






 该博客探讨了Seq2Seq模型在处理长序列时面临的梯度消失问题,以及如何通过引入Attention机制来改善这一状况。Self-Attention在计算中考虑每个单词的重要性,解决了传统模型中长期依赖的问题,且能并行计算,提高效率。此外,博客还提及深度文本匹配的应用,如搜索引擎、聊天机器人和翻译,并介绍了如何利用卷积计算文本相似度。
该博客探讨了Seq2Seq模型在处理长序列时面临的梯度消失问题,以及如何通过引入Attention机制来改善这一状况。Self-Attention在计算中考虑每个单词的重要性,解决了传统模型中长期依赖的问题,且能并行计算,提高效率。此外,博客还提及深度文本匹配的应用,如搜索引擎、聊天机器人和翻译,并介绍了如何利用卷积计算文本相似度。
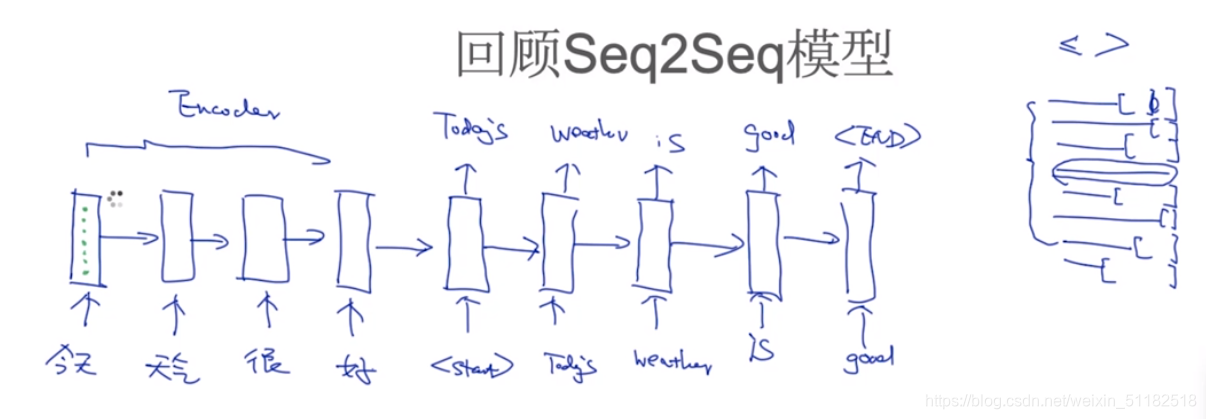
1、回顾Seq2Seq模型
预处理中,要保证每个seq长度一致
输出时,找到长度最长的len,然后把其他输出补齐
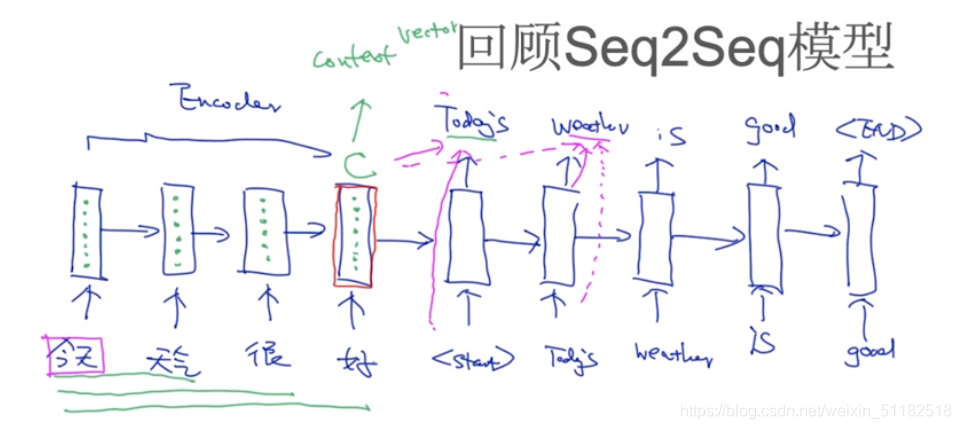
结构的问题
- 1、梯度问题:当seq过长时,当前词无法捕获到很前面时刻的单词信息,梯度消失
- 2、应用的角度:w=(prev,c),对于某一个词的翻译,只需要观察原始seq中的某一部分的重要信息。使用attention解决
- 3、c没有考虑句子的长度
- 4、BottleNeck:决定了decoder的生成效果

2、Seq2Seq 的 Attention
attention:学习每个单词权重的过程
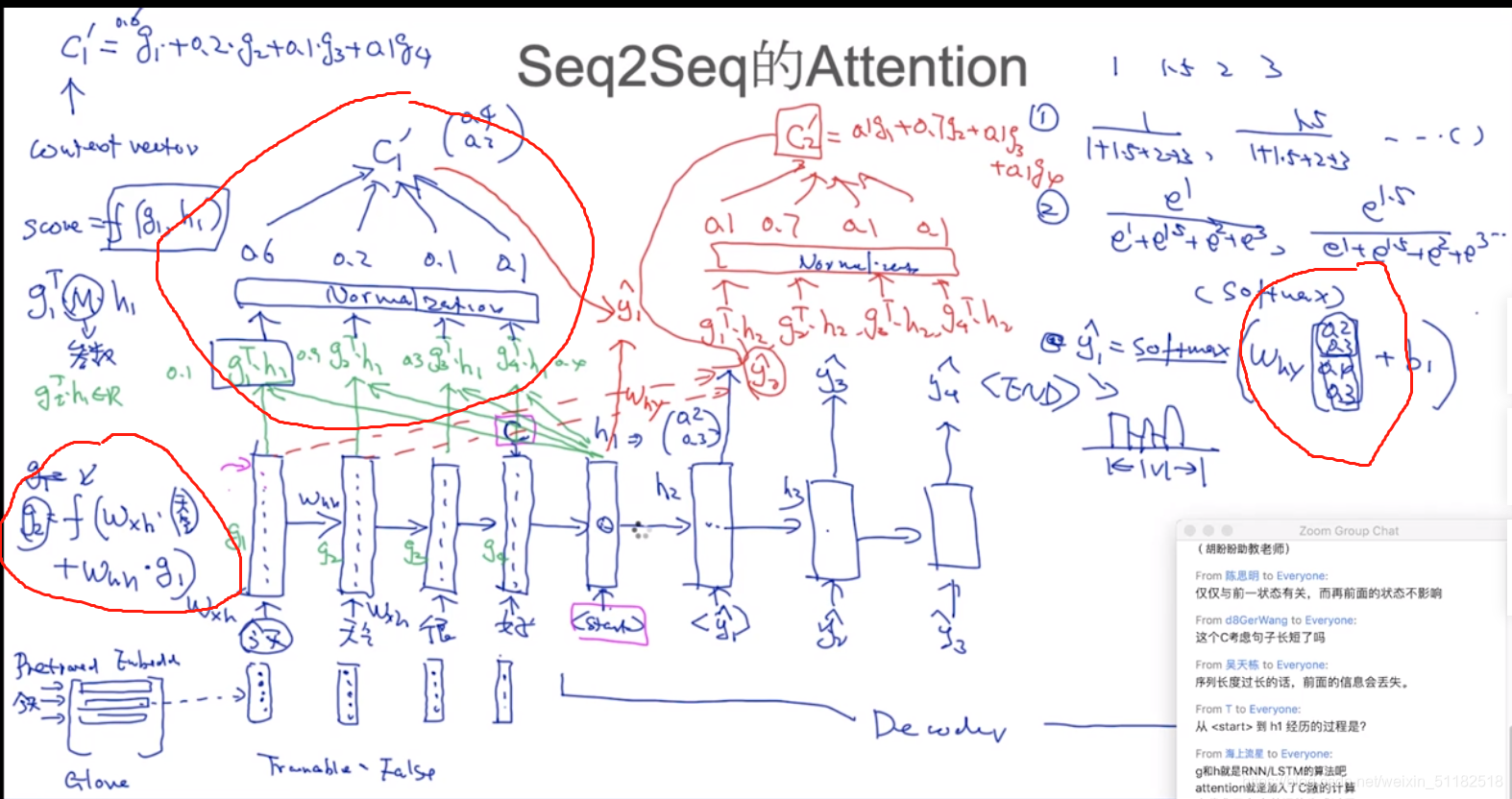
对于decoder中,每个时刻的单词生成考虑了encoder中每个时刻的输出值和h之间的关系。权值较大的会对于decoder的生成贡献更多。
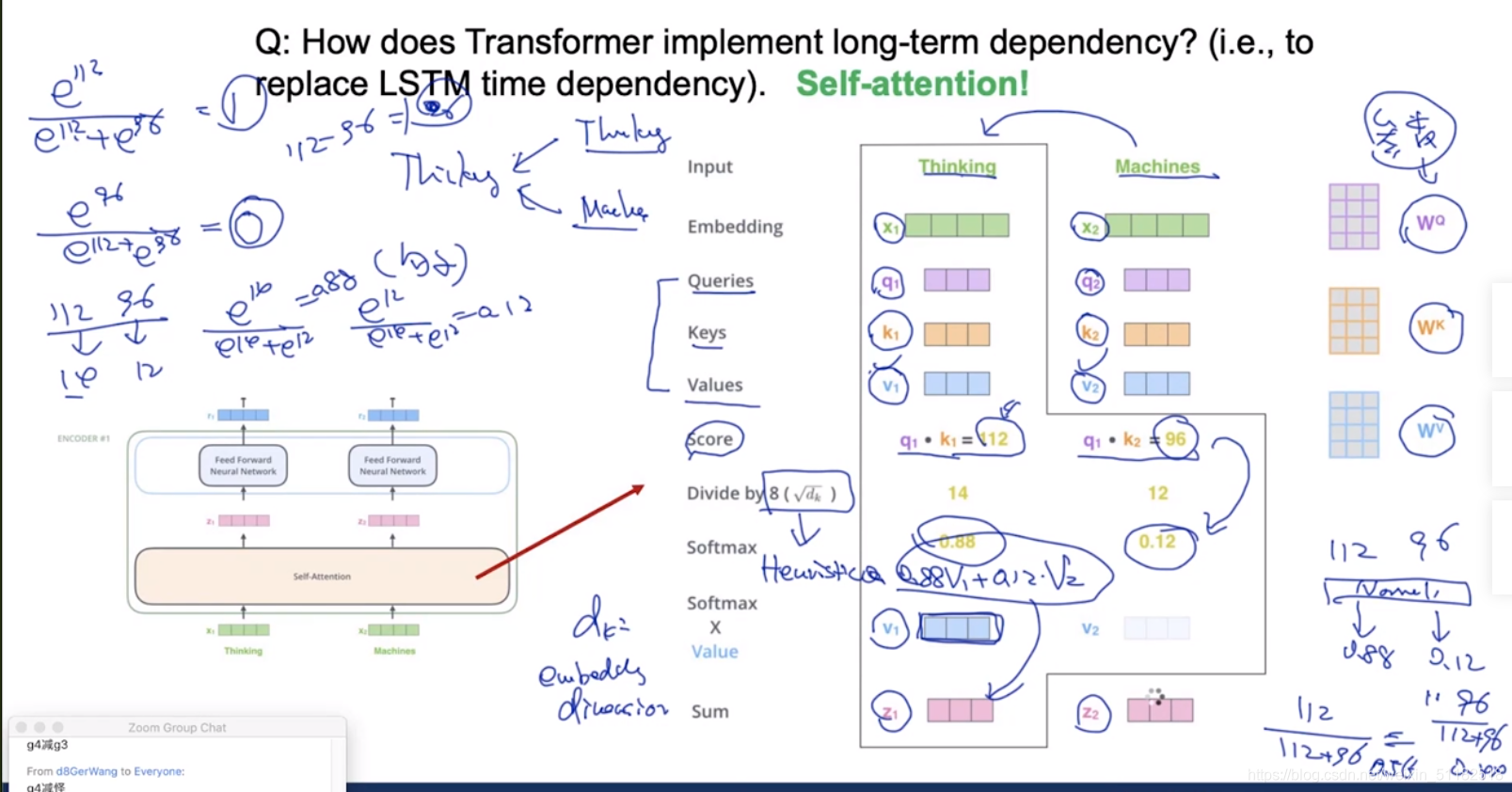
3、Self-attention
3.1 Transformer
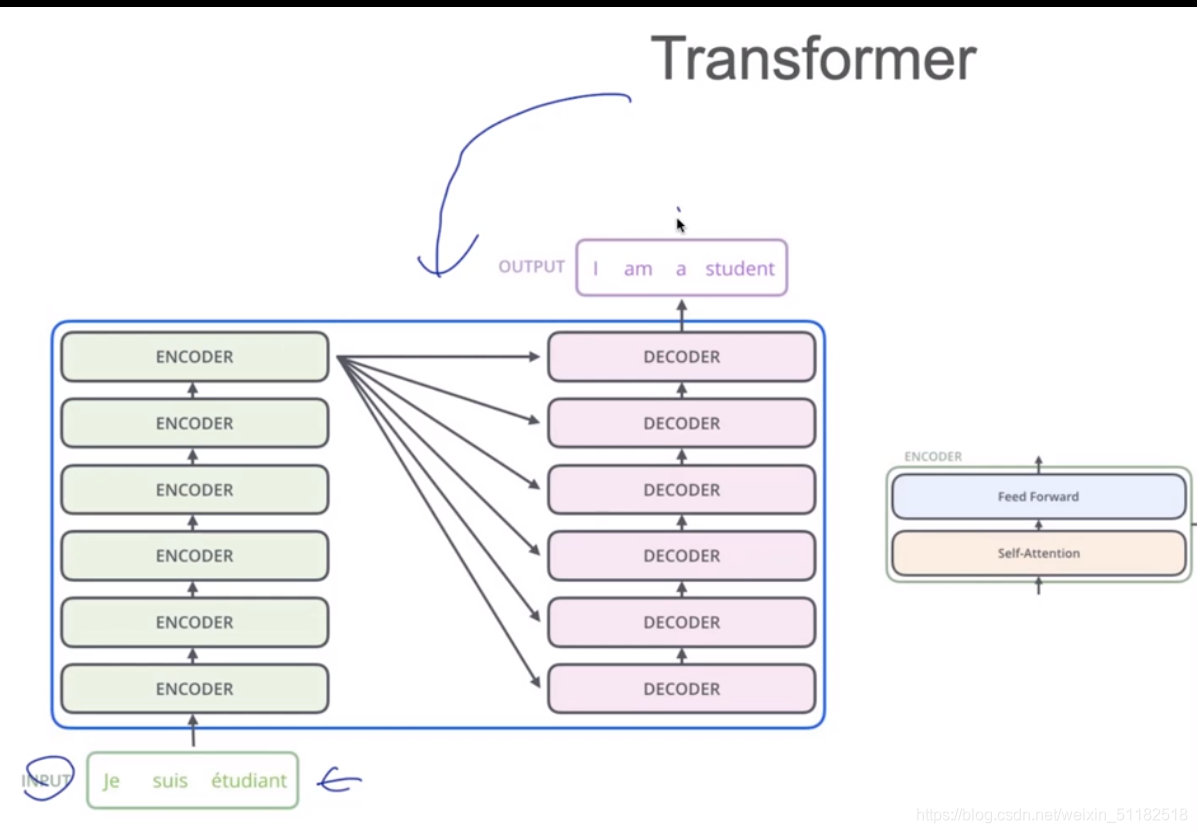
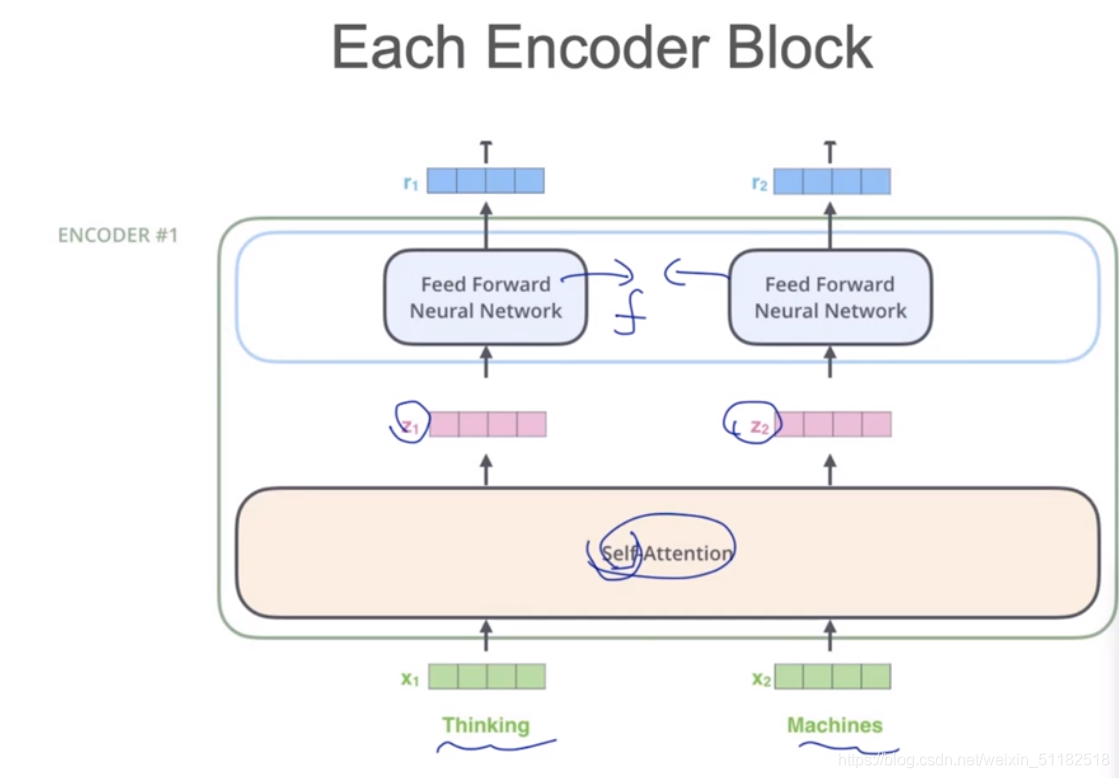
Feed forward neural network:激活函数
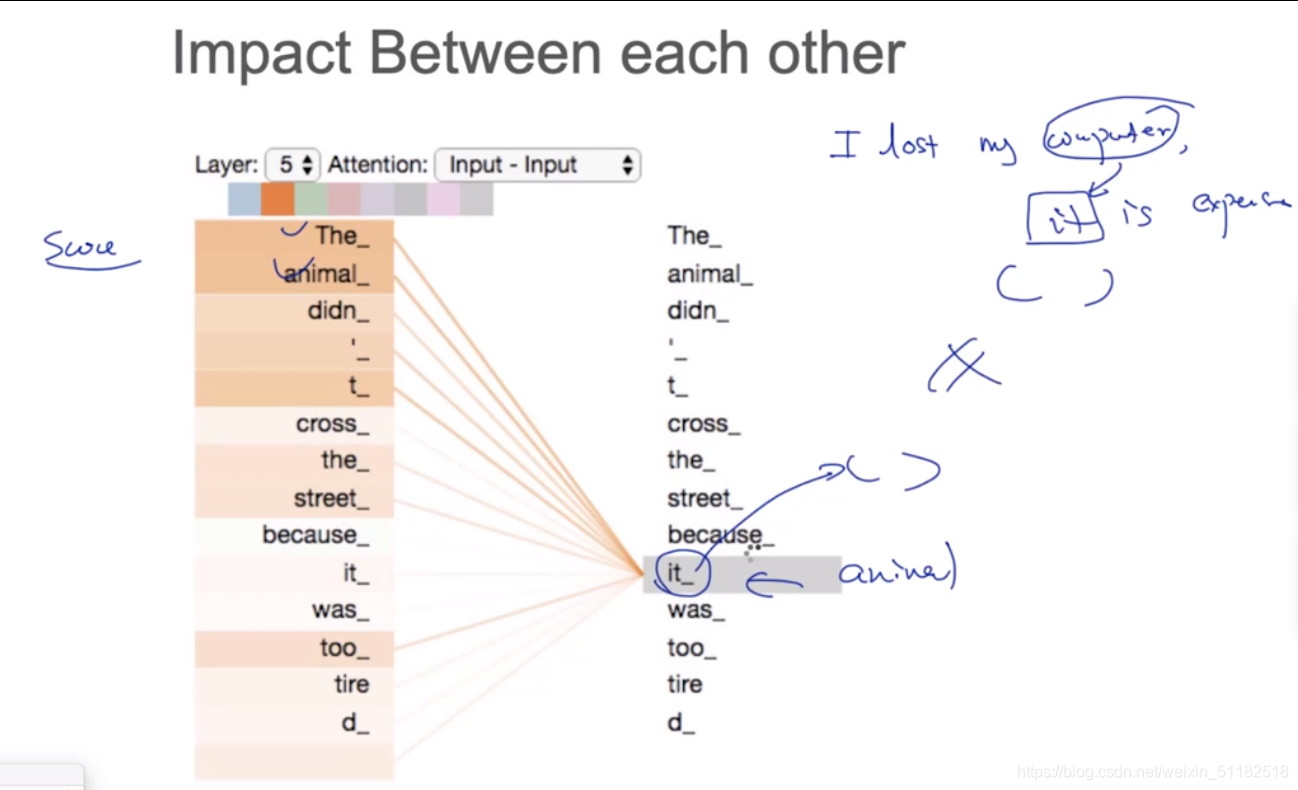
Impact between each other
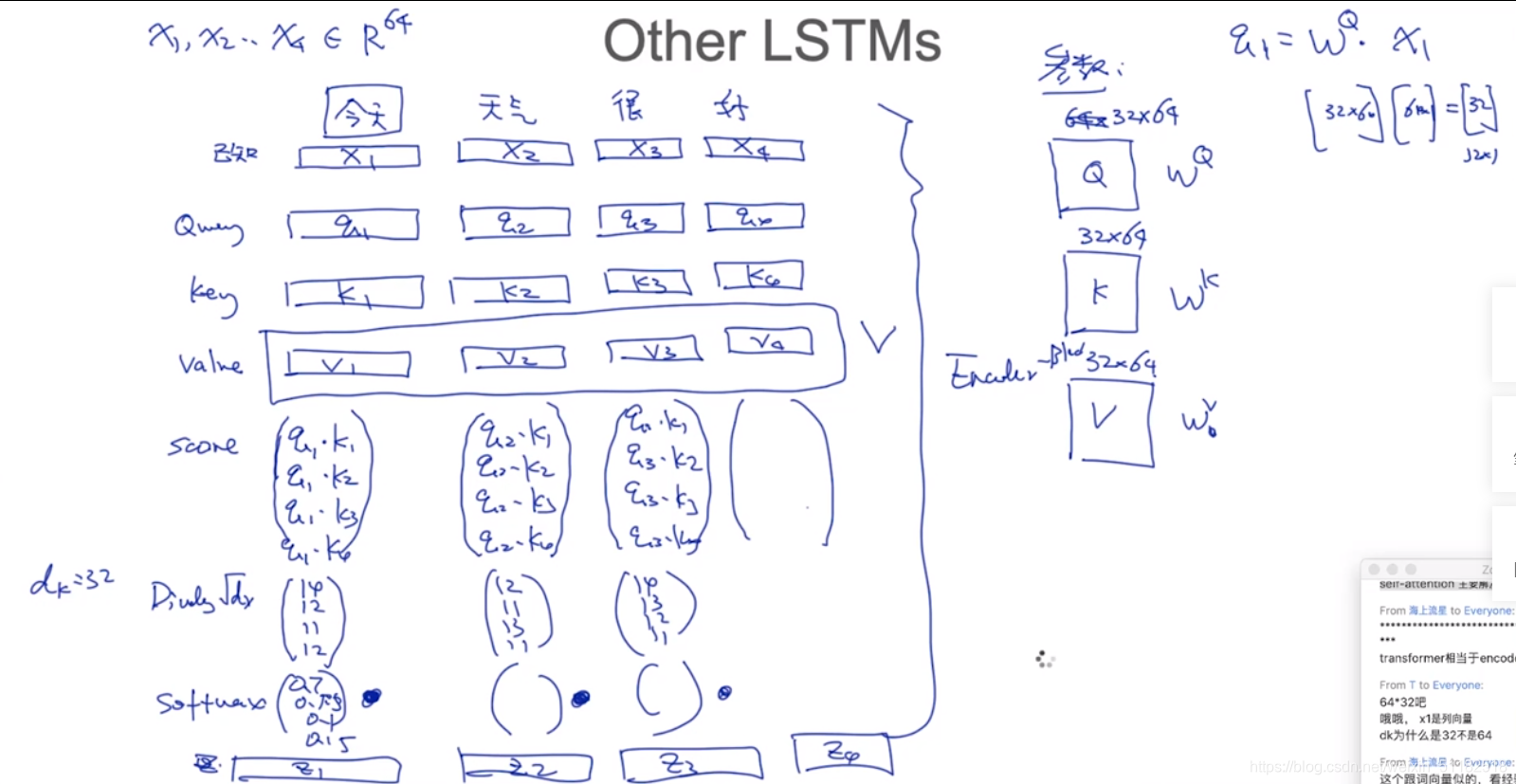
q,k,v的维度不一定要和word embedding的dim一样。
为什么需要self-attention
- Long term dependency:对于普通RNN模型作为encoder,如果decoder的部分只选择最后一个时刻的输出的话。最后一个时刻的输出会包含更多的靠后时刻的信息而忽略前面几个时刻的信息。Gradient vanishing 导致前几个时刻的梯度无法更新。
self-attention 解决: 在计算过程中,考虑了每个单词的weight/重要性。考虑了所有词的信息。 - 串行计算:时序类模型,无法并行计算。
self-attention 解决 q,k,v可以并行计算
4、深度文本匹配
4.1 应用场景
- 搜索引擎
- chat-bot
- 翻译
4.2 单语义文本匹配
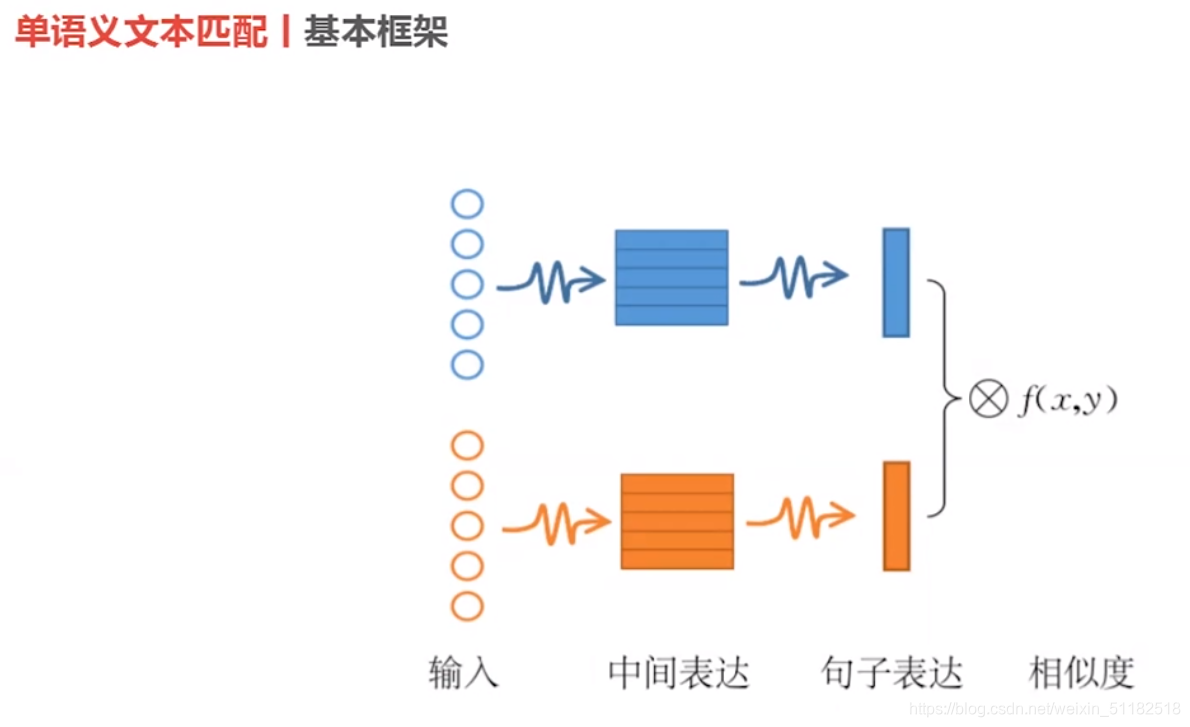
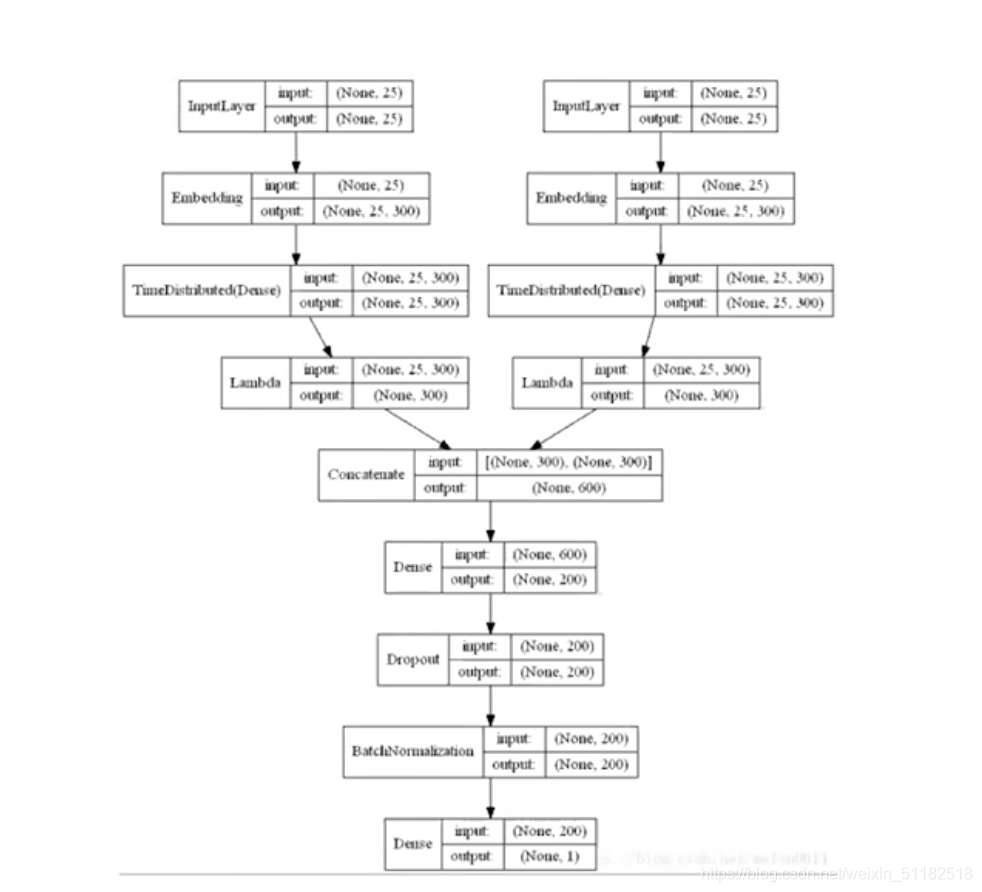
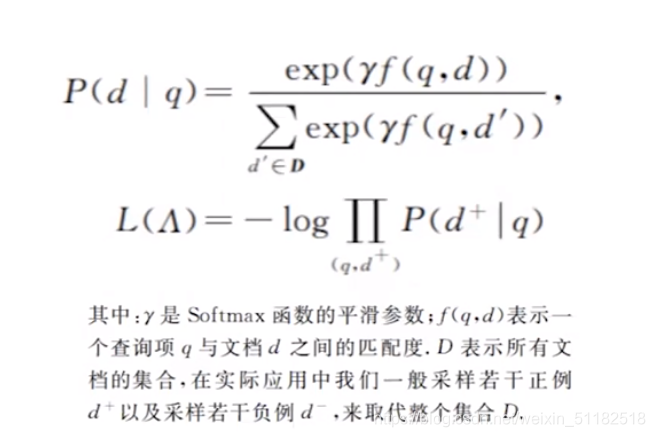
4.3 多语义文档表达
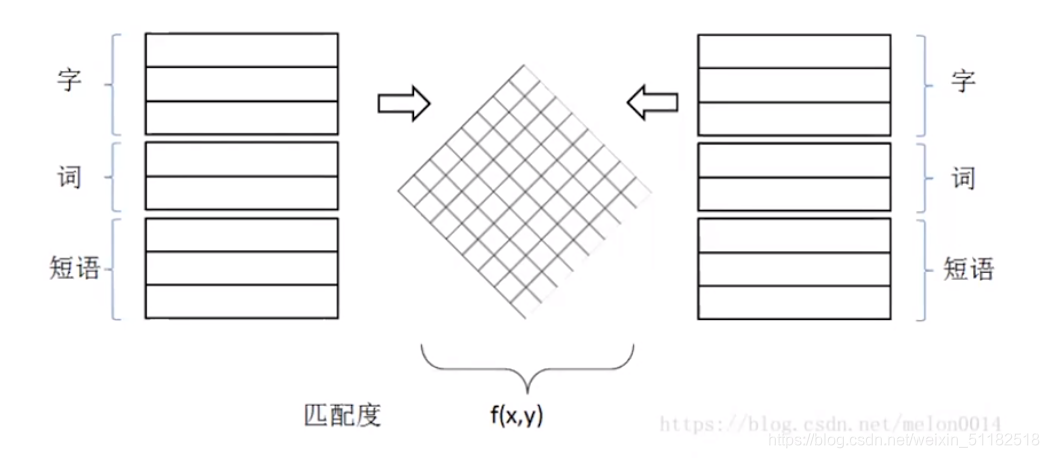
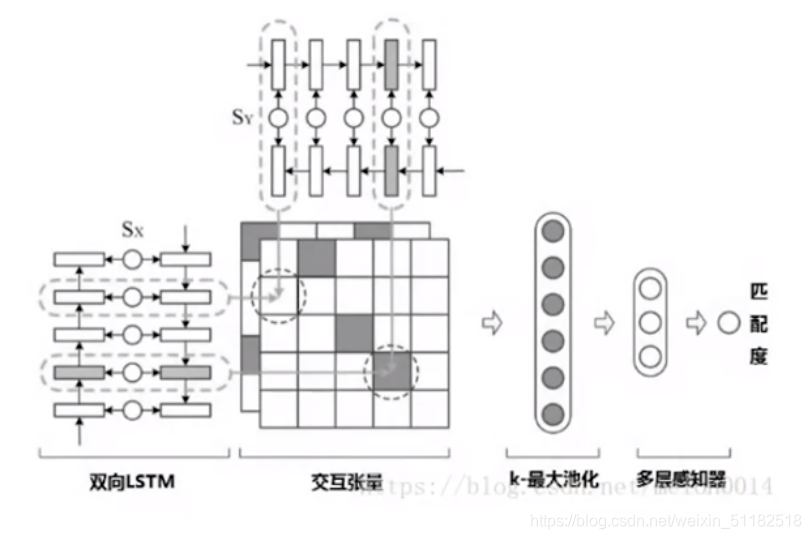
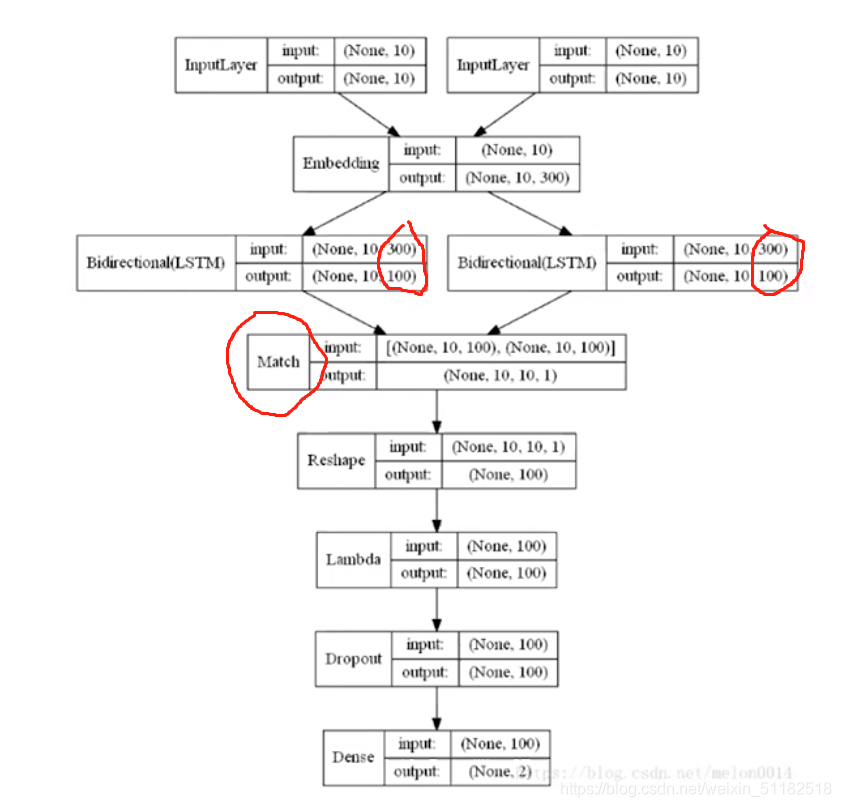
match过后的output就是[10,10,1]代表两句话每个单词之间的数值化的关系表示
可以使用image 卷积的方式计算两个文本的相似度
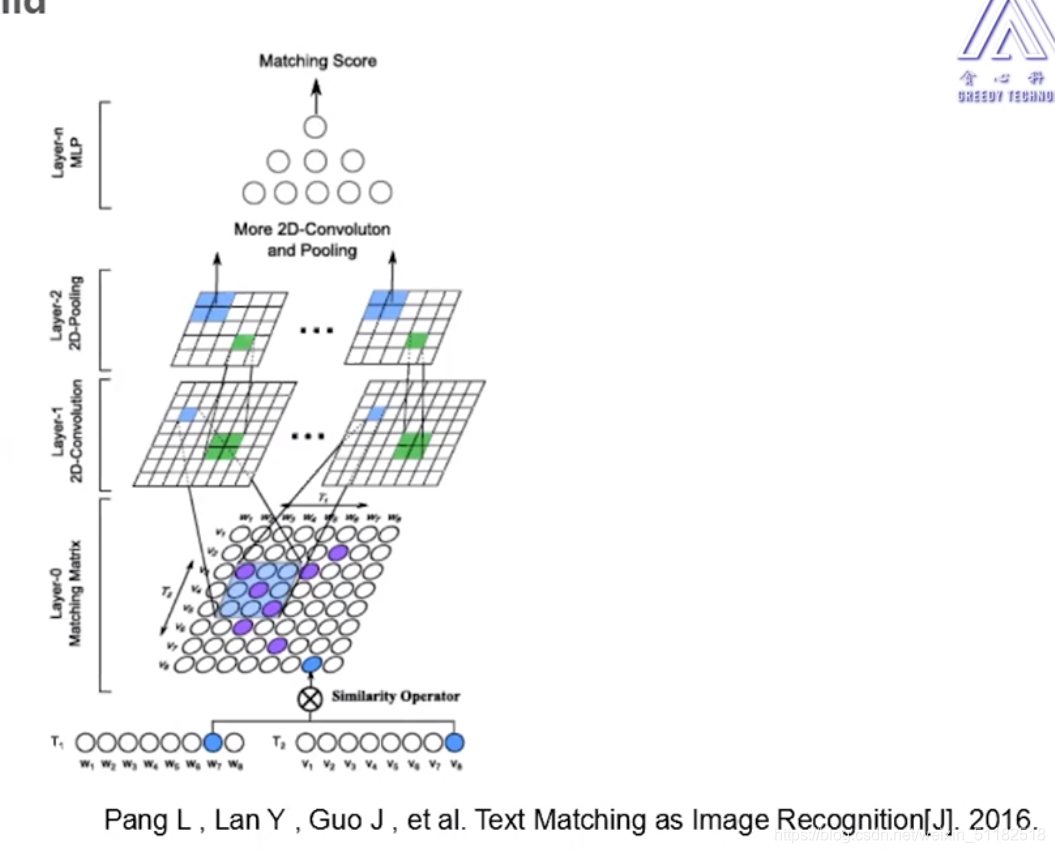
卷积核扫过match后矩阵的特征的过程也考虑了上下文的关系。
4.4 问题与问题的匹配和问题与答案的匹配
问题和问题之间的性质一样,可以共享一个网络参数
问题与答案应该由两个网络分别进行运算。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









