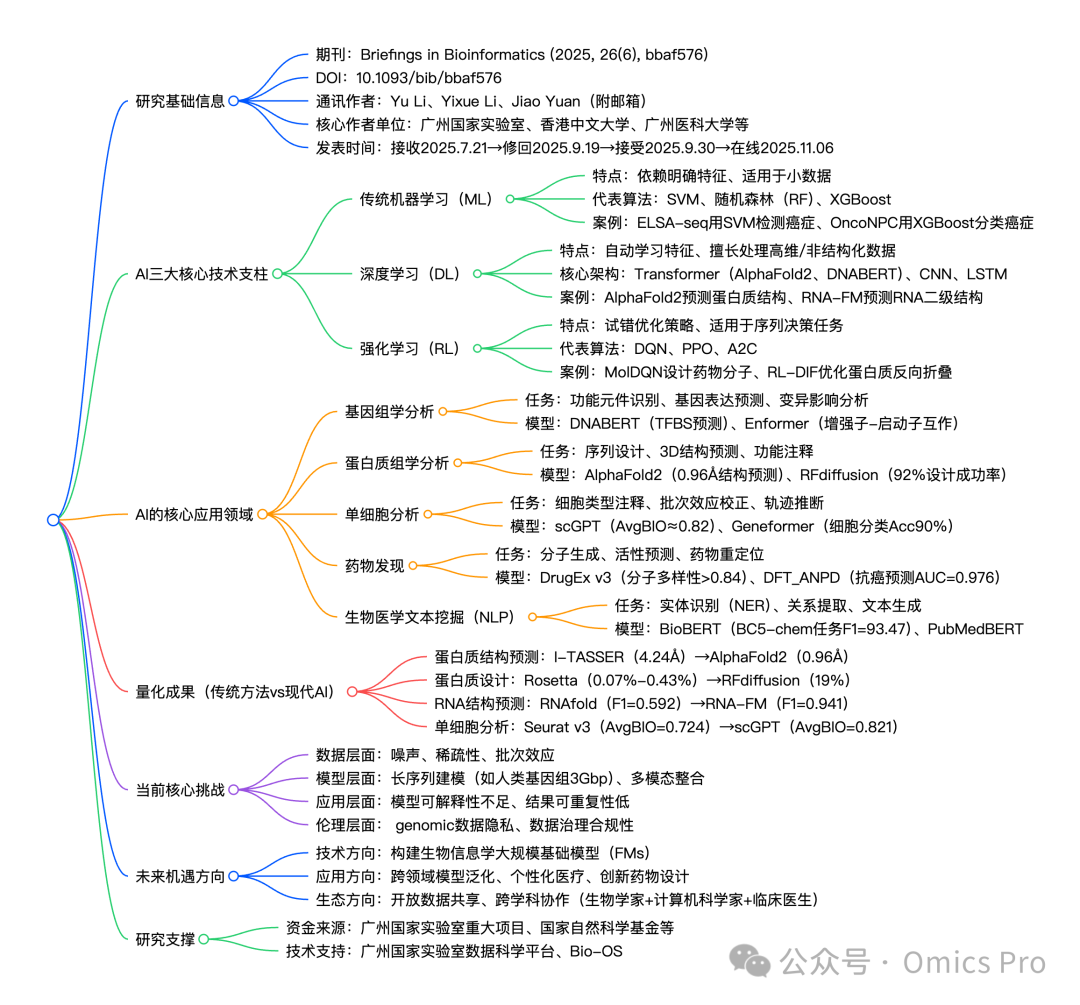
思维导图
研究基础信息

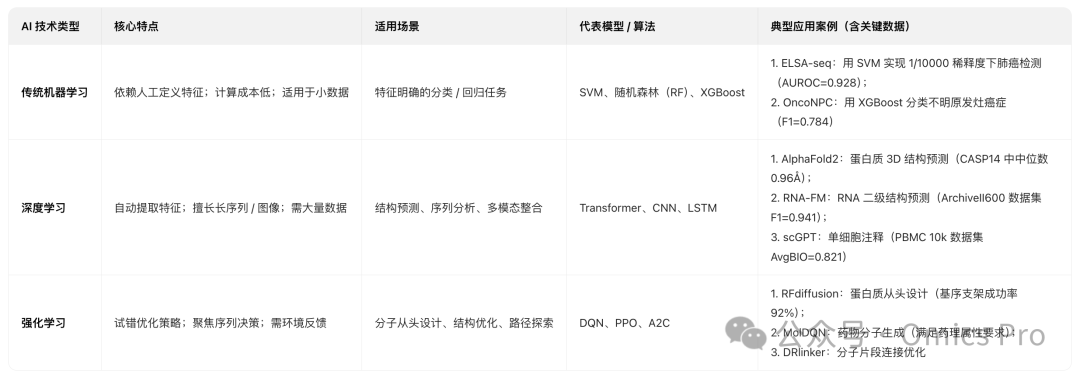
AI三大核心技术及应用场景
AI在生物信息学中的量化成果(传统方法 vs 现代AI)
3者的核心差异与适用场景可通过下表明确,选择需结合 “数据规模、任务类型、特征清晰度” 3要素:

参考
Brief Bioinform. 2025 Nov 1;26(6):bbaf576. doi: 10.1093/bib/bbaf576. Artificial intelligence in bioinformatics: a survey
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。

















 5730
5730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









