







SFT的全称及基本定义如下:
Supervised Fine-Tuning(监督微调) :
SFT是一种在预训练大模型基础上,使用有标签的特定任务数据进一步优化模型的方法。通过这种方式,模型能够将通用语言理解能力迁移到具体任务中(如问答、翻译等),显著提升任务表现。
如果把预训练大模型比作一个天赋异禀的荒野探险家,那么SFT(监督微调)就像是给它佩戴了一副专业护目镜。这副眼镜的镜片由海量标注数据打磨而成,能让原本"视力5.0"的通用AI,瞬间获得透视特定任务迷雾的超能力。
- 核心思想:
预训练模型(如GPT、BERT)已在海量无标注数据上学习了语言规律,但缺乏对特定任务的针对性。SFT通过引入带标签的任务数据,调整模型参数,使其适应目标任务的输入-输出模式。
- 数据格式:
通常为三元组:input(输入内容)、instruction(任务指令)、output(期望输出)。例如,输入为“巴黎是哪个国家的首都?”,指令为“回答地理问题”,输出为“法国”。
SFT在大模型训练中的作用主要分为如下几点:
提升模型性能:通过在特定任务的数据上进行微调,SFT可以显著提高模型在该任务上的表现。例如,在文本生成、问答系统、情感分析等任务中,SFT能够使模型更好地理解和处理特定输入类型,从而提供更高质量的输出。
减少标注数据需求:预训练模型已经在大量数据上进行过训练,因此SFT通常只需要较少的标注数据即可达到良好的效果。
灵活性:SFT可以应用于各种任务,如文本分类、情感分析、机器翻译等,具有较高的灵活性。将通用模型转化为专用模型(如客服对话、医疗诊断)。
优化模型输出:SFT通过调整模型输出层的参数,使模型输出更符合特定任务需求。例如,通过优化模型的Softmax分布,可以提升文本生成的自然度和对话系统的上下文理解能力。
优势:
- 高效性:相比从头训练,SFT节省90%以上的计算资源。
- 灵活性:支持多种任务(文本分类、图像生成等)。
- 低过拟合风险:仅微调部分参数,保留预训练的通用能力。
典型训练流程
SFT的流程可分为以下步骤(以自然语言处理任务为例):
- 数据预处理:
清洗数据,确保输入-输出对齐。 对文本进行分词、填充或截断(如限制序列长度为2048)。
- 选择预训练模型:
常用基座模型:GPT-3、Llama、Qwen等。
- 监督微调:
优化目标:通常为“Next Token Prediction”(预测下一个词)。
关键参数:学习率:逐步升温(如从0升至2e-6),避免初始震荡。
批大小:128-256,平衡显存与梯度稳定性。
正则化:权重衰减(0.1)、Dropout(0.1)防止过拟合。
评估与部署:
使用验证集计算准确率、F1分数等指标。 选择最佳模型快照部署至生产环境。
代码示例:
主流框架如HuggingFace的SFT代码示例可以通过HuggingFace的trl模块实现。具体步骤包括安装并导入相关库(如Transformers库、Torch库和Datasets库),加载预训练模型和分词器,加载并处理特定任务的数据集,定义训练参数并训练模型。例如,可以使用Bert、GPT-2模型作为预训练模型,IMDB数据集进行文本分类任务,并通过反向传播算法更新模型参数。
以下是一个使用Hugging Face Transformers和TRL库进行SFT的简化示例:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from trl import SFTTrainer
from datasets import load_dataset
# 加载预训练模型和分词器
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
# 加载数据集(示例:Alpaca指令数据集)
dataset = load_dataset("tatsu-lab/alpaca", split="train")
# 定义训练参数
training_args = TrainingArguments(
output_dir="./sft_output",
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=2e-5,
warmup_steps=500,
weight_decay=0.1,
fp16=True # 使用混合精度训练
)
# 初始化SFT训练器
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
train_dataset=dataset,
dataset_text_field="text", # 数据集中文本字段名
max_seq_length=1024
)
# 开始训练
trainer.train()
# 保存微调后的模型
trainer.save_model("./sft_finetuned_llama")
更详细的参数设置以及训练准备流程示例如下,包含了数据集的准备、模型的加载、训练参数的设置以及训练过程的启动。
import torch
from transformers import Trainer, TrainingArguments, AutoModelForSequenceClassification, AutoTokenizer
**定义训练参数**
training_args = TrainingArguments(
output_dir='./output_model', # 模型保存目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=8, # 每个设备的训练批次大小
per_device_eval_batch_size=8, # 每个设备的评估批次大小
warmup_steps=500, # 学习率预热步数
weight_decay=0.01, # 权重衰减
logging_dir='./logs', # 日志保存目录
logging_steps=10, # 日志记录频率
evaluation_strategy="steps", # 评估策略
eval_steps=500, # 每隔多少步进行一次评估
save_total_limit=2, # 限制保存的模型检查点数量
load_best_model_at_end=True, # 训练结束时加载最佳模型
metric_for_best_model="accuracy", # 用于选择最佳模型的指标
greater_is_better=True # 指定指标越大越好
)
**加载预训练模型和分词器**
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
**假设我们有一个数据集类 `MyDataset`**
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_length):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_length,
return_token_type_ids=False,
padding='max_length',
return_attention_mask=True,
return_tensors='pt',
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
**创建数据集实例**
train_texts = ["example text 1", "example text 2"]
train_labels = [0, 1]
train_dataset = MyDataset(train_texts, train_labels, tokenizer, max_length=128)
**创建Trainer实例并开始训练**
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
trainer.train()
整体的流程
预训练模型 → 加载任务数据 → 微调模型参数 → 评估性能 → 部署优化后的模型
总结
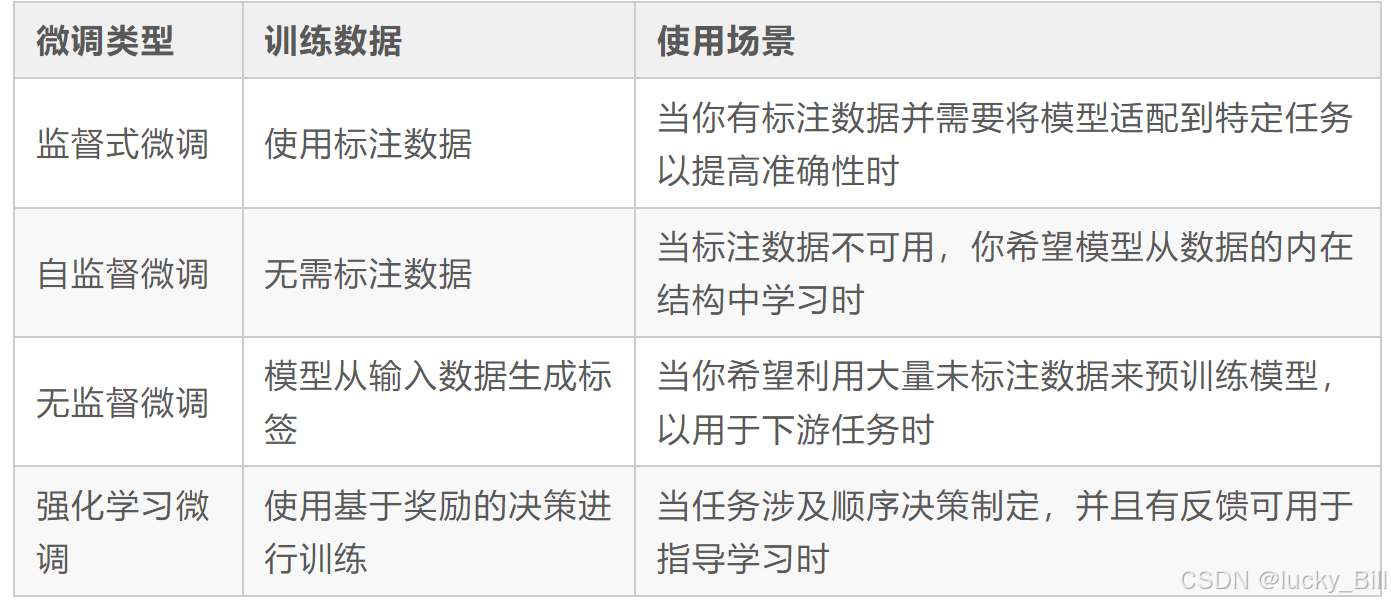
SFT是大模型落地的关键技术,通过“预训练+微调”的范式,将通用能力转化为垂直任务的高性能解决方案。开发者可借助Hugging Face等框架快速实现SFT流程,同时需关注数据质量、超参数调优等细节以提升效果。

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









