







Transforms相对于一个工具箱,需要使用时就初始化相关的方法,将物品放进这个方法中生成新版本的物品。不同的图像转换组件可以通过Compose来连接从而形成一个流水线,以实现更复杂的图像转换功能。在计算机科学尤其是深度学习和计算机视觉领域,Transforms通常指的是一系列用于对数据进行转换和预处理的操作集合,常见于 PyTorch 等深度学习框架中。
安装
pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
以下图展示Transforms的功能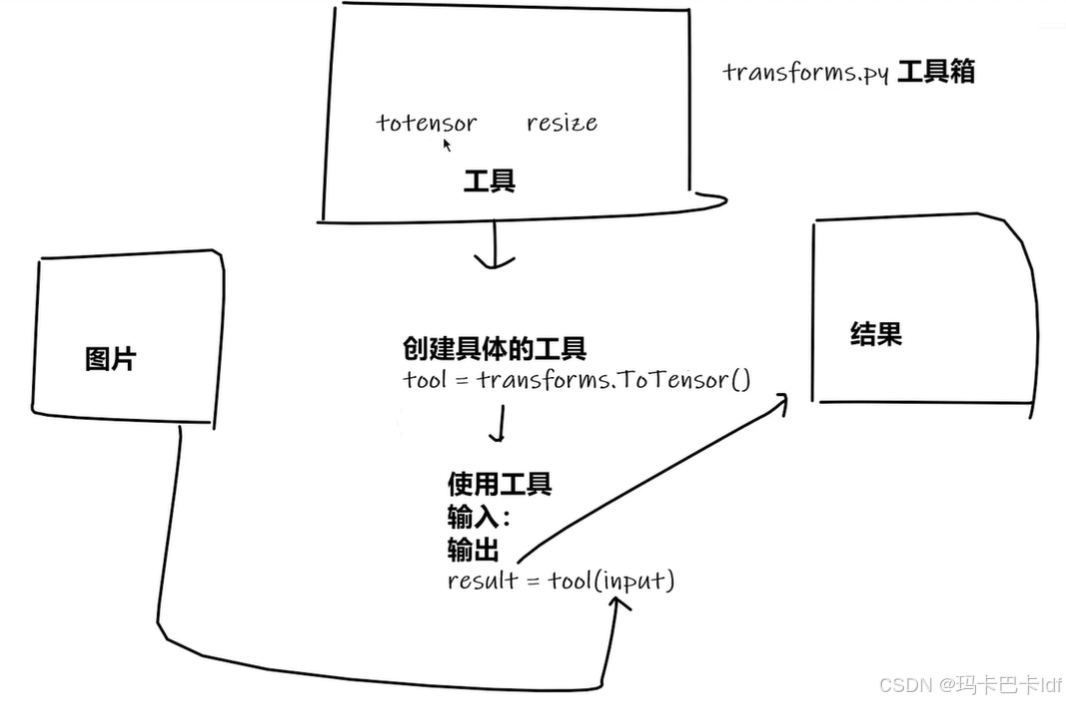
ToTensor()
将图像或其他数据类型转换为张量(Tensor)包装了很多参数。在深度学习中,数据通常以张量的形式进行存储和计算,因为张量可以方便地在 GPU 等硬件上进行并行计算,提高计算效率。ToTensor操作会将图像数据从普通的数组格式转换为适合模型输入的张量格式,并对数据进行归一化等操作。
① 以下例子为PIL Img格式的文件,要用Image.open()来打开
from PIL import Image
from torchvision import transforms
img_path="数据集/hymenoptera_data/train/ants/0013035.jpg" #相对路径
img =Image.open(img_path) #获取img
tensor_trans=transforms.ToTensor() #借用transforms中的类进行创建方法
tensor_img=tensor_trans(img) #将img转化为tensor_img形式
print(tensor_img)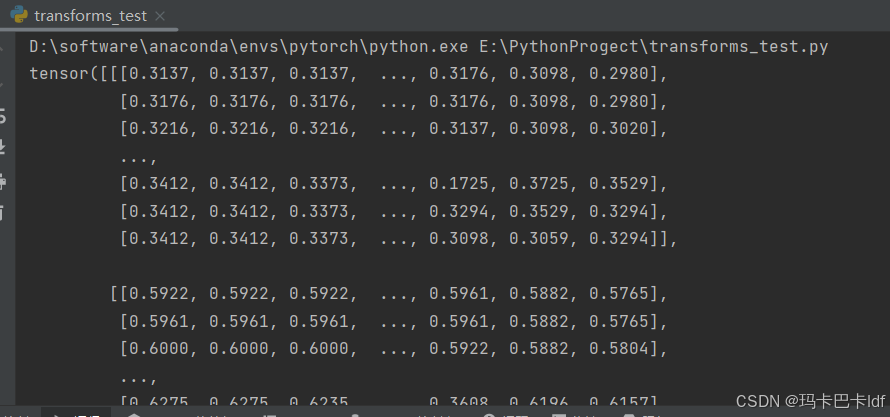
② numpy.ndarray格式文件,要用opencv来打开
玛卡温馨提示:ndarray 即 N-dimensional array(多维数组)的缩写,它是一个存储单一数据类型的多维同质数组。也就是说,数组中的所有元素都具有相同的数据类型,比如整数、浮点数等。这种数据结构使得 NumPy 能够高效地处理大规模的数值数据。.npy 文件:这是 NumPy 专用的二进制文件格式,用于保存单个 ndarray 对象。可以使用 np.save() 函数保存,使用 np.load() 函数加载。
安装
pip install opencv-python
安装完成之后进行使用,注意 该绝对路径不能出现中文,不然会报错!
如下图,读取的该cv_img为NumPy的多维数组 类型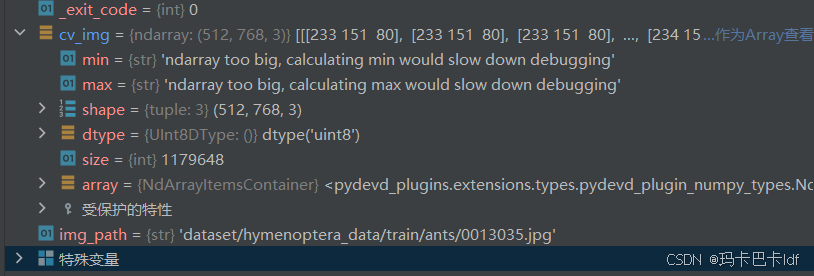
使用Tensorboard打开数据集图片,用到ToTensor
Tensorboard文章在Tensorboard安装、使用、常见问题
在训练深度学习模型时,我们通常需要监控一些标量指标,如训练损失、验证准确率等。SummaryWriter 可以方便地记录这些标量数据随训练步数或训练轮数的变化情况。
logs文件主要用于记录在深度学习模型训练和评估过程中的各种数据,包括但不限于损失值、准确率、学习率、权重和偏置的分布等。
SummaryWriter 是 PyTorch 中 torch.utils.tensorboard 模块提供的一个类,它的主要作用是将各种数据(如训练损失、模型参数、图像等)写入到 TensorBoard 日志文件中,以便后续使用 TensorBoard 工具进行可视化分析。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
'''SummaryWriter 是 PyTorch 中 torch.utils.tensorboard 模块提供的一个类,
它的主要作用是将各种数据(如训练损失、模型参数、图像等)写入到 TensorBoard 日志文件中,
以便后续使用 TensorBoard 工具进行可视化分析。'''
from torchvision import transforms
img_path="dataset/hymenoptera_data/train/ants/0013035.jpg" #相对路径
img =Image.open(img_path) #获取img
tensor_trans=transforms.ToTensor() #借用transforms中的类进行创建
tensor_img=tensor_trans(img) #将img转化为tensor_img形式
writer=SummaryWriter("logs") #将文件写入writer
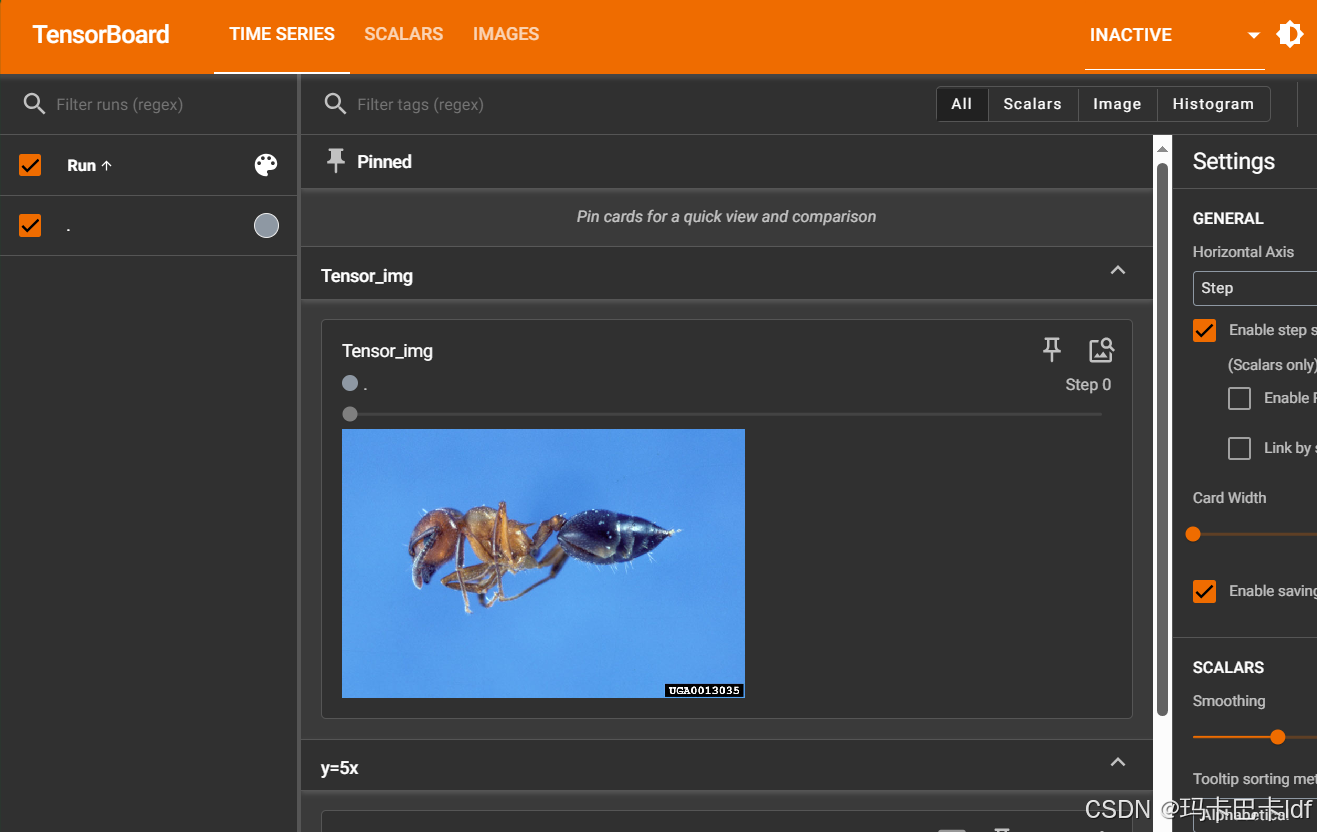
writer.add_image("Tensor_img",tensor_img) #使用该类的add_image方法把图传入tensorboard
writer.close()
在Pycharm终端输入 tensorboard --logdir "logs"

Normalize()
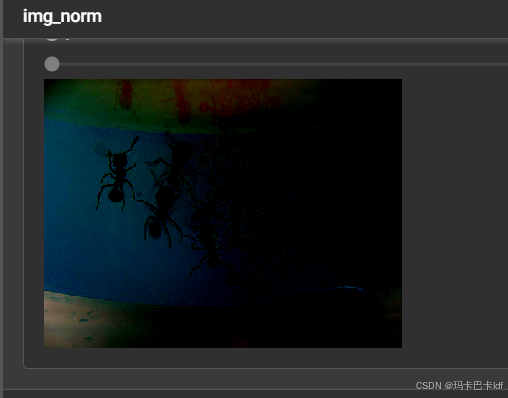
对数据进行归一化处理。归一化可以使数据具有零均值和单位方差,有助于加速模型的收敛,提高模型的训练效果和稳定性。在深度学习中,不同的特征可能具有不同的尺度和分布,通过归一化可以将它们统一到一个相似的尺度上,使得模型更容易学习到特征之间的关系。例如在处理图像数据时,通常会根据数据集的均值和标准差对图像的每个通道进行归一化。
均值和标准差:在统计学中,均值是一组数据的平均值,它反映了数据的集中趋势,减完均值就接近0,更加直观;标准差是衡量数据相对于均值的离散程度的指标,可以把文件像素值大幅缩小。都需要提前指定。
具体公式: 归一化后的像素值 = (输入像素值 - 均值)/标准差
输入必须是tensor形式的img等文件,RBG格式图片有三个值(R,B,G)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img =Image.open("dataset/hymenoptera_data/train/ants/6240329_72c01e663e.jpg")
writer=SummaryWriter("logs")
trans_totensor = transforms.ToTensor() #创建totensor方法
img_tensor=trans_totensor(img) #把img变成tensor形式
writer.add_image("tensor_img",img_tensor) #用writer把img传入tensorboard
#normalize
print(img_tensor[0][0][0]) #初始像素值
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #创建normalize方法,参数为(均值,标准差)
img_norm=trans_norm(img_tensor) #把tensor形式的img 进行标准化
print(img_norm[0][0][0]) #归一化后的像素值
writer.close()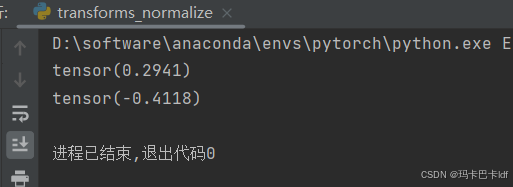
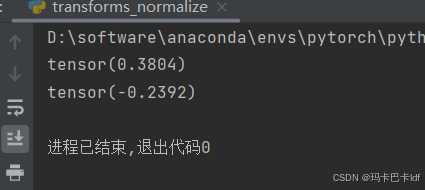
如图数据,我们0.2941为初始像素,代入公式得到 -0.4118,换其他图片也是归一化后的像素值 = (输入像素值 - 均值)/标准差的结果。
进入TensorBoard中观察归一化前后的图片:
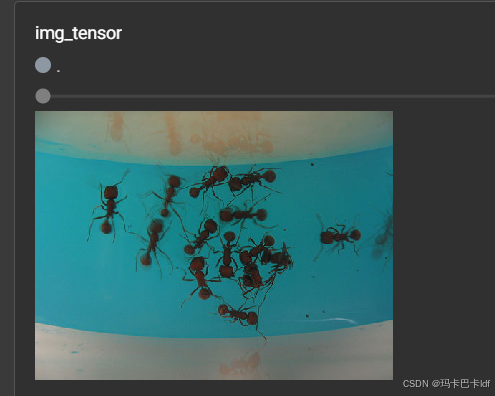
Resize()
Resize 方法的主要功能是将输入的图像调整为指定的大小。可以将图像按比例缩放,也可以直接将图像调整为固定的尺寸。统一调整为模型所需的输入尺寸,如 224×224 或 256×256 等,以便于模型进行特征提取和分类。
当Resize方法只传入一个参数时,它会将图像的较短边调整为该参数指定的大小,同时保持图像的宽高比不变。两个参数即为参数值大小。
img不需要变成tensor形式,如果在TensorBoard上面显示,才需要转换成tensor形式
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img =Image.open("dataset/hymenoptera_data/train/ants/5650366_e22b7e1065.jpg")
writer=SummaryWriter("logs")
#Resize
print(img.size) #输入初始尺寸
trans_resize=transforms.Resize((512,512)) #初始化一个resize方法
img_resize=trans_resize(img)
# 传入tensorboard
tensor=transforms.ToTensor() #初始化tensor方法
img_tensor =tensor(img_resize) #调用tensor方法,传入裁剪过的
writer.add_image("img_resize",img_tensor)
print(img_resize) #resize后还是img文件,tensor后是tensor版的img
writer.close()如下图图片(500,375)变成(512,512)

Compose()
Compose类是一个非常实用的工具,主要用于将多个图像变换操作组合在一起,按顺序依次对图像进行处理。
①初始化时参数为transforms类型的实例 ,注意用[ ]把参数包起来
②参数的顺序不能变,resize需要PIL img类型,而totensor会变成tensor类型
# 定义一系列变换操作
transform = transforms.Compose([
# 将图像调整为 256x256 大小
transforms.Resize((256, 256)),
# 随机裁剪图像为 224x224 大小
transforms.RandomCrop(224),
# 随机水平翻转图像
transforms.RandomHorizontalFlip(),
# 将图像转换为张量
transforms.ToTensor(),
# 对图像进行归一化处理
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])经过compose实例化的img也是tensor版的
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img =Image.open("dataset/hymenoptera_data/train/ants/5650366_e22b7e1065.jpg")
writer=SummaryWriter("logs")
#compose
trans_totensor = transforms.ToTensor() #初始化tensor方法
trans_resize=transforms.Resize((512,512)) #初始化resize方法
trans_compose=transforms.Compose([trans_resize,trans_totensor])#初始化compose方法,把要求写上
img_compose=trans_compose(img) #实例化img变成compose/tensor版的img
writer.add_image("compose",img_compose) #把该img传入tensorboard
writer.close()注意:Compose内俩参数位置交换会报错,因为先有resize需要PIL img类型,而totensor会变成tensor类型,先有img 才有tensor

RandomCrop()
随机从图像中裁剪出指定大小的区域。这是一种数据增强方法,可以增加数据的多样性,防止模型过拟合。通模型可以学习到图像不同部分的特征,提高模型的泛化能力。比如在训练一个目标检测模型时,使用RandomCrop可以让模型更好地适应目标在图像中不同位置和大小的情况。
主要格式参数为
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')size:必需参数,表示裁剪后图像的尺寸。一个整数 裁剪后的图像为正方形;两个整数的元组 (height, width),分别表示裁剪后图像的高度和宽度。
后面参数为填充格式
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img =Image.open("dataset/hymenoptera_data/train/ants/5650366_e22b7e1065.jpg")
writer=SummaryWriter("logs")
trans_totensor = transforms.ToTensor() #初始化tensor方法
#random
trans_random=transforms.RandomCrop(200)
trans_compose=transforms.Compose([trans_random,trans_totensor])#初始化compose方法
for i in range(10): #分成十个块
img_random=trans_compose(img)
writer.add_image("RandomCrop",img_random,i)
writer.close()




















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











