









1 自注意力机制
- 自注意力机制:Q = K = V
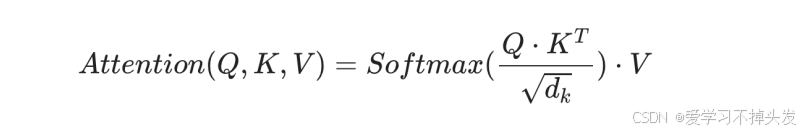


# 自注意力机制函数attention 实现思路分析
# 函数 attention(query, key, value, mask=None, dropout=None)
# 1 求查询张量特征尺寸大小 d_k
# 2 求查询张量q的权重分布scores q@k^T /math.sqrt(d_k)
# 形状[2,4,512] @ [2,512,4] --->[2,4,4]
# 3 是否对权重分布scores进行mask scores.masked_fill(mask == 0, -1e9)
# 4 求查询张量q的权重分布 p_attn F.softmax()
# 5 是否对p_attn进行dropout if dropout is not None:
# 6 求查询张量q的注意力结果表示 [2,4,4]@[2,4,512] --->[2,4,512]
# 7 返回q的注意力结果表示 q的权重分布
def attention(query, key, value, mask=None, dropout=None):
# 1 求查询张量特征尺寸大小 d_k
d_k = query.size()[-1] # 512
# 2 求查询张量q的权重分布 scores q@k^T /math.sqrt(d_k)
# 形状[2,4,512] @ [2,512,4] --->[2,4,4]
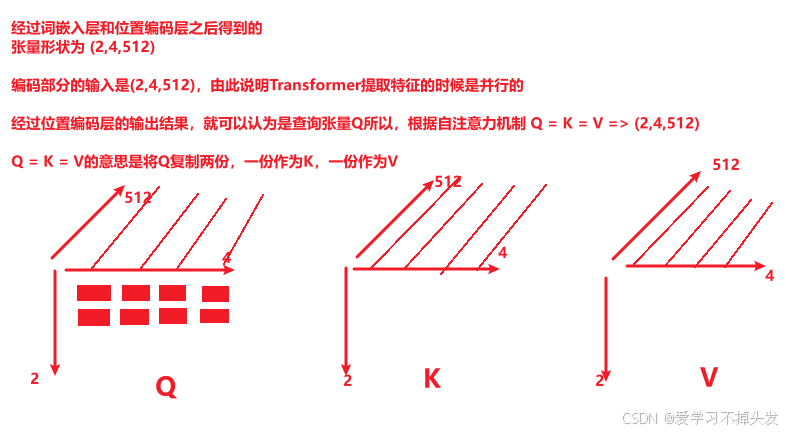
# 2,4,512表示传入两句话,每句话四个词,求每句话中每个词与当前句子中词的关系,得到形状为 (batch_size,seq_len,seq_len)
# scores => (2,4,4)
scores = torch.matmul(query, key.transpose(-1, -2)) / math.sqrt(d_k )
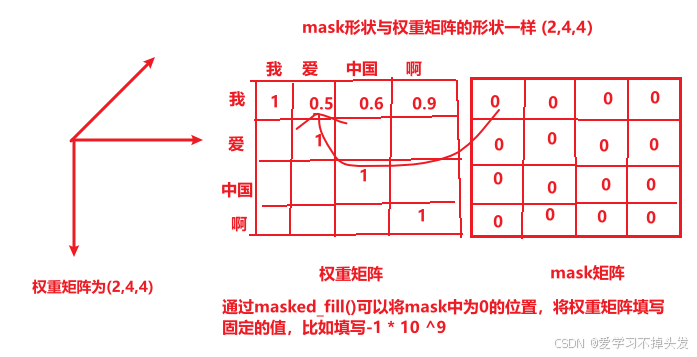
# 3 是否对权重分布scores进行mask scores.masked_fill(mask == 0, -1e9)
if mask is not None:
# scores - (2,4,4)的矩阵,表示两个句子的各自词之间的密切程度
# mask == 0,得到一个形状与mask一样的bool矩阵
# masked_fill(mask == 0,-1e9) 将bool矩阵中为True的位置填上对应的数值
scores = scores.masked_fill(mask==0, -1e9)
# 4 求查询张量q的权重分布 p_attn F.softmax()
# 查询张量q的权重分布
p_attn = F.softmax(scores, dim=-1)
# 5 是否对p_attn进行dropout if dropout is not None:
if dropout is not None:
p_attn = dropout(p_attn)
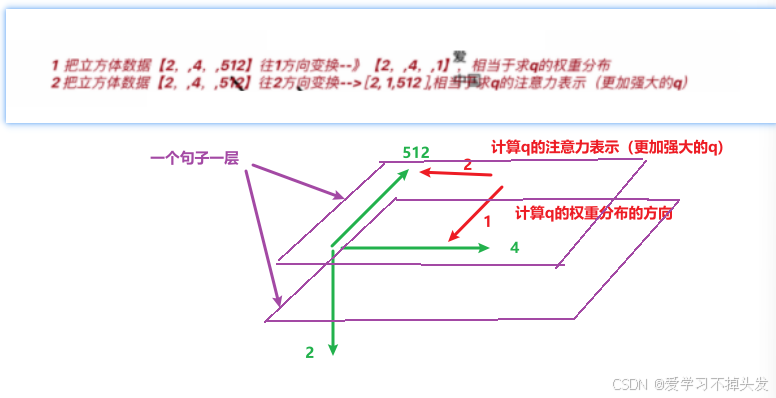
# 6 求查询张量q的注意力结果表示 [2,4,4]@[2,4,512] --->[2,4,512]
# 7 返回q的注意力结果表示 q的权重分布
# return torch.bmm(p_attn, value), p_attn # 方式1 # bmm运行支持3个维度
# return p_attn @ value, p_attn # 方式2
return torch.matmul(p_attn, value), p_attn # 方式3
def dm01_test_attention():
d_model = 512 # 词嵌入维度是512维
vocab = 1000 # 词表大小是1000
# 输入x 是一个使用Variable封装的长整型张量, 形状是2 x 4
x = Variable(torch.LongTensor([[100, 2, 421, 508],
[491, 998, 1, 221]]))
my_embeddings = Embeddings(d_model, vocab)
x = my_embeddings(x) # x.shape = (2,4,512)
dropout = 0.1 # 置0比率为0.1
max_len = 60 # 句子最大长度
my_pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = my_pe(x)
# q的形状为(batch_size,seq_len,dim)
# q = k = v => (2,4,512)
query = key = value = pe_result # torch.Size([2, 4, 512])
print('没有使用mask矩阵对 注意力分布进行处理')
attn1, p_attn1 = attention(query, key, value, mask=None, dropout=None)
print('注意力结果表示attn1--->', attn1.shape, attn1)
print('注意力权重分布p_attn1--->', p_attn1.shape, '\n', p_attn1)
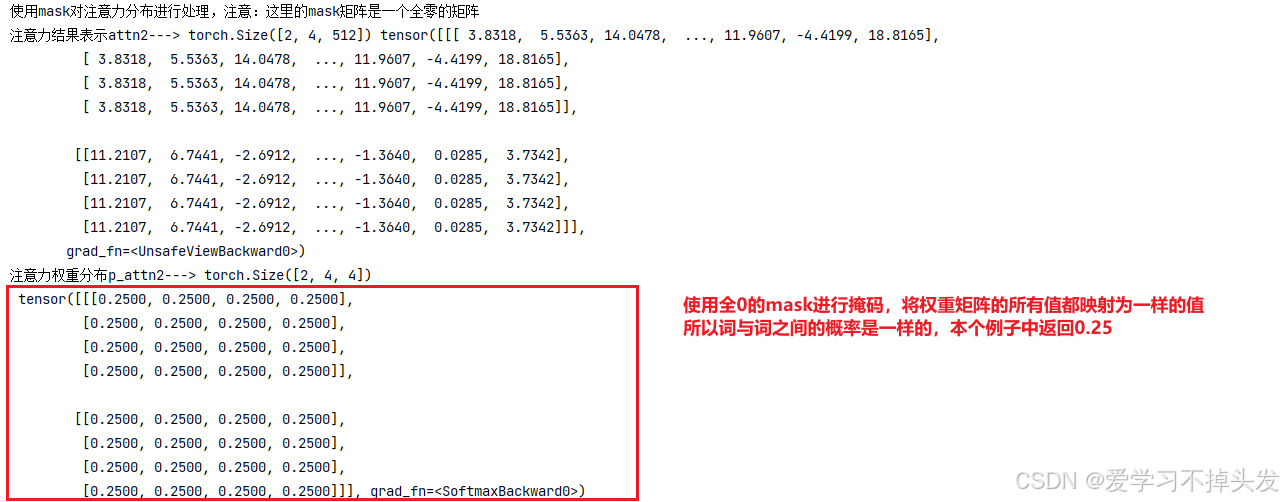
print('使用mask对注意力分布进行处理,注意:这里的mask矩阵是一个全零的矩阵')
# mask 2*4*4
mask_zero = torch.zeros(2, 4, 4)
attn2, p_attn2 = attention(query, key, value, mask=mask_zero, dropout=None)
print('注意力结果表示attn2--->', attn2.shape, attn2)
print('注意力权重分布p_attn2--->', p_attn2.shape, '\n', p_attn2)

2 多头注意力机制
2.1 多头注意力机制的概念
-
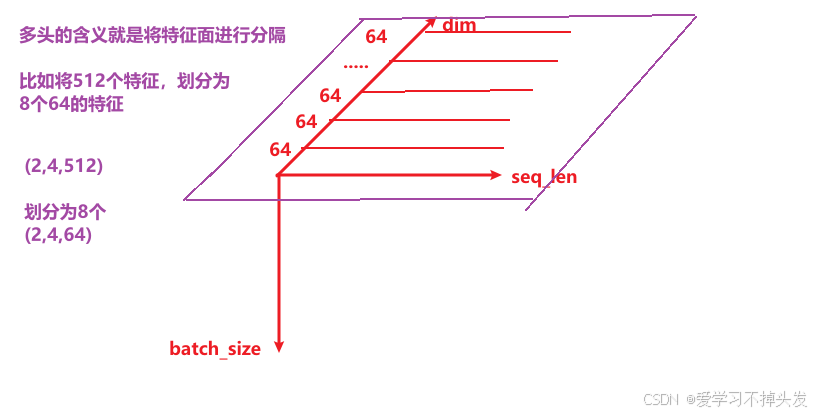
多头注意力机制 (Multi-Head Attention),是Transformer的一个关键组件,它同时使用多个注意力机制来获取多个不同的关注点
-
大白话释义:对文本特征进行切分,分成多头(相当于分成多个人)去观察。更加有利于提取事物特征。
多头注意力机制的作用
- 让多个注意力机制去提取文本特征, 比用1个注意力机制好, 充分提取特征
- 每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果
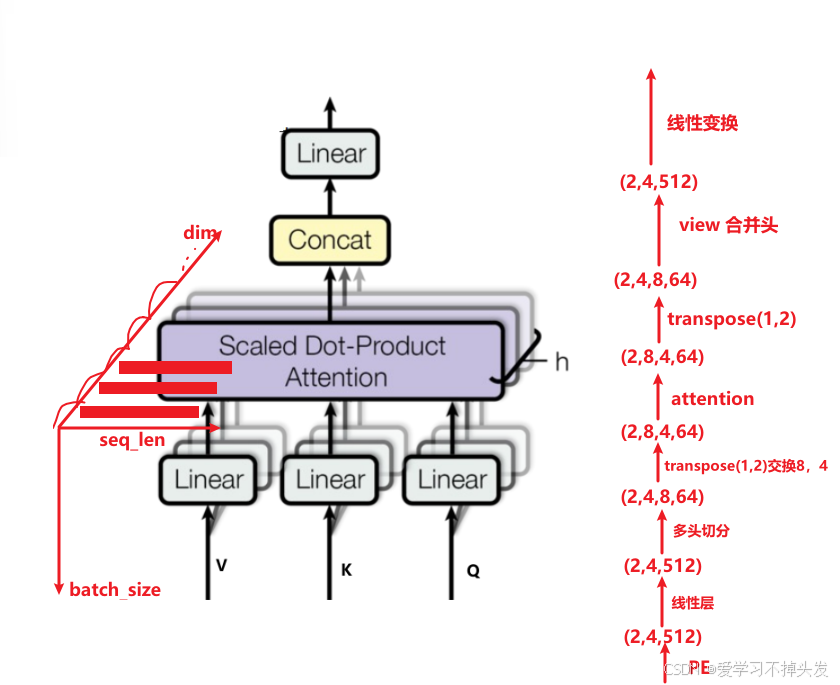
多头注意力机制的结构图
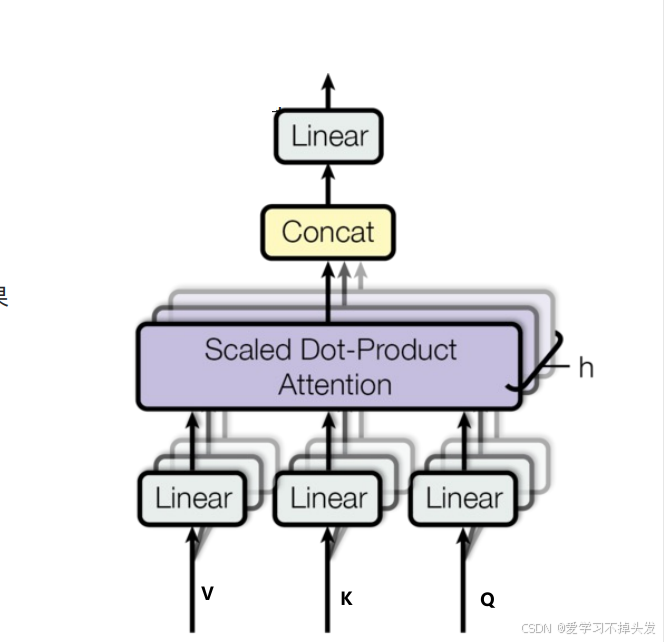
- 线性变化:QKV分别输入到线性层
- view切分:特征进行多头切分,比如:256个特征切分为8个头,每个头64个特征
- attention操作:通过attention函数进行多头特征提取
- Concat操作:合并多头特征提取结果
- 线性层变换:最后得到我们想要的数据形状
-
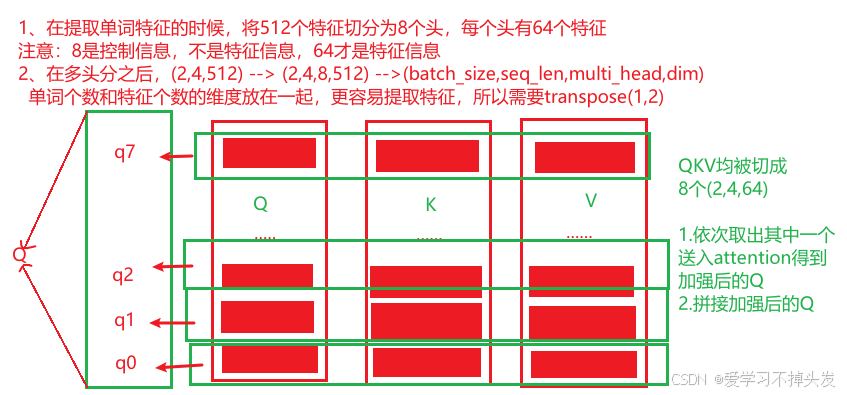
多头注意力机制中,如何将数据送入到attention中?
-
数据在多头注意力机制中的形状变化
2.2 多头注意力机制的代码实现
- 定义克隆函数
# 定义克隆函数
def clones(module,N)
return nn.ModuleList([deepcopy(module) for_ in range(N)])
- 构建多头注意力机制层
# 多头注意力机制类 MultiHeadedAttention 实现思路分析
# 1 init函数 (self, head, embedding_dim, dropout=0.1)
# 每个头特征尺寸大小self.d_k 多少个头self.head 线性层列表self.linears
# self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
# 注意力权重分布self.attn=None dropout层self.dropout=nn.Dropout(p=dropout)
# 2 forward(self, query, key, value, mask=None)
# 2-1 掩码增加一个维度[8,4,4] -->[1,8,4,4] 求多少批次batch_size
# 2-2 数据经过线性层 切成8个头,view(batch_size, -1, self.head, self.d_k), transpose(1,2)数据形状变化
# 数据形状变化[2,4,512] ---> [2,4,8,64] ---> [2,8,4,64]
# 2-3 24个头 一起送入到attention函数中求 x, self.attn
# attention([2,8,4,64],[2,8,4,64],[2,8,4,64],[1,8,4,4]) ==> x[2,8,4,64], self.attn[2,8,4,4]]
# 2-4 数据形状再变化回来 x.transpose(1,2).contiguous().view(batch_size, -1, self.head*self.d_k)
# 数据形状变化 [2,8,4,64] ---> [2,4,8,64] ---> [2,4,512]
# 2-5 返回最后线性层结果 return self.linears[-1](x)
# 深度copy模型 输入模型对象和copy的个数 存储到模型列表中
import copy
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
# 1 init函数 (self, head, embedding_dim, dropout=0.1)
# 每个头特征尺寸大小self.d_k
self.d_k = embedding_dim // head
# 多少个头
self.head = head
# 线性层列表self.linears
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
# 注意力权重分布self.attn=None
self.attn = None
# dropout层self.dropout=nn.Dropout(p=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
# 2-1 掩码增加一个维度[8,4,4] -->[1,8,4,4]
if mask is not None:
mask = mask.unsqueeze(0)
# 求多少批次batch_size # 2,4,512
batch_size = query.size()[0]
# 2-2 数据经过线性层 切成8个头,view(batch_size, -1, self.head, self.d_k), transpose(1,2)数据形状变化
# 数据形状变化[2,4,512] ---> [2,4,8,64] ---> [2,8,4,64]
query, key, value = [ model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))]
# 2-3 24个头 一起送入到attention函数中求 x, self.attn
# attention([2,8,4,64],[2,8,4,64],[2,8,4,64],[1,8,4,4]) ==> x[2,8,4,64], self.attn[2,8,4,4]]
x, self.attn = attention(query, key, value, mask)
# 2-4 数据形状再变化回来 x.transpose(1,2).contiguous().view(batch_size, -1, self.head*self.d_k)
# 数据形状变化 [2,8,4,64] ---> [2,4,8,64] ---> [2,4,512]
x = x.transpose(1,2).contiguous().view(batch_size, -1, self.head*self.d_k)
# 2-5 返回最后线性层结果 return self.linears[-1](x)
x = self.linears[-1](x)
return x
def dm02_test_MultiHeadedAttention():
d_model = 512 # 词嵌入维度是512维
vocab = 1000 # 词表大小是1000
# 这个数据是经过词嵌入+位置编码器层以后的数据 (加了位置信息以后的数据)
pe_result = torch.randn(2, 4, 512)
head = 8 # 头数head
dropout = 0.1
query = key = value = pe_result # torch.Size([2, 4, 512])
# 输入的掩码张量mask
mask = Variable(torch.zeros(8, 4, 4))
my_mha = MultiHeadedAttention(head, d_model, dropout)
x = my_mha(query, key, value, mask)
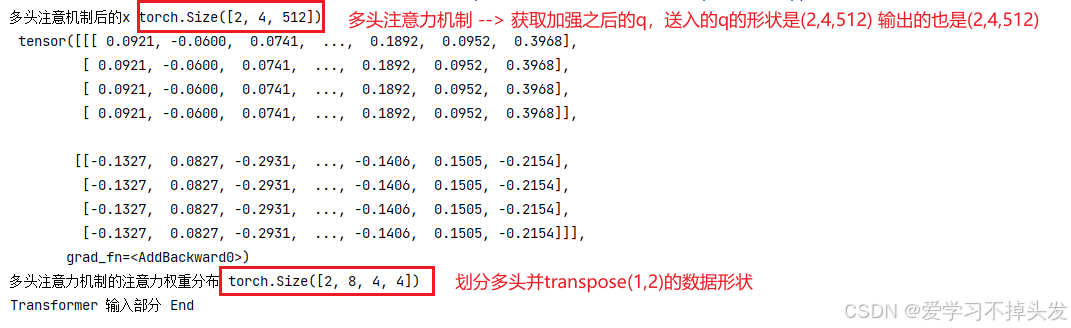
print('多头注意机制后的x', x.shape, '\n', x)
print('多头注意力机制的注意力权重分布', my_mha.attn.shape)
2.3 transpose和view函数区别
- view函数和transpose函数都可以改变张量的形状
- transpose函数会让内存变得不连续
- 先使用x.transpose函数后,一定要使用contiguous()函数,才能再使用view。
- 先使用view 则可以使用transpose
# 测试view和 transpose 函数
# transpose函数会让内存变得不连续
# 先使用x.transpose函数后,一定要使用contiguous()函数,才能再使用view。
# 先使用view 则可以使用transpose
def dm03_test_viewandtranspose():
# view演示
# x = torch.randn(4, 4)
# x = torch.Tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])
# print(x)
#
# y = x.view(16)
# print(y)
a = torch.randn(1, 2, 3, 4)
print('原始数据a===>\n', a)
print(a.size())
# 交换两个维度
b = a.transpose(1, 2)
print('对a transpose后的数据b===> \n', b)
print(b.size())
# view是重新排成一排然后将其组合成要的形状
c = a.view(1, 3, 2, 4)
print('对a view后的数据c===>\n', c)
print(c.size())
# 1 transpose()让Tensor内存空间变得不连续了,需要使用 contiguous()以后再使用view()
# 2 .reshape() =====> 先contiguous() 在view()


















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









