







1、常用网址:
MRCIEU GWAS/IEU数据库:(IEU OpenGWAS project)结合“TwoSampleMR”包
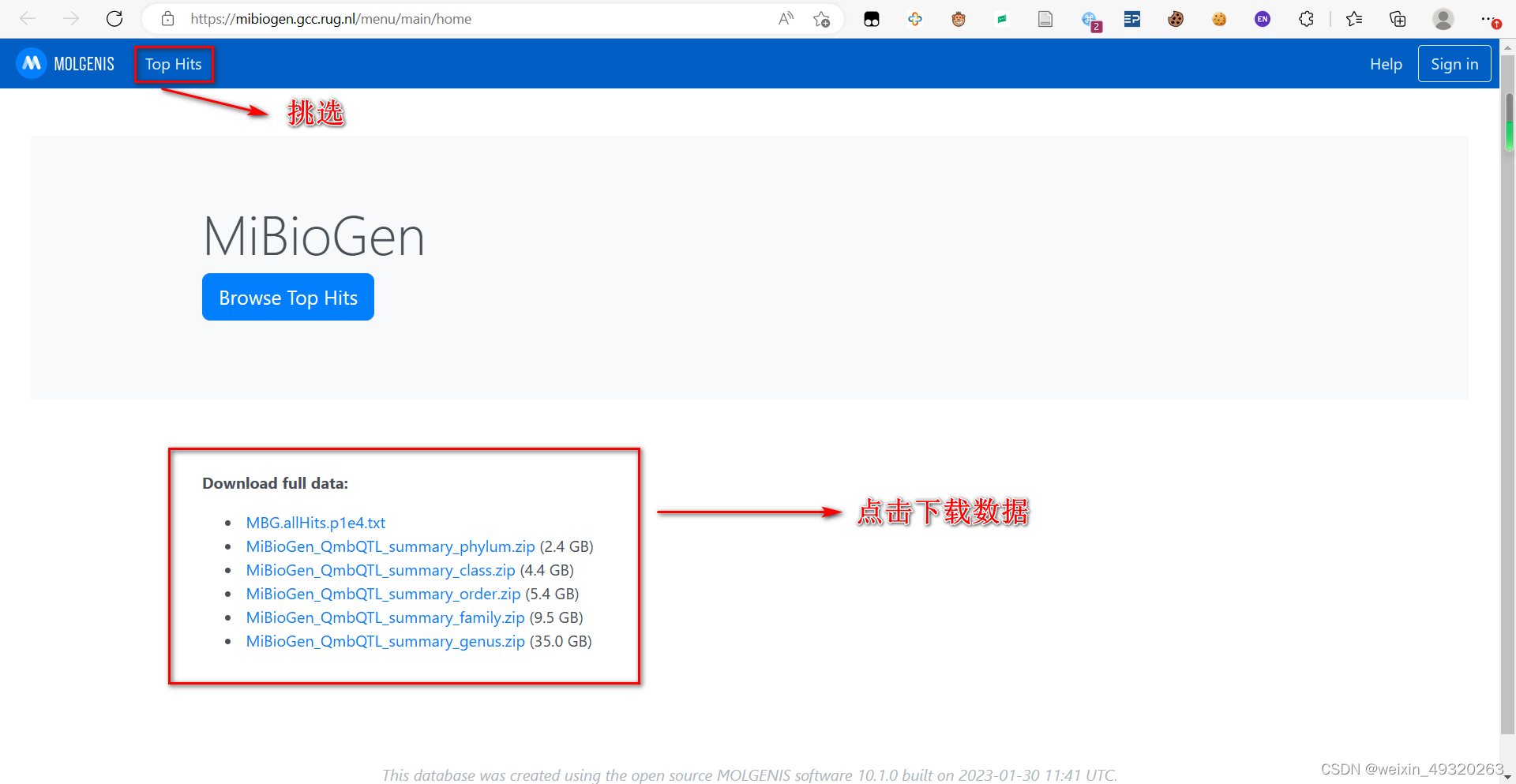
MiBioGen肠道菌群数据库:(MiBioGen)
FinnGen数据库:(Access results | FinnGen)
UK biobank(http://www.nealelab.is/uk-biobank)
GWAS Catalog (https://www.ebi.ac.uk/gwas/)
2、具体操作:
IEU数据库
在搜索框内检索疾病-以colon cancer为例
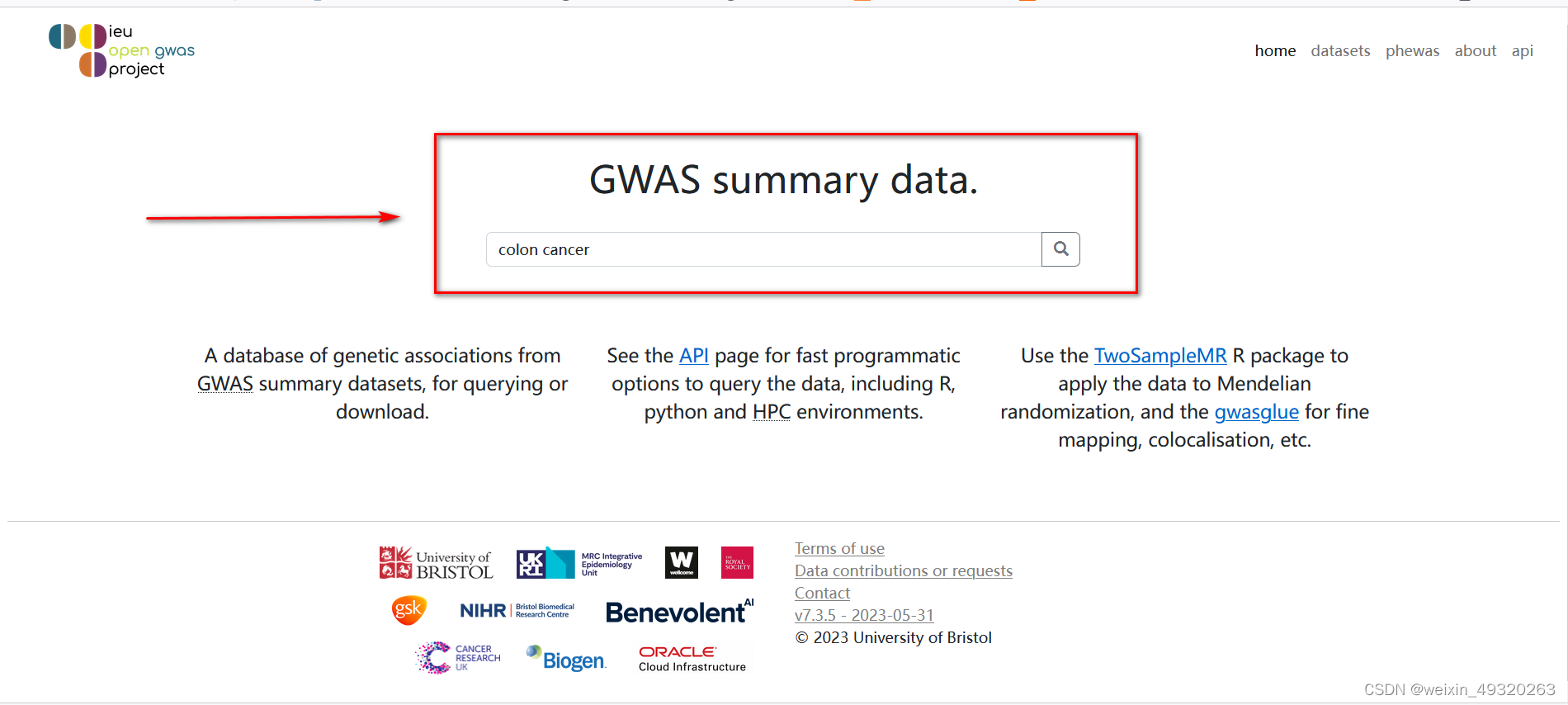
选择需要下载的数据
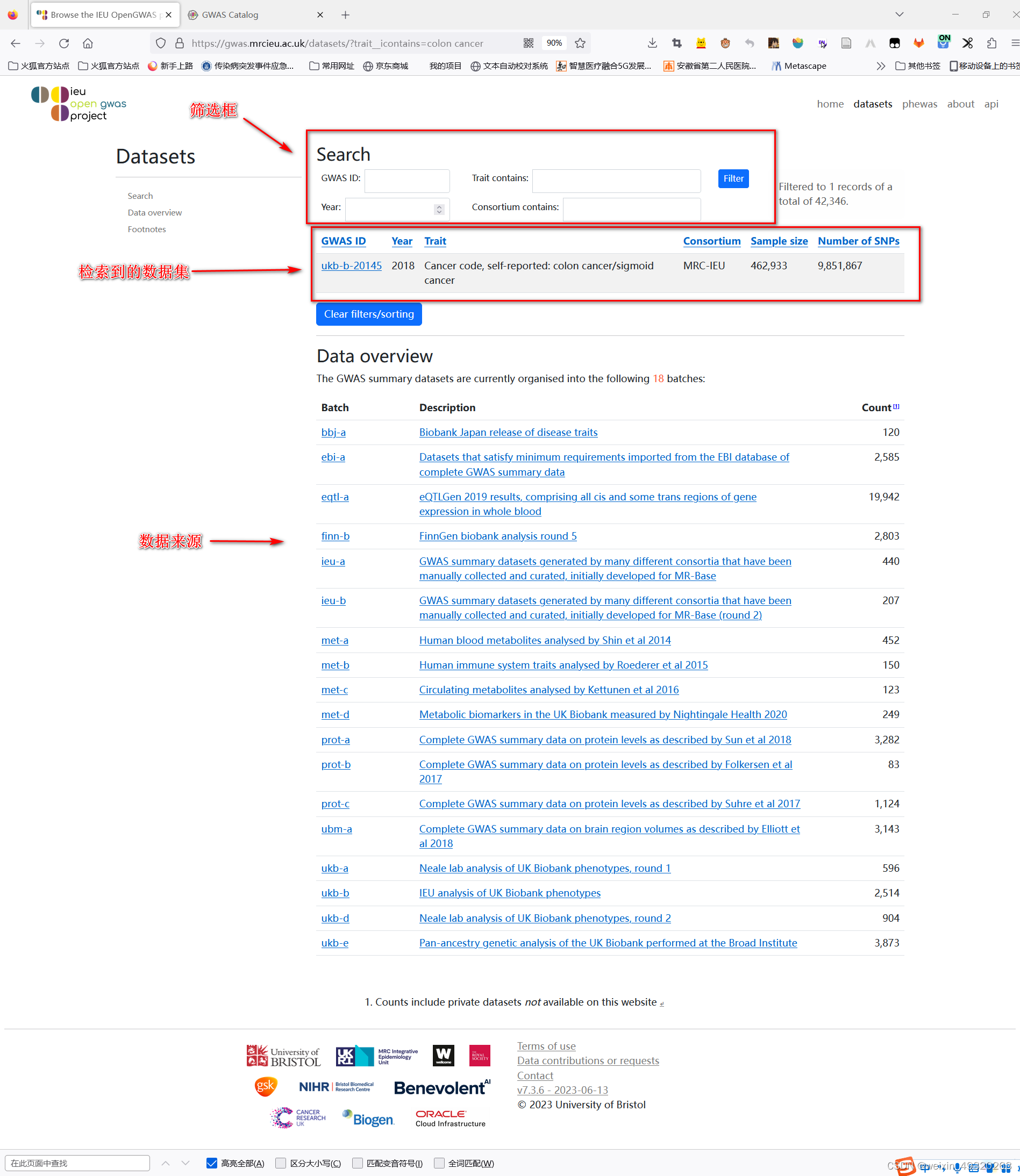
打开一个数据集:GWAS ID:ukb-b-20145
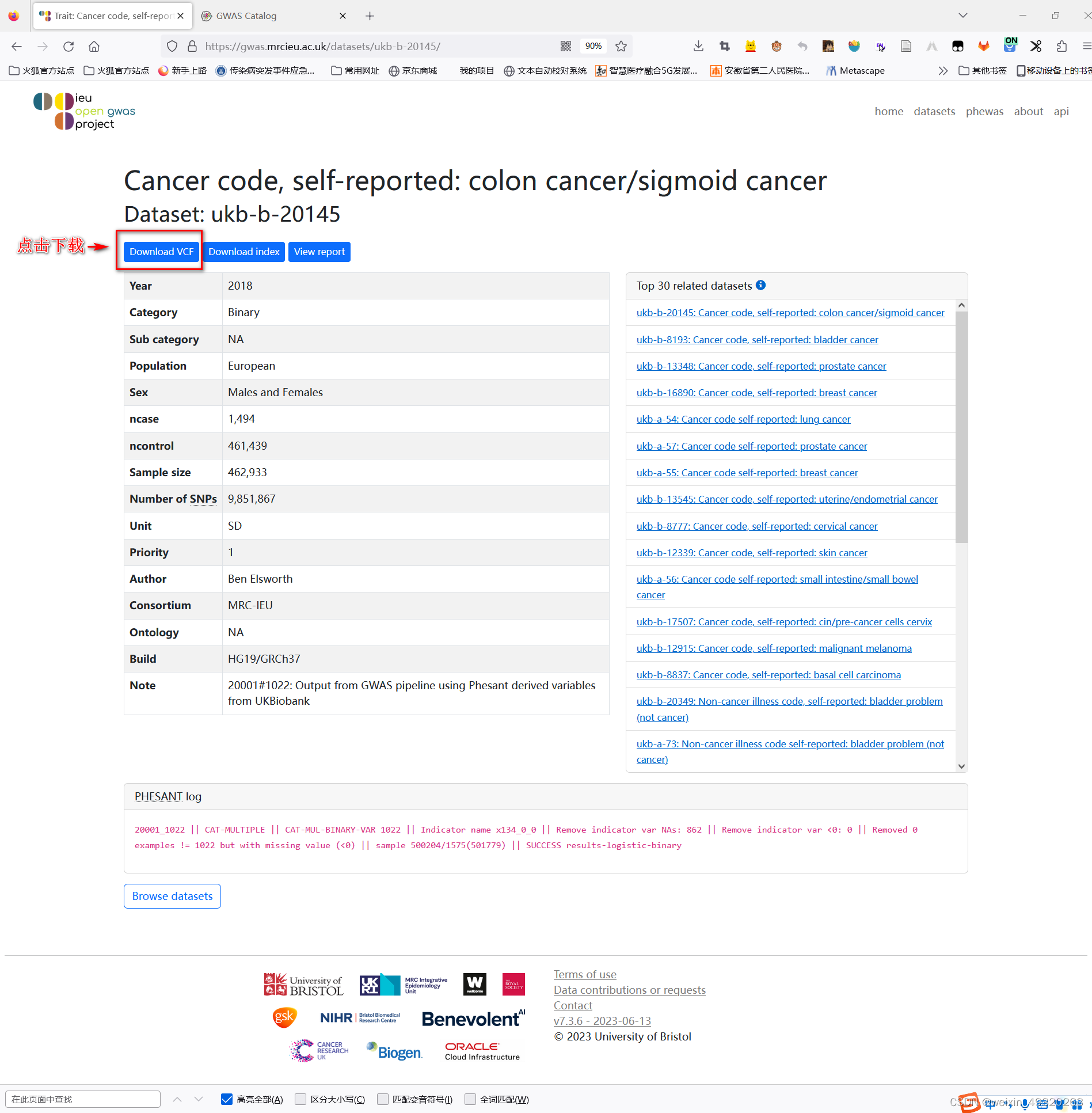
读取下载的文件
#清空
rm(list=ls())
gc()
#设置工作目录
setwd("D:\\GWAS\\IEU数据库")
#读取文件
# install.packages("vcfR")
data <- vcfR::read.vcfR("ukb-b-20145.vcf.gz") #读取VCF文件
gt <- data.frame(data@gt)#ES代表beta值、SE代表se、LP代表-log10(P值)、AF代表eaf、“ID”代表SNP的ID
dat <- as.character(unlist(strsplit(gt$UKB.b.20145, split = ":")))#strsplit切分;unlist解开
fix<-data.frame(data@fix)#为SNP位点的基本信息
#转化为data.frame
matrix<-matrix(data=dat,ncol=5,byrow=T)
frame<-data.frame(matrix)
colnames(frame)<-c("ES","SE","LP","AF","ID")MiBioGen肠道菌群数据库:
P值设定:
作为暴露时P值设定为1e-5(0.00001)或者5e-8(0.00000005)
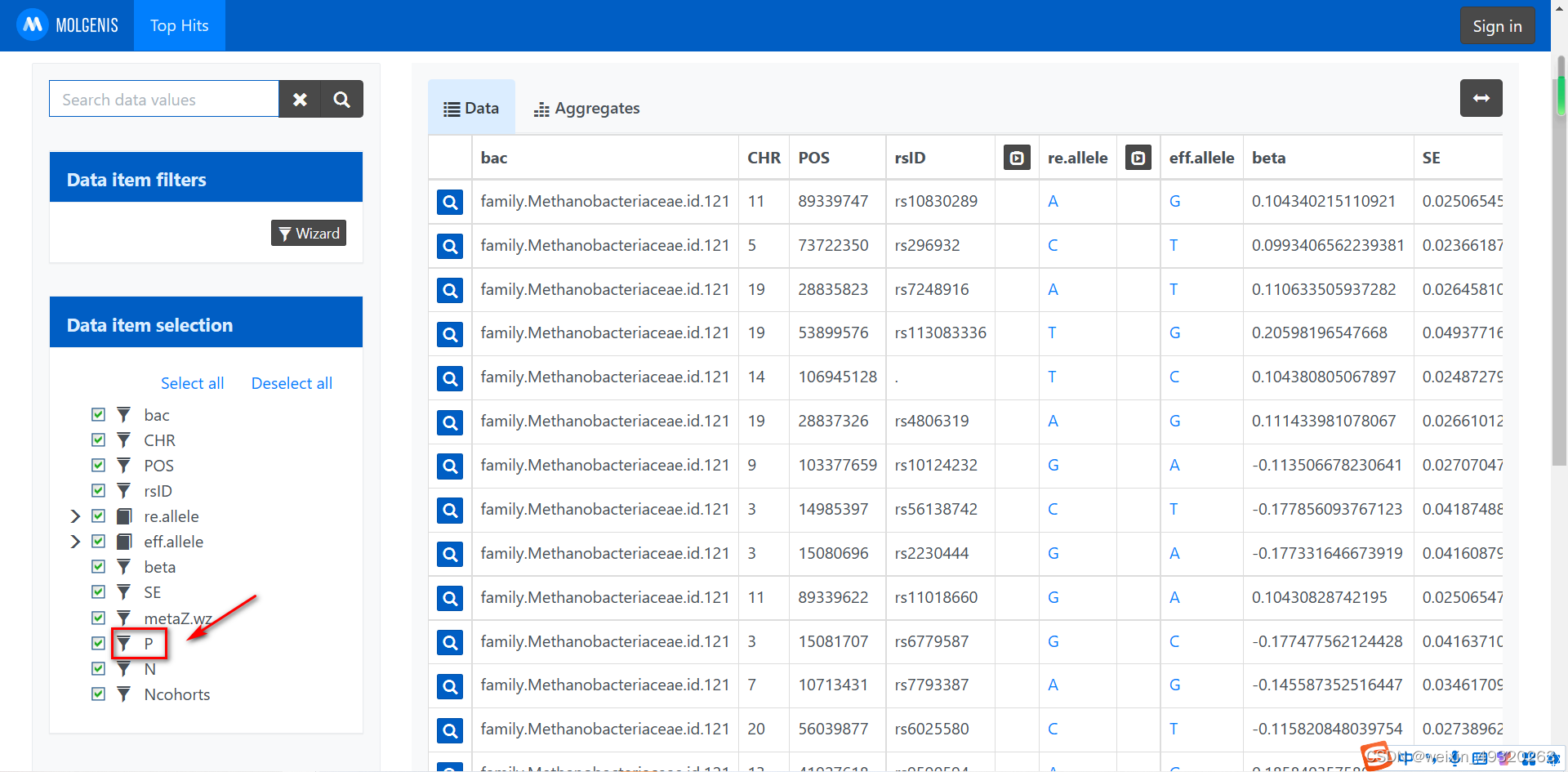
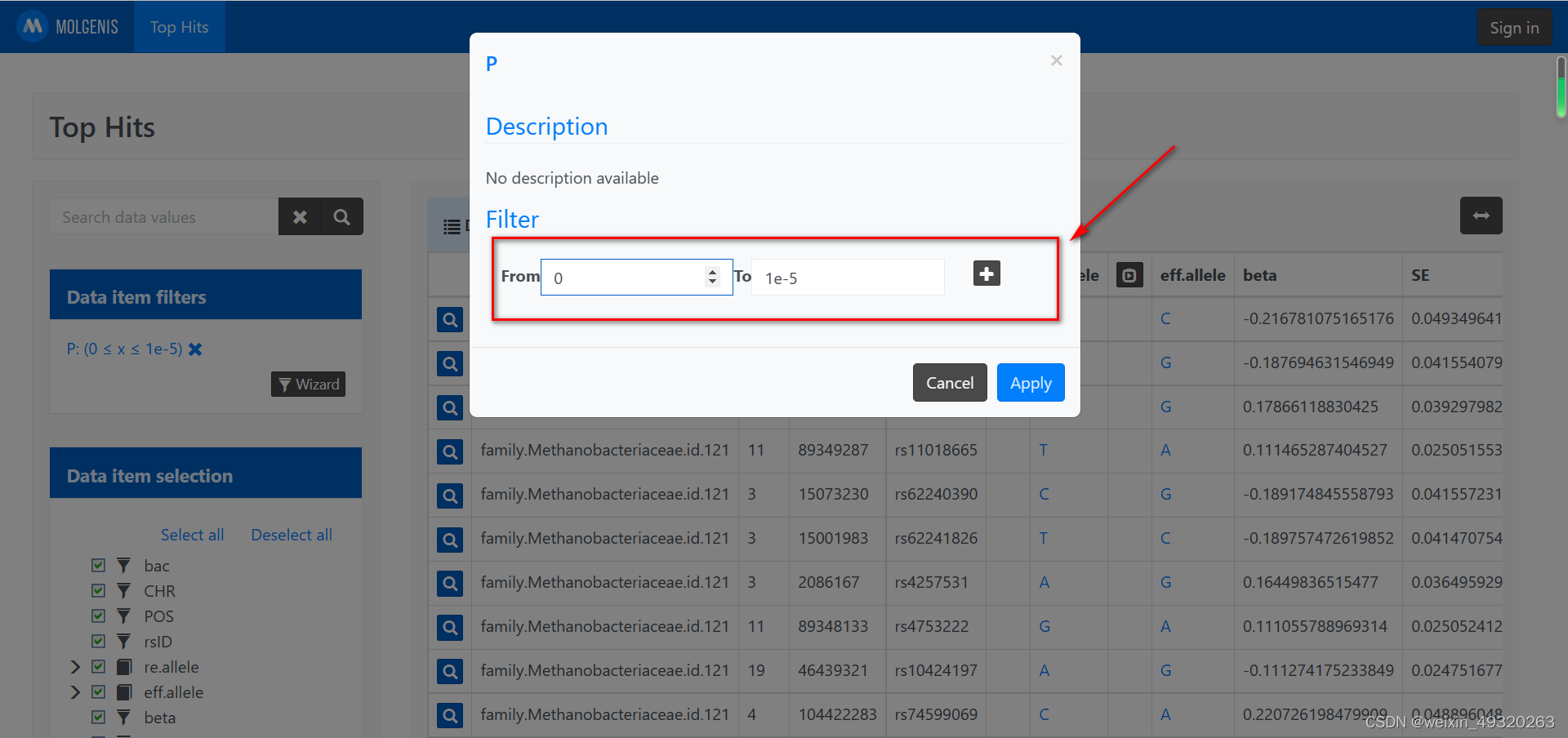
作为结局时P值设定为5e-5(0.00000005)
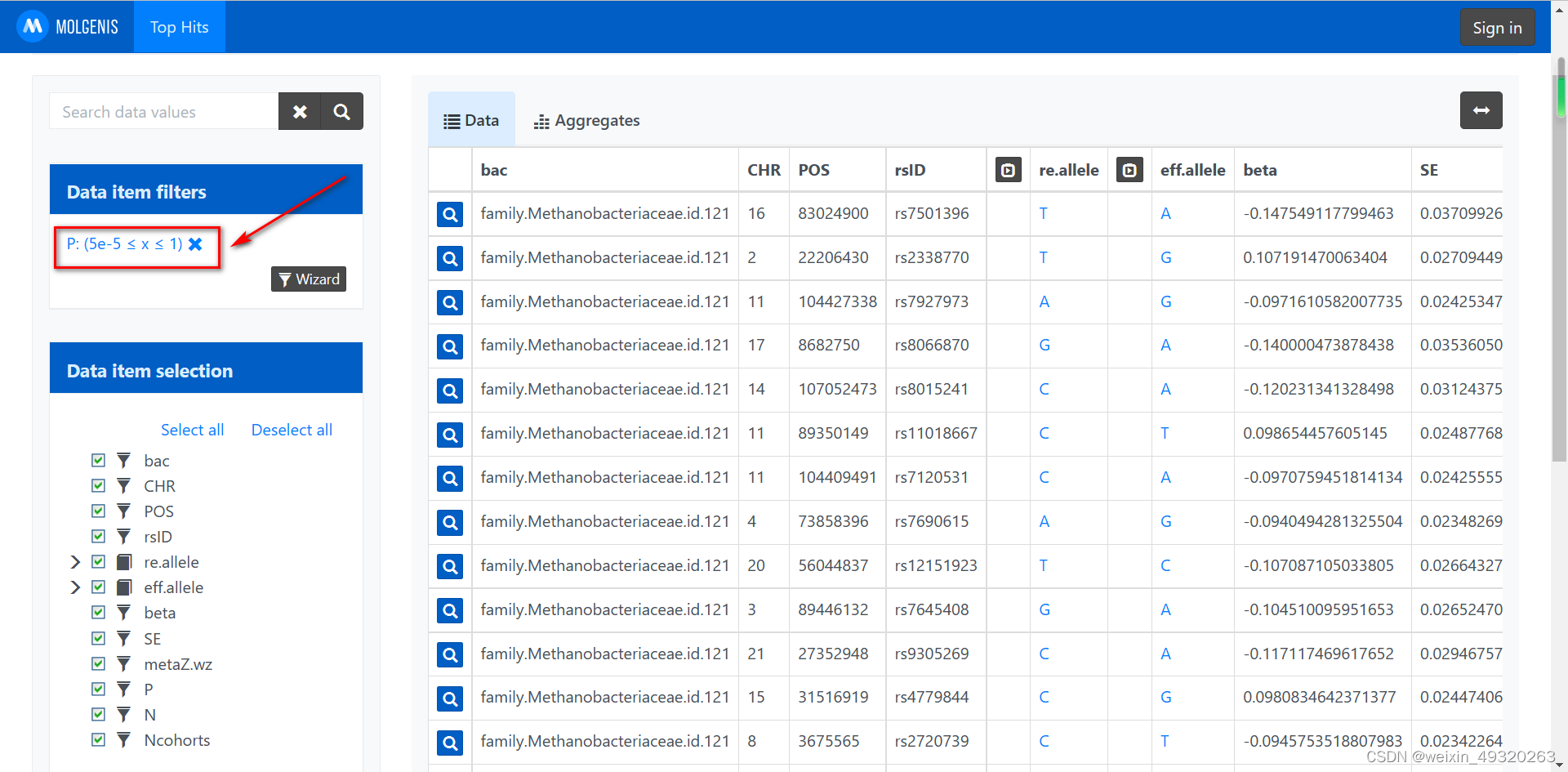
3、注意事项:
仔细阅读不同GWAS数据的注释信息
4、R包
#gwasrapidd包使用简介
#参考文献:http://mirrors.pku.edu.cn/CRAN/web/packages/gwasrapidd/index.html
library(gwasrapidd)
my_studies<-get_studies(efo_trait = 'colorectal cancer')#查询colorectal cancer相关研究
my_associations <- get_associations(study_id = my_studies@studies$study_id)#查询colorectal cancer相关SNP
dplyr::filter(my_associations@associations, pvalue < 1e-6) %>% # 依据P值进行筛选
tidyr::drop_na(pvalue) %>% #drop_na 函数去掉所有含有缺失值的记录
dplyr::pull(association_id) -> association_ids # 提取关联 ID 列(命名为 association_id),最后将提取出来的关联 IDs 存储在一个名为 association_ids 的变量中。
my_associations2 <- my_associations[association_ids]#提取显著SNP#ieugwasr包使用简介
#参考文献:https://mrcieu.github.io/ieugwasr/articles/guide.html
library(ieugwasr)
ieuinform<-gwasinfo('ieu-a-2')
#从特定研究中提取特定关联
bian<-associations(variants=c("rs123", "7:105561135"), id=c("ieu-a-2", "ieu-a-7"))
#从特定研究中获取tophits
tophit<-tophits(id="ieu-a-2")
#MendelianRandomization包使用简介
#参考文献:http://127.0.0.1:15009/doc/html/Search?objects=1&port=15009
library(MendelianRandomization)
mr_allmethods(mr_input(bx = ldlc, bxse = ldlcse,
by = chdlodds, byse = chdloddsse),
method="main", iterations = 100)

















 7271
7271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









