




参考
【数据结构1-3】集合 - 题单 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
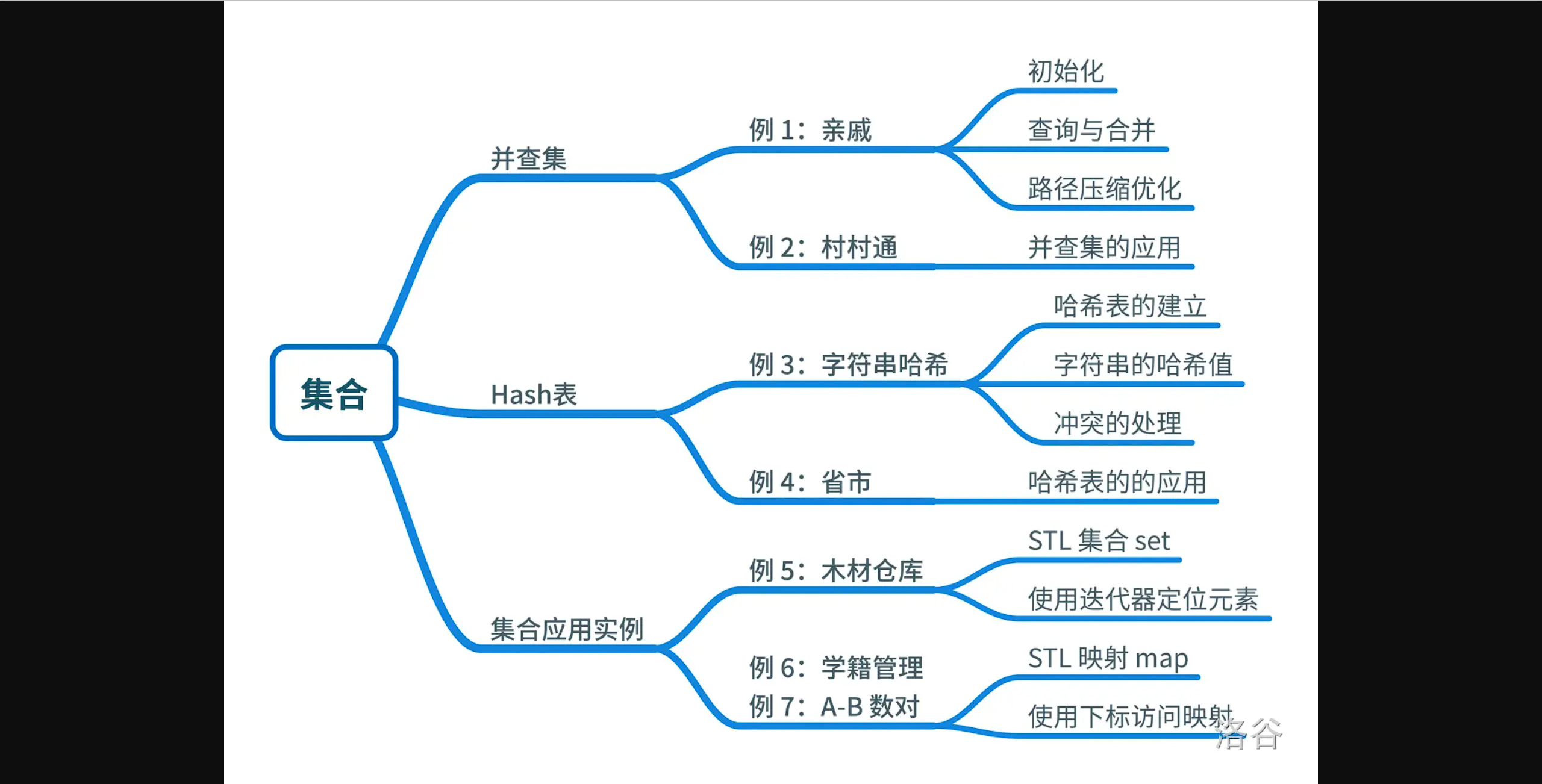
- P1551 亲戚
- P1536 村村通
- P3370 【模板】字符串哈希
- P3405 [USACO16DEC] Cities and States S
- P5250 【深基17.例5】木材仓库
- P5266 【深基17.例6】学籍管理
- P1102 A-B 数对
- P1918 保龄球
- P1525 [NOIP2010 提高组] 关押罪犯
- P1621 集合
- P1892 [BOI2003] 团伙
- P1955 [NOI2015] 程序自动分析
- P4305 [JLOI2011] 不重复数字
- P3879 [TJOI2010] 阅读理解
- P2814 家谱
并查集
P1551 亲戚
一开始自己写了一下,写的不好很多判断还不简洁,还TLE
并查集递归版有个很妙的点对应不递归的路径压缩,就是每次都修改找到的当前点的祖先值,由于递归最终返回的就是最最祖先的祖先,所以寻找路径上的所有点都会被更正(好牛)。
不递归版的路径压缩就是先找到祖先,然后再找一遍路径,并且修改祖先值(注意要用t来临时存当前节点的下一个节点,否则路就断了)
并入的时候就要找祖先,找祖先的时候就会压缩路径,所以一气呵成。
package _1_3;
import java.util.Scanner;
public class P1551 {
private static int[] fa;
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
int p = scanner.nextInt();
fa = new int[n + 1];
// 初始化的时候所有的节点都是一个只有自己的集合(有效避免判断是否被加入关系网中)
for (int i = 1; i <= n; i++) {
fa[i] = i;
}
// 并入
for (int i = 1; i <= m; i++) {
int p1 = scanner.nextInt();
int p2 = scanner.nextInt();
fa[find1(p1)] = find1(p2);
}
for (int i = 1; i <= p; i++) {
int p1 = scanner.nextInt();
int p2 = scanner.nextInt();
if (find1(p1) == find1(p2)) {
System.out.println("Yes");
} else {
System.out.println 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









