



1.延时从库
人为配置从库,当主库发生信息变化后,在延迟时间过后才会在从库执行
普通的主从复制,处理物理故障比较擅长
如果主库出现drop database操作
延时从库:主库做了某项操作之后,从库延时多长时间回放(sql线程)
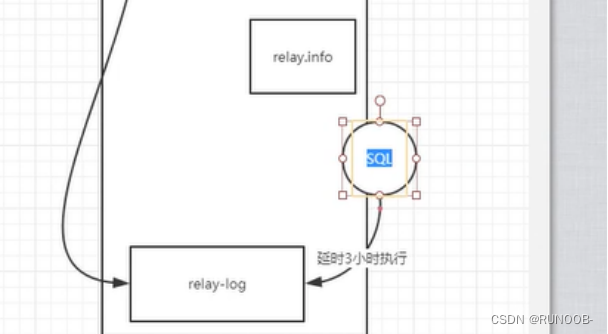
针对sql线程延迟
(1)配置步骤
Stop slave
Change master to master_delay=300; 单位是秒
Start slave;
Show slave status\G

这样可以解决,当主库发生drop时,我们可以在延时时间内 断了从库,以便数据恢复
(2)延迟从库应用
1>故障恢复思路
1主1从,从库延时5分钟,主库误删除1个库
- 5分钟之内 侦测到误删除操作
- 停从库SQL线程
- 截取relaylog
起点 :停止SQL线程时,relay最后应用位置
终点:误删除之前的position(GTID) - 恢复截取的日志到从库
- 从库身份解除,替代主库工作
2>故障模拟恢复
#模拟主库操作
Create database ys charset utf8mb4;
Use ys
Create table t1 (id int);
Inset into t1 values (1),(2),(3),(4);
Insert into t1 values (11),(22),(33),(44);
Drop database ye;
(3)修复数据
停止线程 ;前提是要看主库的日志是否都到从库
Stop slave;\

截取relay log日志
起点:通过mysql> show slave status\G查看

467就是起点
终点:通过查看relay-log-file查看drop之前的位置点
mysql> show relaylog events in’localhost-relay-bin.000002’;
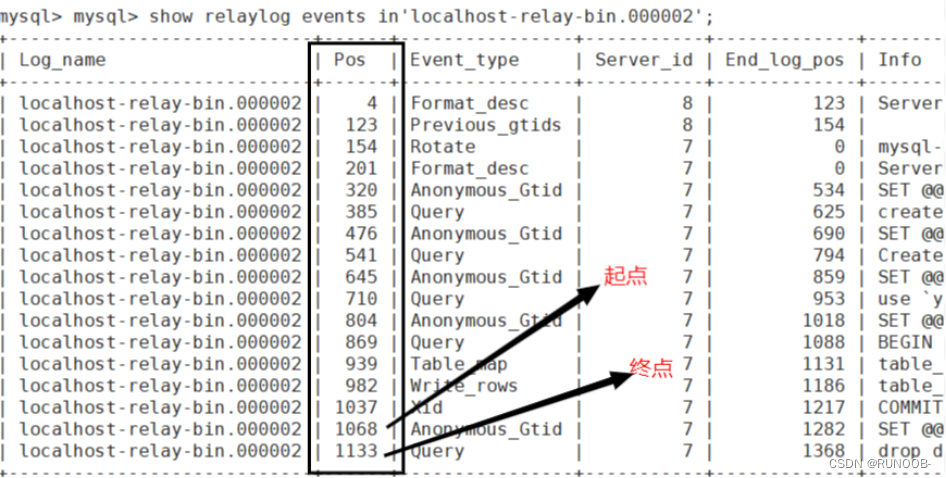
Pos是对应的relaylog的起点和终点,而end_log_pos是对应的binlog的位置点
此时终点是1133
截取日志
[root@localhost ~]# cd /data/3308/data/
[root@localhost data]# mysqlbinlog --start-position=476 --stop-position=1133 localhost-relay-bin.000002 >/tmp/relay.sql
导入从库恢复
mysql> stop slave;
mysql> reset slave all;
mysql> reset master; 清空realy log日志文件
mysql> set sql_log_bin=0;
mysql> source /tmp/relay.sql;
mysql> set sql_log_bin=1;
2.过滤复制
介绍:部分数据复制
使用场景:
(1)配置方法
主库:(主库一般很少用)
查看:Show master status;
白名单:Binlog_Do_DB=world
黑名单:Binlog_Ignore_DB
通过设置白名单和黑名单来控制库传输
从库:(用的多)
show slave status\G
Replicate_Do_DB:
Replicate_Ignore_DB:
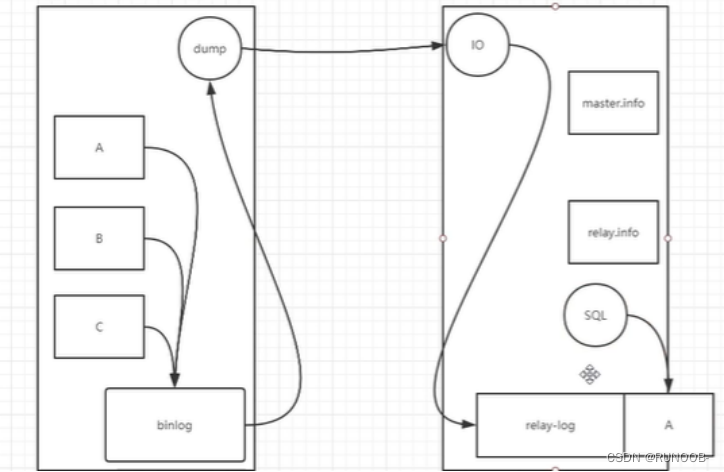
从库的过滤复制是通过控制sql线程来回放指定的库
查看过滤复制参数:Show slave status;
库级别(用的多)
Replicate_Do_DB=world Replicate_Do_DB=t1 白名单下复制,多个库就要写多个
Replicate_ignore_DB= 黑名单不复制
表级别
Replicate_Do_Table=world.t1 写表级别要把库带上
Replicate_ignore_Table=
表级别:模糊匹配
Replicate_Wild_Do_Table=wrold.t*
Replicate_Wild_Ignore_Table:
库级别,表级别,模糊匹配只能用一种。
(2)模拟
只复制zk库
方法1:修改配置文件
vim /data/3309/my.cnf
replicate_do_db=ppt
replicate_do_db=word
replicate_do_db=zk
将这个白名单添加到配置文件,都要小写
重启数据库;
[root@db01 ~]# systemctl restart mysqld3309
mysql> show slave status\G 查看状态;看图则成功

方法2:在线修改
stop slave sql_thread;
Change replication filter replicate_do_db=(zk,cs);
Start slave sql_thread;
先停止sql线程,在先修改白名单,开启线程,但是数据库重启后就会失效
3.半同步复制(面试)
(1)出现的原因
传统异步复制:
传统异步复制是不负责任的。因为没有返回值,当主库将日志传递给从库后主库不会管日志会不会落到从库磁盘;所以就有了半同步复制
(2)半同步复制
5.5 版本加入了半同步
缺点:不能100%保证;拉低性能
(3)半同步复制和传统的异步复制区别:(面试)
半同步复制是给主库和从库里都添加了插件,当主库commit提交事务时,会先将这个事务传递给从库,当从库里的插件检测到这个事务落盘后,从库插件给主库插件发送一个ack,此时主库才会commit成功;
缺点:当传输事数据出现问题,主库有接收不到ack时,commit不结束会阻塞事务
(4)配置半同步复制
加载插件
主:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
从:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
查看是否加载成功:
show plugins;
启动:
主:
SET GLOBAL rpl_semi_sync_master_enabled = 1;
从:
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
重启从库上的IO线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
查看是否在运行
主:
show status like 'Rpl_semi_sync_master_status';
从:
show status like 'Rpl_semi_sync_slave_status';
4. GTID复制
(1)优点
每个事务都有唯一逻辑编号
截binlog更加灵活
主从复制,提高性能:在dump传输日志时是并行传输,sql线程并行回放
(2)Gtid核心参数
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
gtid-mode=on --启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true --强制GTID的一致性
log-slave-updates=1 --slave更新是否记入日志
(3)搭建
准备3台虚拟机
清理环境(3台都要清理)
Rm -rf /data/3306/*
Rm -rf /data/binlog/*
Mv /etc/my.cnf /etc/my.cnf.bak
配置文件
db1:
[mysqld]
user=mysql
basedir=/app/database/mysql
datadir=/data/3307/data
socket=/data/3307/mysql.sock
server_id=51
port=3307
secure-file-priv=/tmp
autocommit=0
log_bin=/data/3307/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
innodb_data_file_path=ibdata1:12M;ibdata2:128M:autoextend
log_error=/data/3307/mysql.log
[mysql]
prompt=db01 [\\d]>
[client]
socket=/tmp/mysql3307.sock
Db2:
[mysqld]
user=mysql
basedir=/app/database/mysql
datadir=/data/3308/data
socket=/data/3308/mysql.sock
server_id=52
port=3308
secure-file-priv=/tmp
autocommit=0
log_bin=/data/3308/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
innodb_data_file_path=ibdata1:12M;ibdata2:128M:autoextend
log_error=/data/3308/mysql.log
[mysql]
prompt=db02[\\d]>
[client]
socket=/tmp/mysql3308.sock
Db3:
[mysqld]
user=mysql
basedir=/app/database/mysql
datadir=/data/3309/data
socket=/data/3309/mysql.sock
server_id=53
port=3309
secure-file-priv=/tmp
autocommit=0
log_bin=/data/3309/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
innodb_data_file_path=ibdata1:12M;ibdata2:128M:autoextend
log_error=/data/3309/mysql.log
[mysql]
prompt=db03 [\\d]>
[client]
socket=/tmp/mysql3309.sock
需要修改的地方
Db01 db02 db03
server_id=51 server_id=53 server_id=53
prompt=db01 [\\d] prompt=db02 [\\d] prompt=db03 [\\d]
log-slave-updates=1 强制从库和主库的gtid参数一致性
prompt=db01 [\\d] 登录数据库的参数
初始化数据(都要做)
mysqld --initialize-insecure --user=mysql --basedir=/app/database/mysql --datadir=/data/3307/data
mysqld --initialize-insecure --user=mysql --basedir=/app/database/mysql --datadir=/data/3308/data
mysqld --initialize-insecure --user=mysql --basedir=/app/database/mysql --datadir=/data/3309/data
启动数据库
[root@db02 ~]# pkill mysqld
[root@db02 ~]# /etc/init.d/mysqld start
主库创建用户(db01)
grant replication slave on *.* to rep1@'192.168.81.%' identified by '123';
(4)开启主从(新环境不需要开启补课)
在db02 db03
change master to
master_host='192.168.81.10',
master_user='rep1',
master_password='123',
MASTER_PORT=3307,
master_auto_position=1; #自动判断起点
启动:Start slave;
搭建失败执行这个:stop slave;reset slave all;
查看状态:
Show slave status;
Retrieved_Gtid_Set: 922b72b2-2c98-11eb-82d3-000c292f1a01:1 这个代表接收到的gtid
Executed_Gtid_Set: 922b72b2-2c98-11eb-82d3-000c292f1a01:1 这个代表的是执行的gtid
(5)Gtid构建不同点
master_auto_position=1;
参数功能:第一次构建主从时会自动检查最后一个relay的gtid信息,检查有没有gtid,没有则从主库的第一个gtid开启复制binlog日志
(6)从库误写入
原因:从库创建了库t1,主库也创建了t1库,重复
查看监控报错信息:
Last_SQL_Error: Error ‘Can’t create database ‘oldboy’; database exists’ on query. Default database: ‘oldboy’. Query: ‘create database oldboy’
Retrieved_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-3
Executed_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-2,
注入空事物的方法:在从库操作
s
top slave;
set gtid_next='99279e1e-61b7-11e9-a9fc-000c2928f5dd:3';
begin;commit;
set gtid_next='AUTOMATIC';
细节:mysql中gtid是怎么生成的,是在每一个事务前自动执行set gtid_next=;命令。所以当从库接收到的日志执行不了时,应该默认创建一个gtid在加一个空事务,这样就跳过了错误的主库gtid事务;
最好的解决方案:重新构建主从环境


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









