






要解决的问题
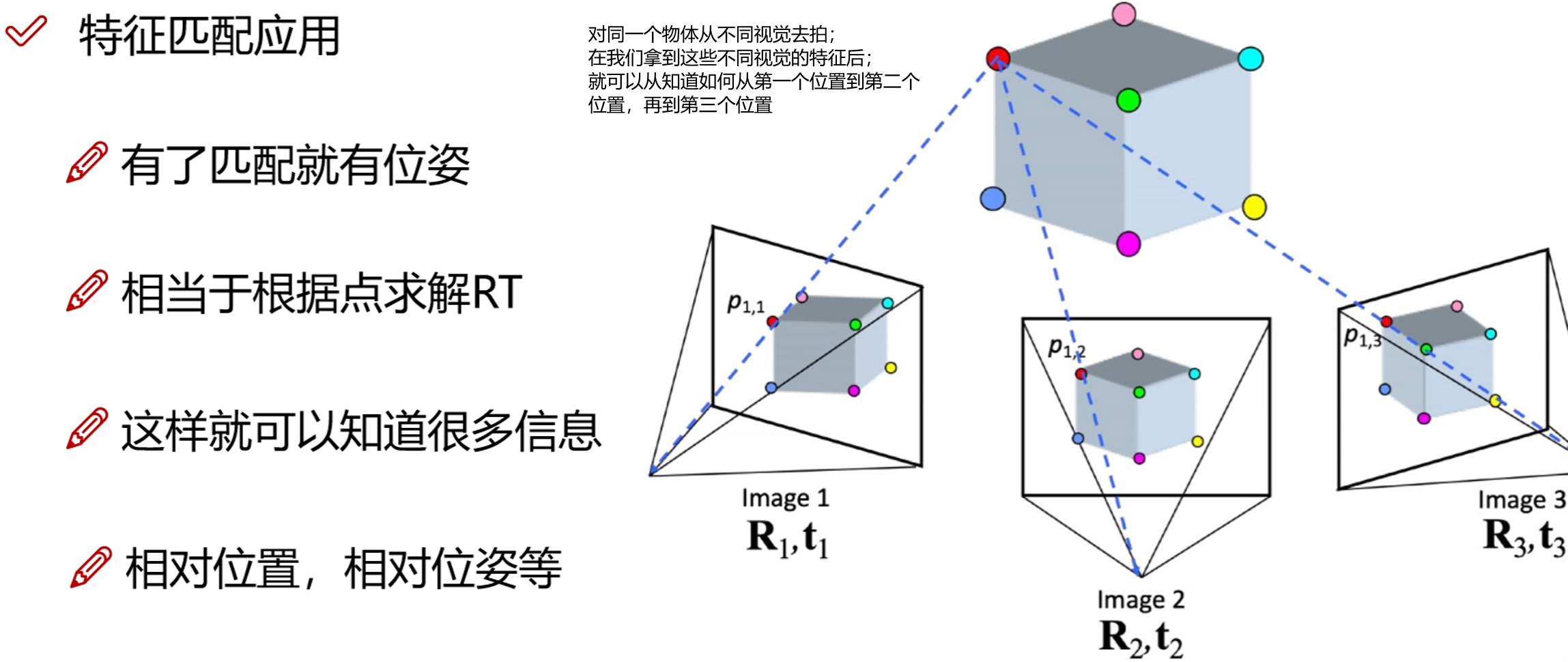
对同一特征点1从不同角度去拍,在我们拿到这些不同视觉的特征后,就可以知道如何从第一个位置到第二个位置,再到第三个位置
对于传统算法

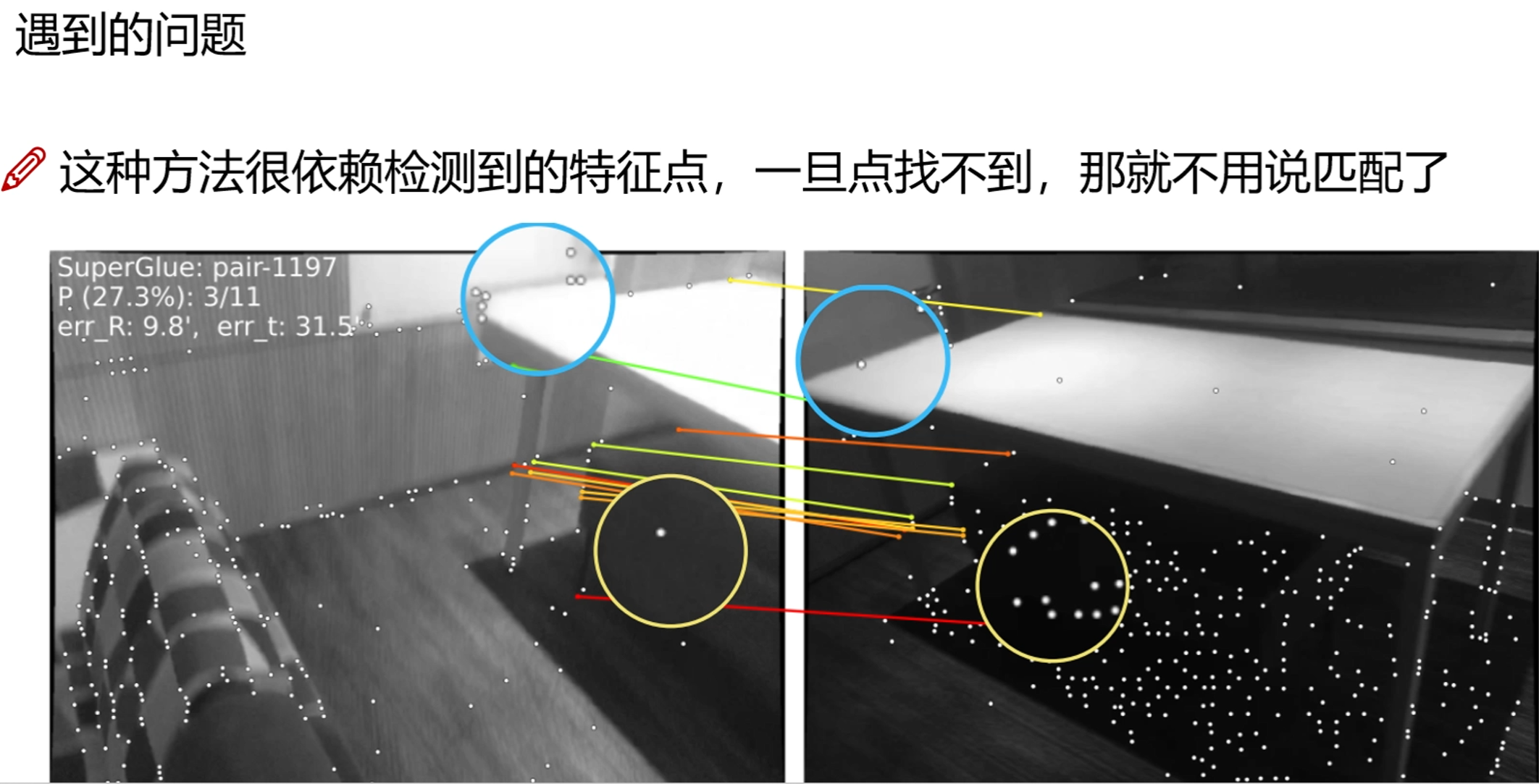
下面很多点检测都是错

loftr当今解决办法
整体流程

具体步骤
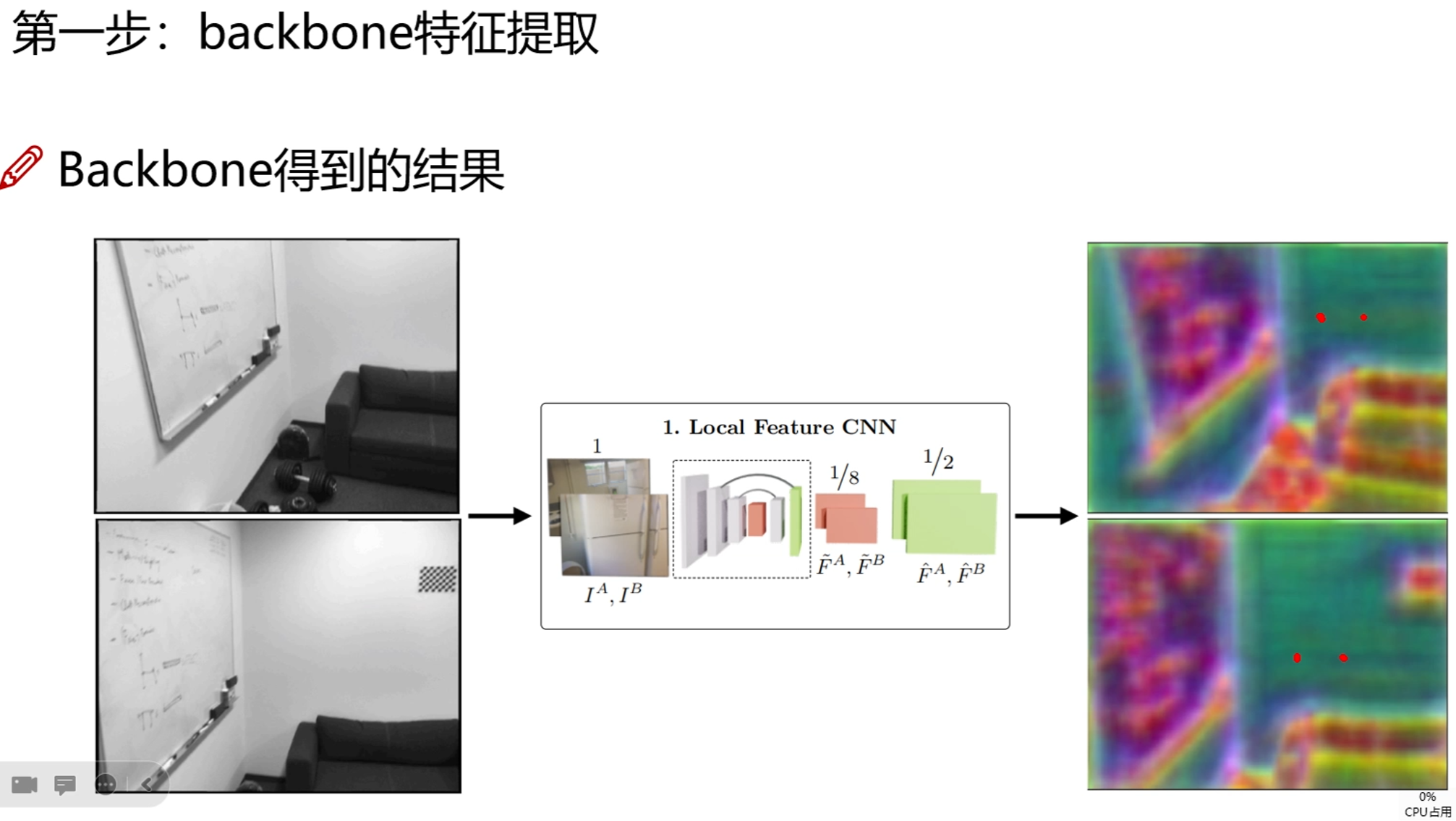
卷积提取特征,一个点代表一个区域
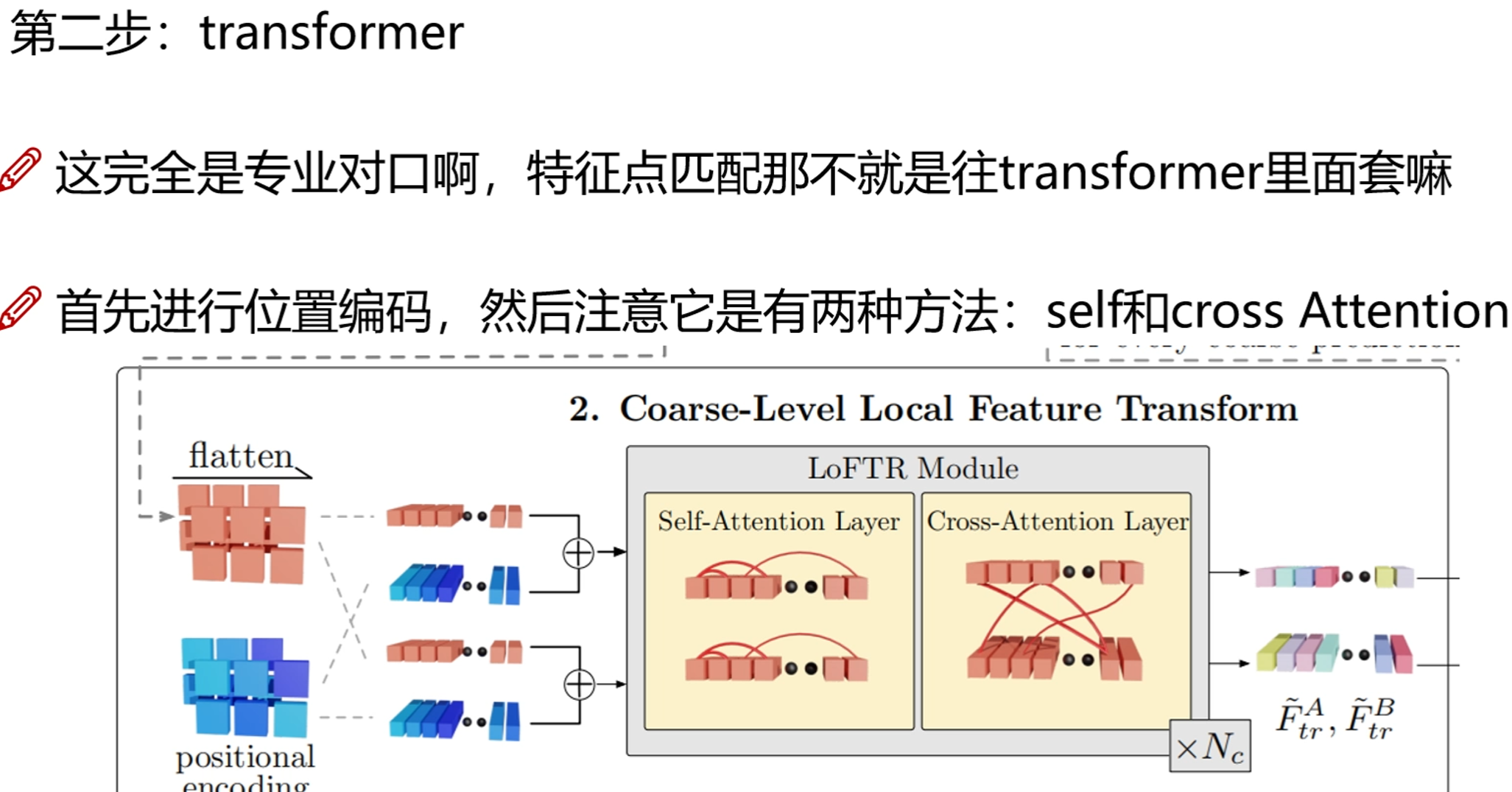
使用transformer

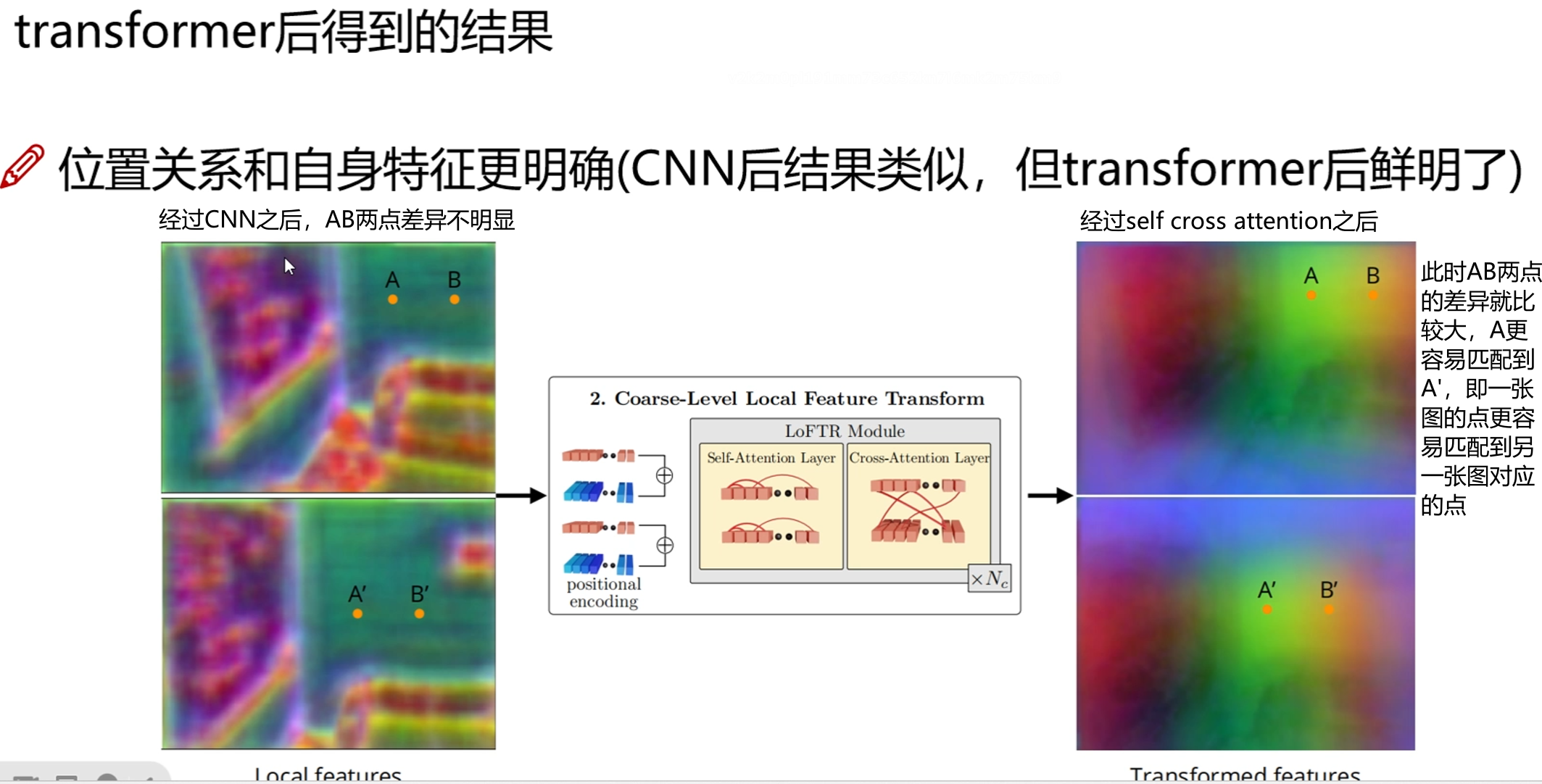
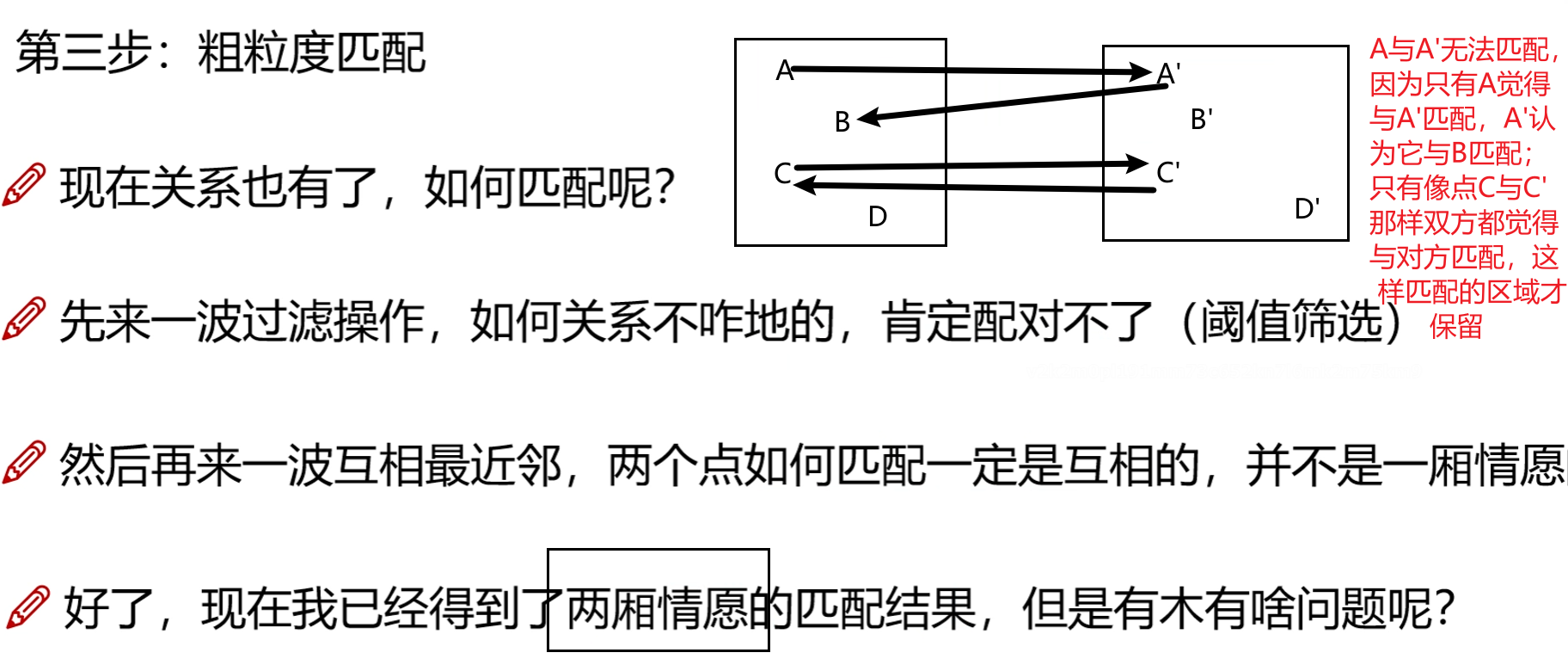
粗粒度匹配
me:这里4800个点应该都是卷积后的点,即代表的是局部区域

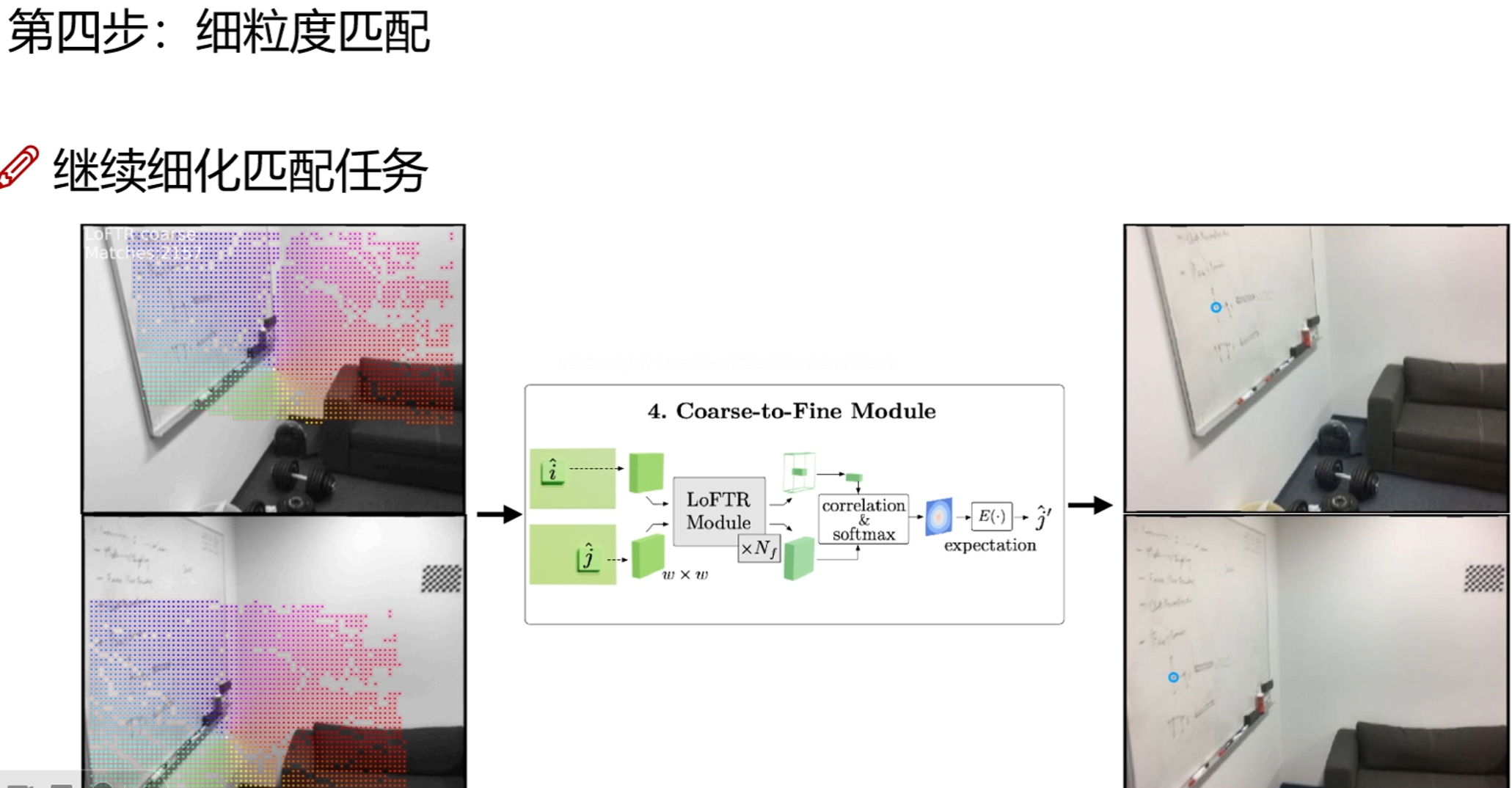
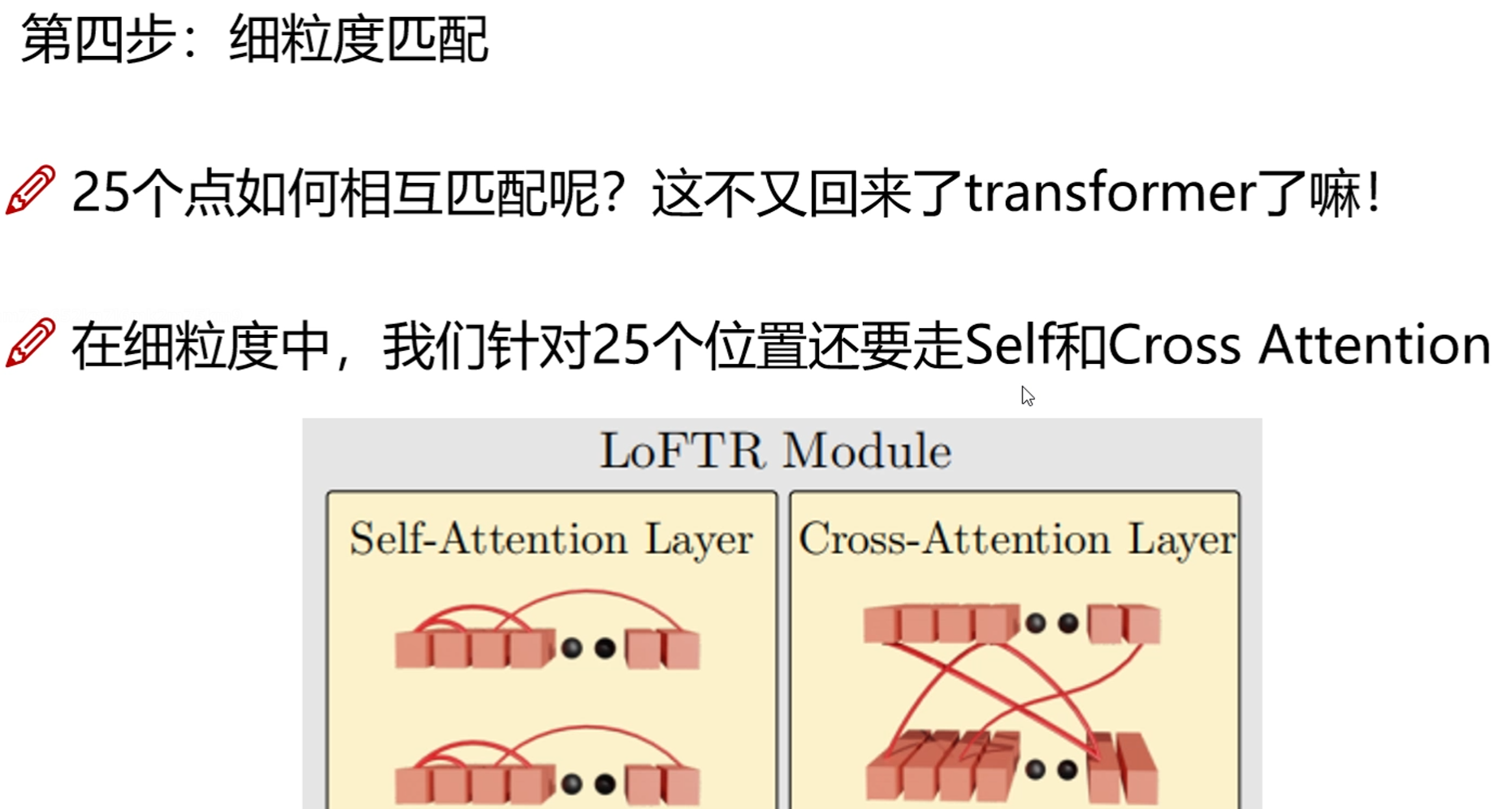
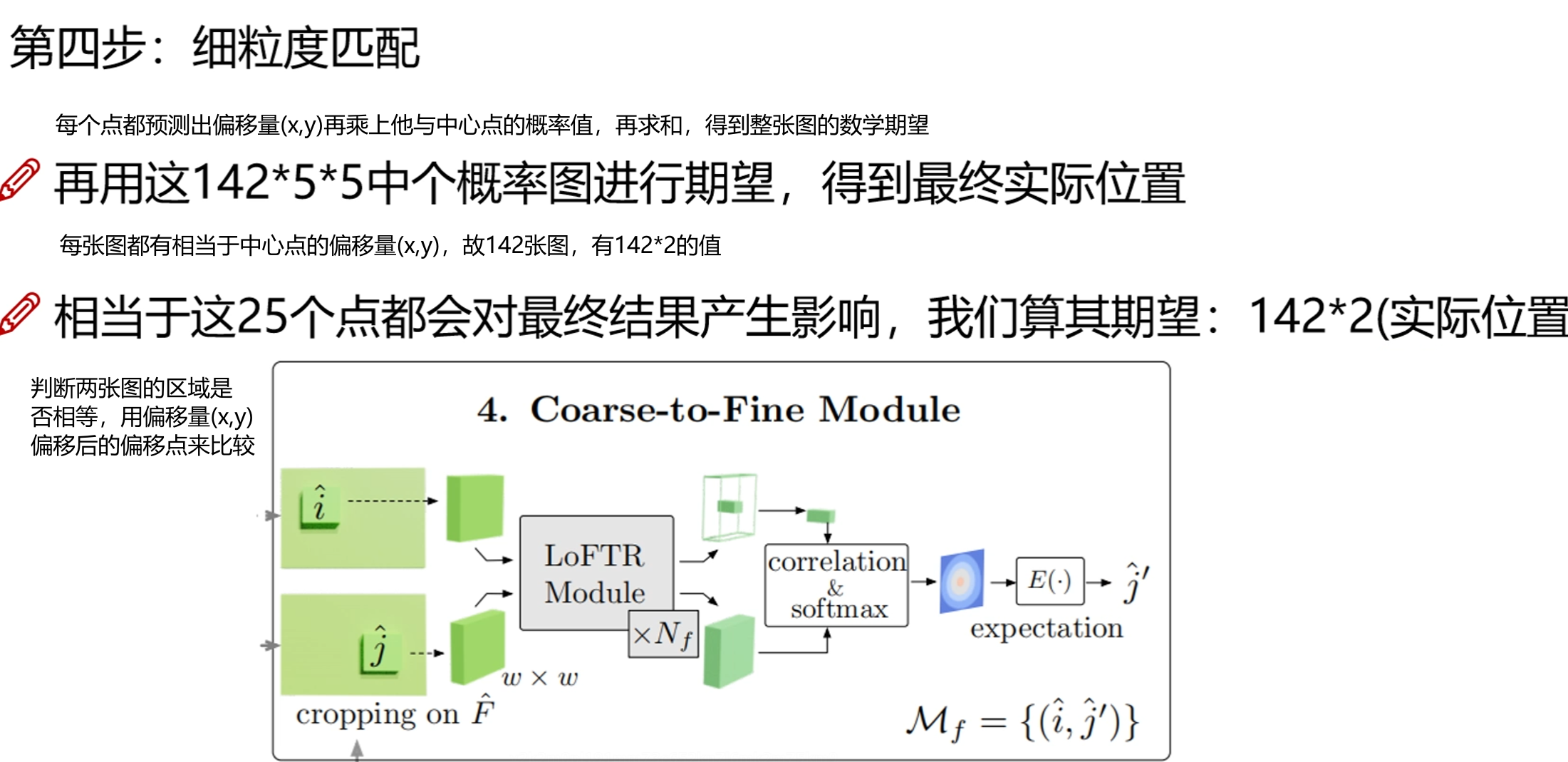
细粒度匹配





对同一特征点1从不同角度去拍,在我们拿到这些不同视觉的特征后,就可以知道如何从第一个位置到第二个位置,再到第三个位置
下面很多点检测都是错
me:这里4800个点应该都是卷积后的点,即代表的是局部区域
 2949
4332
3320
2949
4332
3320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























