







其他章节笔记:
(一)操作系统的启动
(二)系统调用
(三)操作系统历史
(四)多进程管理图像
(五)进程,用户级线程与内核级线程
(六)进程同步与信号量
(七)内存管理
内存管理
程序重定位
计算机在执行指令序列时,把程序从磁盘读入内存,用PC指针指向指令序列,依次执行。这就涉及到逻辑地址与物理地址匹配的问题。比如这样一段代码:
0 .text
8 entry:
... call 40;
... ...
40 main:
...
main()函数的地址是0x40,要调用main函数,就要把PC指针指向0x40.但是在实际工作中,很难正好申请到0x0-0x40的空间去存放指令序列,可能申请到0x1000,这时候main函数的地址应该是0x1040,而PC指针还指向0x40,调用函数出错。
解决的方法就是程序重定位,即将程序中的逻辑地址对应到实际使用的物理内存地址。
程序重定位的时间有三种选择:
- 编译时重定位:编译产生可执行代码时,将程序中所有逻辑地址加上基址再写入可执行文件中。缺点是载入内存地址固定。
- 载入时重定位:更灵活。在内存中寻找一块空地,找到了再把程序中所有逻辑地址改为物理地址。但是一旦载入到物理地址中,就不能移动了。
比如多个进程并发时,因为内存资源宝贵,有时候不能让所有程序都在内存中,而是要动态的从磁盘和内存换入换出。进程1第一次换进来在某位置,第二次换进来时就不一定在原位置了,所以这个方法也有一定局限性。 - 运行时重定位:最好的方法。在程序运行时进行重定位,即每执行一条指令,都将指令中的逻辑地址加上基址后才放在地址总线上。
为了提高执行效率,逻辑地址->物理地址由硬件完成翻译,这个硬件就是存储管理部件(MMU).而每个进程的基址不一样,MMU进行重定位的CPU寄存器只能有一个。联系前面进程切换的知识,每个进程的重定位基址都存放在PCB中,进程切换时将其PCB中存放的基址取出来赋给这个CPU的寄存器,即可解决这个问题。
之前说到进程切换时,要完成内存地址的切换,实际上指的就是这里的重定位基址切换。至此,进程切换的两个部分,指令执行序列的切换和地址空间的切换都有了。
分段
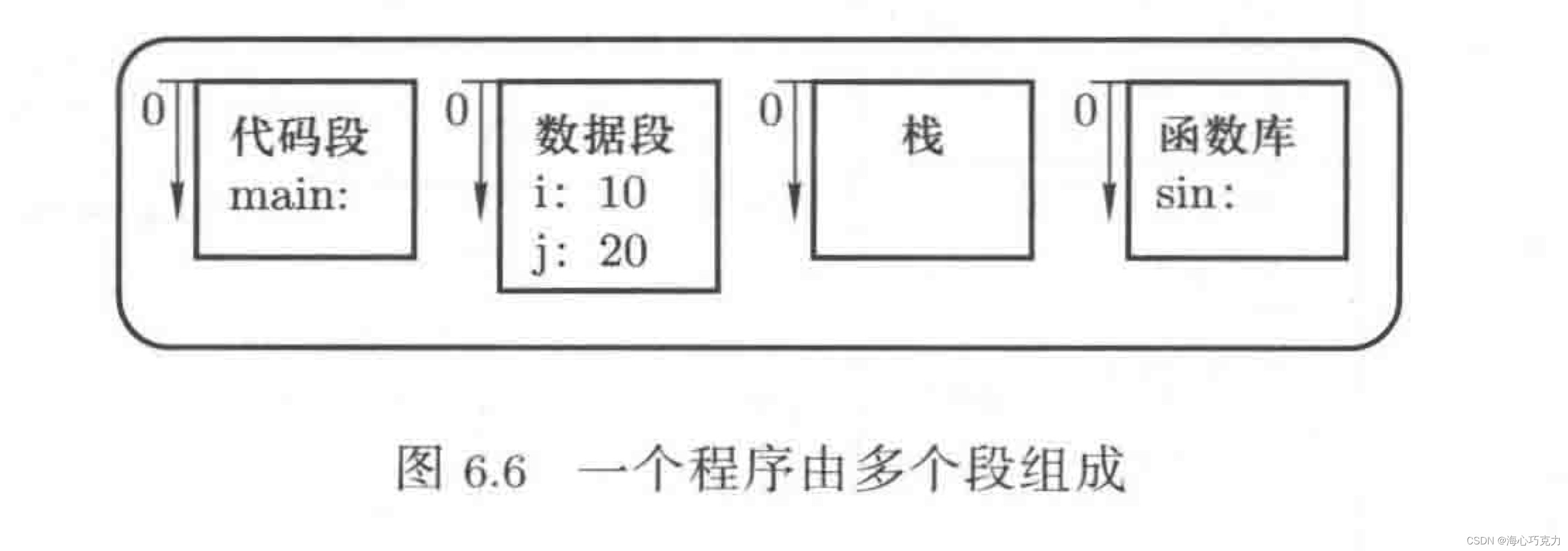
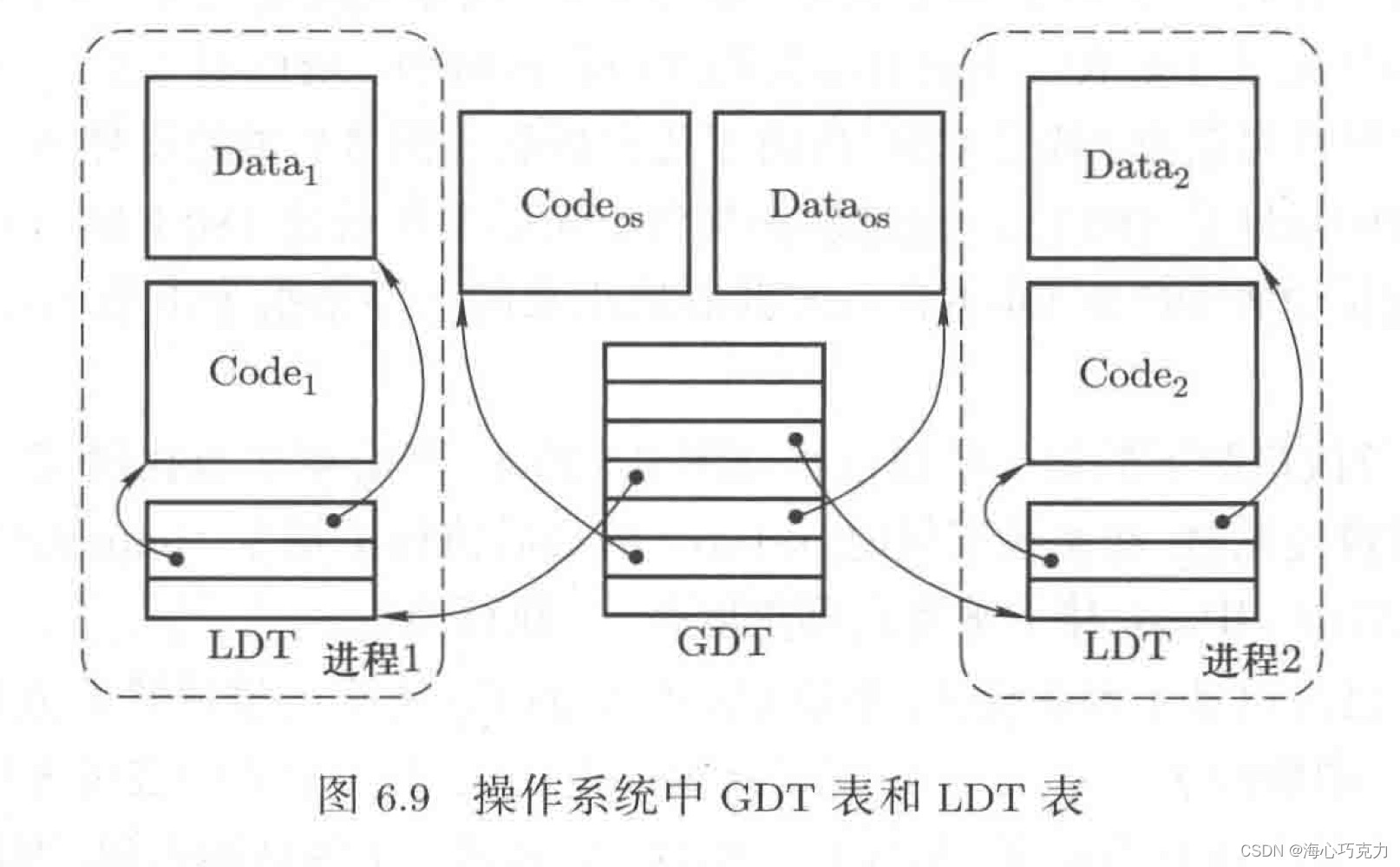
一般来说,一个程序会有好几个段,行使不同的职责,有不同的权限,于是分开管理。程序分段后,可以不作为一个整体存入内存,这样也可以有效利用内存中的零散空间。分段存入内存后,就需要记录不同段的基址,段表就这样产生了。段表(IDT)实现的机制和之前的GDT表是一样的,CS是段地址,IP是偏移地址,运行时通过CS查段表,得出段基址,加上IP得出物理地址。
IDT:local data table,每个进程拥有自己的段表。 GDT:global data
table,把OS看作一个进程,GDT表就是OS的段表,只有一个。为了让操作系统找到每个进程的段信息,GDT表中还有指向各个进程LDT表的表项。
分区
可变分区与适配算法
如何在内存中找出一个空闲的区域。
考虑维护两个表,一个记录占用了内存的进程,一个记录内存空闲分区。
分配的三种方法:
- 最佳适配:选择能够满足要求且最不浪费的分区。比如一段程序40KB,有空闲区域50KB,150KB,选择50KB,此时“浪费”10KB.而这样做会使内存空间越来越碎,分配给其他程序的可能会越来越小,这样会造成利用率不足。
- 最差适配:反过来想,选择能够满足要求且最浪费的分区,即一段程序40KB,有空闲区域50KB,150KB,选择150KB.会导致出现许多中等大小的空闲内存区域。
- 最先适配:操作系统的内存请求没有规律,有大有小,此时没有必要用最佳适配来制造内存很大的分区,也没有必要用最差适配来制造内存中等的空闲区域。可以在空闲区域表中选择最先满足条件的分区,最先适配算法执行起来最快。
内存碎片
接上例,有空闲内存区域150KB,50KB,而现在来了一个160KB的程序,虽然内存空间有空余,却无法放入程序。这就是内存碎片,虽然总的空闲内存很大,但是由一堆分散在物理内存多个位置的小区域组成,小区域不能满足进程的段尺寸而无法使用,从而造成空间浪费。
解决的方法:
- 内存紧缩,即通过移动整理将零散空间合成整块的空间。但这种方法的缺点很明显,就是时间长,且移动过程中所有进程不得运行,这给用户的体验是极差的。
- 内存离散化,分隔程序,160 = 150+10,就可以放入内存空间中。为了便于管理,把内存分隔成固定大小的小片,程序也分隔为相同大小的小片,这样就可以解决内存碎片化问题。这个小片作为分页的基本思想。
分页
首先将物理内存分隔成大小相等的页框,再将程序分隔成大小相同的页,最后将所有页都映射到页框上,完成物理内存页框的使用。映射结果如图:
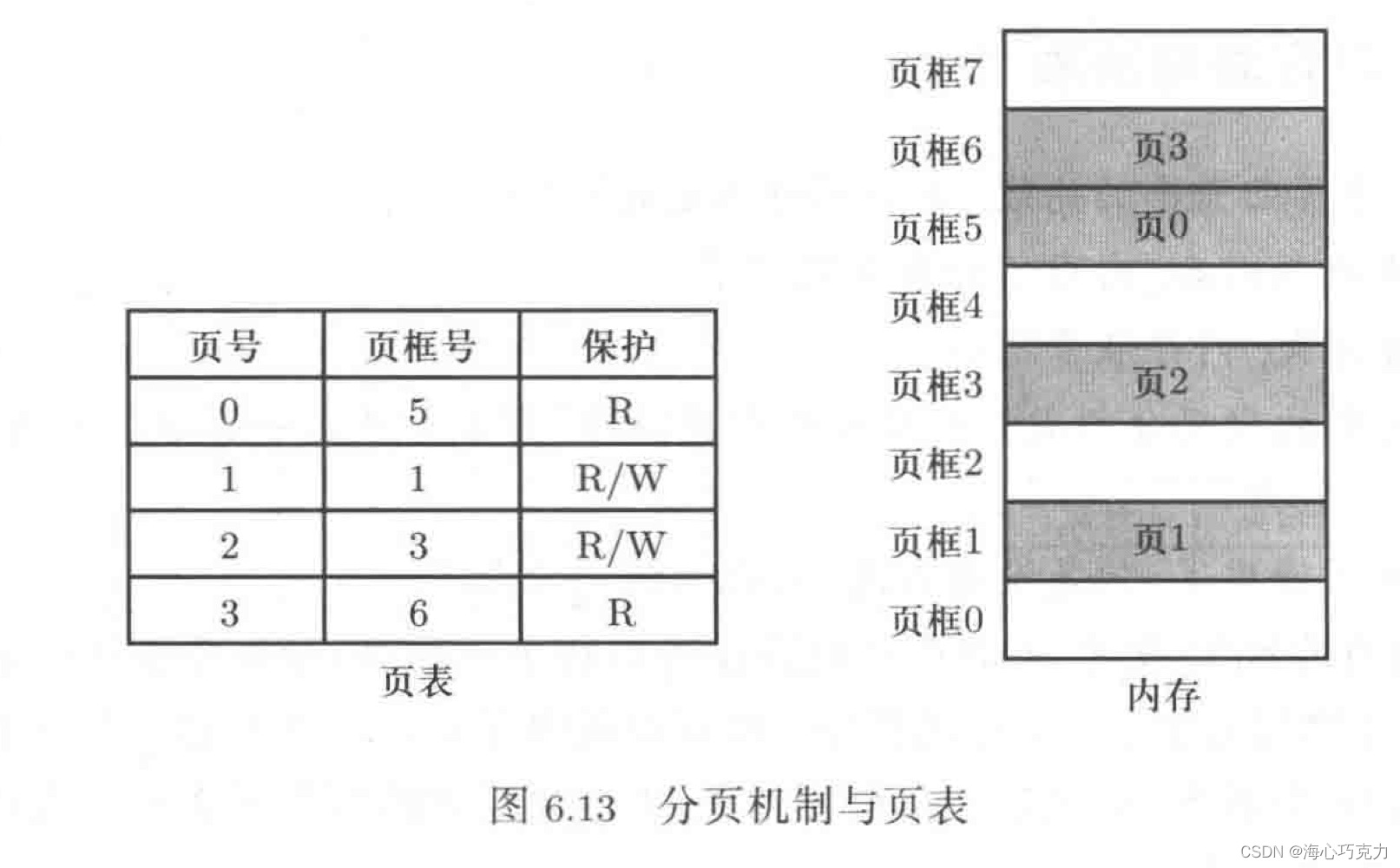
这样完成了载入工作。而运行时,段页表如何结合在一起完成重定位工作呢。
多级页表
为了提高内存空间利用率,使用分页的机制,但是页表所需的存储空间也不小。
在32位系统里,一个进程假装拥有整个CPU的资源,其逻辑地址大小相当于内存大小。比如内存大小4G,要存储逻辑地址与物理地址页号的映射关系,一个进程就有一个4M的页表(一页4K,有4G/4K=220个页表,即一个页表有220个页表项,每个页表项4B,得一个页表大小为4M),一百个进程就有400M大小,400M/4G=10%的占用率,这显然过高,为了解决这个问题,考虑以下几种方法:
- 只存放用到的页。通常情况下,一个进程占用的逻辑地址空间不会是4G这么大,很多逻辑地址空间并没有被使用,所以将没有使用到的逻辑地址空间不写入页表。如下:
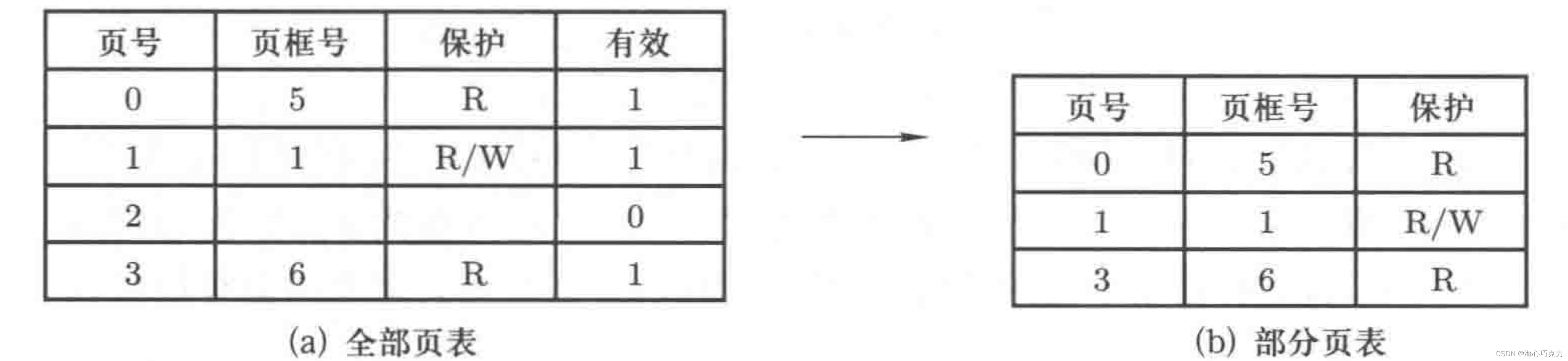
但是消去没有使用的逻辑地址空间会导致页号不连续,查找不方便。原来是一个连续的类似数组的结构,比如访问页号3,直接“0+3”即可,而现在却需要用查找算法查到页号3所在的页表项,这无疑让访问页表的次数大大增加。而页表在内存之中,访问页表意味着访问内存,即每执行一条指令(取值执行),就要访问多次内存,这样会造成时间效率的下降。 - 采用多级页表的结构。不存储没有使用的逻辑地址空间,也解决了不连续页表号带来的查找时间负荷。主要思想是在页表上建立一个高层结构,通常称其为页目录。
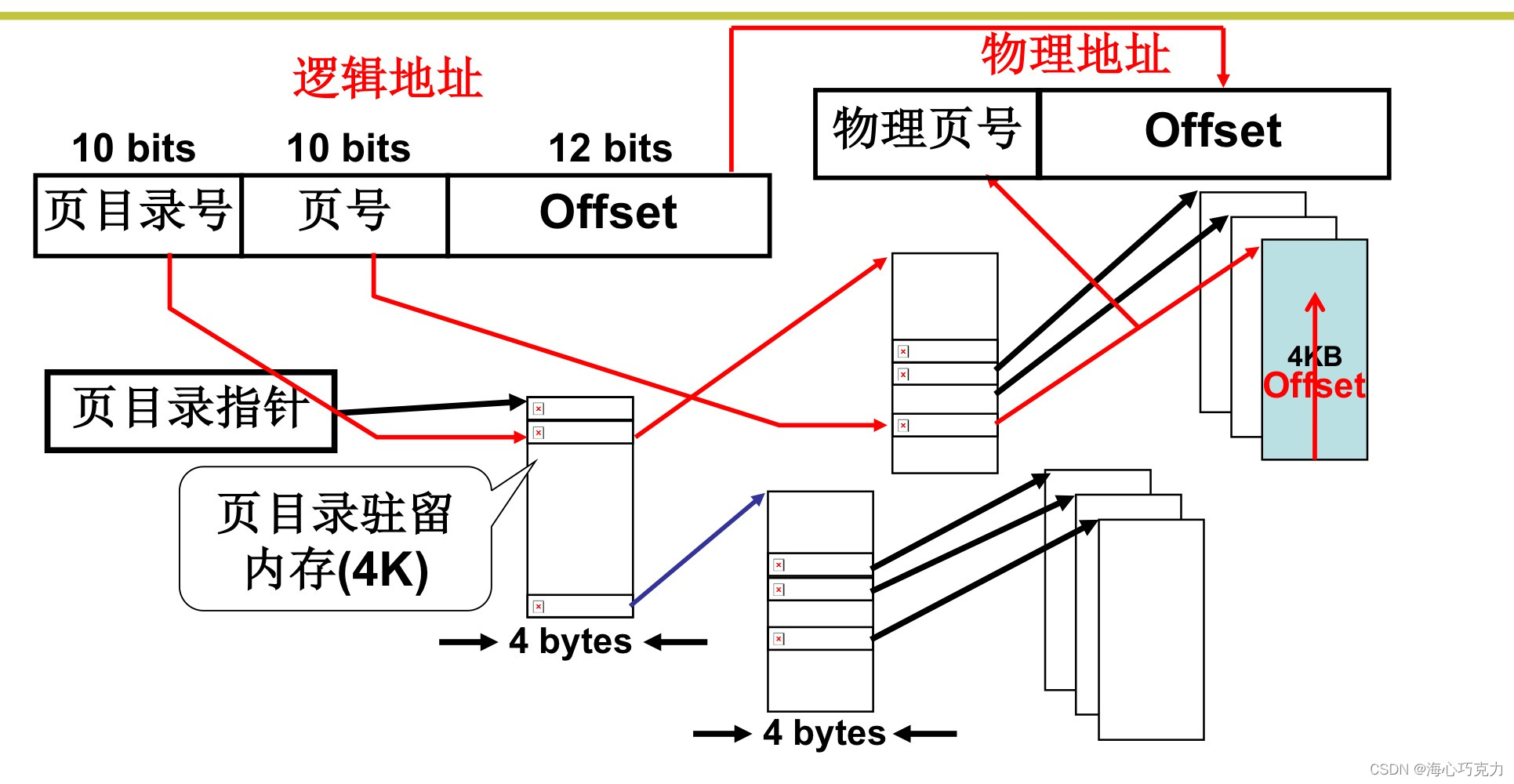
如图,逻辑地址共有32位,一页有4K,所以偏移地址是12位,页地址高十位为页目录号,低十位为页号。该进程使用到了逻辑地址的0 ~ 4K,4K ~ 8K,4G-4K ~ 4G,所以只建立了三个页表,加上页目录表,只使用了16K的内存,比原来的4M少很多。相当于一本书的章节目录横跨整本,但是有些章节是空的,使用到的章节才会有页表。
快表
多级页表意味着要多次查表,虽然比第一个方法时间效率上节省很多,但仍有提升空间。快表就是一个类似于高速缓存的结构,把经常使用的页表项放在快表里,因为快表是借助硬件电路来完成缓存页表的查找的,所以比访问内存查找页表快速得多。
程序执行具有典型的局部性,即因为循环,函数调用等等结构的存在,常常需要反复读取同一页表的内容,所以快表这一结构可以很大加快查找速度,一定程度上弥补了用来换取空间的时间。
此时的地址转换过程就是:先查快表,快表命中即获得物理地址,不命中则查找页目录表,查找页表,找到物理地址并更新快表。
段页结合
从用户的角度来说,希望程序分为多个便于管理的段,从硬件的角度来说,希望把内存分为多个页。所以考虑设置一个中间结构把段页结合在一起,这个中间结构称为虚拟内存。结构如下:
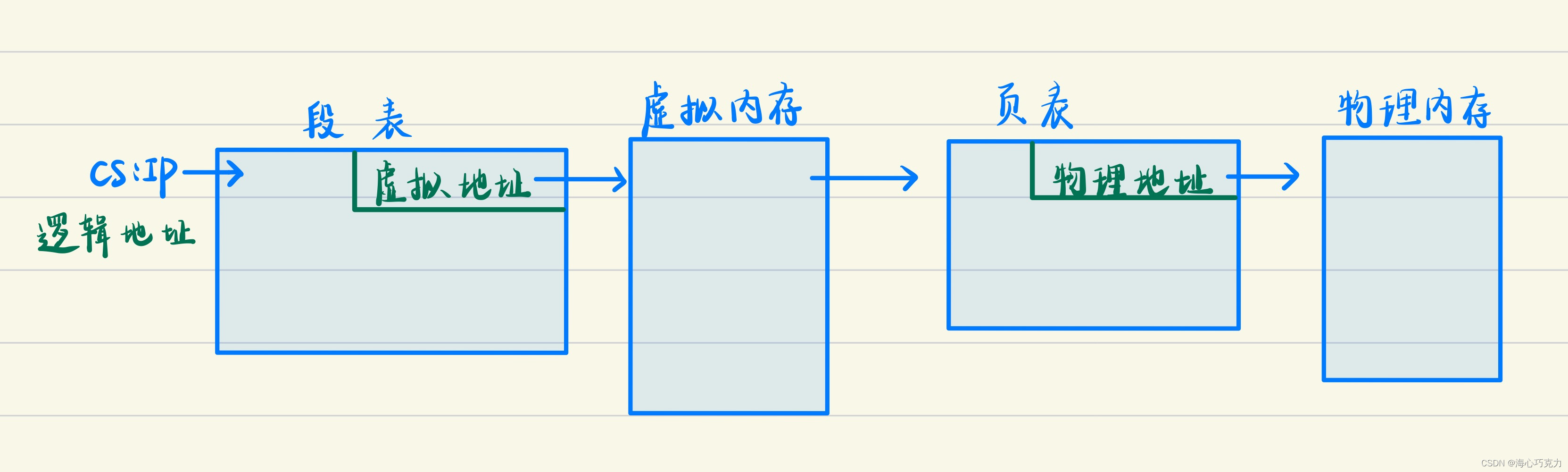
在进行进程内存分配时,步骤是:
- 在虚拟内存中分割出一些分区,将程序的各个段放入。
- 建立段表来记录映射关系。
- 将虚拟内存分割成页,选择物理内存中的空闲页框,将虚拟内存中的“页内容”放到物理页框中。
- 建立页表来记录虚拟内存页和物理内存页框的映射关系。
内存的换入换出
假定虚拟内存有4G,程序运行时需要使用4G的内容,而内存中只有1G,这时就要动态地执行内存的换入换出。
请求调页
在执行进程时,MMU会查看页表项的有效位,如果页表的有效位为0,就说明该虚拟页还没有映射到物理页框上,这时MMU就会向CPU发出缺页中断。操作系统的内存换入就从这个缺页中断开始。
内存换入的核心是在缺少虚拟页的时候请求调页,操作系统实现换入就是实现请求调页。
页面换出
页面换出要解决的基本问题就是选择哪个页面进行淘汰。
(不想写了)

















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









