




双链表的不同结构
1.双向无头不循环链表

2.双向无头循环链表
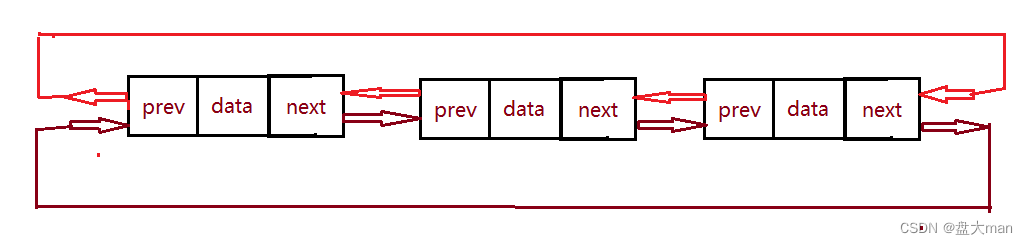
3.双向有头不循环链表

4.双向有头循环链表

双向链表和单向链表的区别
存储空间方面:双链表比单链表多一个prev指针,故双链表的存储空间要比单链表大。
在处理时间方面:在插入删除方面,双链表的处理时间要比单链表短。双链表每个结点都记录着前一个结点和后一个结点的地址,单链表在插入的时候,需要再遍历一遍找到前一个结点的地址,或者用双指针记录前结点的地址,而双链表一个prev就搞定了。
提问:为什么市面上单链表的应用比双链表多?
原因:在插入删除和查找方面,双链表更优,在内存分配方面,单链表更优。双链表比单链表多一个指针,长度为n的话就要多n*len字节(32位,len为4,64位,len为8),在一些对时间效率要求不高的应用场景下,通常会选择以时间换空间的做法,即选择单链表。
双向有头循环链表的增删改查
创建和初始化结点
思路:初始化双向有头循环链表,要把next,prev都指向head
//双链表的初始化
DList* DListinit()
{
//创建头节点
DList* phead = (DList*)malloc(sizeof(DList));
assert(phead);
//next为下一个结点的地址,prev为前一个结点的地址
//循环链表中,头结点的前一个结点和后一个结点都是自己
phead->next = phead;
phead->prev = phead;
return phead;
}
增加结点
思路:注意插入时,链接断开的顺序,清楚next和prev的指向
//双链表的尾插
void DListpushback(DList* phead, Datatype x)
{
assert(phead);
//用tail记录尾结点地址
DList* tail = phead->prev;
DList* newnode = (DList*)malloc(sizeof(DList));
assert(newnode);
newnode->data = x;
//将尾结点的next指向新结点
tail->next = newnode;
//将新结点prev指向尾结点
newnode->prev = tail;
//将新结点next指向头结点
newnode->next = phead;
//再将头结点prev指向新结点
phead->prev = newnode;
}
//头插
void DListpushfront(DList* phead, Datatype x)
{
assert(phead);
DList* cur = phead->next;
DList* newnode = (DList*)malloc(sizeof(DList));
assert(newnode);
newnode->data = x;
//判断链表中是否只有一个头结点
if (cur == phead)
{
phead->next = newnode;
phead->prev = newnode;
newnode->next = phead;
newnode->prev = phead;
}
else
{
cur->prev = newnode;
newnode->next = cur;
newnode->prev = phead;
phead->next = newnode;
}
}
//在pos位置前面插入
void DListpushposfront(DList* pos, Datatype x)
{
assert(pos);
DList* newnode = (DList*)malloc(sizeof(DList));
assert(newnode);
newnode->data = x;
//pos->prev为前一个结点的地址,后面再加个->next,表示将前结点的next指向新结点
pos->prev->next = newnode;
newnode->prev = pos->prev;
newnode->next = pos;
pos->prev = newnode;
}
删除结点
思路:头删和尾删时,需注意头结点的指向问题。
//双链表的尾删
void DListdelback(DList* phead)
{
assert(phead);
assert(phead->next != phead);
DList* tail = phead->prev;
//tailprev为尾结点的前一个结点
DList* tailprev = tail->prev;
//释放尾结点
free(tail);
//将前结点的next指向头结点
tailprev->next = phead;
//头结点的prev指向tailprev
phead->prev = tailprev;
}
//头删
void DListdelfront(DList* phead)
{
assert(phead);
assert(phead->next);
//head为第一个记录数据的结点
DList* head = phead->next;
phead->next = head->next;
head->next->prev = phead;
free(head);
}
//删除指定位置pos的值
void DListdelpos(DList*phead,DList* pos)
{
assert(pos);
assert(phead);
assert(phead->next);
DList* post = pos;
//将pos位置的前结点和后结点链接起来
post->prev->next = post->next;
post->next->prev = post->prev;
free(post);
}
修改结点
思路:
//通过查找函数找到需要修改的结点,然后直接对其data修改
DList* pos = DListcheck(plist, 2);
if (pos)
pos->data = 0;
//打印链表
DListprint(plist);
查找和打印结点
思路:根据尾结点的next为头结点的特性,遍历打印链表。
//查找
DList* DListcheck(DList* phead,Datatype x)
{
assert(phead);
//需要对头结点的next断言,查找结点时,链表不能为空
assert(phead->next);
DList* cur = phead->next;
//遍历条件设置为!=phead,防止进入链表循环
while (cur!=phead)
{
if (cur->data == x)
return cur;
else
cur = cur->next;
}
return NULL;
}
//打印双链表
void DListprint(DList* phead)
{
DList* cur = phead->next;
while (cur!=phead)
{
printf("%d ",cur->data);
cur = cur->next;
}
printf("NULL\n");
}
总结
双链表在增删改查方面比单链表方便很多,但在存储空间方面,单链表是比双链表更优的,根据场景不同,两种链表都能发挥出其优点。在学习链表方面,还是要注意区分头指针和头结点!

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







