






 本文深入探讨了Seq2Seq模型在机器翻译中的应用,包括训练数据、解码策略如贪心搜索与Beam Search。同时,介绍了注意力机制在机器翻译和图像描述中的重要性,以及seqGAN的相关概念,结合强化学习优化序列生成。
本文深入探讨了Seq2Seq模型在机器翻译中的应用,包括训练数据、解码策略如贪心搜索与Beam Search。同时,介绍了注意力机制在机器翻译和图像描述中的重要性,以及seqGAN的相关概念,结合强化学习优化序列生成。
1、Drop out
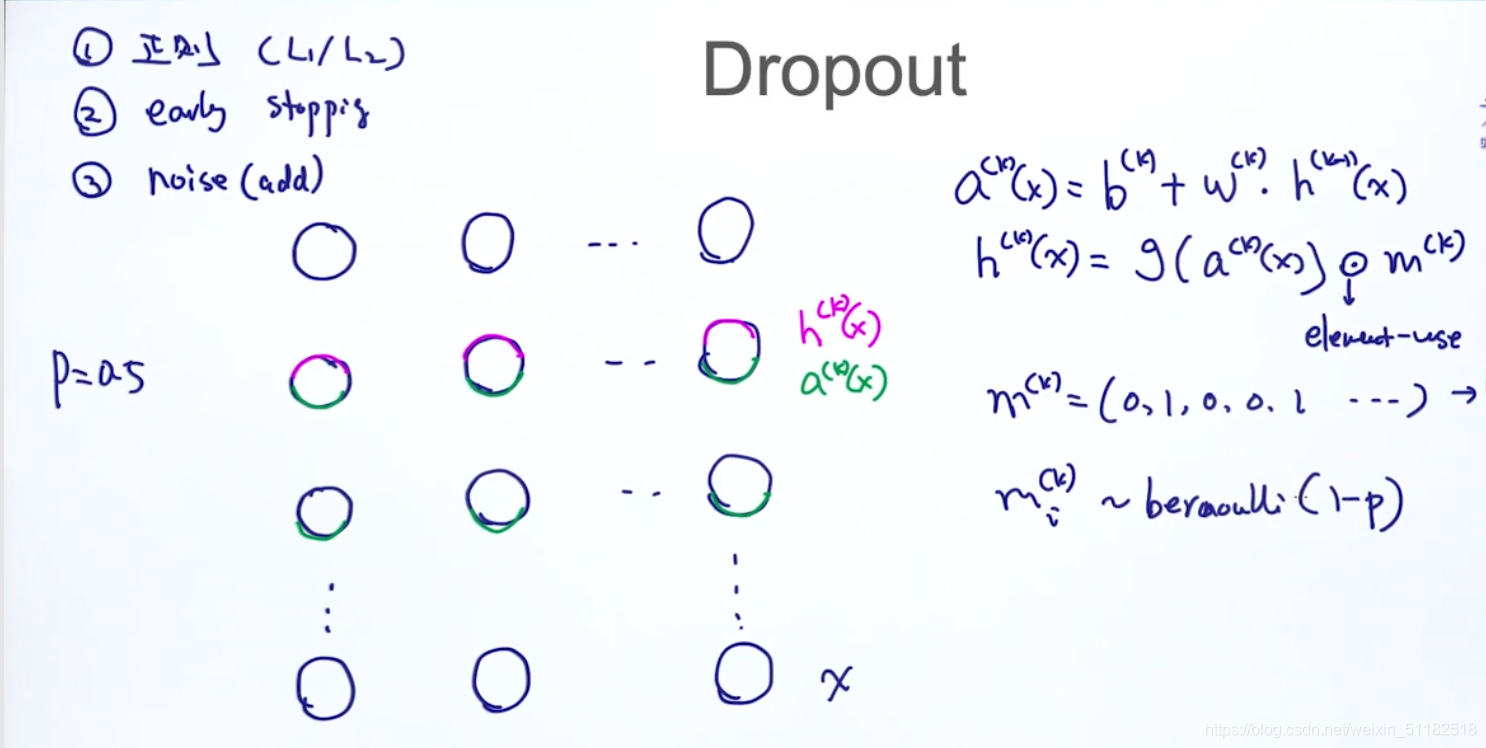
m ( k ) m^{(k)} m(k)决定了哪些节点的weight被drop out
keep_prob 需要调参

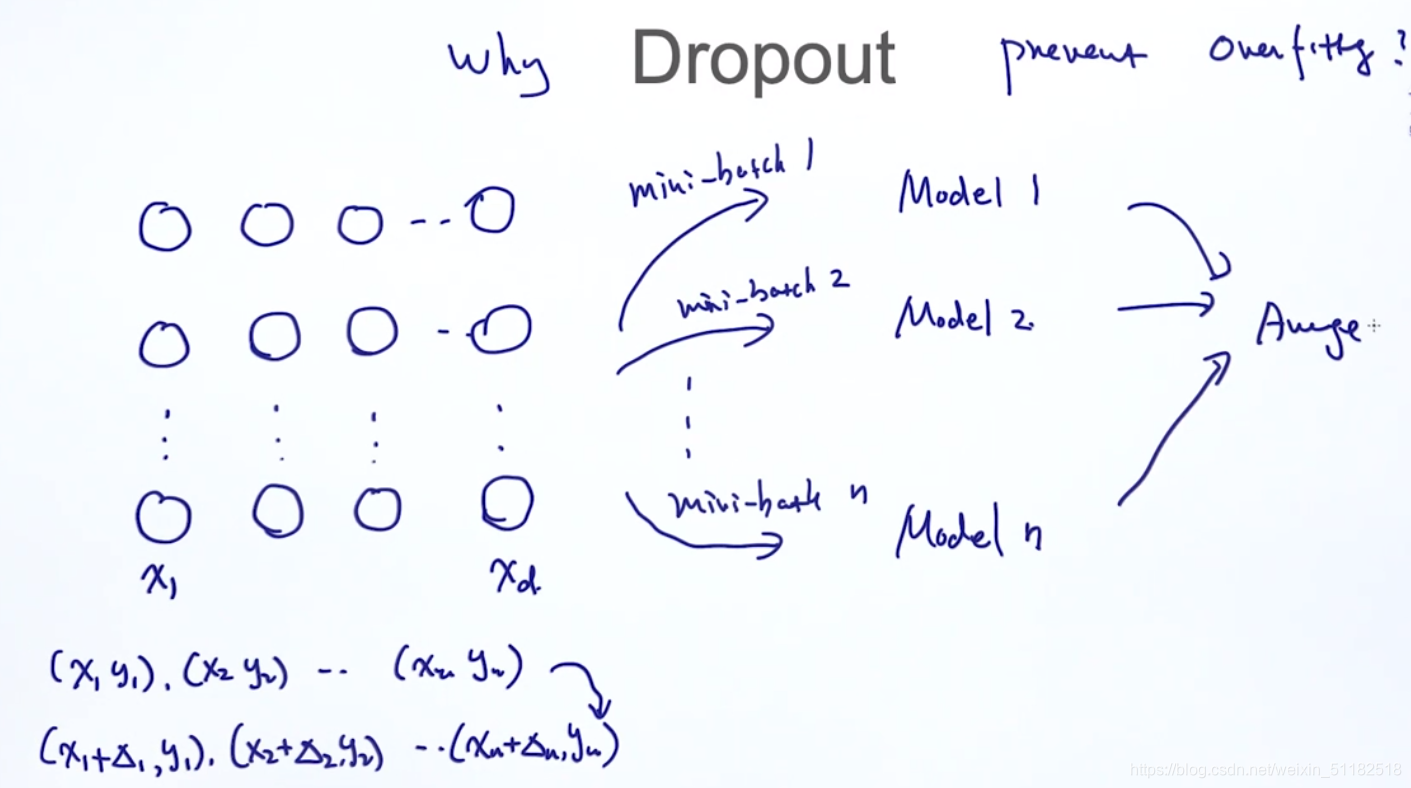
2、为什么drop out 防止过拟合
答:减少了模型的复杂度
对于每一个mini-batch,使用drop out 训练了不一样的模型,在预测时可以使用这些模型的average
3、机器翻译
基于深度学习的机器翻译系统,端到端的翻译,不需要语法。例如使用:RNN/LSTM模型
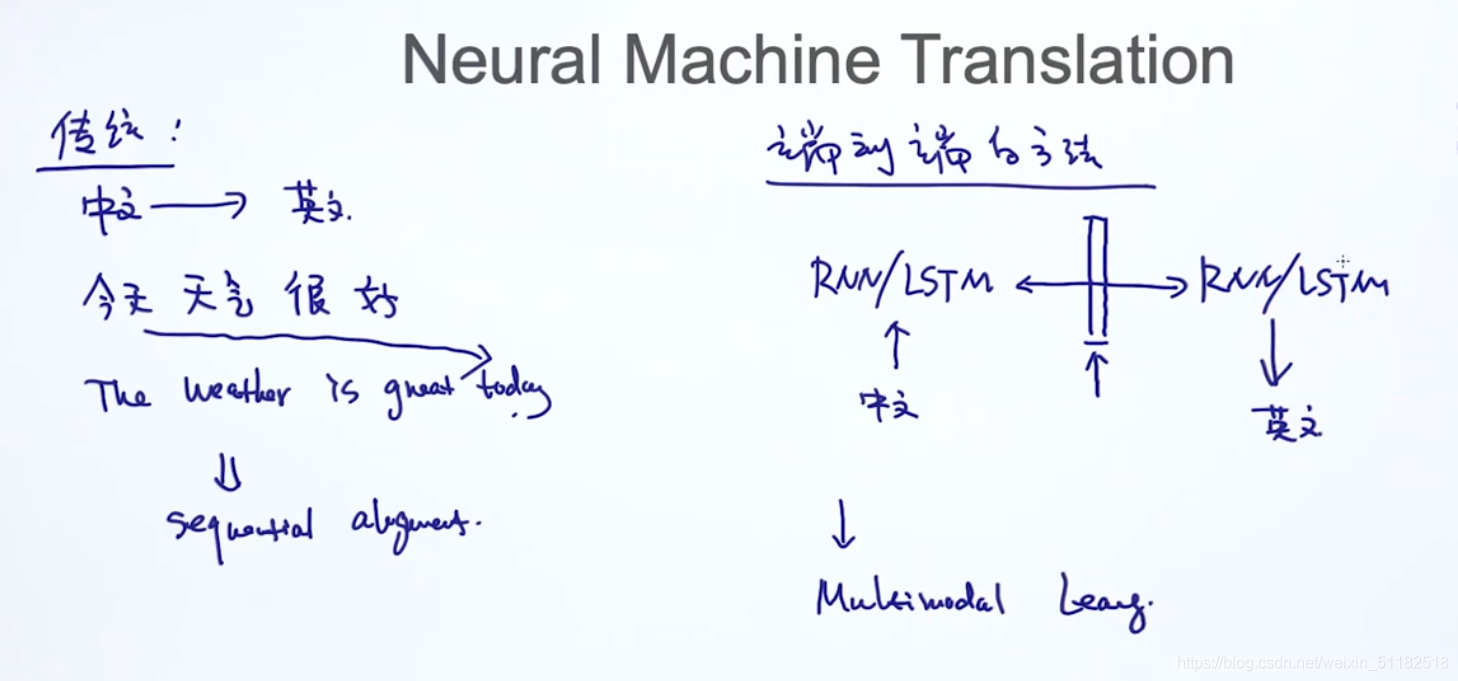
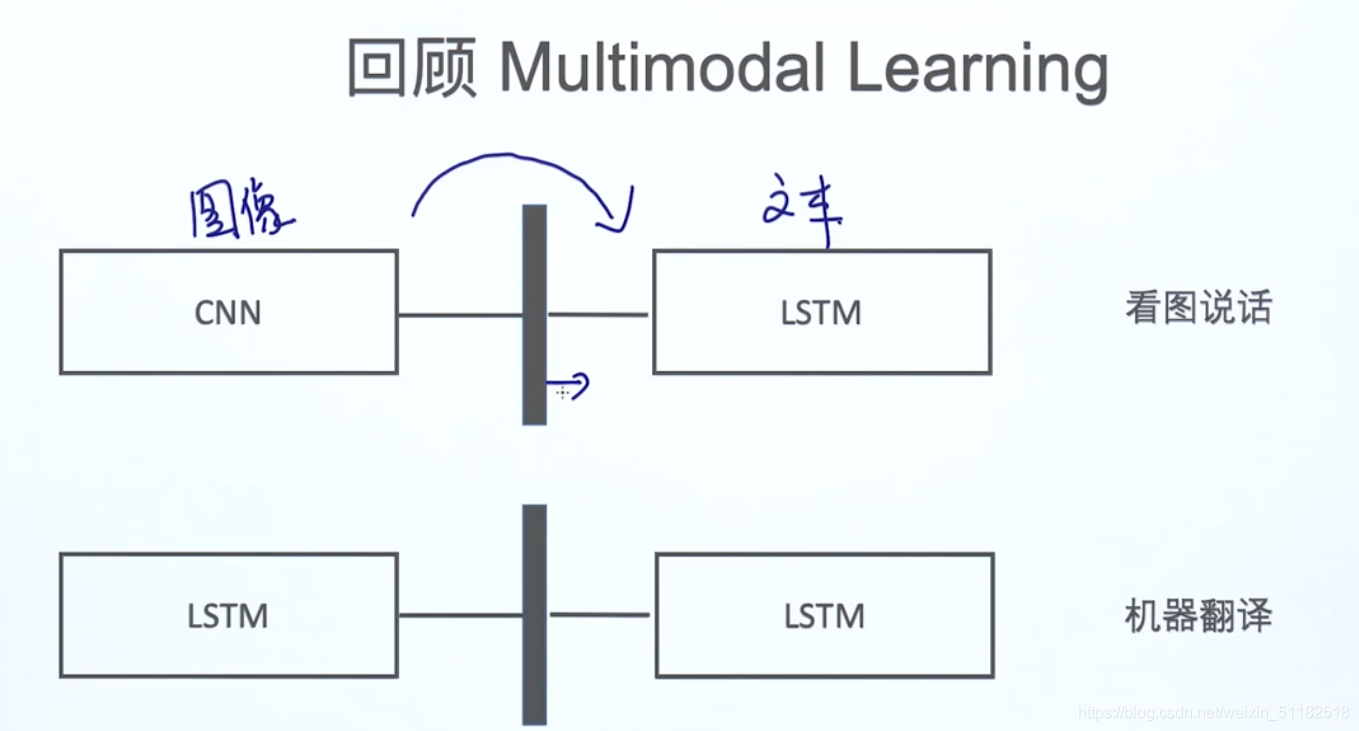
4、Multimodal learning

通过拼接两个模型,达到任务目的
5、Seq2Seq Model
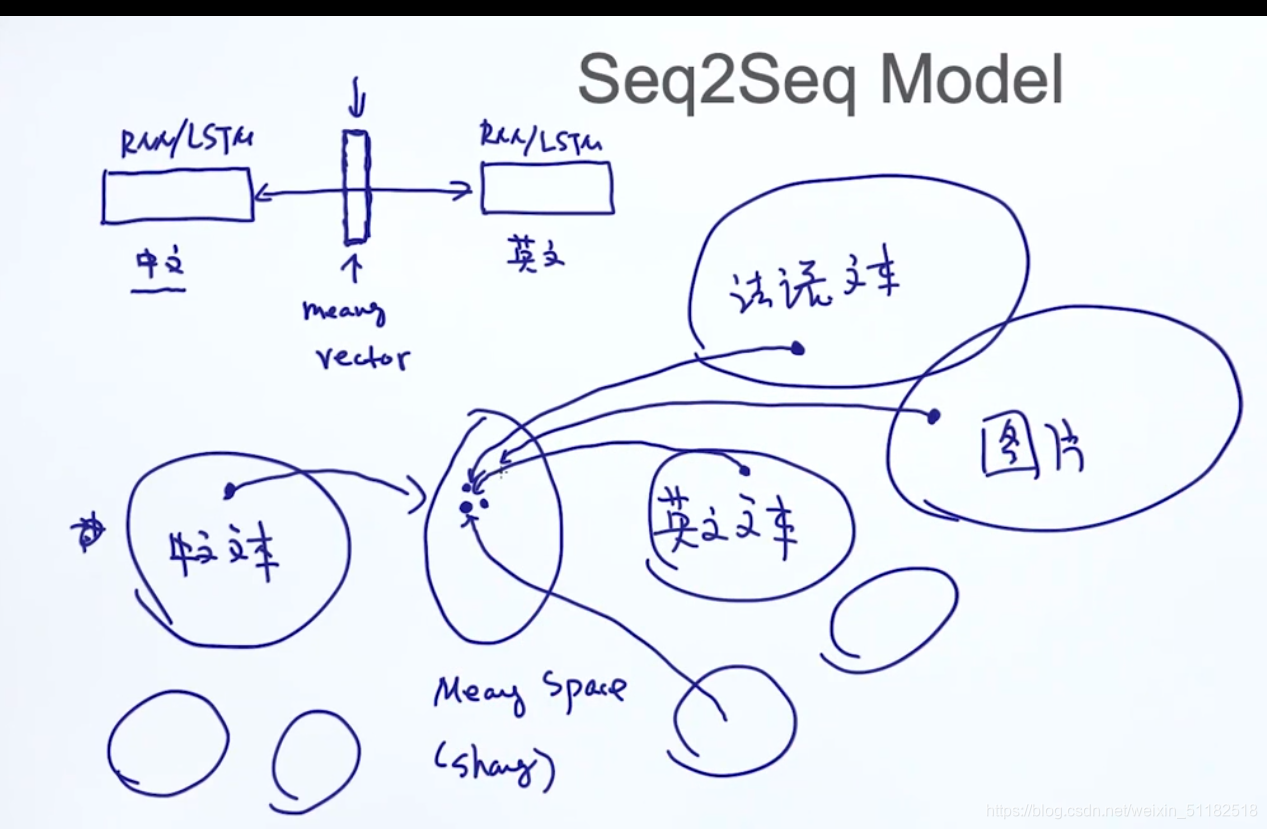
5.1 应用在机器翻译上:
讲一句话输入进rnn,最后时刻的输出保存了这句话的meaning,
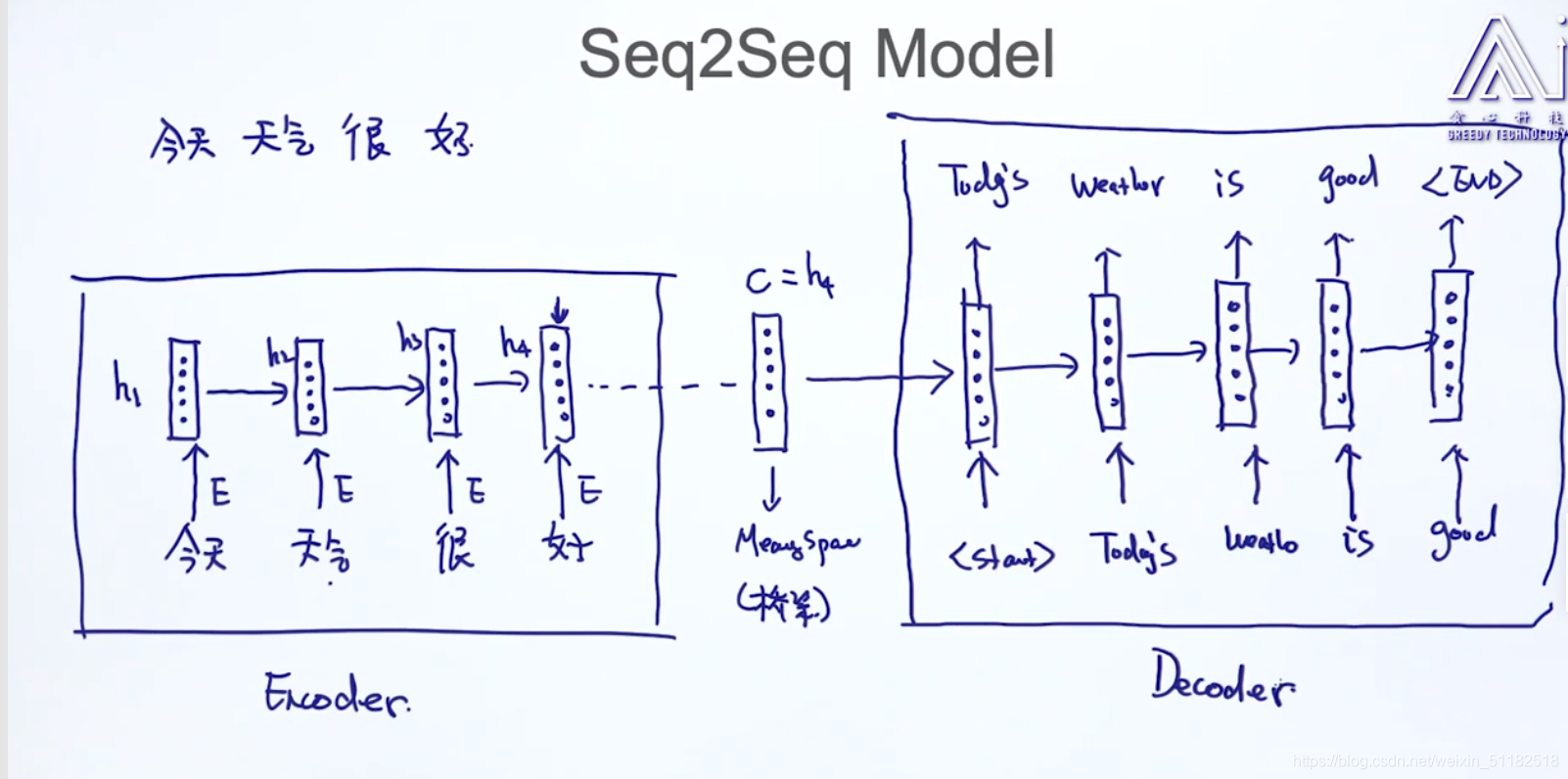
5.2 训练数据

5.3 Inference/Decoding
输出的结果是一个概率分布图
Inference/decoding:在已知模型参数的情况下,给定数据输入模型,得到输出
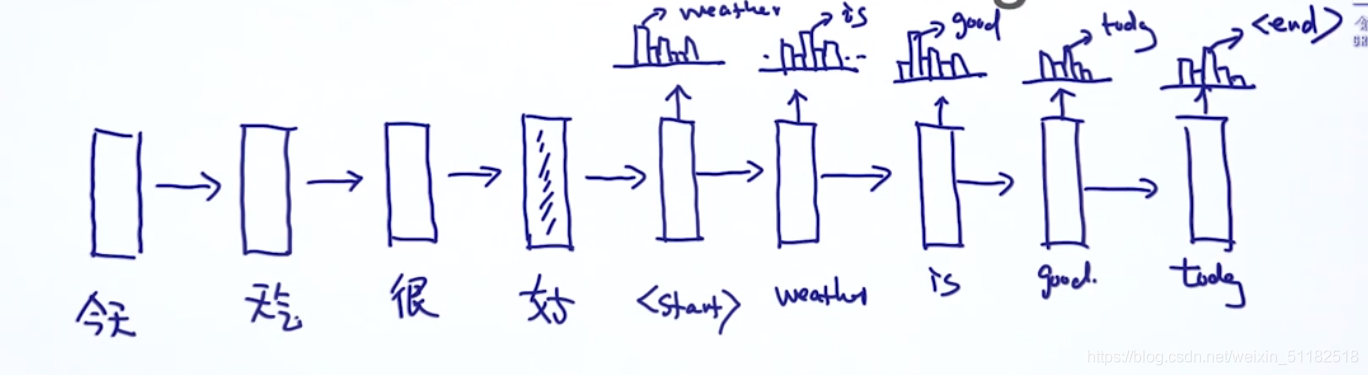
如何去判断通过seq2seq model的性能
- 1、判断预测值和实际值之间的相似性/重叠性

上述的两个输出预测值和第一个句子的实际值的重叠性都很好,但显示红色的预测值并不符合语义,如果只考虑单词之间的重叠性,即uni-gram的方法,会忽略单词组合顺序这一重要特性。
解决:bigram,trigram,…N-gram
decoding的过程:每一步都输出最好的结果(当前出现概率最大的单词),贪心算法,只能得到局部最优解。
如何解决:Beam search:每一次保留topk的结果
5.4 Exhaustic Search 穷举法
对于单词很多的概率分布,对于每时刻都考虑所有的可能会使时间复杂度变大很多
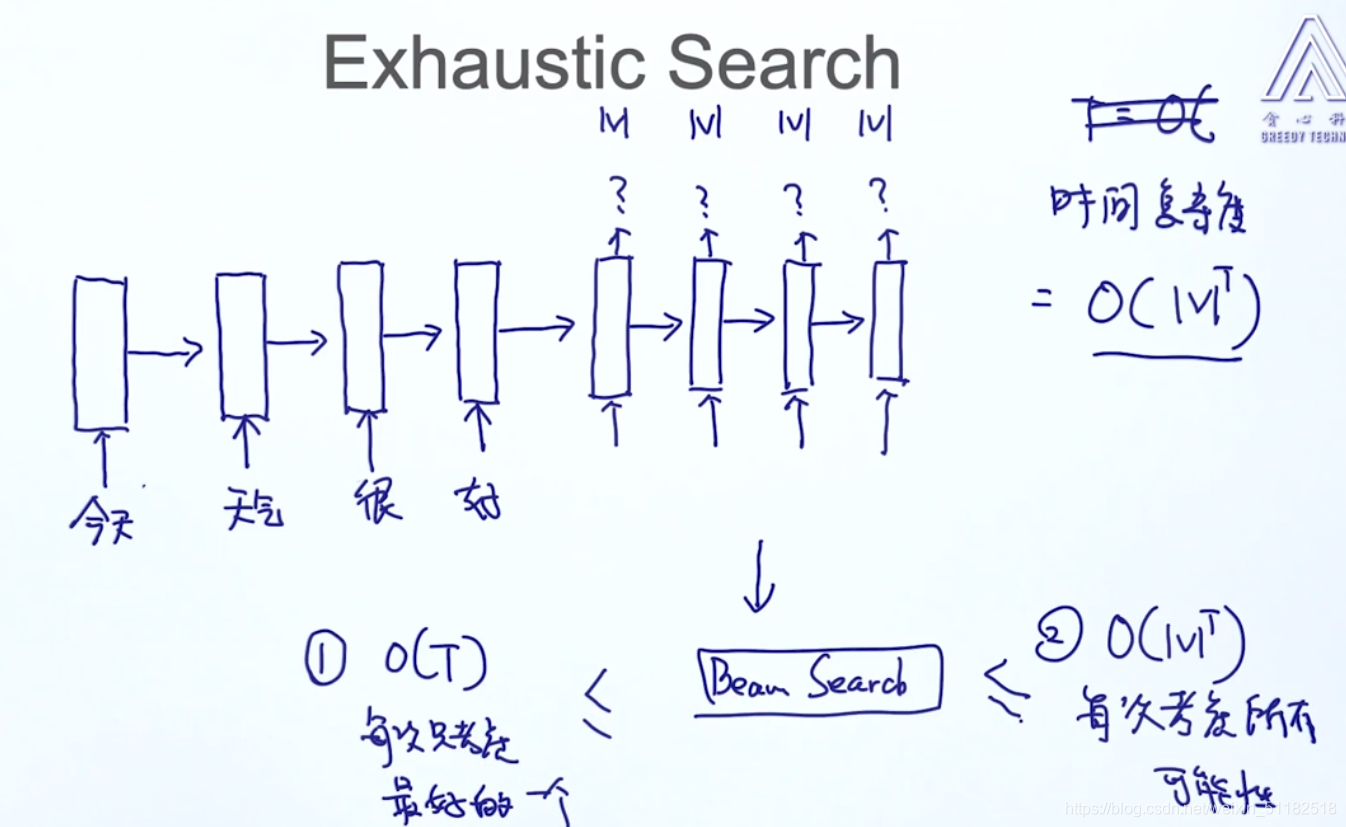
5.5 Beam Search
对于每个时刻,考虑前topk个出现概率最大的单词
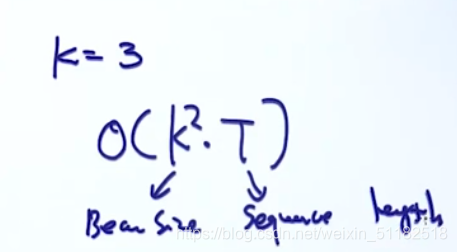
时间复杂度:
O
(
k
2
∗
t
)
O(k^2*t)
O(k2∗t)
- k:前k个
- t:要输出多少个时刻的单词,sequence length
总会倾向于选择长度最小的路径
使用平均的方法,对于logp的和除以它走过节点的长度
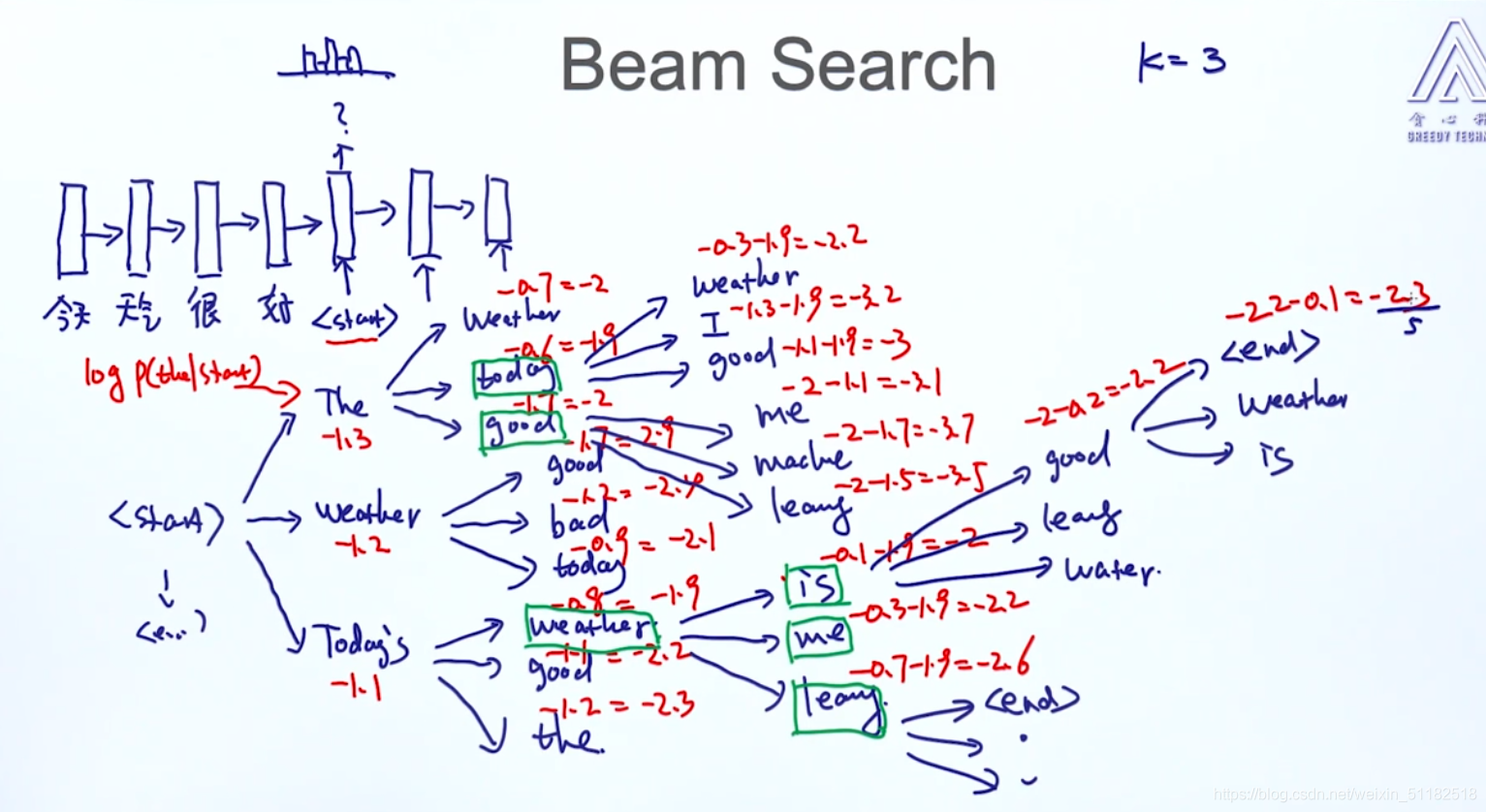
或者使用viterbi算法
6、Attention 注意力机制
- Attention for Image Captioning
- Attention for Machine Translation
- Self-Attention
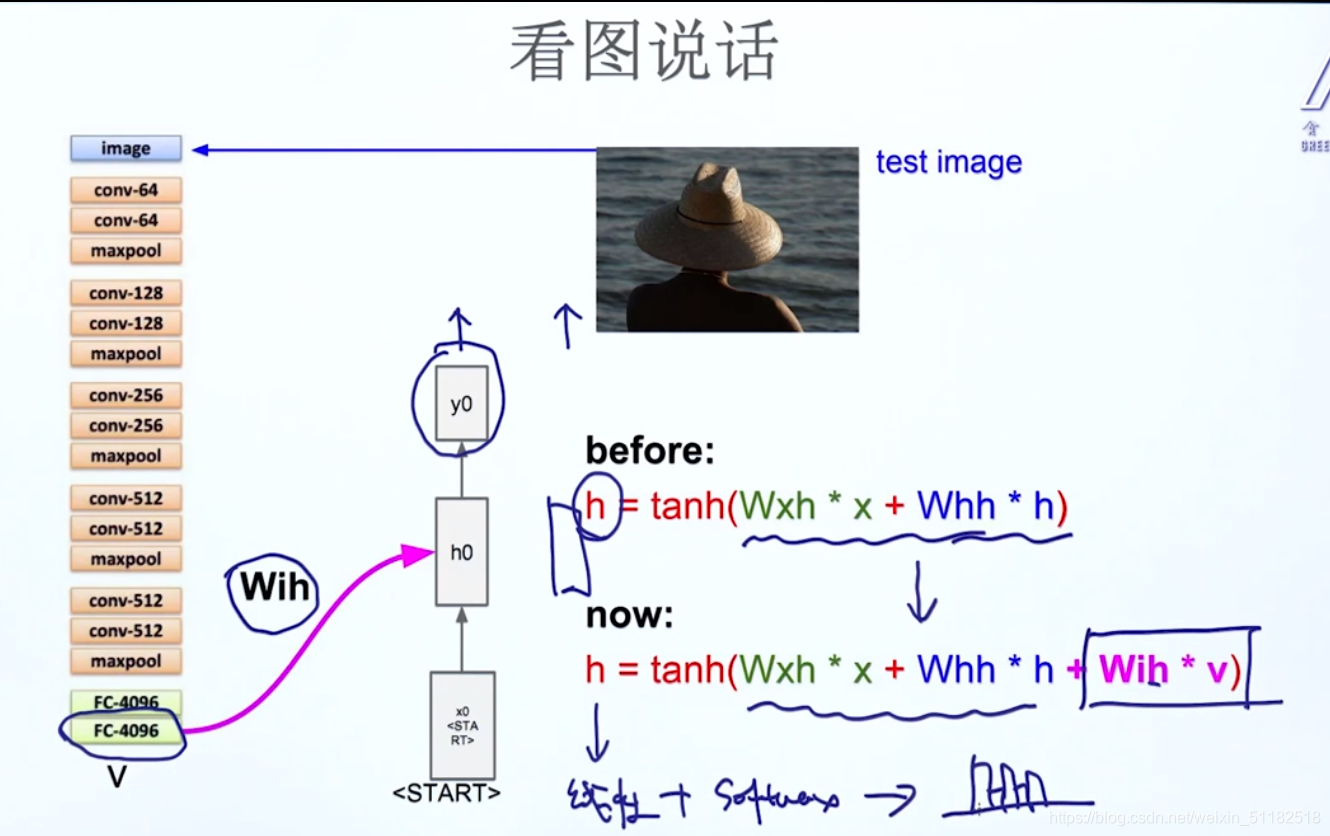
7、案例01 看图说话
对于使用CNN部分,输入图片,去掉CNN最后的softmax层,保留倒数第二层(FC4096)为vector层。
为什么不用倒数第一层?:并不是分类问题,是需要描述图片的特征。最后一层的dense层缺乏泛化能力。
再输入进LSTM模型
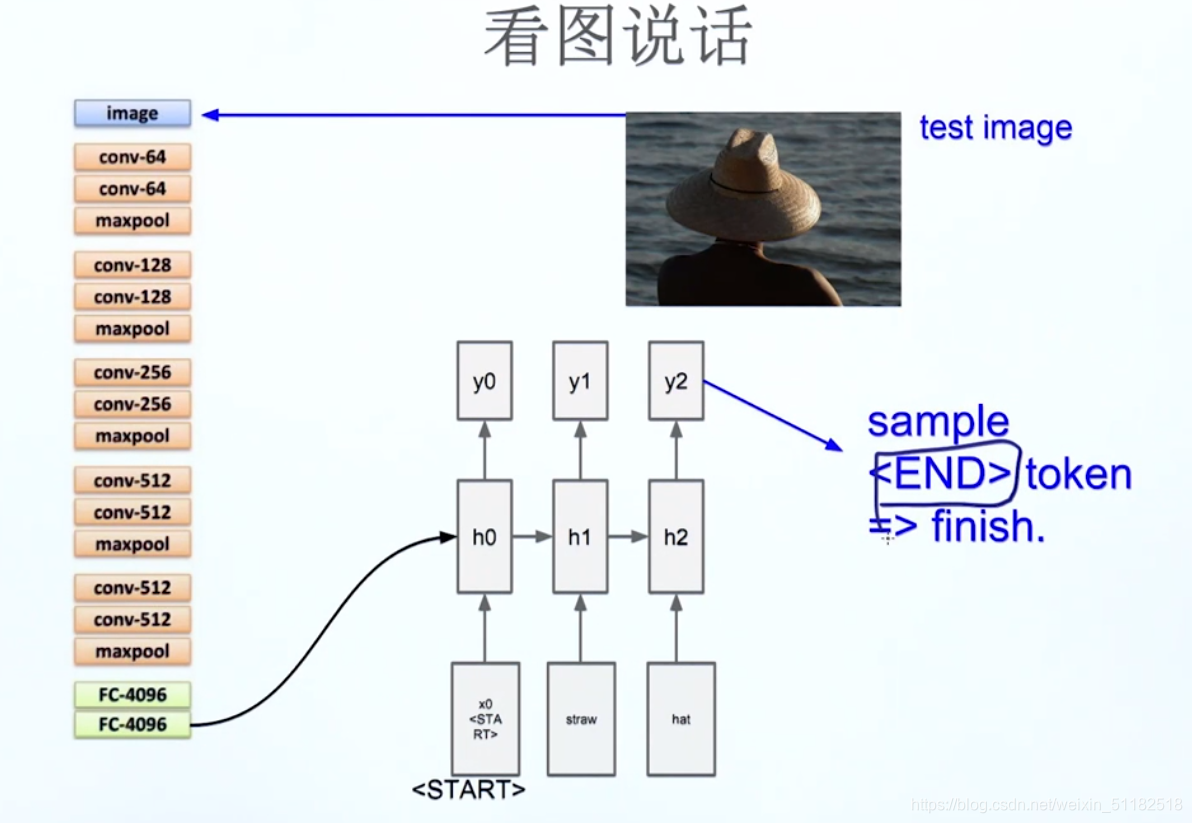
出现 < end > 停止

问题:
- 1、给定图片与输出文本的不相关
- 2、如何判断哪个地方输出的不对,debug
- 3、Bottle neck problem,对于某个时刻的输入产生的文本,不需要了解到vector所有的信息
看图说话的attention 机制

可以把重要的信息看的更清楚
通过找到最大的weight,来定义每个时刻的attention应该放在哪里

z:带表生成第一个单词时需要关注的信息
生成第一个单词
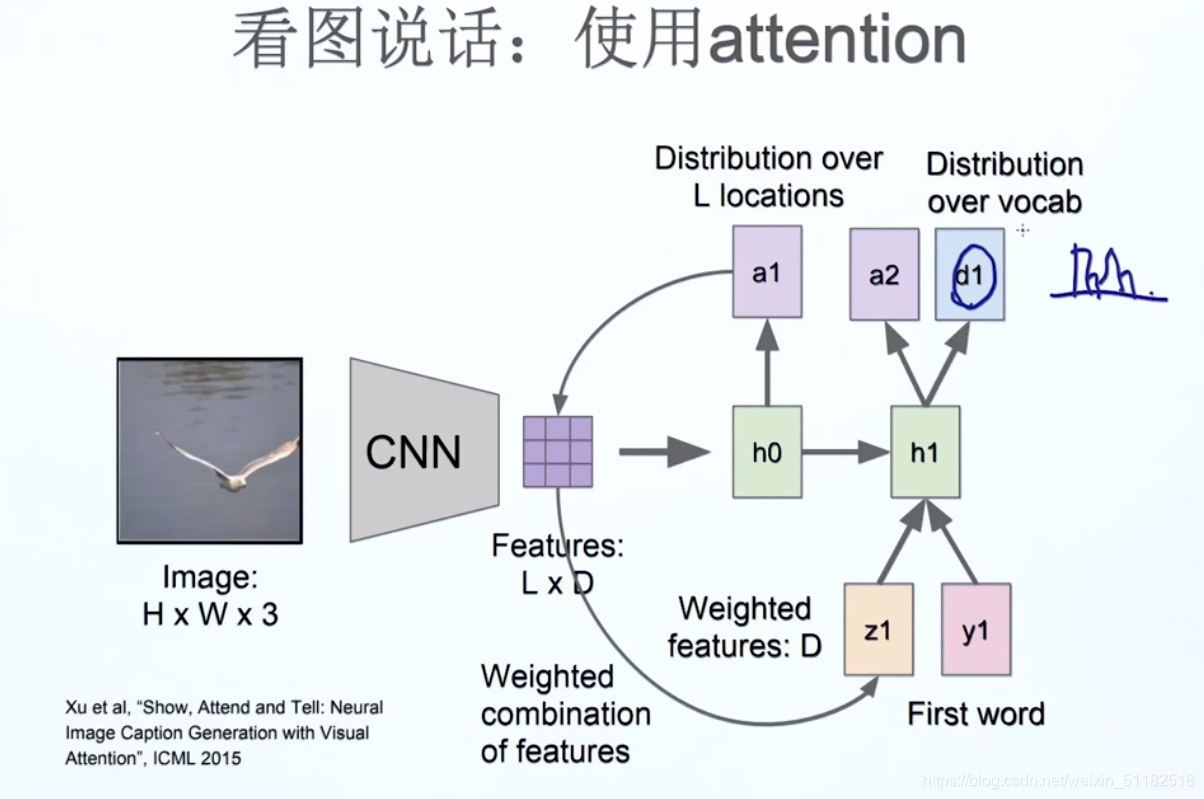
- d i : d_i: di:每个时刻输入后,输出单词的分布
- a i + 1 a_{i+1} ai+1每个时刻输入后,对于该时刻输入来说,图像每个位置点对于生成当前概率分布有贡献的概率。将z乘以本身的图像features map,得到weighted features,z越大的图像点,对于当前时刻的输入来说,贡献的比例越大。
8、seqGAN
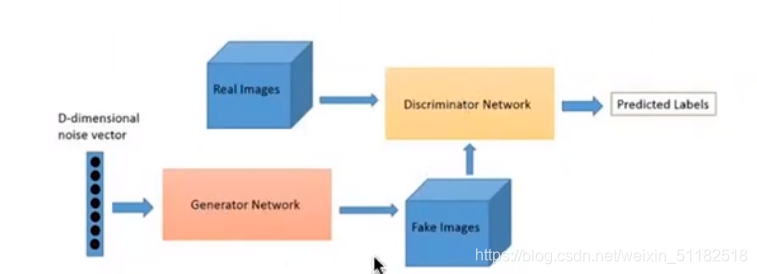
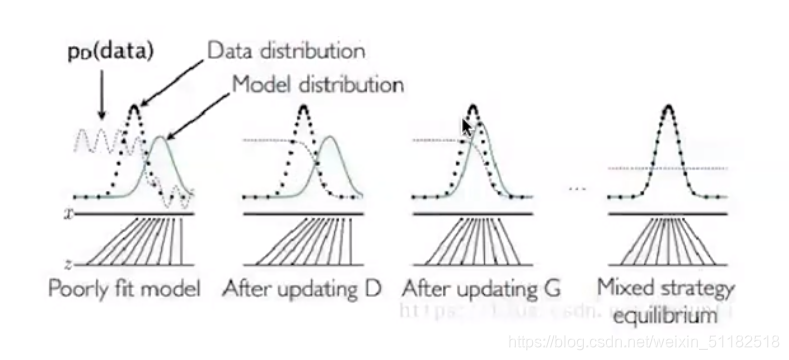
8.1 GAN
8.2 强化学习
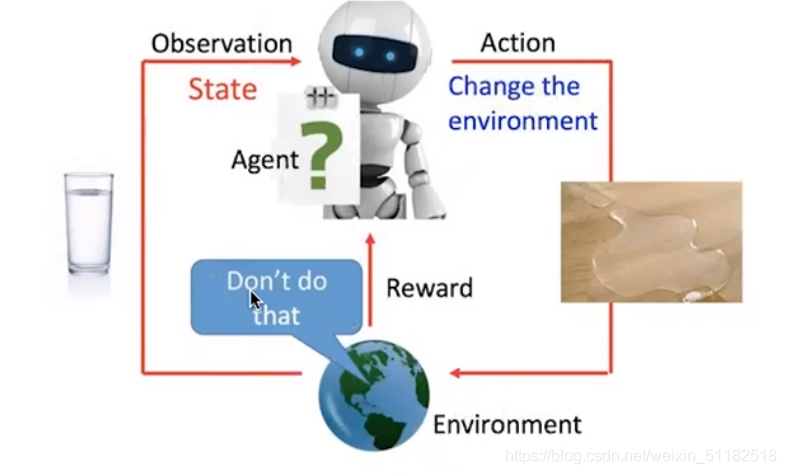
agent根据观察到的环境,作出一定的action,action作用于环境,得到新的观察,且对于agent的action给定一个reward。reward大的代表action正确,reward=0代表action是不对的。通过多次交互,agent学习去做出那些可以让reward最大化的actions
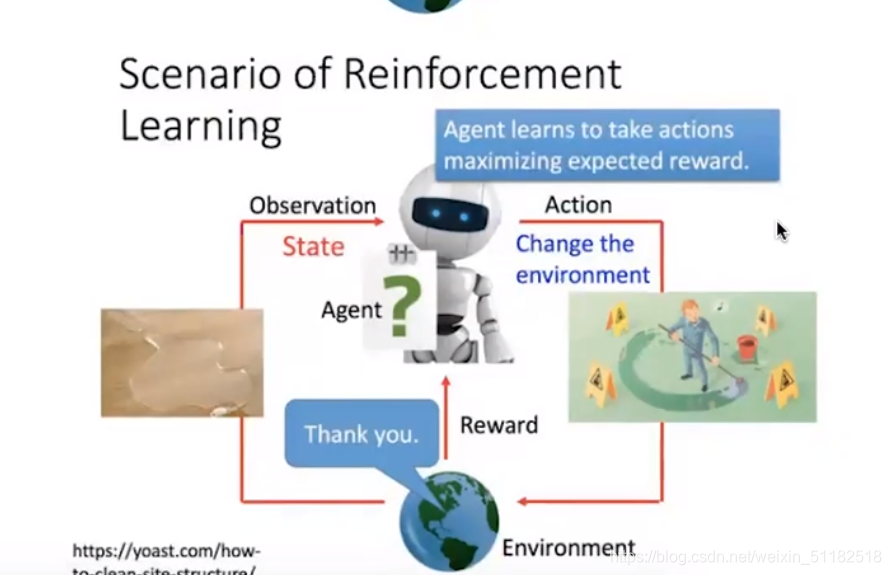
与深度学习的区别:
unsupervised learning,根据reward给与反馈。基于agent和环境的交互,不断学习。
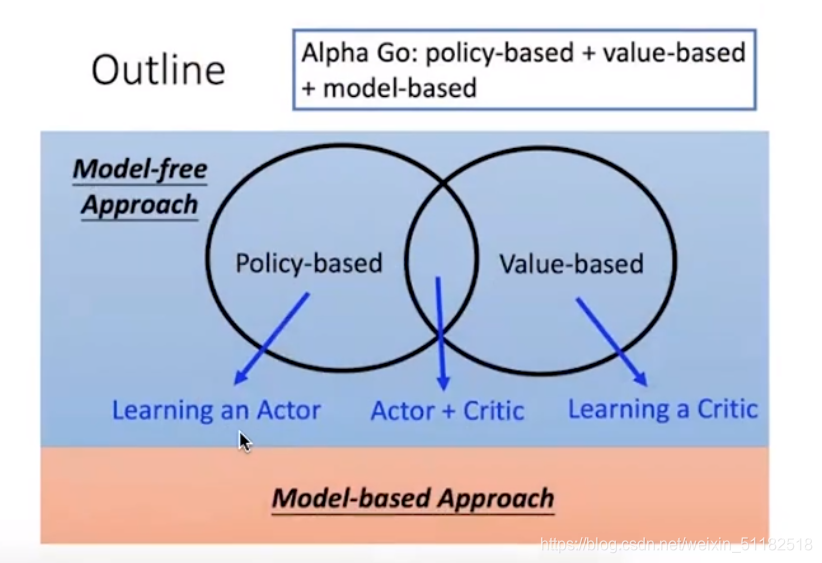
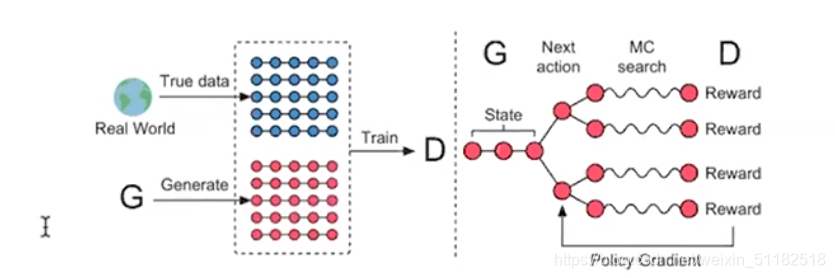
8.3 SeqGAN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









