






 本文介绍了如何在Flink中配置Kafka数据源以适应Kafka Topic的动态分区变化和新增Topic。针对Kafka分区增加,可以通过设置`flink.partitions-discovery.interval-millis`来定时检查新分区。当业务增长需要创建新Topic时,可使用正则表达式匹配来确保Flink能正确消费。这两个设置对于保持数据流处理的实时性和灵活性至关重要。
本文介绍了如何在Flink中配置Kafka数据源以适应Kafka Topic的动态分区变化和新增Topic。针对Kafka分区增加,可以通过设置`flink.partitions-discovery.interval-millis`来定时检查新分区。当业务增长需要创建新Topic时,可使用正则表达式匹配来确保Flink能正确消费。这两个设置对于保持数据流处理的实时性和灵活性至关重要。
flink之kafka数据源之topic的分区和topic发现设置
情景一:kafka因为后台数据增多,重新新增加分区,这时候需要在kafka中设置flink.partitions-discovery.interval-millis(设置时间为多少毫秒后天自动启动一个线程校验是否有新增分区)
情景二: 由于业务增多,需要新增一个topic,这时候需要设置kafka 匹配topic的名称的时候采用正则表达式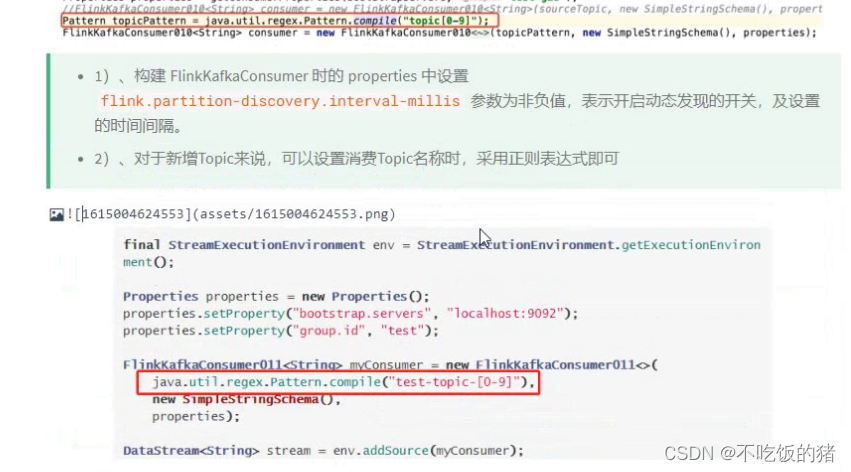
flink之kafka数据源之topic的分区和topic发现设置
情景一:kafka因为后台数据增多,重新新增加分区,这时候需要在kafka中设置flink.partitions-discovery.interval-millis(设置时间为多少毫秒后天自动启动一个线程校验是否有新增分区)
情景二: 由于业务增多,需要新增一个topic,这时候需要设置kafka 匹配topic的名称的时候采用正则表达式
 1247
3168
1247
3168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























