










Adaboost,与随机森林相似,也是由多个学习器共同决定最终分类的
但Adaboost和随机森林的区别,有两个:
①学习器关系不同:
- 随机森林的学习器关系:学习器相互独立,每个学习器的权重都一样
- Adaboost的学习器关系:学习器递进演变,每个学习器的权重也是独立的,但样本权重是基于上一个学习器的分类情况决定
②最终分类决定方式不同:
- 随机森林的最终分类结果:每个学习器都有一个分类结果,每个学习器权重都一样,最终按票高者决出最终分类结果
- Adaboost的最终分类结果:每个学习器的权重不同,每个学习器权重不一样,最终按加权求和结果决出最终分类结果
- Adaboost有两种性质的权重:
- 样本权重D:每条数据都有一个权重
- 特征权重W:每条数据里的每个特征x,都有一个权重
Adaboost的基本结构
多个弱分类器,构造一个强分类器
弱分类器
- 每次迭代训练一个新的弱分类器G,每个弱分类器都有对应的权重a
- 新分类器训练的权重a,主要是基于强分类器的损失函数Loss最小值求得
- 每次训练的数据样本,会基于上次弱分类器的分类误差率而有所改变
- 每次弱分类器,都会对每个样本做出预测分类,分类结果为-1和1两种
强分类器
- 每次迭代训练一个弱分类器,强分类器F就会更新:将新增的弱分类器加权求和,重构强分类器
迭代训练结构变化
- 迭代第一次:
- 弱分类器: G 1 ( X ) G_1(X) G1(X)
- 弱分类器权重: a 1 a_1 a1
- 强分类器 F 1 = a 1 G 1 ( X ) F_1 = a_1G_1(X) F1=a1G1(X) - 迭代第二次:
- 新增弱分类器: G 2 ( X ) G_2(X) G2(X)
- 新增弱分类器的权重: a 2 a_2 a2
- 重构强分类器: F 2 = a 1 G 1 ( X ) + a 2 G 2 ( X ) F_2=a_1G_1(X)+a_2G_2(X) F2=a1G1(X)+a2G2(X) - 迭代第三次:
- 新增弱分类器: G 3 ( X ) G_3(X) G3(X)
- 新增弱分类器的权重: a 3 a_3 a3
- 重构强分类器: F 3 = a 1 G 1 ( X ) + a 2 G 2 ( X ) + a 3 G 3 ( X ) F_3=a_1G_1(X)+a_2G_2(X)+a_3G_3(X) F3=a1G1(X)+a2G2(X)+a3G3(X) - 迭代第m次:
- 新增弱分类器: G m ( X ) G_m(X) Gm(X)
- 新增弱分类器的权重: a m a_m am
- 重构强分类器: F m = a 1 G 1 ( X ) + a 2 G 2 ( X ) + a 2 G 2 ( X ) + . . . + a m G m ( X ) = ∑ m = 1 M a m G m F_m=a_1G_1(X)+a_2G_2(X)+a_2G_2(X)+...+a_mG_m(X)=∑^M_{m=1}a_mG_m Fm=a1G1(X)+a2G2(X)+a2G2(X)+...+amGm(X)=∑m=1MamGm
- 相当于 F m = F m − 1 + a m G m ( X ) F_m=F_{m-1}+a_mG_m(X) Fm=Fm−1+amGm(X)
Adaboost的数学公式
- 强分类器模型-加法模型
- F m = ∑ m = 1 M a m G m = F m − 1 + a m G m ( X ) F_m=∑^M_{m=1}a_mG_m=F_{m-1}+a_mG_m(X) Fm=∑m=1MamGm=Fm−1+amGm(X)
- 强分类器的损失函数模型-指数函数模型
- L o s s = ∑ i = 1 N e − y i F m ( x i ) Loss=∑^N_{i=1}e^{-y_iF_m(x_i)} Loss=∑i=1Ne−yiFm(xi)
- N是数据样本量,m表示当前有m个弱分类器构成了一个强分类器 F m F_m Fm
- 当前最新的弱分类器的分类误差率-分类错误样本的权重之和:
- e m = ∑ W m , i I [ y i ≠ G m ( x i ) ] e_m=∑W_{m,i}I[y_i≠G_m(x_i)] em=∑Wm,iI[yi=Gm(xi)],
- 这里的 I [ y i ≠ G m ( x i ) ] I[y_i≠G_m(x_i)] I[yi=Gm(xi)]不参与计算,只表示条件:实际分类结果 y i y_i yi与弱分类器预测分类结果 G m ( x i ) G_m(x_i) Gm(xi)不相等
- 当前最新的弱分类器的权重公式:
-
a
m
=
1
2
l
n
1
−
e
m
e
m
a_m=\frac{1}{2}ln\frac{1-e_m}{e_m}
am=21lnem1−em
这里有两种推导方式
-
a
m
=
1
2
l
n
1
−
e
m
e
m
a_m=\frac{1}{2}ln\frac{1-e_m}{e_m}
am=21lnem1−em
- 每个数据样本的权重更新公式:
-
W
m
+
1
,
i
=
W
m
,
i
∗
e
−
y
i
a
m
G
m
(
x
i
)
Z
m
W_{m+1,i}=\frac{W_{m,i}*e^{-y_ia_mG_m(x_i)}}{Zm}
Wm+1,i=ZmWm,i∗e−yiamGm(xi)
- Z m = ∑ i N W m , i ∗ e − y i a m G m ( x i ) Z_m = ∑_i^NW_{m,i}*e^{-y_ia_mG_m(x_i)} Zm=∑iNWm,i∗e−yiamGm(xi)
- 推导方式①:按损失函数最小化推导(在下方)
- 推导方式②:按分类误差率em最小化推导
-
W
m
+
1
,
i
=
W
m
,
i
∗
e
−
y
i
a
m
G
m
(
x
i
)
Z
m
W_{m+1,i}=\frac{W_{m,i}*e^{-y_ia_mG_m(x_i)}}{Zm}
Wm+1,i=ZmWm,i∗e−yiamGm(xi)
按损失函数最小化进行数学推导
- 按损失函数最小化推导: W m + 1 , i = W m , i ∗ e − y i a m G m ( x i ) W_{m+1,i}=W_{m,i}*e^{-y_ia_mG_m(x_i)} Wm+1,i=Wm,i∗e−yiamGm(xi)
重点,太困了,明天再继续
上班划个水,摸个鱼来梳理
在Adaboost的数学公式中,有几个是固定的,无需进行推导:
a.强分类器模型-加法模型 F m = ∑ m = 1 M a m G m = F m − 1 + a m G m ( X ) F_m=∑^M_{m=1}a_mG_m=F_{m-1}+a_mG_m(X) Fm=∑m=1MamGm=Fm−1+amGm(X)
这个模型的意思是,将所有弱分类器的分类结果加权求和,最终得到的 F m F_m Fm并不一定是准确的-1或1这样的二分类结果
但可以进行sign函数来划分:
当
F
m
>
0
F_m>0
Fm>0,预测分类为+1
当
F
m
<
0
F_m<0
Fm<0,预测分类为-1
不过,不着急划分 F m F_m Fm,等最后将所有弱分类器都训练完之后,再应用sign函数对 F m F_m Fm分类
b.强分类器的损失函数模型-指数函数模型 L o s s = ∑ i = 1 N e − y i F m ( x i ) Loss=∑^N_{i=1}e^{-y_iF_m(x_i)} Loss=∑i=1Ne−yiFm(xi)
这是用于衡量每次新增的弱分类器,是否能使整体强分类器的分类表现更好
指数函数e是个单调递增函数
当
F
m
(
x
i
)
与
y
i
F_m(x_i)与y_i
Fm(xi)与yi同向,表示分类正确,则
−
y
i
∗
F
m
(
x
i
)
<
0
-y_i*F_m(x_i)<0
−yi∗Fm(xi)<0,则
F
m
(
x
i
)
F_m(x_i)
Fm(xi)越大,则Loss值越小
当
F
m
(
x
i
)
与
y
i
F_m(x_i)与y_i
Fm(xi)与yi反向,表示分类错误,则
−
y
i
∗
F
m
(
x
i
)
>
0
-y_i*F_m(x_i)>0
−yi∗Fm(xi)>0,则
F
m
(
x
i
)
F_m(x_i)
Fm(xi)越小,则Loss值越大
在 L o s s = ∑ i = 1 N e − y i F m ( x i ) Loss=∑^N_{i=1}e^{-y_iF_m(x_i)} Loss=∑i=1Ne−yiFm(xi)中, F m ( x i ) F_m(x_i) Fm(xi)还是加权求和后的分类值
d.每个数据样本的权重更新公式: W m + 1 , i = W m , i ∗ e − y i a m G m ( x i ) W_{m+1,i}=W_{m,i}*e^{-y_ia_mG_m(x_i)} Wm+1,i=Wm,i∗e−yiamGm(xi)
每次新增一个弱分类器进行训练时,训练的数据是不一样的,重点训练上一轮弱分类器中分类错误的那些数据样本
因此,在每次训练完数据后,都要尽可能增加分类错误的数据样本权重,降低分类正确的数据样本权重
只要数据样本的权重发生改变,那么下一次随机抽取数据进行训练时,错误样本被抽取到的概率就会增加,正确样本被抽取到的概率就会降低。
W m + 1 , i = W m , i ∗ e − y i a m G m ( x i ) W_{m+1,i}=W_{m,i}*e^{-y_ia_mG_m(x_i)} Wm+1,i=Wm,i∗e−yiamGm(xi)
- W m + 1 , i W_{m+1,i} Wm+1,i:表示下一轮数据样本的权重
- W m , i W_{m,i} Wm,i:表示本轮数据样本的权重
- a m a_m am:表示本轮弱分类器的分类权重,大于0
- G m ( x i ) G_m(x_i) Gm(xi):表示本轮弱分类器的分类结果(+1或-1)
这个公式中的 a m G m ( x i ) a_mG_m(x_i) amGm(xi)表示当前弱分类器的分类结果 G m ( x i ) G_m(x_i) Gm(xi)和权重 a m a_m am
指数函数e是个单调递增函数
当 G m ( x i ) 与 y i G_m(x_i)与y_i Gm(xi)与yi同向,表示分类正确,则 − y i ∗ a m ∗ G m ( x i ) < 0 -y_i*a_m*G_m(x_i)<0 −yi∗am∗Gm(xi)<0,则 W m , i ∗ e − y i a m G m ( x i ) W_{m,i}*e^{-y_ia_mG_m(x_i)} Wm,i∗e−yiamGm(xi)越小,即 W m + 1 , i 比之前的权重降低 W_{m+1,i}比之前的权重降低 Wm+1,i比之前的权重降低
当 G m ( x i ) 与 y i G_m(x_i)与y_i Gm(xi)与yi反向,表示分类错误,则 − y i ∗ a m ∗ F m ( x i ) > 0 -y_i*a_m*F_m(x_i)>0 −yi∗am∗Fm(xi)>0,则 W m , i ∗ e − y i a m G m ( x i ) W_{m,i}*e^{-y_ia_mG_m(x_i)} Wm,i∗e−yiamGm(xi)越大,即 W m + 1 , i 比之前的权重增加 W_{m+1,i}比之前的权重增加 Wm+1,i比之前的权重增加
无论是课本、还是别人的权重更新公式,都要进行归一化处理,实际不应该先进行归一化处理的
因为a和e的关系,是要根据未归一化处理的权重调整公式来推理的
具体推理往后边看
c.当前最新的弱分类器的分类误差率-分类错误样本的权重之和: e m = ∑ W m , i I [ y i ≠ G m ( x i ) ] ∑ W m , i e_m=\frac{∑W_{m,i}I[y_i≠G_m(x_i)]}{∑W_{m,i}} em=∑Wm,i∑Wm,iI[yi=Gm(xi)]
这个分类误差率 e m e_m em,其实就是当前最新弱分类器中,错误分类在所有数据样本的权重中的占比
e
m
e_m
em的作用主要是衡量当前弱分类器的权重
如果当前弱分类器的
e
m
e_m
em比较大,那么应当降低当前弱分类器的权重
a
m
a_m
am,表示较小程度的参考当前弱分类器
如果当前弱分类器的
e
m
e_m
em比较小,那么应当提高当前弱分类器的权重
a
m
a_m
am,表示较大程度的参考当前弱分类器
但
e
m
e_m
em和
a
m
a_m
am的关系是怎样的呢?
这是要重点推导的部分
当前最新的弱分类器的权重公式: a m = 1 2 l n 1 − e m e m a_m=\frac{1}{2}ln\frac{1-e_m}{e_m} am=21lnem1−em
a m a_m am是基于强分类器的损失函数极值来求的
首先 L o s s = ∑ i = 1 N e − y i F m ( x i ) Loss=∑^N_{i=1}e^{-y_iF_m(x_i)} Loss=∑i=1Ne−yiFm(xi)
= ∑ i = 1 N e − y i ( F m − 1 ( x i ) + a m G m ( x i ) ) =∑^N_{i=1}e^{-y_i(F_{m-1}(x_i)+a_mG_m(x_i))} =∑i=1Ne−yi(Fm−1(xi)+amGm(xi))
= ∑ i = 1 N e − y i F m − 1 ( x i ) ∗ e a m G m ( x i ) =∑^N_{i=1}e^{-y_iF_{m-1}(x_i)}*e^{a_mG_m(x_i)} =∑i=1Ne−yiFm−1(xi)∗eamGm(xi)
在之前的m-1轮训练弱分类器时,就已经能算出 F m − 1 ( x i ) F_{m-1}(x_i) Fm−1(xi)了,因此 e − y i F m − 1 ( x i ) e^{-y_iF_{m-1}(x_i)} e−yiFm−1(xi)在最新一轮的训练中属于已知常数,可设为 A i = e − y i F m − 1 ( x i ) A_i=e^{-y_iF_{m-1}(x_i)} Ai=e−yiFm−1(xi)
则 L o s s = ∑ i = 1 N A i ∗ e − y i a m G m ( x i ) Loss=∑^N_{i=1}A_i*e^{-y_ia_mG_m(x_i)} Loss=∑i=1NAi∗e−yiamGm(xi)
当前弱分类器如果预测正确,即
y
i
=
G
m
(
x
i
)
y_i=G_m(x_i)
yi=Gm(xi),则
−
y
i
G
m
(
x
i
)
=
−
1
-y_iG_m(x_i)=-1
−yiGm(xi)=−1
当前弱分类器如果预测错误,即
y
i
≠
G
m
(
x
i
)
y_i≠G_m(x_i)
yi=Gm(xi),则
−
y
i
G
m
(
x
i
)
=
1
-y_iG_m(x_i)=1
−yiGm(xi)=1
因此,Loss函数可根据当前弱分类器的分类结果,进行拆分加和
L
o
s
s
=
∑
i
=
1
N
A
i
∗
e
−
a
m
I
[
y
i
=
G
m
(
x
i
)
]
+
∑
i
=
1
N
A
i
∗
e
a
m
I
[
y
i
≠
G
m
(
x
i
)
]
Loss=∑^N_{i=1}A_i*e^{-a_m}I[y_i=G_m(x_i)]+∑^N_{i=1}A_i*e^{a_m}I[y_i≠G_m(x_i)]
Loss=∑i=1NAi∗e−amI[yi=Gm(xi)]+∑i=1NAi∗eamI[yi=Gm(xi)]
我们要让Loss达到极小值,则对Loss求
a
m
a_m
am的偏导
L
a
m
′
=
−
∑
i
=
1
N
A
i
∗
e
−
a
m
I
[
y
i
=
G
m
(
x
i
)
]
+
∑
i
=
1
N
A
i
∗
e
a
m
I
[
y
i
≠
G
m
(
x
i
)
]
=
0
L'_{am} = -∑^N_{i=1}A_i*e^{-a_m}I[y_i=G_m(x_i)]+∑^N_{i=1}A_i*e^{a_m}I[y_i≠G_m(x_i)]=0
Lam′=−∑i=1NAi∗e−amI[yi=Gm(xi)]+∑i=1NAi∗eamI[yi=Gm(xi)]=0
这时候还是很难看出 a m a_m am和 e m e_m em的关系,但是,我们可以将 L a m ′ L'_{am} Lam′尽可能化成与 e m e_m em公式相似的结构
已知 e m = ∑ W m , i I [ y i ≠ G m ( x i ) ] ∑ W m , i e_m=\frac{∑W_{m,i}I[y_i≠G_m(x_i)]}{∑W_{m,i}} em=∑Wm,i∑Wm,iI[yi=Gm(xi)],含有错误样本和全部样本项
那么 L a m ′ = − ∑ i = 1 N A i ∗ e − a m I [ y i = G m ( x i ) ] + ∑ i = 1 N A i ∗ e a m I [ y i ≠ G m ( x i ) ] L'_{am} = -∑^N_{i=1}A_i*e^{-a_m}I[y_i=G_m(x_i)]+∑^N_{i=1}A_i*e^{a_m}I[y_i≠G_m(x_i)] Lam′=−∑i=1NAi∗e−amI[yi=Gm(xi)]+∑i=1NAi∗eamI[yi=Gm(xi)]中,
可以将正确样本项 ∑ i = 1 N A i ∗ e − a m I [ y i = G m ( x i ) ] ∑^N_{i=1}A_i*e^{-a_m}I[y_i=G_m(x_i)] ∑i=1NAi∗e−amI[yi=Gm(xi)]用【全部样本项-错误样本项】来表示
即
∑
i
=
1
N
A
i
∗
e
−
a
m
I
[
y
i
=
G
m
(
x
i
)
]
∑^N_{i=1}A_i*e^{-a_m}I[y_i=G_m(x_i)]
∑i=1NAi∗e−amI[yi=Gm(xi)]
=
∑
i
=
1
N
A
i
∗
e
−
a
m
−
∑
i
=
1
N
A
i
∗
e
−
a
m
I
[
y
i
≠
G
m
(
x
i
)
]
=∑^N_{i=1}A_i*e^{-a_m}-∑^N_{i=1}A_i*e^{-a_m}I[y_i≠G_m(x_i)]
=∑i=1NAi∗e−am−∑i=1NAi∗e−amI[yi=Gm(xi)]
则
L
a
m
′
L'_{am}
Lam′
=
−
∑
i
=
1
N
A
i
∗
e
−
a
m
+
∑
i
=
1
N
A
i
∗
e
−
a
m
I
[
y
i
≠
G
m
(
x
i
)
]
+
∑
i
=
1
N
A
i
∗
e
a
m
I
[
y
i
≠
G
m
(
x
i
)
]
= -∑^N_{i=1}A_i*e^{-a_m}+∑^N_{i=1}A_i*e^{-a_m}I[y_i≠G_m(x_i)]+∑^N_{i=1}A_i*e^{a_m}I[y_i≠G_m(x_i)]
=−∑i=1NAi∗e−am+∑i=1NAi∗e−amI[yi=Gm(xi)]+∑i=1NAi∗eamI[yi=Gm(xi)]
=
−
e
−
a
m
∑
i
=
1
N
A
i
+
[
e
−
a
m
+
e
a
m
]
∑
i
=
1
N
A
i
∗
I
[
y
i
≠
G
m
(
x
i
)
]
= -e^{-a_m}∑^N_{i=1}A_i+[e^{-a_m}+e^{a_m}]∑^N_{i=1}A_i*I[y_i≠G_m(x_i)]
=−e−am∑i=1NAi+[e−am+eam]∑i=1NAi∗I[yi=Gm(xi)]
=
0
=0
=0
则有
e
−
a
m
∗
∑
i
=
1
N
A
i
=
(
e
−
a
m
+
e
a
m
)
∗
∑
i
=
1
N
A
i
I
[
y
i
≠
G
m
(
x
i
)
]
e^{-a_m}*∑^N_{i=1}A_i=(e^{-a_m}+e^{a_m})*∑^N_{i=1}A_iI[y_i≠G_m(x_i)]
e−am∗∑i=1NAi=(e−am+eam)∗∑i=1NAiI[yi=Gm(xi)]
则有 ∑ i = 1 N A i I [ y i ≠ G m ( x i ) ] ∑ i = 1 N A i = e − a m e − a m + e a m \frac{∑^N_{i=1}A_iI[y_i≠G_m(x_i)]}{∑^N_{i=1}A_i}=\frac{e^{-a_m}}{e^{-a_m}+e^{a_m}} ∑i=1NAi∑i=1NAiI[yi=Gm(xi)]=e−am+eame−am👉👉👉👉重点式子①
其中,
A
i
=
e
−
y
i
F
m
−
1
(
x
i
)
A_i=e^{-y_iF_{m-1}(x_i)}
Ai=e−yiFm−1(xi)
其中,
F
m
−
1
(
x
i
)
=
a
1
G
1
(
x
i
)
+
a
2
G
2
(
x
i
)
+
.
.
.
+
a
m
−
1
G
m
−
1
(
x
i
)
F_{m-1}(x_i)=a_1G_1(x_i)+a_2G_2(x_i)+...+a_{m-1}G_{m-1}(x_i)
Fm−1(xi)=a1G1(xi)+a2G2(xi)+...+am−1Gm−1(xi)
则,
A
i
=
e
−
y
i
F
m
−
1
(
x
i
)
A_i=e^{-y_iF_{m-1}(x_i)}
Ai=e−yiFm−1(xi)
=
e
−
y
i
∗
[
a
1
G
1
(
x
i
)
+
a
2
G
2
(
x
i
)
+
.
.
.
+
a
m
−
1
G
m
−
1
(
x
i
)
]
=e^{-y_i*[a_1G_1(x_i)+a_2G_2(x_i)+...+a_{m-1}G_{m-1}(x_i)]}
=e−yi∗[a1G1(xi)+a2G2(xi)+...+am−1Gm−1(xi)]
=
e
−
y
i
∗
a
1
G
1
(
x
i
)
e
−
y
i
∗
a
2
G
2
(
x
i
)
.
.
.
e
−
y
i
∗
a
m
−
1
G
m
−
1
(
x
i
)
=e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}
=e−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)
则, ∑ i = 1 N A i I [ y i ≠ G m ( x i ) ] ∑ i = 1 N A i = ∑ i = 1 N e − y i ∗ a 1 G 1 ( x i ) e − y i ∗ a 2 G 2 ( x i ) . . . e − y i ∗ a m − 1 G m − 1 ( x i ) I [ y i ≠ G m ( x i ) ] ∑ i = 1 N e − y i ∗ a 1 G 1 ( x i ) e − y i ∗ a 2 G 2 ( x i ) . . . e − y i ∗ a m − 1 G m − 1 ( x i ) \frac{∑^N_{i=1}A_iI[y_i≠G_m(x_i)]}{∑^N_{i=1}A_i}=\frac{∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}I[y_i≠G_m(x_i)]}{∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}} ∑i=1NAi∑i=1NAiI[yi=Gm(xi)]=∑i=1Ne−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)∑i=1Ne−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)I[yi=Gm(xi)]
已知, W 2 , i = W 1 , i ∗ e − y i ∗ a 1 G 1 ( x i ) Z 1 , 可得 e − y i ∗ a 1 G 1 ( x i ) = W 2 , i ∗ Z 1 W_{2,i}=\frac{W_{1,i}*e^{-y_i*a_1G_1(x_i)}}{Z_1},可得e^{-y_i*a_1G_1(x_i)}=W_{2,i}*Z_1 W2,i=Z1W1,i∗e−yi∗a1G1(xi),可得e−yi∗a1G1(xi)=W2,i∗Z1
e 2 = ∑ W 2 , i I [ y i ≠ G 1 ( x i ) ] = ∑ i = 1 N W 1 , i ∗ e − y i ∗ a 1 G 1 ( x i ) Z 1 I [ y i ≠ G 1 ( x i ) ] e_2=∑W_{2,i}I[y_i≠G_1(x_i)]=\frac{∑^N_{i=1}W_{1,i}*e^{-y_i*a_1G_1(x_i)}}{Z_1}I[y_i≠G_1(x_i)] e2=∑W2,iI[yi=G1(xi)]=Z1∑i=1NW1,i∗e−yi∗a1G1(xi)I[yi=G1(xi)]
e 3 = ∑ W 3 , i I [ y i ≠ G 1 ( x i ) ] = ∑ i = 1 N W 2 , i ∗ e − y i ∗ a 2 G 2 ( x i ) Z 2 I [ y i ≠ G 2 ( x i ) ] e_3=∑W_{3,i}I[y_i≠G_1(x_i)]=\frac{∑^N_{i=1}W_{2,i}*e^{-y_i*a_2G_2(x_i)}}{Z_2}I[y_i≠G_2(x_i)] e3=∑W3,iI[yi=G1(xi)]=Z2∑i=1NW2,i∗e−yi∗a2G2(xi)I[yi=G2(xi)]
= ∑ i = 1 N W 1 , i ∗ e − y i ∗ a 1 G 1 ( x i ) ∗ e − y i ∗ a 2 G 2 ( x i ) Z 1 ∗ Z 2 I [ y i ≠ G 2 ( x i ) ] =\frac{∑^N_{i=1}W_{1,i}*e^{-y_i*a_1G_1(x_i)}*e^{-y_i*a_2G_2(x_i)}}{Z_1*Z_2}I[y_i≠G_2(x_i)] =Z1∗Z2∑i=1NW1,i∗e−yi∗a1G1(xi)∗e−yi∗a2G2(xi)I[yi=G2(xi)]
同理可得
e
m
=
∑
i
=
1
N
W
1
,
i
∗
e
−
y
i
∗
a
1
G
1
(
x
i
)
∗
e
−
y
i
∗
a
2
G
2
(
x
i
)
∗
.
.
.
∗
e
−
y
i
∗
a
m
−
1
G
m
−
1
(
x
i
)
Z
1
∗
Z
2
∗
.
.
.
∗
Z
m
−
1
I
[
y
i
≠
G
m
−
1
(
x
i
)
]
e_m=\frac{∑^N_{i=1}W_{1,i}*e^{-y_i*a_1G_1(x_i)}*e^{-y_i*a_2G_2(x_i)}*...*e^{-y_i*a_{m-1}G_{m-1}(x_i)}}{Z_1*Z_2*...*Z_{m-1}}I[y_i≠G_{m-1}(x_i)]
em=Z1∗Z2∗...∗Zm−1∑i=1NW1,i∗e−yi∗a1G1(xi)∗e−yi∗a2G2(xi)∗...∗e−yi∗am−1Gm−1(xi)I[yi=Gm−1(xi)]
∑ i = 1 N e − y i ∗ a 1 G 1 ( x i ) ∗ e − y i ∗ a 2 G 2 ( x i ) ∗ . . . ∗ e − y i ∗ a m − 1 G m − 1 ( x i ) ∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}*e^{-y_i*a_2G_2(x_i)}*...*e^{-y_i*a_{m-1}G_{m-1}(x_i)} ∑i=1Ne−yi∗a1G1(xi)∗e−yi∗a2G2(xi)∗...∗e−yi∗am−1Gm−1(xi)
= Z 1 ∗ Z 2 ∗ . . . ∗ Z m − 1 ∗ 1 W 1 , i =Z_1*Z_2*...*Z_{m-1}*\frac{1}{W_{1,i}} =Z1∗Z2∗...∗Zm−1∗W1,i1
那么
∑ i = 1 N A i I [ y i ≠ G m ( x i ) ] ∑ i = 1 N A i = ∑ i = 1 N e − y i ∗ a 1 G 1 ( x i ) e − y i ∗ a 2 G 2 ( x i ) . . . e − y i ∗ a m − 1 G m − 1 ( x i ) I [ y i ≠ G m ( x i ) ] ∑ i = 1 N e − y i ∗ a 1 G 1 ( x i ) e − y i ∗ a 2 G 2 ( x i ) . . . e − y i ∗ a m − 1 G m − 1 ( x i ) \frac{∑^N_{i=1}A_iI[y_i≠G_m(x_i)]}{∑^N_{i=1}A_i}=\frac{∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}I[y_i≠G_m(x_i)]}{∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}} ∑i=1NAi∑i=1NAiI[yi=Gm(xi)]=∑i=1Ne−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)∑i=1Ne−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)I[yi=Gm(xi)]
=
e
m
∗
Z
1
Z
2
.
.
.
Z
m
−
1
∑
i
=
1
N
e
−
y
i
∗
a
1
G
1
(
x
i
)
e
−
y
i
∗
a
2
G
2
(
x
i
)
.
.
.
e
−
y
i
∗
a
m
−
1
G
m
−
1
(
x
i
)
∗
1
W
1
,
i
=\frac{e_m*Z_1Z_2...Z_{m-1}}{∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}}*\frac{1}{W_{1,i}}
=∑i=1Ne−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)em∗Z1Z2...Zm−1∗W1,i1👉式子②
重要
又因为
W
2
,
i
=
W
1
,
i
∗
e
−
y
i
a
1
G
1
(
x
i
)
Z
1
W_{2,i}=\frac{W_{1,i}*e^{-y_ia_{1}G_{1}(x_i)}}{Z_{1}}
W2,i=Z1W1,i∗e−yia1G1(xi)
W
3
,
i
=
W
2
,
i
∗
e
−
y
i
a
2
G
2
(
x
i
)
Z
2
W_{3,i}=\frac{W_{2,i}*e^{-y_ia_{2}G_{2}(x_i)}}{Z_{2}}
W3,i=Z2W2,i∗e−yia2G2(xi)
=
W
1
,
i
∗
e
−
y
i
a
1
G
1
(
x
i
)
∗
e
−
y
i
a
2
G
2
(
x
i
)
Z
1
Z
2
=\frac{W_{1,i}*e^{-y_ia_{1}G_{1}(x_i)}*e^{-y_ia_{2}G_{2}(x_i)}}{Z_{1}Z_{2}}
=Z1Z2W1,i∗e−yia1G1(xi)∗e−yia2G2(xi)
同理可得
W
m
,
i
=
W
1
,
i
∗
e
−
y
i
a
1
G
1
(
x
i
)
∗
e
−
y
i
a
2
G
2
(
x
i
)
∗
.
.
.
∗
e
−
y
i
a
m
−
1
G
m
−
1
(
x
i
)
Z
1
Z
2
∗
.
.
.
∗
Z
m
−
1
W_{m,i}=\frac{W_{1,i}*e^{-y_ia_{1}G_{1}(x_i)}*e^{-y_ia_{2}G_{2}(x_i)}*...*e^{-y_ia_{m-1}G_{m-1}(x_i)}}{Z_{1}Z_{2}*...*Z_{m-1}}
Wm,i=Z1Z2∗...∗Zm−1W1,i∗e−yia1G1(xi)∗e−yia2G2(xi)∗...∗e−yiam−1Gm−1(xi)
已知 ∑ i = 1 N W m , i = 1 ∑^N_{i=1}W_{m,i}=1 ∑i=1NWm,i=1,则有 ∑ i = 1 N W 1 , i ∗ e − y i a 1 G 1 ( x i ) ∗ e − y i a 2 G 2 ( x i ) ∗ . . . ∗ e − y i a m − 1 G m − 1 ( x i ) Z 1 Z 2 ∗ . . . ∗ Z m − 1 = 1 ∑^N_{i=1}\frac{W_{1,i}*e^{-y_ia_{1}G_{1}(x_i)}*e^{-y_ia_{2}G_{2}(x_i)}*...*e^{-y_ia_{m-1}G_{m-1}(x_i)}}{Z_{1}Z_{2}*...*Z_{m-1}}=1 ∑i=1NZ1Z2∗...∗Zm−1W1,i∗e−yia1G1(xi)∗e−yia2G2(xi)∗...∗e−yiam−1Gm−1(xi)=1
则有 ∑ i = 1 N e − y i a 1 G 1 ( x i ) ∗ e − y i a 2 G 2 ( x i ) ∗ . . . ∗ e − y i a m − 1 G m − 1 ( x i ) = Z 1 Z 2 . . . Z m − 1 ∗ 1 W 1 , i ∑^N_{i=1}e^{-y_ia_{1}G_{1}(x_i)}*e^{-y_ia_{2}G_{2}(x_i)}*...*e^{-y_ia_{m-1}G_{m-1}(x_i)}=Z_{1}Z_{2}...Z_{m-1}*\frac{1}{W_{1,i}} ∑i=1Ne−yia1G1(xi)∗e−yia2G2(xi)∗...∗e−yiam−1Gm−1(xi)=Z1Z2...Zm−1∗W1,i1👉式子③
把式子③代入上述的式子②,就可以得到最后的
∑ i = 1 N A i I [ y i ≠ G m ( x i ) ] ∑ i = 1 N A i = ∑ i = 1 N e m ∗ Z 1 Z 2 . . . Z m − 1 ∑ i = 1 N e − y i ∗ a 1 G 1 ( x i ) e − y i ∗ a 2 G 2 ( x i ) . . . e − y i ∗ a m − 1 G m − 1 ( x i ) ∗ 1 W 1 , i \frac{∑^N_{i=1}A_iI[y_i≠G_m(x_i)]}{∑^N_{i=1}A_i}=\frac{∑^N_{i=1}e_m*Z_1Z_2...Z_{m-1}}{∑^N_{i=1}e^{-y_i*a_1G_1(x_i)}e^{-y_i*a_2G_2(x_i)}...e^{-y_i*a_{m-1}G_{m-1}(x_i)}}*\frac{1}{W_{1,i}} ∑i=1NAi∑i=1NAiI[yi=Gm(xi)]=∑i=1Ne−yi∗a1G1(xi)e−yi∗a2G2(xi)...e−yi∗am−1Gm−1(xi)∑i=1Nem∗Z1Z2...Zm−1∗W1,i1
= e m =e_m =em
结合式子①就有
∑ i = 1 N A i I [ y i ≠ G m ( x i ) ] ∑ i = 1 N A i = e − a m e − a m + e a m = e m \frac{∑^N_{i=1}A_iI[y_i≠G_m(x_i)]}{∑^N_{i=1}A_i}=\frac{e^{-a_m}}{e^{-a_m}+e^{a_m}}=e_m ∑i=1NAi∑i=1NAiI[yi=Gm(xi)]=e−am+eame−am=em
这不就出来了嘛!!!!!
e m = e − a m e − a m + e a m e_m=\frac{e^{-a_m}}{e^{-a_m}+e^{a_m}} em=e−am+eame−am
最后化简得到 a m = 1 2 l n 1 − e m e m a_m=\frac{1}{2}ln\frac{1-e_m}{e_m} am=21lnem1−em
推导完成!可见,W还是要归一化的!!!!!!
Adaboost的基础思路
① 初始化数据样本权重W
- 所有数据样本的初始权重,设置为 W 1 , i = 1 N W_{1,i}=\frac{1}{N} W1,i=N1,这里的i指的是单个样本
② 应用单层二分类决策树,训练一个新的弱分类器G,并计算该弱分类器的分类误差率e
- 这里的单层二分类决策树,指的就是只应用单个特征进行训练的决策树,训练后的预测分类结果是二分类
③ 根据整体分类损失函数Loss,计算该弱分类器的权重a
④ 更新数据样本权重
W
n
e
w
W_{new}
Wnew,并随机抽取数据下一轮准备训练的数据样本X
⑤ 重复执行②③④步,直到分类误差率较低或特征分完了
⑥ 最终所有弱分类器的分类结果加权求和,形成了加法模型F,并进行sign函数完成最终预测分类
好,此刻我认为已经全部理解了
接下来,就是实战!!!
可是目前是二分类,能不能实现多分类呢?多分类的公式又有什么不同呢?
回头再推导,先试试二分类能不能实现
手动代码
哇哦!完美
import math
import numpy as np
import pandas as pd
import random
import warnings
warnings.filterwarnings('ignore')
# 获取所需数据
datas = pd.read_excel('./datas5.xlsx')
important_features = ['推荐类型','专业度', '回复速度']
datas_1 = datas[important_features]
datas_1['Y']=np.where(datas_1.loc[:,'推荐类型']=="高推荐",1,-1) # 高推荐设置为1
datas_1 = datas_1.drop('推荐类型',axis=1)
class Node_1():
def __init__(self,value):
self.value = value
self.select_feat = None
self.sons = {}
# 根据节点,构建一个树
class Tree():
def __init__(self,datas_arg,feat):
self.root = None
self.datas = datas_arg
self.feat = feat
self.em = None
self.am = None
self.Y_predict = []
self.Y = pd.DataFrame(datas_arg['Y'])
self.X = pd.DataFrame(datas_arg[feat])
def get_value_1(self,datas_arg,node_arg=None):
# 明确当前节点数据
node = node_arg
if self.root == None:
node = Node_1(datas_arg)
self.root = node
# 明确当前节点的划分特征、子节点们: 计算各特征划分后的信息增益,并选出信息增益最大的特征
gain_dicts = {}
for i in self.X.columns:
groups = datas_arg.groupby(i)
groups = [groups.get_group(j) for j in set(datas_arg[i])]
if len(groups) > 1: # 特征可分
gain_dicts[i] = self.get_gain(datas_arg,groups,Y_feature)
# 明确停止划分的条件,即停止迭代的条件:无可划分的属性,或是最大的条件熵为0
if (not gain_dicts) or max(gain_dicts.values()) == 0:
return
select_feat = max(gain_dicts,key=lambda x:gain_dicts[x])
node.select_feat = select_feat
group_feat = datas_arg.groupby(select_feat)
for j in set(datas_arg[select_feat]):
node_son_value = group_feat.get_group(j)
node_son = Node_1(node_son_value)
node.sons[j] = node_son
for key,node_single in node.sons.items():
self.get_value_1(node_single.value,node_single)
# 获取熵
def get_ent(self,datas,feature):
p_values = datas[feature].value_counts(normalize=True)
p_updown = 1/p_values
ent = (p_values*(p_updown).apply(np.log2)).sum()
return ent
# 获取条件熵
def get_condition_ent(self,datas_list,feature):
proportions = [len(i) for i in datas_list]
proportions = [i/sum(proportions) for i in proportions]
ents = [self.get_ent(i,feature) for i in datas_list]
condition_ent = np.multiply(ents,proportions).sum()
return condition_ent
# 获取信息增益
def get_gain(self,datas_all,datas_group,feature):
condition_ent = self.get_condition_ent(datas_group,feature)
ent_all = self.get_ent(datas_all,feature)
gain = ent_all - condition_ent
return gain
# 探访决策树,并进行预测分类
def predict(self,data,root):
if not root.select_feat:
p_values = root.value[Y_feature].value_counts(normalize=True)
self.Y_predict.append(p_values.idxmax())
return
feat = root.select_feat
try:
if data[feat] not in root.sons.keys():
self.Y_predict.append(None)
return
next_node = root.sons[data[feat]]
except:
print(data)
print(root.sons)
raise Exception("错了")
self.predict(data,next_node)
def pre_print(self, root):
if root is None:
return
for key,node_son in root.sons.items():
self.pre_print(node_son)
def func(self,data):
self.predict(data,self.root)
max_feat_num = datas_1.shape[1]
max_data_num = datas_1.shape[0]
W = [1/max_data_num for i in range(max_data_num)]
FM = [0 for i in range(max_data_num)]
important_features.remove('推荐类型')
Y_feature = "Y"
datas_1['weight'] = W
datas_1['FM'] = FM
for index,feat in enumerate(important_features):
# 根据数据权重,随机抽取待训练的数据
for i in range(len(W)):
if i == 0:
pass
else:
W[i]=W[i-1]+W[i]
rand_datas = []
for i in range(max_data_num):
rand_W = random.uniform(0, max(W))
for j in range(max_data_num):
if rand_W<=W[j]:
rand_datas.append(datas_1.iloc[j])
break
datas = pd.DataFrame(rand_datas)
# 训练单个弱分类器
tree = Tree(datas,feat)
tree.get_value_1(tree.datas)
datas.apply(tree.func, axis=1)
# 计算弱分类器的分类误差率 em
G_x = tree.Y_predict
datas['Y_predict'] = tree.Y_predict
length = len(tree.Y)
em = 0
for i,row in datas.iterrows():
if row['Y_predict'] != row['Y']:
em += row['weight']
W_sum = datas['weight'].sum()
em = em/W_sum
# 计算am,并更新FM
am = 1/2*math.log((1-em)/em,math.e)
# 计算并更新W
Zm = 0
for i,row in datas.iterrows():
row['weight'] = row['weight']*math.exp(-row['Y']*am*row['Y_predict'])
Zm += row['weight']
datas_1.loc[i,'weight'] = row['weight']
datas_1.loc[i,'FM'] += am*row['Y_predict']
datas_1['weight'] = datas_1['weight']/Zm # 归一化
datas_1['FM'] = np.where(datas_1['FM']>=0,1,-1)
accurency = sum(datas_1['FM']==datas_1['Y'])/len(datas_1)
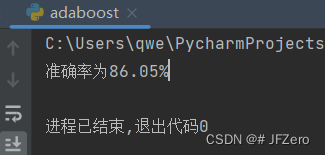
print(f"准确率为{round(accurency*100,2)}%")
放弃对多分类的推导。。。实现后发现,分类效果极其的差。。。。算了算了,不求甚解,翻篇
算了,还是再优化一下adaboost的多分类吧,书越看到后边,越容易急于求成,calm down
关于adaboost的多分类推导,有个阿婆主推导的非常清晰!
adaboost的多分类数学推导
重点还是对多分类的分类结果,更换为二元向量分类结果,类别结果为1,其余结果为 − 1 K − 1 , K 为类别数 -\frac{1}{K-1},K为类别数 −K−11,K为类别数
例如假设共有3种类别:A\B\C
如果某个样本是A类,则对应的二元分类向量结果为
A
:
1
,
B
:
−
1
K
−
1
=
−
1
2
,
C
:
−
1
K
−
1
=
−
1
2
A:1,B:-\frac{1}{K-1}=-\frac{1}{2},C:-\frac{1}{K-1}=-\frac{1}{2}
A:1,B:−K−11=−21,C:−K−11=−21


那个up主真的讲的很清晰,解决了很大的困惑,这样的up主就应该拉到卫城广场上大受褒扬
紧接着,就可以对修改后的Loss函数进行求导,算出am的公式


最后这里的am,我不理解的是,am好像不需要归一化呀,既然不需要归一化,那又为什么去掉这个 ( K − 1 ) 2 K \frac{(K-1)^2}{K} K(K−1)2常数呢?
不过,按我想法,就是am是每个弱分类器的权重,每个弱分类器权重都乘以 ( K − 1 ) 2 K \frac{(K-1)^2}{K} K(K−1)2后的加权结果,对最后的 F m F_m Fm判断并没有影响,因此可以去掉
重点来了,最终Fm输出的预测结果是怎样的呢
Fm最终对单个样本的预测结果是向量,假设有A\B\C三类,则单个样本的Fm输出值为
[预测A类值
F
m
a
F_{ma}
Fma,预测B类值
F
m
b
F_{mb}
Fmb,预测C类值
F
m
c
F_{mc}
Fmc]
选取Fm值最高的那一类作为预测结果
为什么选择Fm值更高的,作为预测类别呢?
下边进行推导
已知
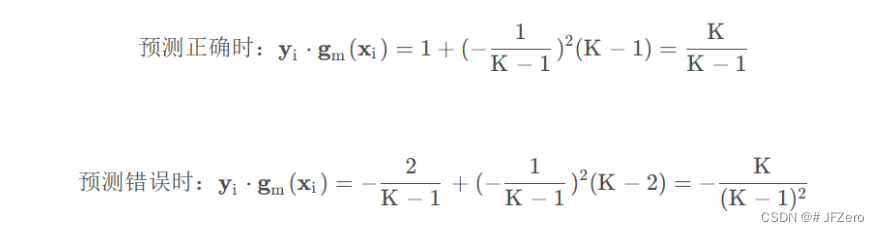
- 每个数据样本的权重更新公式:
-
W
m
+
1
,
i
=
W
m
,
i
∗
e
−
y
i
a
m
G
m
(
x
i
)
Z
m
W_{m+1,i}=\frac{W_{m,i}*e^{-y_ia_mG_m(x_i)}}{Zm}
Wm+1,i=ZmWm,i∗e−yiamGm(xi)
- Z m = ∑ i N W m , i ∗ e − y i a m G m ( x i ) Z_m = ∑_i^NW_{m,i}*e^{-y_ia_mG_m(x_i)} Zm=∑iNWm,i∗e−yiamGm(xi)
-
W
m
+
1
,
i
=
W
m
,
i
∗
e
−
y
i
a
m
G
m
(
x
i
)
Z
m
W_{m+1,i}=\frac{W_{m,i}*e^{-y_ia_mG_m(x_i)}}{Zm}
Wm+1,i=ZmWm,i∗e−yiamGm(xi)
若当前弱分类器预测类别准确,则分类准确的样本权重 W m W_m Wm会降低,分类错误的样本权重 W m W_m Wm会升高
- 当前最新的弱分类器的分类误差率-分类错误样本的权重之和:
- e m = ∑ W m , i I [ y i ≠ G m ( x i ) ] e_m=∑W_{m,i}I[y_i≠G_m(x_i)] em=∑Wm,iI[yi=Gm(xi)],
若当前分类器分类错误更多,则分类错误率em会上升
- 当前最新的弱分类器的权重公式:
-
a
m
=
(
K
−
1
)
2
K
[
l
n
1
−
e
m
e
m
+
l
n
(
K
−
1
)
]
a_m=\frac{(K-1)^2}{K}[ln\frac{1-e_m}{e_m}+ln(K-1)]
am=K(K−1)2[lnem1−em+ln(K−1)]
其实,多分类的a_m公式,同样适用于二分类 - a m = l n 1 − e m e m + l n ( K − 1 ) a_m=ln\frac{1-e_m}{e_m}+ln(K-1) am=lnem1−em+ln(K−1)
-
a
m
=
(
K
−
1
)
2
K
[
l
n
1
−
e
m
e
m
+
l
n
(
K
−
1
)
]
a_m=\frac{(K-1)^2}{K}[ln\frac{1-e_m}{e_m}+ln(K-1)]
am=K(K−1)2[lnem1−em+ln(K−1)]
如果em越大,则a_m越小,如果em越小,则a_m越大
- 当前弱分类器的预测结果,只含一个预测类别为1,其他预测类别为
−
1
K
−
1
-\frac{1}{K-1}
−K−11
例如 G m ( x ) = [ 1 , − 1 K − 1 , − 1 K − 1 , − 1 K − 1 . . . ] G_m(x)=[1,-\frac{1}{K-1},-\frac{1}{K-1},-\frac{1}{K-1}...] Gm(x)=[1,−K−11,−K−11,−K−11...]
则,
当分类准确率越高, a m 越高, G m ( x ) 也越大 a_m越高,G_m(x)也越大 am越高,Gm(x)也越大,则 a m ∗ G m ( x ) 越大 a_m*G_m(x)越大 am∗Gm(x)越大
- 强分类器模型-加法模型
- F m = ∑ m = 1 M a m G m = F m − 1 + a m G m ( X ) F_m=∑^M_{m=1}a_mG_m=F_{m-1}+a_mG_m(X) Fm=∑m=1MamGm=Fm−1+amGm(X)
则,
当分类准确率越高, F m F_m Fm值也越大
- 强分类器的损失函数模型-指数函数模型
- L o s s = ∑ i = 1 N e − y i F m ( x i ) Loss=∑^N_{i=1}e^{-y_iF_m(x_i)} Loss=∑i=1Ne−yiFm(xi)
则,
当分类准确率越高, F m F_m Fm值也越大, L o s s Loss Loss值越小
所以,应该选择 F m F_m Fm值最大的,作为预测结果
那么最终输出的单个样本预测结果向量中:[预测A类值 F m a F_{ma} Fma,预测B类值 F m b F_{mb} Fmb,预测C类值 F m c F_{mc} Fmc]
如果 F m a F_{ma} Fma最大,则最终预测结果为A类
好,思路非常之清晰了!!!!开始动工!!!
之前看其他up主的胡乱思路,搞得自己瞎折腾了仨小时,结果adaboost多分类结果非常差劲
还好世界上,还是有好up主的,很优秀!挽救了每一个想要放弃的人
Python实现时,遇到了一个问题!!!
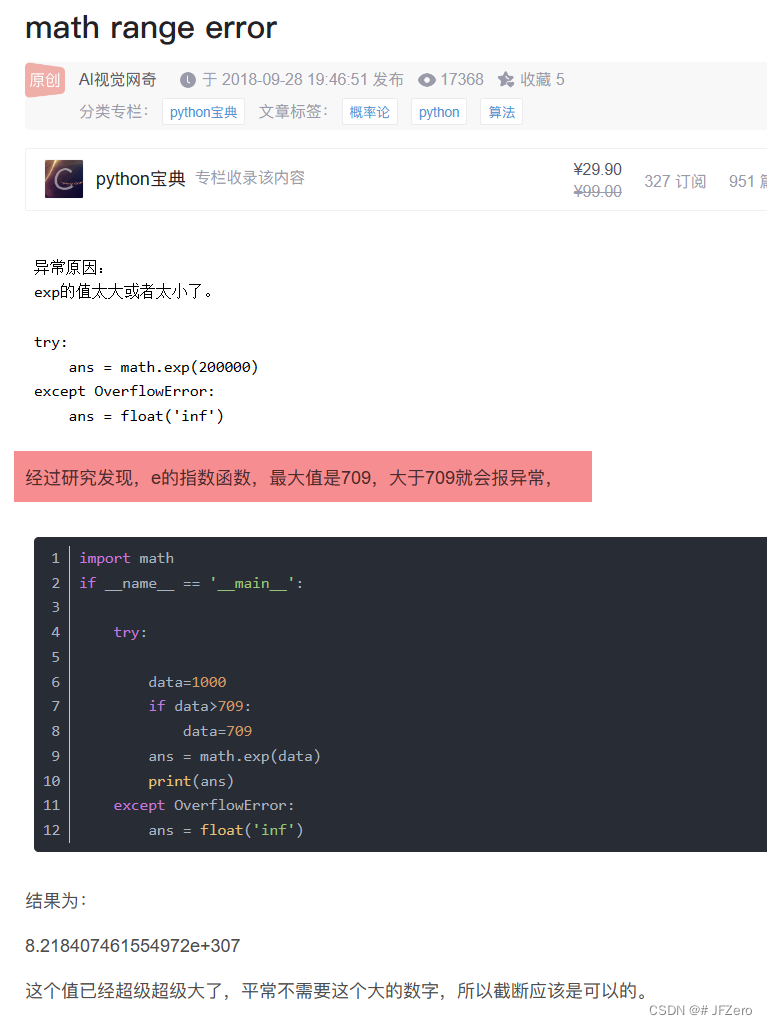
如果特征本身是线性可分的情况下,em为0,则am无法计算!!!!
我原想着,如果em为0,就让am直接赋值1000
但是。。。该死的python报错了
很痛苦,不知道该怎么办,想直接停止,用那个能够完全分类的特征进行分类就好了!
import math
import numpy as np
import pandas as pd
import random
import warnings
warnings.filterwarnings('ignore')
pd.options.display.max_columns = None
pd.options.display.max_rows = None
# 获取所需数据
datas = pd.read_excel('./datas1.xlsx')
important_features = ['推荐类型', '专业度','回复速度','推荐分值']
Y_feature = '推荐类型'
datas_1 = datas[important_features]
max_feat_num = datas_1.shape[1]
max_data_num = datas_1.shape[0]
# 获取多分类的具体类别名称,及创建多个类别的实际二分类结果、强分类器的预测二分类结果
cla = datas_1['推荐类型'].unique()
K = len(cla)
datas_1['Y_pre_final'] = [0 for i in range(max_data_num)]
datas_1['Y']=datas_1['推荐类型']
W = [1/max_data_num for i in range(max_data_num)]
datas_1['weight'] = [i/sum(W) for i in W]
FM = [0 for i in range(max_data_num)]
FM_name = [str(i) for i in cla]
for i in range(K):
datas_1[FM_name[i]] = FM
important_features.remove('推荐类型')
class Node_1():
def __init__(self,value):
self.value = value
self.select_feat = None
self.sons = {}
# 根据节点,构建一个树
class Tree():
def __init__(self,datas_arg,feat):
self.root = None
self.datas = datas_arg
self.feat = feat
self.em = None
self.am = None
self.Y_predict = []
self.Y = pd.DataFrame(datas_arg[Y_feature])
self.X = pd.DataFrame(datas_arg[feat])
def get_value_1(self,datas_arg,node_arg=None):
# 明确当前节点数据
node = node_arg
if self.root == None:
node = Node_1(datas_arg)
self.root = node
# 明确当前节点的划分特征、子节点们: 计算各特征划分后的信息增益,并选出信息增益最大的特征
gain_dicts = {}
for i in self.X.columns:
groups = datas_arg.groupby(i)
groups = [groups.get_group(j) for j in set(datas_arg[i])]
if len(groups) > 1: # 特征可分
gain_dicts[i] = self.get_gain(datas_arg,groups,Y_feature)
# 明确停止划分的条件,即停止迭代的条件:无可划分的属性,或是最大的条件熵为0
if (not gain_dicts) or max(gain_dicts.values()) == 0:
return
select_feat = max(gain_dicts,key=lambda x:gain_dicts[x])
node.select_feat = select_feat
group_feat = datas_arg.groupby(select_feat)
for j in set(datas_arg[select_feat]):
node_son_value = group_feat.get_group(j)
node_son = Node_1(node_son_value)
node.sons[j] = node_son
for key,node_single in node.sons.items():
self.get_value_1(node_single.value,node_single)
# 获取熵
def get_ent(self,datas,feature):
p_values = datas[feature].value_counts(normalize=True)
p_updown = 1/p_values
ent = (p_values*(p_updown).apply(np.log2)).sum()
return ent
# 获取条件熵
def get_condition_ent(self,datas_list,feature):
proportions = [len(i) for i in datas_list]
proportions = [i/sum(proportions) for i in proportions]
ents = [self.get_ent(i,feature) for i in datas_list]
condition_ent = np.multiply(ents,proportions).sum()
return condition_ent
# 获取信息增益
def get_gain(self,datas_all,datas_group,feature):
condition_ent = self.get_condition_ent(datas_group,feature)
ent_all = self.get_ent(datas_all,feature)
gain = ent_all - condition_ent
return gain
# 探访决策树,并进行预测分类
def predict(self,data,root):
if not root.select_feat:
p_values = root.value[Y_feature].value_counts(normalize=True)
self.Y_predict.append(p_values.idxmax())
return
feat = root.select_feat
try:
if data[feat] not in root.sons.keys():
self.Y_predict.append(None)
return
next_node = root.sons[data[feat]]
except:
print(data)
print(root.sons)
raise Exception("错了")
self.predict(data,next_node)
def pre_print(self, root):
if root is None:
return
for key,node_son in root.sons.items():
self.pre_print(node_son)
def func(self,data):
self.predict(data,self.root)
for index,feat in enumerate(important_features):
# 根据数据权重,随机抽取待训练的数据
W = list(datas_1['weight'])
for i in range(len(W)):
if i == 0:
pass
else:
W[i]=W[i-1]+W[i]
rand_datas = []
for i in range(max_data_num):
rand_W = random.uniform(0, max(W))
for j in range(max_data_num):
if rand_W<=W[j]:
rand_datas.append(datas_1.iloc[j])
break
datas = pd.DataFrame(rand_datas)
# 训练单个弱分类器
tree = Tree(datas,feat)
tree.get_value_1(tree.datas)
datas.apply(tree.func, axis=1)
# 计算弱分类器的分类误差率 em
G_x = tree.Y_predict
datas['Y_predict'] = tree.Y_predict
em = 0
for i,row in datas.iterrows():
if row['Y_predict'] != row['Y']:
em += row['weight']
if em == 0:
linedivision = True
break
else:
# 计算am,并更新FM
am = math.log((1-em)/em,math.e)+math.log(K-1,math.e)
# 计算并更新W,根据多分类结果,构建二分类预测向量
for i,row in datas.iterrows():
G_temp = []
Y_temp = []
temp = 0
for c in cla:
if row['Y_predict']==c:
G_temp.append(1)
datas_1.loc[i,c] += am * 1
else:
G_temp.append(-1/(K-1))
datas_1.loc[i, c] += am * -1/(K-1)
if row['Y']==c:
Y_temp.append(1)
else:
Y_temp.append(-1/(K-1))
temp = np.dot(G_temp,Y_temp)
try:
row['weight'] = row['weight']*math.exp(am*temp)
except:
print(math.exp(temp*am))
datas_1.loc[i,'weight'] = row['weight']
del G_temp, Y_temp
datas_1['weight'] = datas_1['weight']/sum(datas_1['weight'])
if linedivision:
tree = Tree(datas_1, feat)
tree.get_value_1(tree.datas)
datas_1.apply(tree.func, axis=1)
datas_1['预测Y'] = tree.Y_predict
else:
datas_1['预测Y']=datas_1[FM_name].idxmax(axis=1)
accurency = sum(datas_1['预测Y']==datas_1['Y'])/len(datas_1)
print(f"准确率为{round(accurency*100,2)}%")

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









