







动手学深度学习笔记
一、BERT
在word2vec和GloVe中,每个词都是由一个固定的预训练向量表示,而不考虑词的上下文。这些词嵌入模型都是与上下文无关的,无法解决一词多义或复杂语义的问题。
随后,ELMo(Embeddings from Language Models) 通过两个LSTM进行双向建模,学习到了词的上下文,从而解决了一词多义的问题。具体来说,ELMo将来自预训练的双向LSTM的所有中间层表示组合为输出表示,然后,ELMo的表示将作为附加特征添加到下游任务的有监督模型中,例如通过将ELMo的表示和现有模型中词元的原始表示(例如GloVe)连结起来。一方面,在加入ELMo表示后,冻结了预训练的双向LSTM模型中的所有权重。另一方面,现有的监督模型是专门为给定的任务定制的。
尽管ELMo显著改进了各种自然语言处理任务的解决方案,但每个解决方案仍然依赖于一个特定于任务的架构。然而,为每一个自然语言处理任务设计一个特定的架构实际上并不是一件容易的事。
GPT(Generative Pre Training)模型为上下文的敏感表示设计了通用的任务无关模型。GPT建立在Transformer解码器的基础上,预训练了一个用于表示文本序列的语言模型。当将GPT应用于下游任务时,语言模型的输出将被送到一个附加的线性输出层,以预测任务的标签。与ELMo冻结预训练模型的参数不同,GPT在下游任务的监督学习过程中可以对预训练Transformer解码器中的所有参数进行微调。
然而,由于语言模型的自回归特性,GPT只能向前看(从左到右)。在“i went to the bank to deposit cash”(我去银行存现金)和“i went to the bank to sit down”(我去河岸边坐下)的上下文中,由于“bank”对其左边的上下文敏感,GPT将返回“bank”的相同表示,尽管它有不同的含义。
1.BERT:把两个结合起来
ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文。BERT(来自Transformers的双向编码器表示)结合了这两个模型的优点。它对上下文进行双向编码,并且对于大多数的NLP任务只需要少量的架构改变。通过使用预训练的Transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。
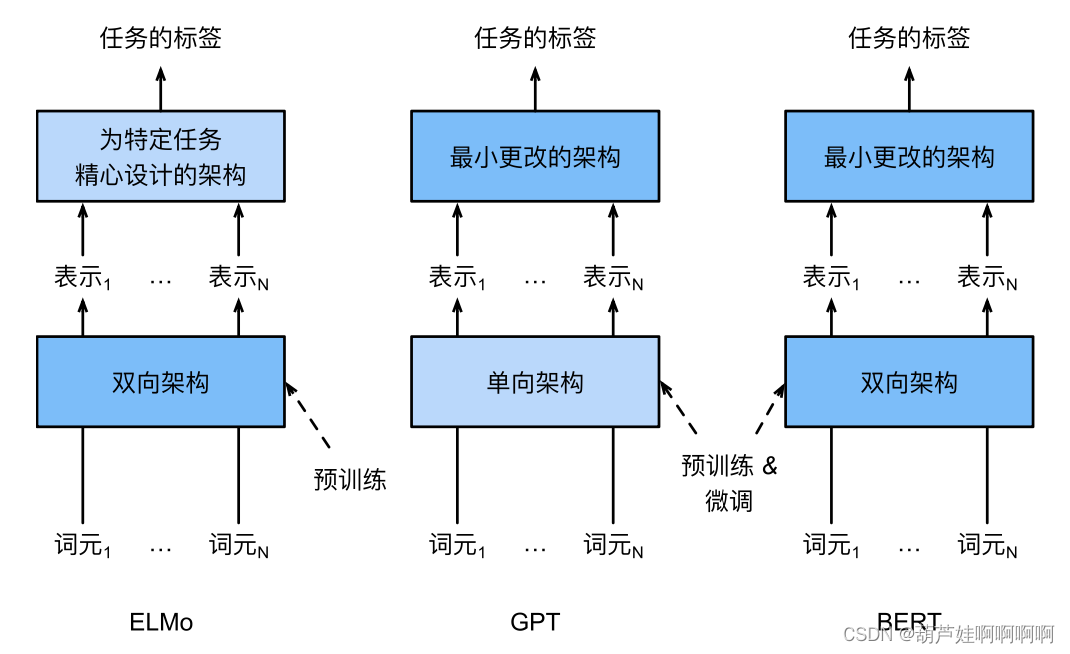
从上下文敏感的ELMo到任务不可知的GPT和BERT,它们都是在2018年提出的。BERT刷新了11种NLP任务的技术水平。
2.BERT的输入表示
在NLP中,有些任务(如情感分析)以单个文本作为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。当输入为单个文本时,BERT输入序列是特殊类别词元“<cls>”、文本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对时,BERT输入序列是“<cls>”、第一个文本序列的标记、“<sep>”、第二个文本序列标记、以及“<sep>”的连结。
下面的函数将一个句子或两个句子作为输入,然后返回BERT输入序列的标记及其相应的片段索引。
import torch
from torch import nn
from d2l import torch as d2l
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * len(tokens)
if tokens_b:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
3.编码器
BERT以Transformer编码器作为其双向架构。BERTEncoder类与Transformer中实现的TransformerEncoder类相似。不同的是,BERTEncoder使用词元嵌入、片段嵌入和可学习的位置嵌入的和作为其输入序列的嵌入。
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{
i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的
self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
4.预训练任务
预训练包括两个任务:掩蔽语言模型和下一句预测。前者能够编码双向上下文来表示单词,而后者则显式地建模文本对之间的逻辑关系。
掩蔽语言模型
语言模型使用左侧的上下文预测词元。为了双向编码上下文以表示每个词元,BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。此任务称为掩蔽语言模型(Masked Language Modeling)。
在这个预训练任务中,将随机选择15%的词元作为预测的掩蔽词元。要预测一个掩蔽词元而不使用标签作弊,一个简单的方法是总是用一个特殊的“<mask>”替换输入序列中的词元。然而,特殊词元“<mask>”不会出现在微调中。为了避免预训练和微调之间的这种不匹配,如果为预测而屏蔽词元(例如,在“this movie is great”中选择掩蔽和预测“great”),则在输入中将其替换为:
- 80%概率为特殊的“<mask>“词元;
- 10%概率为随机词元;
- 10%概率内为不变的标签词元。
请注意,在15%的概率中,有10%的概率插入了随机词元。这种偶然的噪声鼓励BERT在其双向上下文编码中不那么偏向于掩蔽词元(尤其是当标签词元保持不变时)。
- 预测BERT掩蔽语言模型任务中的掩蔽标记
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
"""输入BERTEncoder的编码结果和用于预测的词元位置,输出是这些位置的预测结果"""
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx = tensor([0, 0, 0, 1, 1, 1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
下一句预测
尽管掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测(Next Sentence Prediction)。在为预训练生成句子对时,有一半的概率它们确实是标签为“真”的连续句子;在另一半的概率里,第二个句子是从语料库中随机抽取的,标记为“假”。
由于Transformer编码器中的自注意力,特殊词元“<cls>”的BERT表示已经对输入的两个句子进行了编码。因此,多层感知机分类器的输出层(self.output)以X作为输入,其中X是多层感知机隐藏层的输出,而MLP隐藏层的输入是编码后的“<cls>”词元。
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











