







面向康复工程的脑电信号分析和判别模型
文章目录
摘要
大脑是……,一句话介绍背景,引入通过机器学习和数据挖掘,对大量数据进行训练学习从而找出规律进行分类识别,对数据进行反复的训练和测试有利于进一步提高识别精准率,为临床治疗提供重要的辅助作用。
借助于数据预处理,支持向量机、随机森林、卷积神经网络等机器学习方法就目标识别、通道选择、样本训练和测试、睡眠分期预测问题进行了数学建模和编程尝试,以求更好的结合实际解决问题。
问题一先进行数据处理,然后比较三种机器学习算法(支持向量机、随机森林、卷积神经网络)在训练集上训练,在测试集上测试的效果,选择一种方法对测试数据进行测试,得出结果。
问题二使用卷积神经网络算法进行单个被试者通道选择设计,利用卷积核权重来衡量20个通道的重要程度,针对单个个体进行特定分析,将权重值较高的通道筛选出来,选出一组最优通道,验证最优通道组合适合所有受试者。
问题三主要使用神经网络和支持向量机两种方法对睡眠分期进行预测,选用效果更好的支持向量机设计预测模型进行训练,得出结果。
一、问题重述
1.1 问题背景
根据题目所给内容,进行改写,换成更加详细的语言进行介绍。
查阅资料,说明此类型题目用到的方法大有哪些。

1.2 问题分析
有四个问题,分为五段进行写。
第一段总写结合借助于数据挖掘知识对数据进行分析和处理,寻找背后的规律,找出合适的机器学习方法对待识别目标进行精准识别,进一步解决四个问题。
问题一:根据所给题目进行改写。
问题二:……
问题三:……
问题四:以上全部根据所给题目进行重述即可。

二、模型假设与符号说明
2.1 模型基本假设
对数据集进行说明:
假设一:每一个文件指的是什么,统称什么。
假设二:在无噪声干扰下,人类脑电信号特征是类似的。

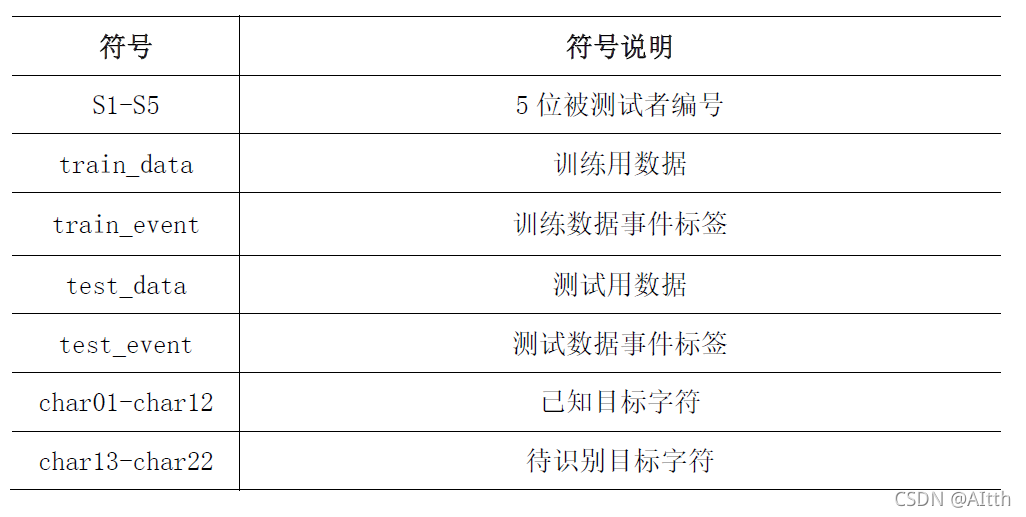
2.2 模型符号说明
表格形式;
三、数据预处理
先进行描述

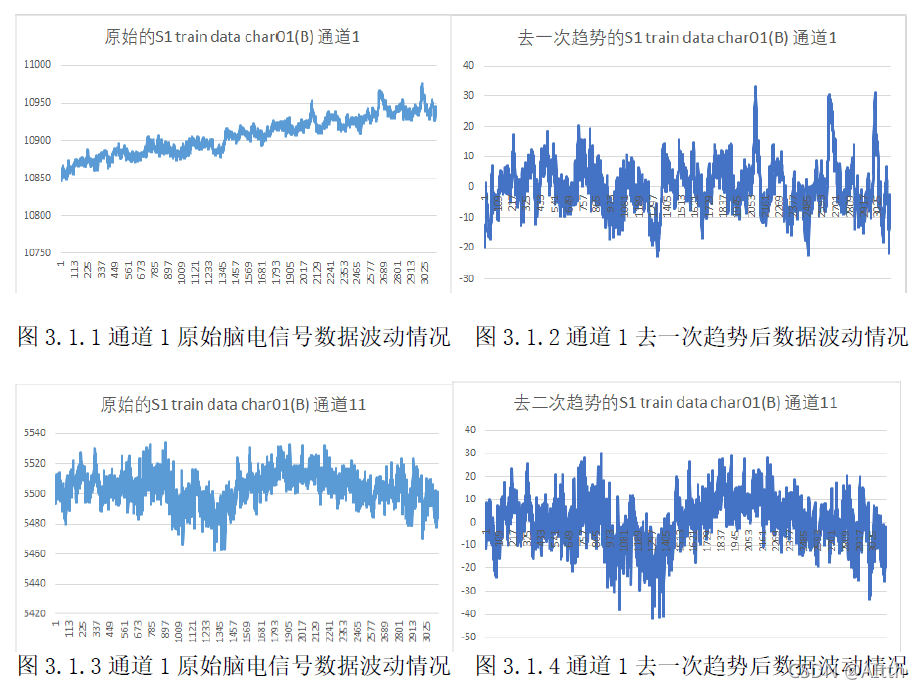
3.1 去趋势
数据去趋势就是对数据减去一条最优(最小二乘)的拟合直线、平面或曲面,使去趋势后的数据均值为零。借助于Matlab软件对数据进行去趋势处理,运用Detrend函数进行一次函数拟合和二次函数拟合来分析效果。放出来结果图。
3.2 滤波
滤波处理主要是借助于eeglab软件,写出操作过程和结果图。
3.3 不平衡样本的重采样
训练二分类模型时,正负样本数不均衡,结果会不好。针对不平衡数据样本,主要通过重采样的方法对数据集进行平衡,先随机采样,然后将数据分为训练集和测试集,通过增加正训练样本数和减少负样本数使不平衡样本分布变平衡,从而提高分类器对正样本的识别率。
四、问题一:模型建立与求解
4.1 L2正则化
在模型训练过程中,由于模型的复杂程度较高,很容易出现过拟合情况,由于模型从训练集的噪音数据中学习了过多的细节,最终导致模型在未知数据上的性能不好,就运算结果来看会出现训练误差很小而测试误差很大的情况。
L2 正则化是指权值向量w中各个元素的平方和然后再求平方根,针对过拟合这一现象,L2 正则化处理可以很好地解决这一问题,主要是通过对最小化经验误差函数添加约束(先验知识),在优化误差函数的时候倾向于选择满足约束的梯度减少的方向,使最终的解倾向于符合先验知识进行调整,以消除奇异性。
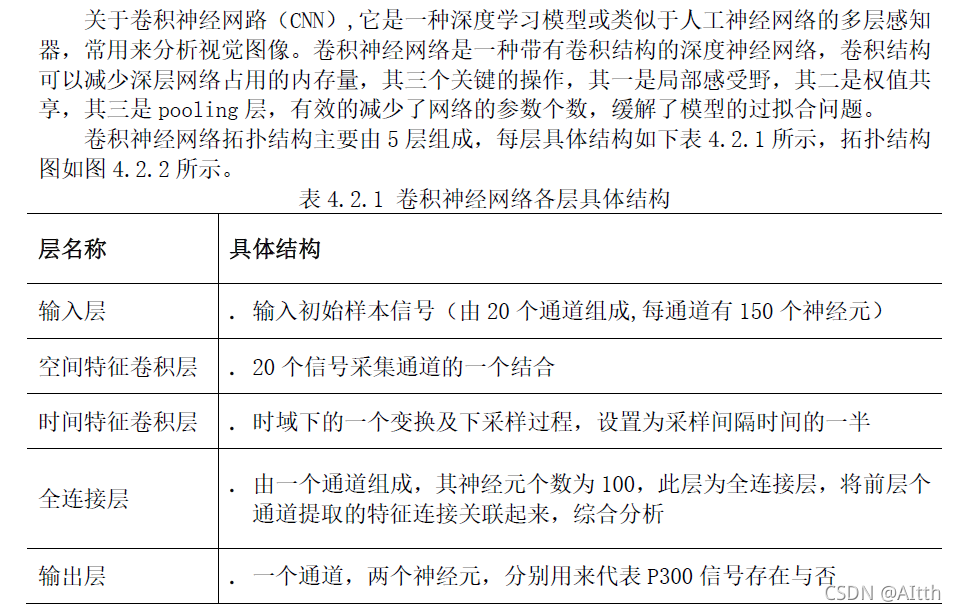
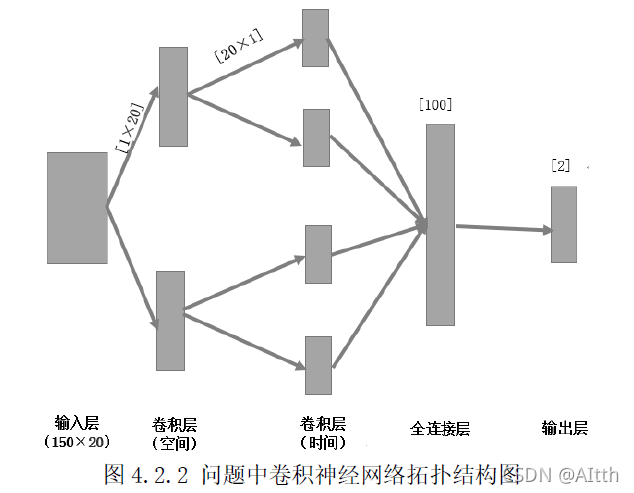
4.2 卷积神经网路方法
卷积神经网络的方法理论介绍:

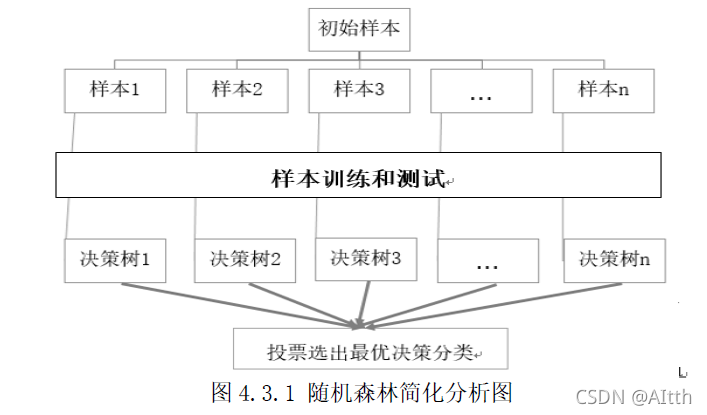
4.3 随机森林方法
随机森林(RF)介绍:


4.4 目标的分类识别方法设计本题中我们分别
采用支持向量机 (SVM))、随机森林 (RT)、卷积神经网络(CNN)三种方法执行判别功能。由于掌握的数据量较少,常见的训练集和测试集的分配比例是70%数据设置为训练集, 30%数据设置为测试集。但由于掌握的数据量较小,我们采用80%训练集和20%测试集的分配比例。
对于支持向量机和随机森林 ,直接判断信号所在行和列。支持向量机和随机森林的输
入形式是……参数设置如下:惩罚系数 C= 1 核函数为高斯核函数,核函数参gamma=2 ;随机森林的参数设置如下:树的数量为400,树的深度为60,采用交叉熵准则。
对于卷积神经网络,由于采用 TensorFlow 封装的卷积神经网络模块,对矩阵的数值单独列为一维,故输入为满足该卷积神经网络模块的四维数据。
4.5 不同方法的合理性分析
纵向对比和横向对比,用图表的形式表现出来结果的差异。得出最后的预测结果。
五、问题二:模型建立与求解
进行问题分析的过程中,利用卷积神经网络进行分析,优化通道选择算法,找出最优通道名称组合,然后找出适合所有被试者的一组最优通道组合。
5.1 L1正则化
正则化的理论介绍:

5.2 单个被试者通道选择算法设计
针对本问题样本数据及设计的卷积神经网络介绍,对参数设置,调节惩罚因子,使矩阵尽量稀疏。给出题目所给数据的结果图,对比精确率。
5.3 所有被试者最优通道组合设计
所有数据的结果图得出来,进行对比,选择出最优通道以及最优通道的精确率。注意,这里以图和表的形式展现最好。
六、问题三:模型建立与求解
本问题存在有标签样本和无标签样本的情况,采用半监督学习进行研究探讨。关于半监督学习,结合了有监督学习和无监督学习,其主要思想是基于数据分布的模型假设,这样与有标记样本独立同分布采样的未标记样本,即使未直接包含标记信息,也可利用其数据分布特征与有标记样本相联系。具体来说,利用少量的已标注数据进行指导并预测未标记数据的标记,并合并到标记数据集中去,从而提高学习器的性能。
6.1 标签传播算法
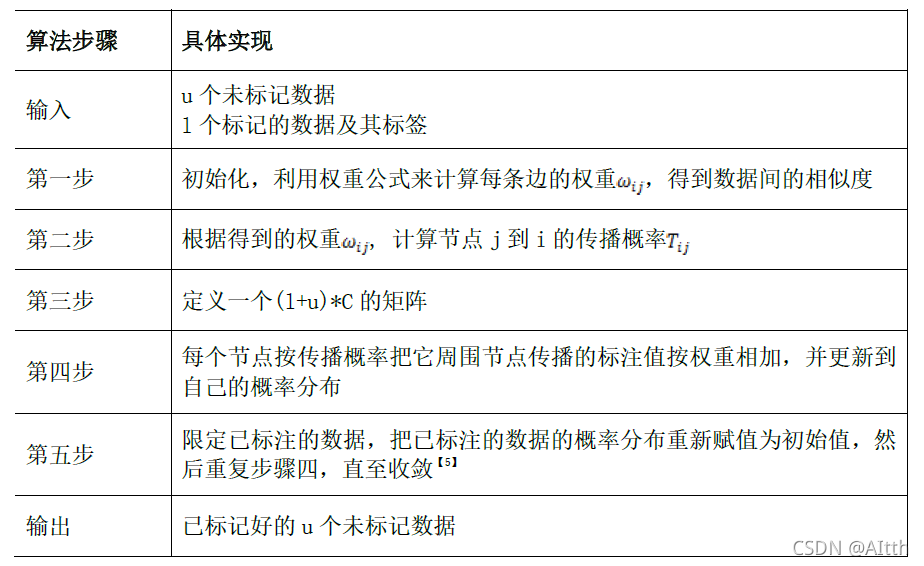
采用了半监督学习中的标签传播算法。它的基本思想是给定一个数据集,我们可将其映射为一个图,数据集中的每个样本对应于图中的一个结点,如果两个样本之间的相似度(相关性)很高,则认为对应的结点之间存在一条边,边的强度正比于样本之间的相似度(相关性)。将同一分布范围的已标记结点和未标记结点视为拥有相同的标签,从而将已标记结点的标签信息传播给附近的未标记结点。在每一次迭代过程中,已标记结点的标签保持不变,未标记结点根据相邻结点的标签更新自己的标签。相邻程度由结点的相似程度决定,邻近程度越高,对未标记结点的标签更新的影响权重越大。在不断迭代的过程中,未标记结点的标签趋向于稳定,从而实现对未标记结点的标签传递。
算法的基本描述如下:
由于分类器的性能好坏直接取决于对未标记数据标记的准确程度,准确程度低的标记会对分类器的性能产生负面影响。因此,在实际应用标签传播算法的过程中,我们对未标记数据的标签预测结果进行评价,根据评价结果的好坏进行接受或拒绝,从而保证算法效果的正面性。
6.2 自适应半监督学习
在进行标签传播算法实现的过程中会出现不收敛情形,学习效果不是很好,因此我们尝试在卷积神经网络( CNN )的基础上采用自适应半监督学习算法。
6.2.1 算法实现步骤

6.2.2 算法参数设定

6.2.3 算法识别结果分析
用图和表的形式,给出题目数据集预测之后的结果,进行结果分析,体现出本方法的有效性。
七、问题四:模型建立与求解
在求解过程中主要用到了随机森林和支持向量机两种方法进行预测,同时每一种方法就训练样本占总样本比例进行不断的调整,以求找出最合适精准率最高的分配比例。
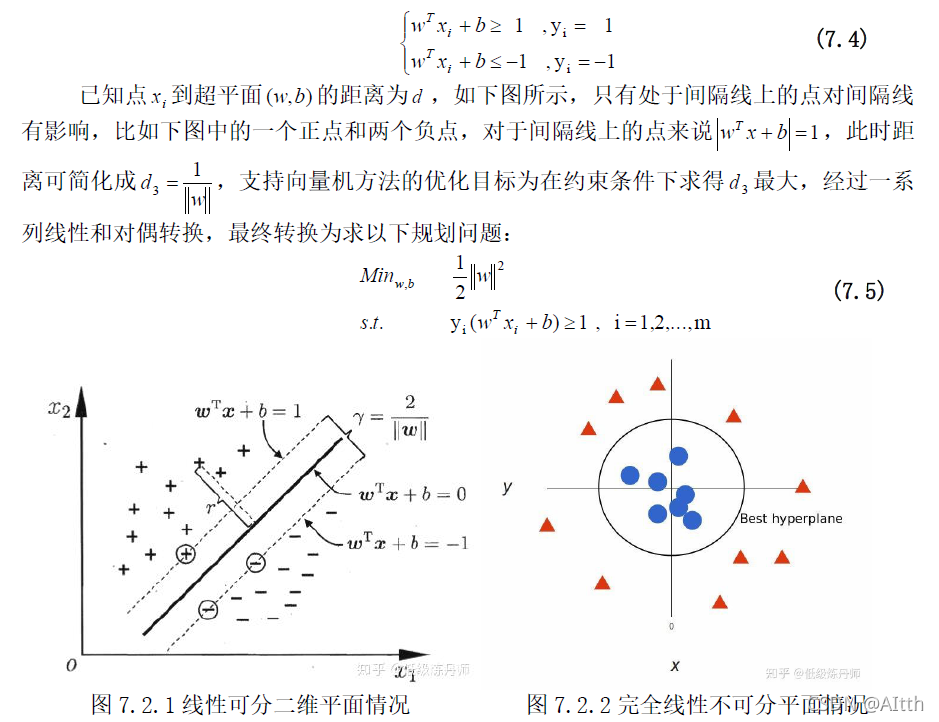
7.1 支持向量机方法


7.2 睡眠分析预测模型选择
选用支持向量机和神经网络两种方法进行尝试,每一种方法的优缺点,最后选用的方法,以及用此方法的结果图。
7.3 训练和测试数据的选择
在较高的预测准确率条件下选择尽可能少的样本。
7.3.1 选取方式
对样本数进行统计,在抽取之前顺序打乱弄混以实现随机抽样,在不同状态下随机选取样本进行训练预测。
7.3.2 分配比例
对于训练集和测试集的比例变化用折线图表示出来,找出最好的比例,使得在使用较少训练集数据的前提下获得良好的分类效果。同时对算法参数进行调试,确定最终的参数使得鞥能够获得较高的预测准确率。
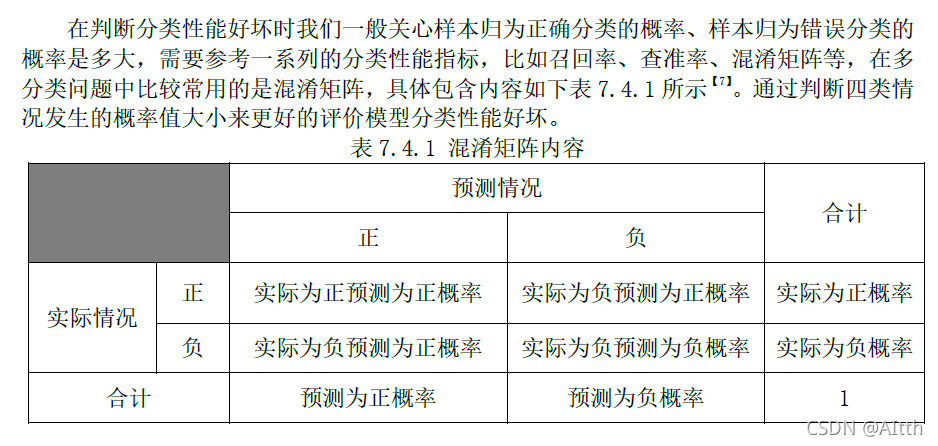
7.4 结合分类性能分析模型预测效果
八、参考文献




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









