







1 分词
1.1 分词的概念和作用
分词定义:将连续的字序列按照一定的规范重新组合成词序列的过程
分词作用:词作为语言语义理解的最小单元, 是人类理解文本语言的基础,是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节
中文为什么要分词?中文没有明显的分解符,英文天然空格是分解符
1.2 jieba分词
jieba 是一个python实现的分词库,对中文有着很强大的分词能力
jieba分词愿景: “结巴”中文分词,做最好的 Python 中文分词组件
jieba分词功能:
- 支持多种分词模式(三种模式)
- 精确模式
- 全模式
- 搜索引擎模式
- 支持中文繁体分词
- 支持用户自定义词典
- 自定义字典的格式
1.3 jieba-分词模式
jieba分词安装
pip install jieba
- 精确模式
- 全词模式
- 搜索引擎模式
- 三种分词模式的本质: 对分词的颗粒度进行控制
import jieba
# def cut(self, sentence, cut_all = False, HMM = True,use_paddle = False):
def dm01_jiebase_base():
content = "传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能"
# 精确模式: 按照句子的语义对文本,尽量精准的进行分词
# def cut(self, sentence, cut_all=False, HMM=True, use_paddle=False):
myobj1 = jieba.cut(sentence=content, cut_all= False)
print('myobj1-->', myobj1) # 返回一个可迭代对象
# 使用lcut()可以将可迭代对象转换为列表
mydata1 = jieba.lcut(sentence=content, cut_all=False)
print('mydata1-->', mydata1)
# 全词模式: 把所有的词都分出来
myobj2 = jieba.cut(sentence=content, cut_all=True)
print('myobj2-->', myobj2)
mydata2 = jieba.lcut(sentence=content, cut_all=True)
print('mydata2-->', mydata2)
# 搜索引擎模式: 是在精确模式的基础之上, 对长词再做切分!!
# def lcut_for_search(self, *args, **kwargs):
myobj3 = jieba.cut_for_search(sentence=content)
print('myobj3-->', myobj3)
mydata3 = jieba.lcut_for_search(sentence=content)
print('mydata3-->', mydata3)

1.4 jieba-用户自定义字典
- 通过用户自定义字典,法律和医疗行业有很多专有名词,给到jieba进行识别
- 用户字典的作用: 的确可以增加jieba分词的准确性
-
1 用户字典格式
名字 + 词频 + 词性 ;注意 词频 + 词性是可以省略
氨基硅油 3 nz
柔顺剂 5 n
def dm02_jiebase_userdict():
# 1 不使用用户字典
content = "氨基硅油是有机硅柔顺剂的一种,其主要作用是可以增加衣物的舒适度"
# 精确模式: 按照句子的语义对文本,尽量精准的进行分词
mydata1 = jieba.lcut(sentence=content, cut_all=False)
print('mydata1-->', mydata1)
# 2 使用用户字典
# 加载用户自定义字典
jieba.load_userdict('./userdict.txt')
# lcut
mydata2 = jieba.lcut(sentence=content, cut_all=False)
print('mydata2-->', mydata2)
pass

1.5 jieba-繁体文本分词
def dm03_jieba_base():
content = "煩惱即是菩提,我暫且不提"
mydata1 = jieba.lcut(content)
print('mydata1--->', mydata1)
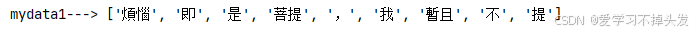
2.命名实体识别
- 命名实体: 将人名, 地名, 机构名等专有名词统称命名实体。如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机
- 命名实体识别:(Named Entity Recognition,简称NER),识别出一段文本中可能存在的命名实体
- 作用:命名实体也是人类理解文本的基础单元,是AI解决NLP领域高阶任务的重要基础环节
鲁迅,浙江绍兴人,五四新文化运动的重要参与者,代表作朝花夕拾。
==> 鲁迅(人名) / 浙江绍兴(地名)人 / 五四新文化运动(专有名词) / 重要参与者 / 代表作 / 朝花夕拾(专有名词)
3. 词性标注
-
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果,常见的词性有14种, 如: 名词, 动词, 形容词等
-
词性标注:(Part-Of-Speech tagging, 简称POS),标注出一段文本中每个词汇的词性
-
词向标注作用:对文本语言的另一个角度的理解,AI解决NLP领域高阶任务的重要基础环节
-
jieba词性对照表

-
进行词性标注,可以获取到其中形容词信息,然后进行评论分类
import jieba.posseg as pseg
pseg.lcut(sentence)
- 结果得到一个分词列表,列表中为pair对象,pair(“北京”,ns)
- pair(word,flag)
- 通过pair.word - 获取到词语
- 通过pair.flag - 获取到词性
import jieba.posseg as pseg
def dm04_jieba_posseg():
mydata1 = pseg.lcut("我爱北京天安门")
print('mydata1-->', mydata1)
for i in mydata1:
print(i.word)
print(i.flag)
# mydata1--> [pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









