







nn.Module
在 PyTorch 里,torch.nn.Module 是所有神经网络模块的基类。自定义的神经网络模型通常会继承 nn.Module 类,通过定义 __init__ 方法来初始化模块的层,定义 forward 方法来定义前向传播过程。
import torch
import torch.nn as nn
# 定义一个简单的神经网络模块
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
# 定义全连接层
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
# 前向传播过程
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleNet()
# 输入数据
input_data = torch.randn(1, 10)
# 前向传播
output = model(input_data)
print(output)__init__ 方法:用于初始化模块的层,一般把网络中具有可学习参数的层(如全连接层、卷积层 等)放在构造函数__init__()中,这里定义了两个全连接层 fc1 和 fc2。
forward 方法:定义了输入数据 x 在前向传播过程中经过的操作,包括激活函数 torch.relu, forward 方法是必须要重写的。
创建模型实例后,可以直接将输入数据传递给模型实例,就像调用一个函数一样,这会自动调用 forward 方法。这里将所有的层都放在了构造函数__init__里面,但是只是定义了一系列的层,各个层之间到底是什么连接关系并没有,而是在forward里面实现所有层的连接关系。
卷积神经网络CNN
原理:卷积核在输入中来回移动,并且对应格子进行相乘,把9个积加起来。为了控制卷积操作后输出特征图的大小,有时会在输入数据的边缘填充一些值,通常是填充 0。这样可以使卷积核在滑动到边缘位置时也能有完整的局部区域进行计算,避免边缘信息的丢失。
作用:特征提取:卷积层中的卷积核可以自动学习到输入数据中的各种特征,如边缘、角点、纹理等低级特征。减少参数数量:与全连接神经网络相比,卷积神经网络通过卷积操作大大减少了模型的参数数量。稀疏连接:每个输出特征图上的一个点只与输入数据中的一个局部区域相关联,而不是与整个输入数据相连。
Conv2D 指在二维数据上的操作,是卷积神经网络(Convolutional Neural Network, CNN)中的核心组件之一。它通过在输入数据上滑动卷积核(也称为滤波器)进行卷积操作,以提取输入数据中的特征。
# 添加一个 Conv2D 层
model.add(Conv2D(filters=32, # 卷积核的数量
in_channels,#通道数
kernel_size=(3, 3), # 卷积核的大小,数字为正方形,也可以为长方形(元组)
strides=(1, 1), # 卷积核的滑动步长,可以是数字或元组
padding='same', # 填充方式,默认为0
activation='relu', # 激活函数
input_shape=(28, 28, 1))) # 输入数据的形状
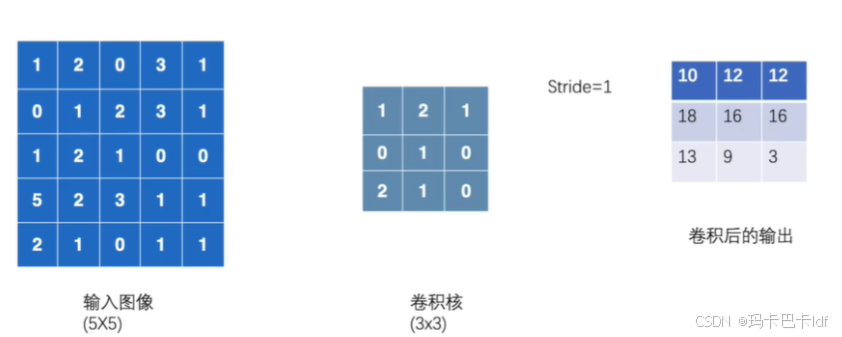
import torch
import torch.nn.functional as F
input =torch.tensor([[1,2,0,3,1], #输入数据5*5的
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel =torch.tensor([[1,2,1], #卷积核
[0,1,0],
[2,1,0]])
#由于两种张量大小形式不一样,需要使用reshape进行统一
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
#四个数字(一次处理的样本数量,通道数rgb等等,高度,宽度)
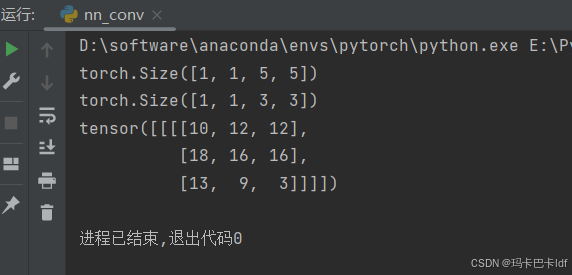
print(input.shape)
print(kernel.shape)
output =F.conv2d(input,kernel,stride=1)
print(output)运行结果:
CNN--CIFAR10数据集在tensorboard显示
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
from torch.utils.data import DataLoader
dataset = datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset=dataset, batch_size=64)
# 创建神经网络
class Shenjing(nn.Module): # 定义__init__和forward
def __init__(self):
super(Shenjing, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x): # x为输出
x = self.conv1(x)
return x
shenjing = Shenjing()
print(shenjing)
# 传入tensorboard
writer = SummaryWriter("logs")
# 返回dataloader中打包好的数据,用for循环
i = 0
for data in dataloader:
imgs, targets = data # 所有的img在imgs中,所有的label在labels中
output = shenjing(imgs) # 把img变成tensor形式
writer.add_images("nn_convd_input", imgs, i)
output=torch.reshape(output, (-1, 3, 30, 30)) #通道数为6变成3,不然会报错
writer.add_images("nn_convd_output", output, i)
i = i + 1
writer.close()
注意:通道数不一致会报错,提前查看input.shape和output.shape , 方便下面用reshape()更改一致,参数-1为默认,3为现通道数
显示结果:


池化层(Pooling Layer)
池化,也叫下采样或子采样,其本质是一种对数据进行压缩和特征提取的操作。它通过在数据的局部区域内进行聚合计算,从而得到一个代表该区域特征的新值,以此来减少数据量,降低计算复杂度,同时保留数据的主要特征。
类型:
最大池化(Max Pooling):在每个池化窗口内,取窗口内数据的最大值作为该窗口的池化结果。这种方式能够突出数据中的局部最大值特征,对于提取图像中的边缘、角点等显著特征非常有效。
平均池化(Average Pooling):计算每个池化窗口内数据的平均值作为池化结果。它可以平滑数据,对图像等数据进行模糊处理,保留数据的整体统计特征,在一些对全局特征较为敏感的任务中可能会有较好的效果。
随机池化(Stochastic Pooling):根据一定的概率分布对池化窗口内的数据进行采样,每个元素被选中的概率与其数值大小有关,数值越大,被选中的概率越高。在训练过程中,随机池化引入了一定的随机性,有助于提高模型的泛化能力。
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
dataset = datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset=dataset, batch_size=64)
# 创建神经网络
class Chihua(nn.Module): # 定义__init__和forward
def __init__(self):
super(Chihua, self).__init__()
self.maxpool1 = MaxPool2d( kernel_size=3, ceil_mode=False)
def forward(self, input): # x为输出
output= self.maxpool1(input)
return output
chihua = Chihua()
# 传入tensorboard
writer = SummaryWriter("logs")
# 返回dataloader中打包好的数据,用for循环
i = 0
for data in dataloader:
imgs, targets = data # 所有的img在imgs中,所有的label在targets中
writer.add_images("chihua_input", imgs, i)
output=chihua(imgs)
writer.add_images("chihua_output", output, i)
i = i + 1
writer.close()
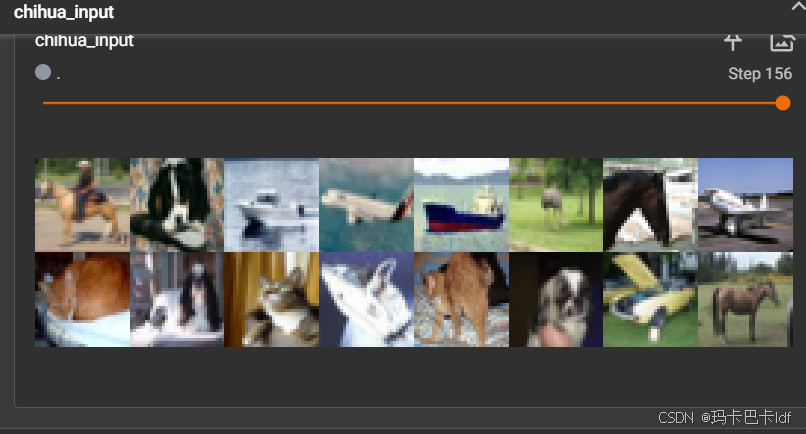

最大池化输出结果有一种马赛克的感觉,变更模糊了
非线性激活
定义:在神经网络中,神经元接收到输入信号后,会对这些输入进行加权求和,然后将这个总和输入到一个激活函数中,激活函数的输出就是该神经元的最终输出。如果激活函数是一个非线性函数(不是直线的那种,cos sin等),那么这个过程就被称为非线性激活。
引入非线性:线性函数的组合仍然是线性函数。而非线性激活函数可以让神经网络学习到输入和输出之间的复杂非线性关系,处理更复杂的任务,如图像识别、自然语言处理等。
特征提取和转换:非线性激活函数可以对输入特征进行非线性变换,将输入数据映射到一个新的特征空间,使得神经网络能够更好地捕捉数据中的模式和特征。
控制神经元的激活状态(开关):激活函数可以决定神经元是否被激活。例如,在某些激活函数中,当输入小于某个阈值时,神经元输出为 0,表示该神经元未被激活;当输入大于阈值时,神经元输出一个非零值,表示该神经元被激活。
常见的激活函数:
①Sigmoid 函数
![]()
函数的值域在 0-1 之间,可以将输入映射到一个概率值,常用于二分类问题的输出层。但它存在梯度消失问题,当输入值非常大或非常小时,函数的导数趋近于 0,这会导致在反向传播过程中梯度变得非常小,使得网络的训练速度变慢甚至无法收敛。
②Tanh 函数
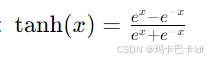
函数的值域在-1和1 之间,它是零中心的,相比于 Sigmoid 函数,它的收敛速度可能更快。但同样存在梯度消失问题。
③ReLU 函数
![]()
计算简单,能够有效缓解梯度消失问题,使得网络的训练速度更快。但是它存在 “死亡 ReLU” 问题,即当输入小于 0 时,导数为 0,神经元可能永远不会被激活。
import torchvision.datasets
from torch import nn
from torch.nn import ReLU,Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
dataset = datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset=dataset, batch_size=64)
# 创建神经网络
class Jihuo(nn.Module): # 定义__init__和forward
def __init__(self):
super(Jihuo, self).__init__()
self.relu1=ReLU()
self.sigmoid1=Sigmoid()
def forward(self, input): # x为输出
output= self.sigmoid1(input)
return output
jihuo = Jihuo()
# 传入tensorboard
writer = SummaryWriter("logs")
# 返回dataloader中打包好的数据,用for循环
i = 0
for data in dataloader:
imgs, targets = data # 所有的img在imgs中,所有的label在targets中
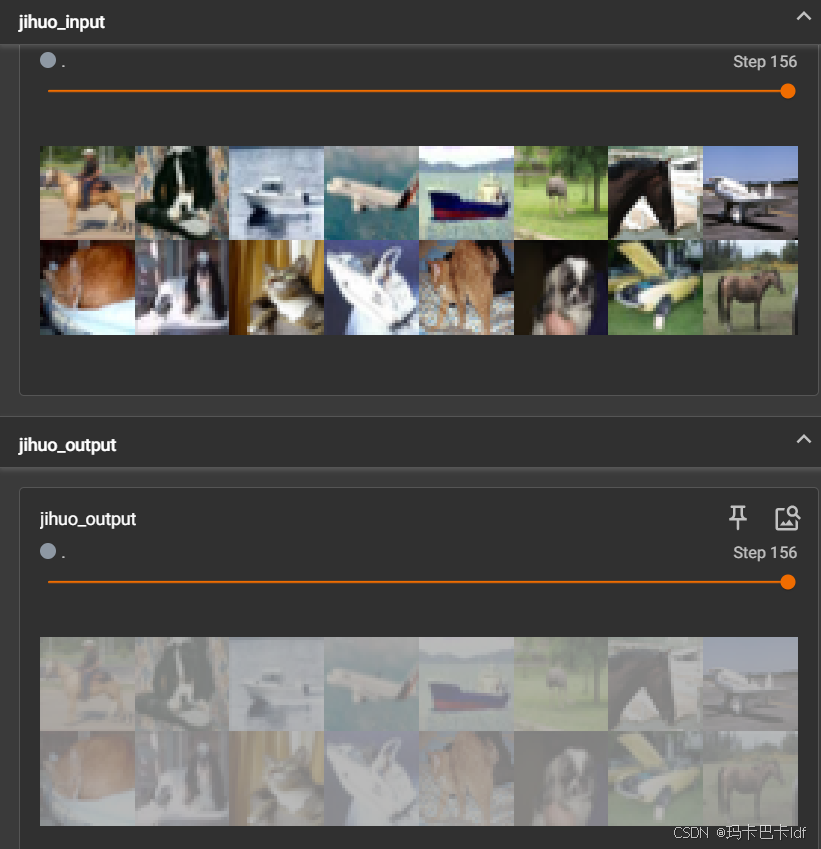
writer.add_images("jihuo_input", imgs, i)
output=jihuo(imgs)
writer.add_images("jihuo_output", output, i)
i = i + 1
writer.close()
tensorboard显示结果:
实战练习题--搭建简易神经网络

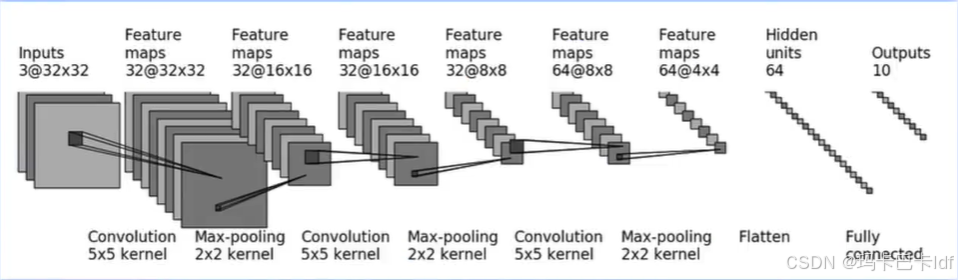
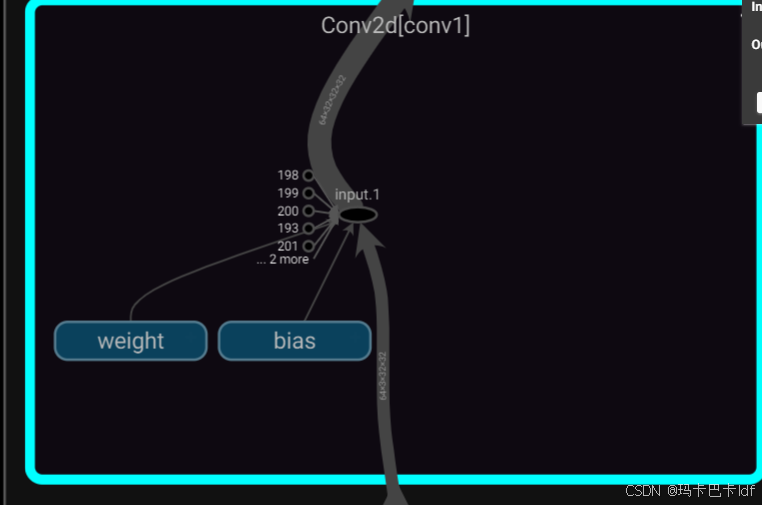
第一个卷积:
dilation【0】默认为1 32= 【32+2*padding-1*(5-1)-1】/stride +1
求解该式子得: stride=1 padding=2
Convertd(输入通道数 3 ,输出通道数 32 ,卷积核尺寸 5,padding=2)
第二个卷积:
dilation【0】默认为1 16= 【32+2*padding - 1*(5-1)-1】/stride +1
求解该式子得: stride=3 padding=2
Convertd(输入通道数 32 ,输出通道数 32 ,卷积核尺寸 5,padding=2)
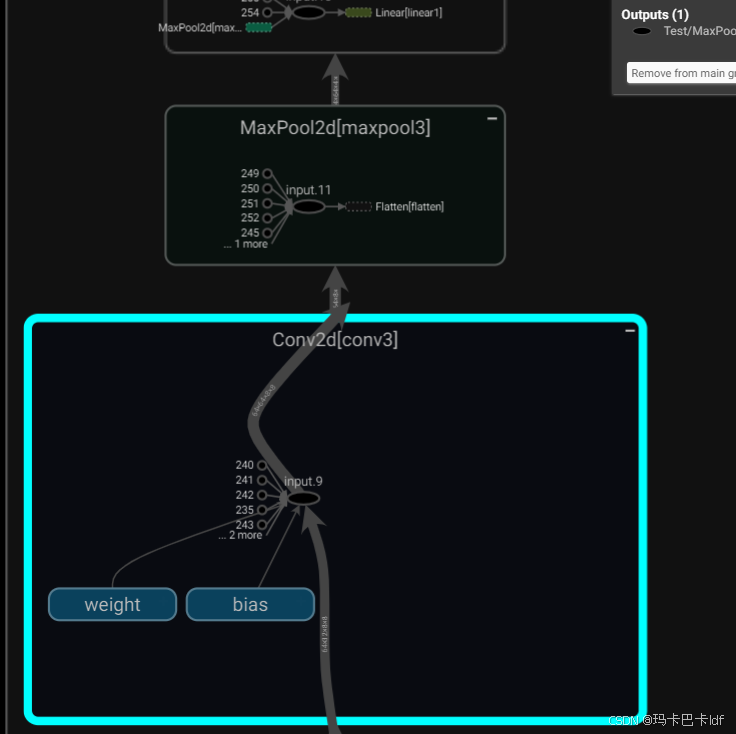
第三个卷积:
dilation【0】默认为1 64= 【32+2*padding - 1*(5-1)-1】/stride +1
求解该式子得: stride=3 padding=2
Convertd(输入通道数 32 ,输出通道数 64,卷积核尺寸 5,padding=2)
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
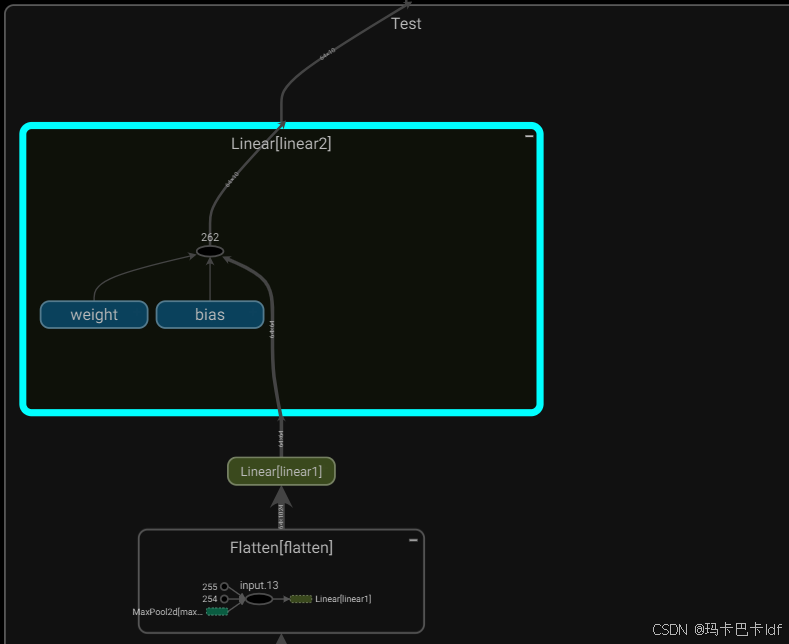
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64) # 线性层
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
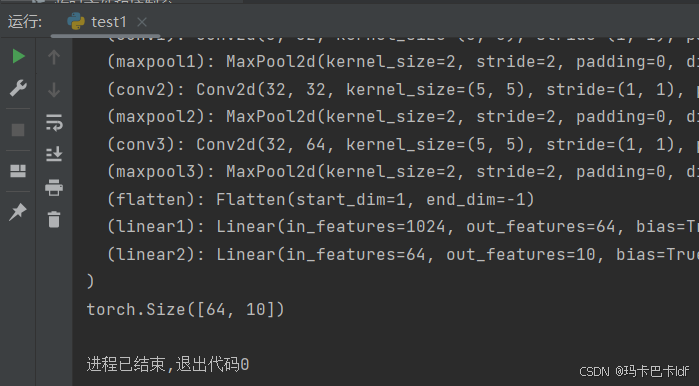
test = Test()
print(test)
input = torch.ones((64, 3, 32, 32))
output = test(input)
print(output.shape)
writer = SummaryWriter("logs_test")
writer.add_graph(test, input)
writer.close()
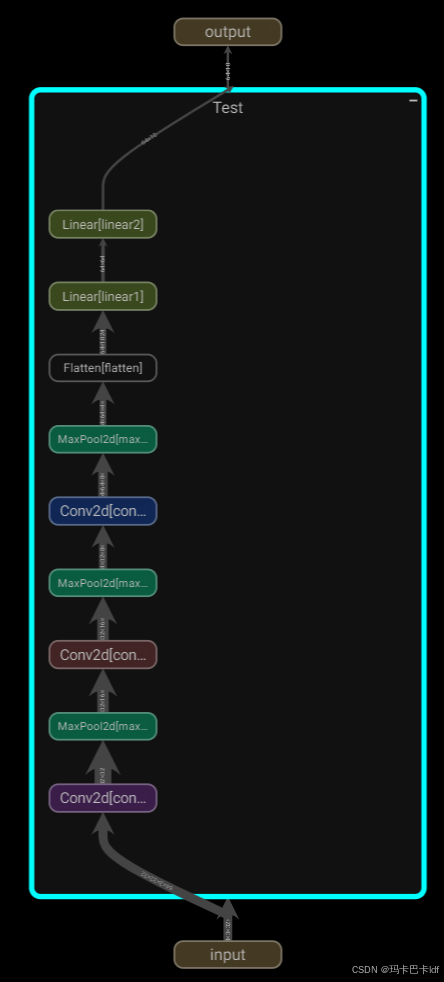
传入tensorboard显示: 整个过程会描述出来



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











