






1、sql介绍
结构化的查询语言,关系型数据库中通用的一类语言
Sql标准 89 92 99 03
Mysql
2、Sql类型
(1) Mysql自带的功能
客户端命令
Mysql> Help #查看所有mysql自带的命名
(2)server端命令分类
Mysql > help contents
面试:列举sql的种类
DDL: 数据定义语言
DCL: 数据控制语言
DML: 数据操作语言
DQL: 数据查询语言
3、Sql的各种名词
(1)sql_mode SQL模式
作用:规范sql语句执行的语法
比如说:在现实的数学角度,除法运算中,除数不能为0
在mysql中需要做除法运算时,为了保证符合现实的数学逻辑,也需要保证除数不能为0,所有mysql通过设点sql_mode 参数,规范我们除法运算
(2)字符集(charset)及校对规则(collation)
字符集:mysql> show charset;
Utf8 :最大存储最多3个字节
Utf8mb4(建议使用):最大存储最多4个字节
差别: Utf8mb4支持的编码比utf8更多
比如: emoji字符mb4中文支持,utf8不支持。Emoji表情字符。1个字符占4个字节,utf8存不下
5.7默认是latinl,不支持存中文
查询创建库的逻辑:
mysql> show create database 库名;
校对规则(collation):
每种字符集,有多种校对规则(排序规则)
Show collation;
作用:
影响到库和表排序的操作。简单来说就是大小写是否敏感
按照ASllc来排序,就是表和库的名称就是按照这个规则来排序
(3)数据类型
Mysql数据类型分为数字、时间、字符串
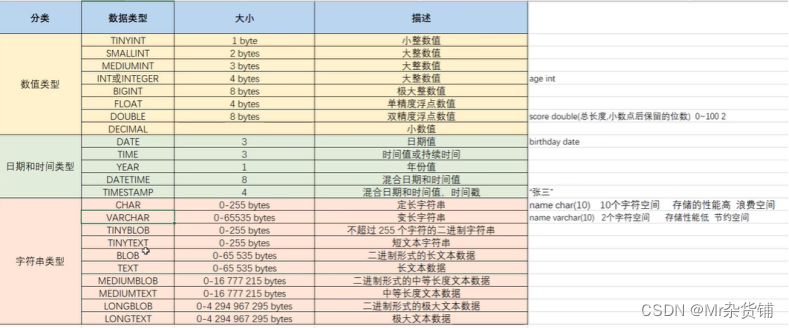 A、数字
A、数字
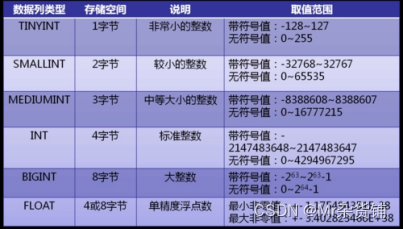
B:字符串类型
Char(长度):定义字符串类型 255字符
Varchar(长度):变长字符类型 65535 字符
Enum(‘bj’,’sh’); 枚举类型
当我们存储的是规定的名称时如省份,则用enum,当我们存储数据时只需要将枚举对应名称的索引存入,这样可以节约空间
例如:
char(10) : 最多存10个字符,如果存储的字符不够10个,自动用空格填满,对于磁盘都会占用10个
Varchar(10): 最多存10个,按需分配存储空间,存储5个就占5个空间
补充:
varchar类型, 在存储数据时,会先判断字符长度,然后合理分配存储空间
而char类型,不会判断,立即分配空间。
在固定长度的列中,还是推荐选择char类型。
Varchar在存储时,还会使用1-2个字节空间存储自己里面存储的字符长度;
Abcdef --> 6+1字节
存储过程:
varchar (10)
abcde —> 判断字符长度----> 申请空间—> 存字符----> 申请1个字节存储这个数字长度
char (10)
abcde —>申请10个字符空间—> 存字符+空格填充
括号中数字问题
括号中,设置的是,字符的个数,无关字符类型。
但是,不同种类的字符,占用的存储空间是不一. 样的.
对于英文和数字,每个字符占1个字节长度。
对于中文,占用空间大小,要考虑字符集。
utf8,utf8mb4 , 每个中文,占3个字节长度;emoji字符, 占4个字节长度。
总长度不能超过数据类型的最大长度。
彩蛋: 以上两种数据类型选择需要考虑周全,会考虑到索引应用
C:时间类型
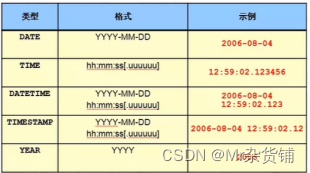 常用的时间格式:
常用的时间格式:
DATETIME(8字节)
范围为从1000-01-01 ~ 9999-12-31
TIMESTAMP(4字节)
1970-01-01 ~ 2038-01-19
D: json文档数据类型
{
id :101
Name:‘zhangsan’
}
(4)约束
PK(primary key) :主键约束
作用: 唯一 并且非空 每张表只能有一个主键
not null:非空约束
作用:必须非空,建议每个列都为非空
unique key : 唯一约束
作用:必须不重复的值
unsiqned :针对数字列 非负数
其他属性
Default: 默认值 有些信息不想填,我们会给他一个默认值
Comment :注释
Auto_ increment:自增长
4、Sql的应用
(1)client端命令
这些命令都是跟在sql后
\c 结束输入错误的命令
\G 格式化输出,就是将列放到行上输出;主要用在列名很多时堆在一起的表
\q 退出
tee /tmp/mysql.log; 开启命令记录;将在mysql中输入的命令保存的mysql.log 中
notee :是关闭记录
source /root/world.sql ;导入sql脚本
System ls;;它可以在MySQL里调用linux里的命令;
(2) server端命令
LInux中一切皆命令 ,一切皆文件
Mysql中一切皆sql 一切皆表
A: DDL 数据定义语言
库定义
1) 创建库:
CREATE DATABASE oldguo CHARSET utf8mb4 ;
规范:
库名:小写,业务有关,不要数字开头,
库名不要太长,不能使用保留字符串。
必须制定字符集。
2)查库
mysql> show databases;
mysql> show create database oldguo; #查看建库的具体信息
3)修改库:一般是从字符集从小到大改,只能改属性不能改库名
mysql> alter database oldguo charset utf8mb4 ;
4)删除库
mysql>Drop database 库名;
表定义
1)创建表
Create tableoldboy '.'wp_users' ( 'idint(11) NOT NULL AUTo_INCREMENT COMMENT ‘用户序号’,
'name ‘ varchar(64) not null COMIMENT ‘用户名,
‘age’tinyint(3) UNSIGNED NOT NULL DEFAULT 18 COMMENT’年龄",
gender’ char(1) NOT NULL DEFAULT 'F' COMMENT '性别', ‘cometimedatetime NOT NULLCOMMENT ‘注册时间’,
‘shengfen’enum (‘北京市’,‘上海市’ ‘天津市’,深圳市’,‘重庆市’)NOr NULZ DEFAULT’北京市·COMNENTV省份’,
PRIMARY KEY ( id`)
ENGINE=INNODB CHARSET=utf8mb4;
建表规范:
1、表名:小写字母 ,不能数字开头,表名和业务有关,名字不能太长,不能使用关键字
2、必须设置存储引擎和字符集
3、数据类型:合适 简短 足够
4、必须要有主键
5、每个列尽量设置not null 设置默认值
6、每个列要有注释
7、列名不能太长
2)查询表
mysql> Show tables;
mysql> desc user; 查询表结构
mysql> show create table user; 查看创建表的详细信息
(3)修改表
例子:
– 1.添加手机号列
Mysql> alter table wp_users add shouji bigint not null unique key comment '手机号’;
– 2.将shouji列数据类型修改为char (11),其他不变的属性也要写上
mysql> alter table wp_users modify shouji char (11) not null unique key comment ‘手机号’;
– 3.删除手机号列(危险) [ˈmɒdɪfaɪ]修改
mysql> alter table wp_users drop shouji;
4)删除表
Drop table uese;
B: DCL 数据控制语言
Grant 权限
Revoke 回收
C: DML 数据操作语言
Insert 插入
insert into dept(deptno, dname) values(50, ‘开发部’);
– 简约的方法(设置了默认值可以省略)
insert into dept values(50, ‘开发部’);
批量录入方式
insert into dept(deptno, dname)
values(50, ‘开发部’),(51, ‘眼发部’);
Update 更新:
前提 : 必须要明确要改哪一行,一般updata语句都有where的条件
mysql> update student set statu=1 where id =1;
Delete删除:
前提 : 必须要明确要改哪一行,一般delete语句都有where的条件
mysql> delete from student where id =1;
扩展:
1、伪删除
- - - 需求 : 删除id为1的数据
- - - 原操作
Delete from student where id=1;
- - - 修改表结构,添加state 状态列
给表添加一个列,默认值是0表示正常,1表示删除,当我们删除数据时只 需要修改这个状态列为1即可;
mysql> alter table student add statu tinyint not null default 0;
当删除时将状态列改成1
mysql> update student set statu=1 where id =1;
查询语句是加上状态
mysql> select * from student where id =1;
面试题:
delete from student 、
drop table student
truncate table student区别?
说明:
1.以上三条命令都可以删除全表数据。
2.区别:
delete from student:
逻辑上,逐行删除。数据行多,操作很慢。
并没有真正从磁盘上删除,只是在存储层面打标记,磁盘空间不立即释
HKM高水位线不会降低。就是id不会变
drop table student (删除整个表)
将表结构(元数据)和数据行物理层次删除。
truncate table student(清空表)
清空表段中的所有数据页。物理层次删除全表数据,磁盘空间立即释放,HWM高水位线会降低。
D:DQL 数据查询语言
select
1)功能: 获取表中的数据行
2)select 单独用法
Select now(); 显示当前时间
Select database(); 显示当前库
select concat (user,“@”,host) from user; concat拼接
mysql> select concat(“host”); 将双引号里的打印出来;
mysql> select version(); 查看数据库版本
mysql> select user(); 当前登录的用户
3)查询数据库参数
Select @@port; 查看端口号
Select @@datadir; 查看当前数据路径
Select @@socket; 查看当前socket路径
mysql> show variables; 如果不记得语句 可以查找
mysql> show variables like ‘po%’; 查询端口命令
4) 单表查询
–默认执行顺序
select
from 表1,表2,…: ::.
Where 过滤条件1过滤条件2 …
group by 条件列1条件列2 分组
select_list 列名列表
Having 过条件1过滤条件2 …
order by 条件列1条件列2
Limit 限制
select配合from的使用
- - 语法:
select 列 from 表;
- - 例子1: 查询表中所有的数据
Select * from world.city:
* 代表所有列
- - 例子2:查询城市名和对应的人口数(部分数据)
Select name, population from world.city ;
select 配合 where使用
where配合比较判断符号= ,>,<=,>=,<=,!=
---例子3:查询city中,中国所有城市信息。
Select* from world.city where countrycode='CHN';
WHERE配合LIKE语句模糊查询
---例子5:查询city中,国家代号是cH开头的城市信息。
mysql> select * from city where CountryCode like 'CH%';
---注意:like语句在使用时,切记不要出现前面带%的模糊查询,不走索引
Select * from world.city where countrycode like '%CH%';
where配合逻辑连接符and(且) or(或)
---例子6:查询中国人口大于500w的城市。
SELECT * FROM world.city WHERE countrycode='CHN' AND population>5000000;
细节:A or B 也可写成in(A,B); 只要满足括号里任意一个打印
---例子8:查询中国或美国的城市信息,并且人口数量超过500w
Select *FROM world.city
Where countrycode IN ('CHN', 'USA') AND population>5000000;
where 配合between AND--- > 100 > A > 10
---例子9:查询城市额人口数在100w到200w之间的。
SELECT *FROM world.city WHERE population>=10o0000 AND Population<=2000000;
mysql> select * from city where Population between 10000 and 30000;
select +from + where + group by
应用场景:需要对一张表中,按照不同数据特点,需要分组统计时
--- group by配合聚合函数max ( ) ,min () ,avg ( ) , count () , sum() , group_concat 使用聚合函数:
max () :最大值 min () :最小值
avg () :平均值 count () :统计个数
sum ( ) :求和 group_concat () :列转行 把1 转成1,2
2
说明:碰到group by 必然会有聚合函数。
---例子10 :统计city中,每个国家的城市个数。
mysql> select CountryCode,count(*) from city group by CountryCode;
---例子11:统计中国,每个省的城市个数。
mysql> select CountryCode,District,count(id) from city where CountryCode='CHN' group by District;
select + having , order by limit 使用
having 语句:
作用:后过滤,要写在group by 后面;要写having必须是where已经出现了;
并且having 过滤的列是前面语句查出来的列的名称
--- 例子15 :统计中国,每个省的总人口,只显示总人口数大于500w信息
mysql> select District,sum(Population) from city where CountryCode="CHN" group by District having sum(Population)>5000000;
order by 语句:
作用:默认是从小到大,desc 从大到小
--- 例子16:统计中国,每个省的总人口,只显示总人口数大于500w信息,并且排序
mysql> select District,sum(Population) from city where CountryCode="CHN" group by District having sum(Population)>5000000 order by sum(Population) desc;
limit 语句:
作用:分页显示; Limit 4,5:是跳过前4 行显示后5行.
- - -例子15 :统计中国,每个省的总人口,只显示总人口数大于500w信息, 并且排序,只看前5名
mysql> select District,sum(Population) from city where CountryCode="CHN" group by District having sum(Population)>5000000 order by sum(Population) desc limit 5;
--看第6行到10行
mysql> select District,sum(Population) from city where CountryCode="CHN" group by District having sum(Population)>5000000 order by sum(Population) desc limit 5,5;
5)多表查询
1>笛卡尔乘积(一般不用)
拿a表的每一行去和b表的每一行拼接
2>内连接 (应用广泛)
Join是连接2个表的; On是连接相同列的
mysql> select * from teacher join course on teacher.tno=course.tno;
Teacher表和course 有相同的列,就可以取到交集
3>外连接
外连接分为左外连接和右外连接
左外连接:查询的是a表数据和a与b交集的b表的部分
select * from emp left join dept on emp.dep_id=dept.did;
查出所有emp表和dept表与emp交集的dept表的数据
右外连接:查询的是b表数据和a与b交集的a表的部分
select * from emp right join dept on emp.dep_id=dept.did;
5.show语句的介绍
Show databases;
Show tables;
Show tables from world ; 从world 库下查询表名;
Show processlist; 查看所有用户连接情况
Show full processlist; 查询所有用户连接的详细信息
Show charset ; 查询支持 的字符集
Show collation ; 查看校对规则
show engines; 查看存储引擎
Show privileges; 查看支持 的权限
show grants for root@localhost; 查看用户的权限、
Show create database 查看建库语句
Show create tables 查看建库语句
Show index from 查看表的索引信息
Show engine innodb status 查看innodb 引擎
Show status ; 查看数据库状态
6.information_schema.tables视图 I _S (全局统计)
(1)介绍
每次数据库启动,会自动在内存中生成I_S ,生成查询mysql部分元数据信息视图
视图?
Select语句的执行方法;不保存数据本身
I_S 中的视图,保存的就是查询元数据的方法
作用:若查询语句很长时,我们可将这个语句保存成视图,当查询是调用这个视图即可;
例如:现在将mysql> select * from student; 语句保存成视图
第一步:创建视图,会以表的形式保存在当前库中
Create view 别名 as 查询命令-
mysql> create view v_select as select * from student; #as后跟语句,前面是别名
第二步:执行视图
mysql> select * from v_select;
select * from 别名
(2)I_S 中的tables
作用:保存了所有表的数据字典信息
desc tables;
TABLE_SCHEMA ---->表所在的库
TABLE_NAME ---->表名
ENGINE ---->引擎
TABLE_ROWS ---->表的行数(不是实时)
AVG_ROW_LENGTH ---->表中行的平均行长度(字节)
INDEX_LENGTH ---->索引的占用空间大小(字节
DATA_LENGTH ----> 表使用的存储空间大小(不是实时的)
DATA_FREE ----> 表中是否有碎片
(3)I_S .tables 企业应用实例
例子1:数据库资产统计每个库下所有表的个数,表名
库名 表个数 表名
select table_schema,count(table_name),group_concat(table_name) from tables group by table_schema
例子2: 统计每个库的占用空间总大小
方法一:
一张表的大小公式= TABLE_ROWS * AVG_ROW_LENGTH +INDEX_LENGTH
=表行*每行大小+存储引擎大小
select table_schema,sum(table_rows*avg_row_length+index_length) from tables group by table_schema;
方法二:
一张表的大小公式=DATA_LENGTH #直接算
mysql> select table_schema,sum(DATA_LENGTH)/1024 from tables group by table_schema;
例子3:查询业务数据库(系统库除外),所有非innodb表(引擎)
select table_schema,table_name from tables where engine!='innodb' and table_schema not in ('sys','performance_schema','information_schema','mysql');
例4:批量修改表,将50个非innodb的表转成innodb表;
思考:可以用concat,将查出来的非innodb的表名拼接成alter修改语句,在用Into outfile 将输出的语句保存到文件中;
第一步:
mysql> select concat("alter table ",table_schema,".",table_name," engine=innodb;") from tables where engine!="innodb" and table_schema not in ('sys','performance_schema','information_schema','mysql');
将查询出来的库名和表民进行拼接,将可以获取到修改语句
alter table school.student engine=innodb;
第二步:将查询结果输出到本地sql文件,在进行socean导入sql脚本
先要修改my.cnf文件,将导出的文件路径设置为安全路径/etc/my.cnf
[mysqld]
secure-file-priv=/tmp
重启数据库:
/etc/init.d/mysqld restart
在导出:
select concat("alter table ",table_schema,".",table_name," engine=innodb;") from tables where engine!="innodb" and table_schema not in ('sys','performance_schema','information_schema','mysql') into outfile "/tmp/alter.sql";
应用sql脚本:
mysql> source /tmp/alter.sql;
下一章:mysql的索引学习


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









