




C4.5 决策树
ID3决策树倾向于选择种类多的特征作为分裂依据
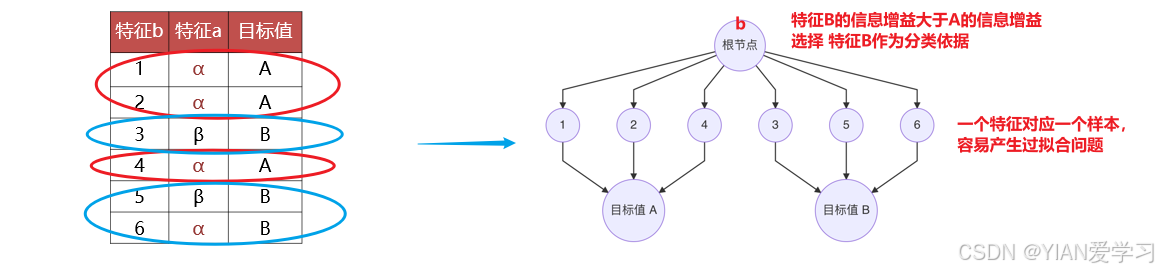
C4.5决策树对ID3决策树进行的修正,采用信息增益率作为选择分类特征的依据。
1. 信息增益率计算公式

- Gain_Ratio 表示信息增益率
- IV 表示分裂信息、内在信息,就是数据集D中某个特征的信息熵,特征熵
- 信息增益率 = 特征的信息增益 ➗ 内在信息(特征熵)
- 信息增益率还可以理解为,信息增益 * 惩罚系数,这里的乘法系数为特征熵的倒数
- 如果某个特征的特征值种类较多,则其内在信息值就越大,特征熵越大,惩罚系数越小,与信息增益相乘之后,会减小信息增益选择的缺点。
- 如果某个特征的特征值种类较小,则其内在信息值就越小,特征熵越小,惩罚系数越大。
- **信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
- 惩罚参数:数据集D以特征A作为随机变量的熵的倒数。**
2. 信息增益率计算举例
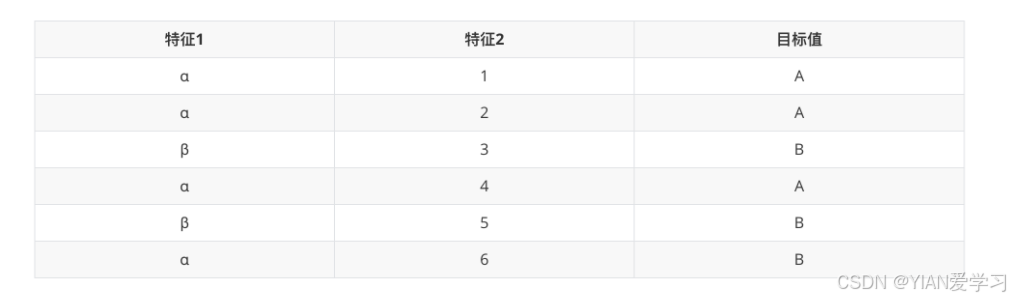
特征1的信息增益率:
- 信息增益:
0.5408520829727552 - 分裂信息:
-4/6*math.log(4/6, 2) -2/6*math.log(2/6, 2)=0.9182958340544896 - 信息增益率:
信息增益/分裂信息=0.5408520829727552/0.9182958340544896=0.5889736868180786
特征2的信息增益率:
- 信息增益:1
- 分裂信息:
-1/6*math.log(1/6, 2) * 6=2.584962500721156 - 信息增益率:
信息增益/信息熵=1/2.584962500721156=0.38685280723454163
由计算结果可见:
- 如果采用信息增益就会选择特征2作为分裂特征。
- 采用信息增益率为指标,特征1的信息增益率大于特征2的信息增益率,我们应该选择特征1作为分裂特征。
3. ID3和C4.5对比
-
ID3算法缺点
- ID3算法不能处理具有连续值的属性
- ID3算法不能处理属性具有缺失值的样本
- 算法会生成很深的树,容易产生过拟合现象
- 算法一般会优先选择有较多属性值的特征,因为属性值多的特征会有相对较大的信息增益,但这里的属性并不一定是最优的
-
C4.5算法的核心思想是ID3算法,对ID3算法进行了相应的改进。
- C4.5使用的是信息增益比来选择特征,克服了ID3的不足。
- 可以处理离散型描述属性,也可以处理连续数值型属性
- 能处理不完整数据
-
C4.5算法优缺点
- 优点:分类规则利于理解,准确率高
- 缺点
- 在构造过程中,需要对数据集进行多次的顺序扫描和排序,导致算法的低效
- C4.5只适合于能够驻留内存的数据集,当数据集非常大时,程序无法运行
-
无论是ID3还是C4.5最好在小数据集上使用,当特征取值很多时最好使用C4.5算法。
4. 小结
- 信息增益率用于计算模型优先选择那个特征进行树分裂
- 使用信息增益率构建的决策树成为 C4.5 决策树

















 6204
6204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









