




Transformation - map
任务描述
本关任务:使用 Spark 的map算子按照相关需求完成转换操作。
相关知识
为了完成本关任务,你需要掌握:如何使用map算子。
map
将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素。
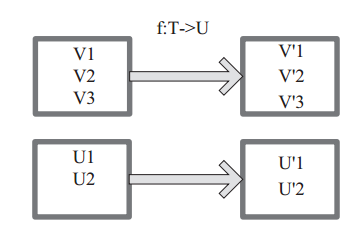
图中每个方框表示一个RDD分区,左侧的分区经过自定义函数f:T->U映射为右侧的新RDD分区。但是,实际只有等到Action算子触发后,这个f函数才会和其他函数在一个Stage中对数据进行运算。
map 案例
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);System.out.println("init:" + list);JavaRDD<Integer> rdd = sc.parallelize(list);JavaRDD<Integer> map = rdd.map(x -> x * 2);System.out.println("result :" + map.collect());
输出:
init :[1, 2, 3, 4, 5, 6] result :[2, 4, 6, 8, 10, 12]
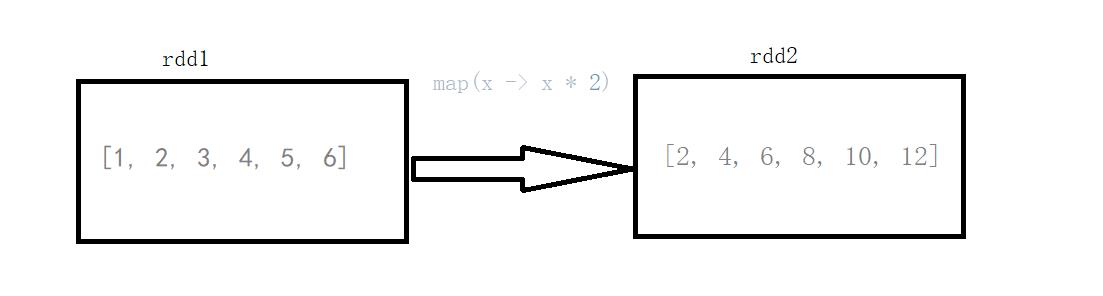
说明:rdd1的元素(1 , 2 , 3 , 4 , 5 , 6)经过map算子(x -> x*2)转换成了rdd2(2 , 4 , 6 , 8 , 10)
编程要求
根据提示,在右侧编辑器begin-end处补充代码,完成以下需求:
需求1:使用map算子,将rdd的数据(1, 2, 3, 4, 5)按照下面的规则进行转换操作,规则如下:
-
偶数转换成该数的平方;
-
奇数转换成该数的立方。
需求2:使用map算子,将rdd的数据("dog", "salmon", "salmon", "rat", "elephant")按照下面的规则进行转换操作,规则如下:
- 将字符串与该字符串的长度组合成一个元组,例如:
dog --> (dog,3)salmon --> (salmon,6)
package net.educoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
public class Step1 {
private static SparkConf conf;
private static JavaSparkContext sc;
static {
conf = new SparkConf().setAppName("Step1").setMaster("local");
sc = new JavaSparkContext(conf);
}
/**
* 返回JavaRDD
*
* @return JavaRDD
*/
public static JavaRDD<Integer> MapRdd() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(list);
/**
*
* 需求:使用map算子,将rdd的数据进行转换操作
* 规则如下:
* 偶数转换成该数的平方
* 奇数转换成该数的立方
*
*/
/*********begin*********/
JavaRDD<Integer> map = rdd.map(num -> {
if (num % 2 == 0) {
return num * num;
} else {
return num * num * num;
}
});
return map;
/*********end*********/
}
/**
* 返回JavaRDD
*
* @return JavaRDD
*/
public static JavaRDD<Tuple2> MapRdd2() {
List<String> list = Arrays.asList("dog", "salmon", "salmon", "rat", "elephant");
JavaRDD<String> rdd = sc.parallelize(list);
/**
*
* 需求:使用map算子,将rdd的数据进行转换操作
* 规则如下:
* 将字符串与该字符串的长度组合成一个元组,例如:dog --> (dog,3),salmon --> (salmon,6)
*
*/
/*********begin*********/
JavaRDD<Tuple2> map = rdd.map(str -> {
int i = str.length();
return new Tuple2(str, i);
});
return map;
/*********end*********/
}
}
Transformation - mapPartitions
任务描述
本关任务:使用Spark的mapPartitions算子按照相关需求完成转换操作。
相关知识
为了完成本关任务,你需要掌握:如何使用mapPartitions算子。
mapPartitions
mapPartitions函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭 代器对整个分区的元素进行操作。
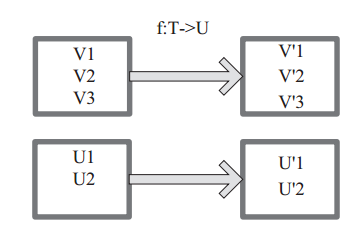
图中每个方框表示一个RDD分区,左侧的分区经过自定义函数f:T->U映射为右侧的新RDD分区。
mapPartitions 与 map
map:遍历算子,可以遍历RDD中每一个元素,遍历的单位是每条记录。
mapPartitions:遍历算子,可以改变RDD格式,会提高RDD并行度,遍历单位是Partition,也就是在遍历之前它会将一个Partition的数据加载到内存中。
那么问题来了,用上面的两个算子遍历一个RDD谁的效率高? 当然是mapPartitions算子效率高。
mapPartitions 案例
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);System.out.println("init::" + list);JavaRDD<Integer> rdd = sc.parallelize(list);JavaRDD<Integer> mapPartitions = rdd.mapPartitions(it -> {ArrayList<Integer> arrayList = new ArrayList<>();while (it.hasNext()) {Integer next = it.next();arrayList.add(next * 2);}return arrayList.iterator();});System.out.println("result :" + mapPartitions.collect());
输出:
init::[1, 2, 3, 4, 5, 6]result :[2, 4, 6, 8, 10, 12]
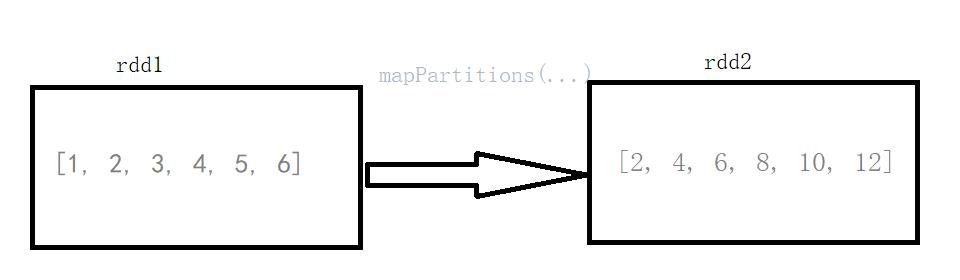
mapPartitions():传入的参数是rdd的iterator(元素迭代器),返回也是一个iterator(迭代器)。
编程要求
根据提示,在右侧编辑器begin-end处补充代码,完成以下需求:
需求1:使用mapPartitions算子,将rdd的数据(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)按照以下规则进行转换操作,规则如下:
-
偶数转换成该数的平方;
-
奇数转换成该数的立方。
需求2:使用mapPartitions算子,将rdd的数据 ("dog", "salmon", "salmon", "rat", "elephant")按照下面的规则进行转换操作,规则如下:
- 将字符串与该字符串的长度组合成一个元组,例如:
dog --> (dog,3)salmon --> (salmon,6)
package net.educoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class Step7 {
private static SparkConf conf;
private static JavaSparkContext sc;
static {
conf = new SparkConf().setAppName("Step7").setMaster("local");
sc = new JavaSparkContext(conf);
s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









