







目录
一、数学基础
1. 期望值
1)概念
在概率论和统计学中,数学期望(mean,或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一,它反映随机变量平均取值的大小。
需要注意的是,期望值并不一定等同于常识中的 “期望” —— “期望值” 也许与每一个结果都不相等。期望值是该变量输出值的加权平均,期望值并不一定包含于变量的输出值集合里。
大数定律规定,随着重复次数接近无穷大,数值的算术平均值几乎肯定地收敛于期望值。
-
离散情况:如果 X 是连续的随机变量、P 是变量出现的概率,则 X 的期望值为:
E ( x ) = ∑ p i ⋅ x i \small E(x) = \sum p_i · x_i E(x)=∑pi⋅xi -
连续情况:如果 X 是连续的随机变量,存在一个相应的概率密度函数 f(x) ,则 X 的期望值为:
E ( x ) = ∫ x ⋅ f ( x ) d x \small E(x) = \int x·f(x) dx E(x)=∫x⋅f(x)dx
2)代码示例
import numpy as np
v = np.array([1,2,3,4,5,6])
result = np.mean(v)
print('矢量v的算数平均值:', result)
M = np.array([[1,2,3,4,5,6],[1,2,3,4,5,6]])
col_mean = np.mean(M, axis=0)
print('矩阵M的列算数平均值:', col_mean)
row_mean = np.mean(M, axis=1)
print('矩阵M的行算数平均值:', row_mean)
【结果】:
矢量v的算数平均值: 3.5
矩阵M的列算数平均值: [1. 2. 3. 4. 5. 6.]
矩阵M的行算数平均值: [3.5 3.5]
2. 方差与样本方差
1)概念
在概率论和统计学中,方差是衡量随机变量或一组数据离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度;统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数 。在许多实际问题中,研究方差(即偏离程度)有着重要意义,方差是衡量源数据和期望值相差的度量值。
【统计描述】:
在统计描述中,方差用来计算每一个变量(观察值)与总体均数之间的差异。为避免出现离均差总和为零、离均差平方和受样本含量的影响,统计学采用平均离均差平方和来描述变量的变异程度。即总体方差的计算公式为:
V a r ( X ) = σ 2 = ∑ i = 1 N ( x i − μ ) 2 N \small Var(X) = \sigma^2 = \frac{\sum_{i=1}^N (x_i - \mu)^2}{N} Var(X)=σ2=N∑i=1N(xi−μ)2
其中 xi 为一个样本的特征向量,N 为样本的总体数量,μ 为样本的总体均值,即:
μ = x 1 + x 2 + … + x N N \small \mu = \frac{x_1+x_2+\ldots+x_N}{N} μ=Nx1+x2+…+xN
假设已经计算了变量的期望值 E(X) ,则可以将随机变量的方差计算为:每个样本与期望值的平方差乘以该值的概率的总和,即:
V a r ( X ) = ∑ i = 1 N p i ⋅ [ x i − E ( x ) ] 2 \small Var(X) = \sum_{i=1}^N p_i · \big[x_i - E(x)\big]^2 Var(X)=i=1∑Npi⋅[xi−E(x)]2
如果分布中每个实例的概率相等,则方差计算可以舍去实例的概率,并将平方差的和乘以分布中实例数的倒数,即:
V a r ( X ) = ∑ i = 1 N [ x i − E ( x ) ] 2 N = E [ ( X − E ( X ) ) 2 ] \small Var(X) = \frac{\sum_{i=1}^N \big[x_i - E(x)\big]^2}{N} = E\Big[\big(X - E(X)\big)^2\Big] Var(X)=N∑i=1N[xi−E(x)]2=E[(X−E(X))2]
实际工作中,总体均数难以获取时,可用样本统计量代替总体参数,即样本方差(又称无偏样本方差),假设我们从总体中抽取了一个大小为 n 的样本,则样本方差的计算公式为:
S 2 2 = ∑ i = 1 n ( x i − x ˉ ) 2 n − 1 \small S_2^2 = \frac{\sum_{i=1}^n (x_i - \bar{x})^2}{n-1} S22=n−1∑i=1n(xi−xˉ)2
其中 xi 为一个样本的特征向量,n 为样本数量,x̅ 为样本均值,即:
x ˉ = x 1 + x 2 + … + x n n \small \bar{x} = \frac{x_1 + x_2 + \ldots + x_n}{n} xˉ=nx1+x2+…+xn
为什么样本方差是除以 n-1 呢?因为我们计算从总体中取出的样本的均值和方差时,并不是关心样本本身,而是为了以此反推出总体的均值和方差,因此它们要尽可能的接近。
样本均值的期望与总体均值是相等的,即 E(x̅) = μ 。但是样本方差如果用除以 n 的方式来计算,即:
S 1 2 = ∑ i = 1 n ( x i − x ˉ ) 2 n (有偏样本方差) \small S_1^2 = \frac{\sum_{i=1}^n (x_i - \bar{x})^2}{n}(有偏样本方差) S12=n∑i=1n(xi−xˉ)2(有偏样本方差) 那它的期望和总体方差并不相等,且偏小,即 E(S12) < σ2 ,因此,除以 n-1 是为了提供一个无偏估计。
推导过程如下:
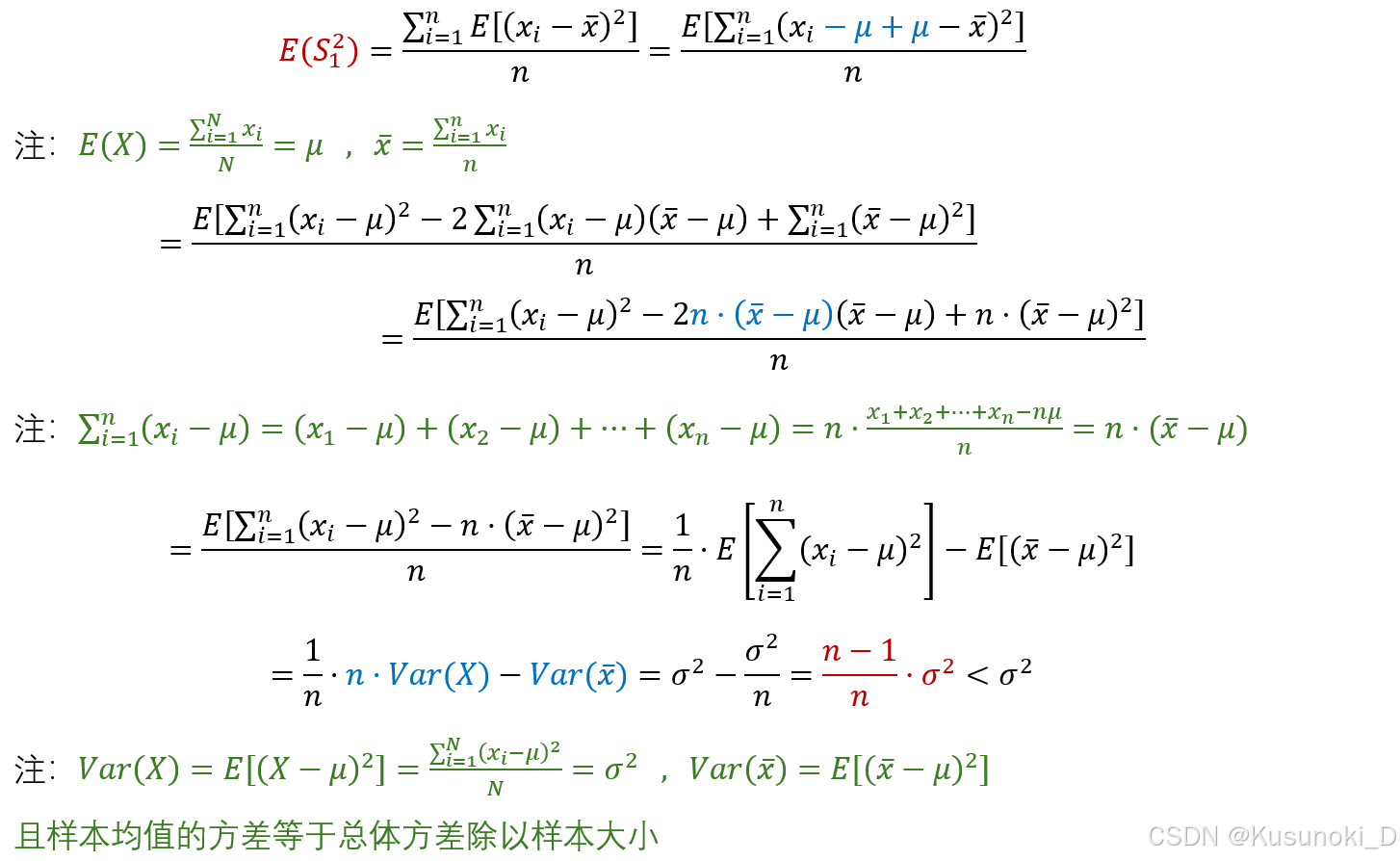
因此,我们得到: E ( S 1 2 ) = ( n − 1 ) ⋅ σ 2 n \small E(S_1^2) = \frac{(n-1)·\sigma^2}{n} E(S12)=n(n−1)⋅σ2
这表明 S12 的期望值不等于总体方差 σ2 ,因此是有偏的,为了得到总体方差的无偏估计,我们需要对 S12 进行修正,令修正后的样本方差为 S22 ,我们希望: E ( S 2 2 ) = σ 2 \small E(S_2^2) = \sigma^2 E(S22)=σ2

为什么样本均值的方差等于总体方差除以样本大小?
推导过程如下:

现在我们需要考虑两种情况:
-
当 i = j 时:
E [ ( x i − μ ) ⋅ ( x j − μ ) ] = E [ ( x i − μ ) 2 ] = V a r ( x i ) = σ 2 \small E\big[(x_i - \mu) ·(x_j - \mu)\big] = E\big[(x_i - \mu)^2\big] = Var(x_i) = \sigma^2 E[(xi−μ)⋅(xj−μ)]=E[(xi−μ)2]=Var(xi)=σ2 -
当 i ≠ j 时:由于我们假设每次抽样都是独立的,所以 xi 和 xj 是独立的,因此:
E [ ( x i − μ ) ⋅ ( x j − μ ) ] = E [ ( x i − μ ) ] ⋅ E ( x j − μ ) = 0 ⋅ 0 = 0 \small E\big[(x_i - \mu) · (x_j - \mu)\big] = E\big[(x_i - \mu)\big] · E(x_j - \mu) = 0 · 0 = 0 E[(xi−μ)⋅(xj−μ)]=E[(xi−μ)]⋅E(xj−μ)=0⋅0=0
因此,只有当 i = j 时,期望值才不为零。 所以,双重求和中只有 n 项不为零(即 i = j 的情况):
V a r ( x ˉ ) = ∑ i = 1 n σ 2 n 2 = n ⋅ σ 2 n 2 = σ 2 n \small Var(\bar{x}) = \sum_{i=1}^n \frac{\sigma^2}{n^2} = \frac{n·\sigma^2}{n^2} = \frac{\sigma^2}{n} Var(xˉ)=i=1∑nn2σ2=n2n⋅σ2=nσ2
因此,样本均值的方差等于总体方差除以样本大小。上述推导说明:样本均值的方差与总体方差成正比,与样本大小成反比,样本越大,样本均值的方差就越小,这表明样本均值更接近总体均值。
【概率分布】:
在概率分布中,离散型随机变量方差计算公式:
D ( X ) = E ( ( X − E ( X ) ) 2 ) = E ( X 2 − 2 X ⋅ E ( X ) + ( E ( X ) ) 2 ) = E ( X 2 ) − ( E ( X ) ) 2 \small D(X) = E\Big(\big(X-E(X)\big)^2\Big) = E\Big(X^2 - 2X·E(X)+\big(E(X)\big)^2\Big) = E(X^2) - \big(E(X)\big)^2 D(X)=E((X−E(X))2)=E(X2−2X⋅E(X)+(E(X))2)=E(X2)−(E(X))2
其中 D(X) 称为变量 X 的方差,而 σ = √D(X) 称为标准差(或均方差)。
方差刻画了随机变量的取值对于其数学期望的离散程度,即标准差、方差越大,离散程度越大。若 X 的取值比较集中,则方差 D(X) 较小,若 X 的取值比较分散,则方差 D(X) 较大。因此,D(X) 是刻画 X 取值分散程度的一个量,它是衡量取值分散程度的一个尺度。
2)代码示例
计算方差时,numpy 中的 var() 函数默认是总体方差(计算时除以样本数 N),若需要得到样本方差(计算时除以 N - 1),需要参数 ddof = 1 。
import numpy as np
v = np.array([5, 6, 9, 16]) # 均值为9
print('矢量v的样本方差:', np.var(v, ddof=1)) # 除数为3
# 默认情况下,ddof为零
print('矢量v的总体方差:', np.var(v)) # 除数为4
M = np.array([[1, 2, 3, 4], [5, 6, 9, 16]])
M_1 = M.reshape((2, -1)) # 转换为2行
print('矩阵M的列样本方差:', np.var(M, ddof=1, axis=0))
print('矩阵M的行样本方差:', np.var(M_1, ddof=1, axis=1))
ddof 为 int 型,计算中使用的除数为 N - ddof ,其中 N 表示元素数。默认情况下,ddof 为零,ddof = 0 为正态分布变量提供方差的最大似然估计。
【结果】:
矢量v的样本方差: 24.666666666666668
矢量v的总体方差: 18.5
矩阵M的列样本方差: [ 8. 8. 18. 72.]
矩阵M的行样本方差: [ 1.66666667 24.66666667]
3. 标准差
1)概念
标准差(Standard Deviation),数学术语,是离均差平方的算术平均数(即方差)的算术平方根,用 σ 表示。标准差也被称为标准偏差,或者实验标准差,在概率统计中最常使用作为统计分布程度上的测量依据。
2)代码示例
NumPy 提供了一个直接通过 std() 函数计算标准差的函数。与 var() 函数一样,ddof 参数必须设置为 1 ,以计算无偏样本标准差,并且可通过分别将 axis 参数设置为 0(列)或 1(行)来计算列和行的标准差。
import numpy as np
v = np.array([5, 6, 9, 16]) # 均值为9
print('矢量v的样本标准差:', np.std(v, ddof=1))
M = np.array([[1, 2, 3, 4], [5, 6, 9, 16]])
M_1 = M.reshape((2, -1)) # 转换为2行
print('矩阵M的列样本标准差:', np.std(M, ddof=1, axis=0))
print('矩阵M的行样本标准差:', np.std(M_1, ddof=1, axis=1))
【结果】:
矢量 v 的样本标准差: 4.96655480858378
矩阵 M 的列样本标准差: [2.82842712 2.82842712 4.24264069 8.48528137]
矩阵 M 的行样本标准差: [1.29099445 4.96655481]
4. 协方差
1)概念
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况(方差是衡量一个变量之间的离散程度)。
期望值分别为 E(X) = u 与 E(Y) = ν 的两个实随机变量 X 与 Y 之间的协方差定义为:
C o v ( X , Y ) = E ( ( X − E ( X ) ) ⋅ ( Y − E ( Y ) ) ) = E ( X Y ) − 2 E ( X ) E ( Y ) + E ( X ) E ( Y ) = E ( X Y ) − u v \small Cov(X,Y) = E\Big(\big(X - E(X)\big) · \big(Y - E(Y)\big)\Big) = E(XY) - 2E(X)E(Y) + E(X)E(Y) = E(XY) - uv Cov(X,Y)=E((X−E(X))⋅(Y−E(Y)))=E(XY)−2E(X)E(Y)+E(X)E(Y)=E(XY)−uv
假设 X 和 Y 的期望值已经计算出来,协方差可以计算为 xi 值与它的期望值的差值乘以 yi 值与它的期望值的差值乘以实例总数的倒数:
C o v ( X , Y ) = ∑ i = 1 N ( x i − E ( X ) ) ⋅ ( y i − E ( Y ) ) N \small Cov(X,Y) = \frac{\sum_{i=1}^N \big(x_i-E(X)\big) · \big(y_i-E(Y)\big)}{N} Cov(X,Y)=N∑i=1N(xi−E(X))⋅(yi−E(Y))
样本协方差的公式为:
∑ i = 1 n ( x i − A ) ⋅ ( y i − B ) n − 1 \small \frac{\sum_{i=1}^n (x_i-A)·(y_i-B)}{n-1} n−1∑i=1n(xi−A)⋅(yi−B)
其中 A 为样本 X 的均值,B 为样本 Y 的均值,除以 n-1 而不是 n 的原因是对总体样本期望的无偏估计。
-
Cov(X, Y) > 0 ↔ X 与 Y 正相关
-
Cov(X, Y) = 0 ← X 与 Y 相互独立 → E(XY) = E(X)·E(Y)
-
Cov(X, Y) < 0 ↔ X 与 Y 负相关
协方差的符号可以解释为:协方差表示的是两个变量总体误差的方差,两个变量是一起增加(正数)还是一起减少(负数)。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果 X 与 Y 是统计独立的,那么二者之间的协方差就是 0 ,反之则不成立。
2)代码示例
import numpy as np
x = np.array([1, 5, 6]) # X的均值为4
y = np.array([4, 3, 9]) # Y的均值为16/3
print('Cov(x,x) = Var(x) = ', np.cov(x, y)[0, 0])
print('Cov(y,y) = Var(y) = ', np.cov(x, y)[1, 1])
# 当平方协方差矩阵[0,1]元素返回时,我们只获取两个变量的协方差
print('Cov(x,y) = ', np.cov(x, y)[0, 1])
【结果】:
Cov(x,x) = Var(x) = 7.0
Cov(y,y) = Var(y) = 10.333333333333334
Cov(x,y) = 4.5
5. 协方差矩阵
1)概念
协方差也只能处理二维问题,当维数多了就需要计算多个协方差,比如 n 维(n > 2)的数据集就需要计算 n ! [ 2 ⋅ ( n − 2 ) ! ] \frac{n!}{[2\cdot(n-2)!]} [2⋅(n−2)!]n! 个协方差,因此我们需要使用矩阵来组织这些数据。
在统计学与概率论中,协方差矩阵(也称离差矩阵、方差-协方差矩阵)在其 (i, j) 位置上的元素值是第 i 个与第 j 个随机变量之间的协方差。协方差矩阵是描述两个及以上随机变量之间的协方差的方型对称矩阵,协方差矩阵的对角线是每个随机变量的方差。
协方差矩阵 Σ 是两个变量的协方差的泛化,并捕捉数据集中所有变量可以一起变化的方式。给出协方差矩阵的定义:
给定 n 个特征列向量 X1, X2, …, Xn ,且每个样本均抽取 m 个特征,则这些随机变量的方差为:
V a r ( X k ) = ∑ i = 1 m ( x k i − x ˉ k ) 2 m − 1 \small Var(X_k) = \sum_{i=1}^m \frac{(x_{ki}-\bar{x}_k)^2}{m-1} Var(Xk)=i=1∑mm−1(xki−xˉk)2
其中 k ∈ [1, n] ,i ∈ [1, m] ,xki 表示随机变量 Xk 中的第 i 个观测样本。对于这些随机变量,我们还可以根据协方差的定义,求出两两之间的协方差,即:
Σ ( p , q ) = C o v ( X p , X q ) = E ( ( X p − E ( X p ) ) ⋅ ( X q − E ( X q ) ) T ) = ∑ i = 1 m ( x p i − x ˉ p ) ⋅ ( x q i − x ˉ q ) m − 1 \small \Sigma(p,q) = Cov(X_p,X_q) = E\Big(\big(X_p-E(X_p)\big) · \big(X_q-E(X_q)\big)^T\Big) = \sum_{i=1}^m \frac{(x_{pi}-\bar{x}_p)·(x_{qi}-\bar{x}_q)}{m-1} Σ(p,q)=Cov(Xp,Xq)=E((Xp−E(Xp))⋅(Xq−E(Xq))T)=i=1∑mm−1(xpi−xˉp)⋅(xqi−xˉq)
其中 p, q ∈ [1, n] ,i ∈ [1, m] 。
协方差矩阵完整形式: Σ ( k , k ) = C o v ( X k , X k ) = V a r ( X k ) \small \Sigma(k,k) = Cov(X_k,X_k) = Var(X_k) Σ(k,k)=Cov(Xk,Xk)=Var(Xk)
c o v [ X , X ] = [ c o v [ X 1 , X 1 ] c o v [ X 1 , X 2 ] ⋯ c o v [ X 1 , X n ] c o v [ X 2 , X 1 ] c o v [ X 2 , X 2 ] … c o v [ X 2 , X n ] ⋮ ⋮ ⋱ ⋮ c o v [ X n , X 1 ] c o v [ X n , X 2 ] ⋮ c o v [ X n , X n ] ] cov[X,X]=\left[ \begin{matrix} cov[X_1,X_1] & cov[X_1,X_2] & \cdots & cov[X_1,X_n]\\ cov[X_2,X_1] & cov[X_2,X_2] & \dots & cov[X_2,X_n]\\ \vdots & \vdots & \ddots & \vdots \\ cov[X_n,X_1] & cov[X_n,X_2] & \vdots & cov[X_n,X_n] \end{matrix} \right] cov[X,X]= cov[X1,X1]cov[X2,X1]⋮cov[Xn,X1]cov[X1,X2]cov[X2,X2]⋮cov[Xn,X2]⋯…⋱⋮cov[X1,Xn]cov[X2,Xn]⋮cov[Xn,Xn]
可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
2)代码示例
import numpy as np
X = np.array([[1 ,5 ,6], [4 ,3 ,9], [4 ,2 ,9], [4 ,7 ,2]])
print('X0的方差:', np.var(X[0], ddof=1))
print('X0和X1的协方差:', np.cov(X)[0, 1])
print('X的协方差矩阵:\n', np.cov(X))
【结果】:
X0的方差: 7.0
X0和X1的协方差: 4.5
X的协方差矩阵:
[[ 7. 4.5 4. -0.5 ]
[ 4.5 10.33333333 11.5 -7.16666667]
[ 4. 11.5 13. -8.5 ]
[-0.5 -7.16666667 -8.5 6.33333333]]
6. 协方差的相关系数
1)概念
相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量。为了准确得到变量之间的相似程度,我们需要把协方差除以各自变量的标准差。这样就得到了相关系数的表达式:
r ( X , Y ) = C o v ( X , Y ) ( σ X ⋅ σ Y ) \small r(X, Y) = \frac{Cov(X, Y)}{(\sigma X·\sigma Y)} r(X,Y)=(σX⋅σY)Cov(X,Y)
可见,相关系数就是在协方差的基础上除以变量 X 和 Y 的标准差。为什么除以各自变量的标准差就能消除幅值影响呢?这是因为标准差本身反映了变量的幅值变化程度,除以标准差正好能起到抵消的作用,让协方差标准化。这样,相关系数的范围就被归一化到 [-1, 1] 之间了。
-
相关系数大于零,则表示两个变量正相关,且相关系数越大,正相关性越高;
-
相关系数小于零,则表示两个变量负相关,且相关系数越小,负相关性越高;
-
相关系数等于零,则表示两个变量不相关。
观察协方差与相关系数的关系,可以发现相关系数是协方差的标准化、归一化形式,消除了量纲、幅值变化不一的影响。实际应用中,在比较不同变量之间相关性时,使用相关系数更为科学和准确。
2)代码示例
import numpy as np
X = np.array([1, 5, 6])
Y = np.array([4, 3, 9])
Cov_XY = np.cov(X, Y)[0, 1]
print('Cov(X,Y) = ', Cov_XY)
X_std = np.std(X, ddof=1)
Y_std = np.std(Y, ddof=1)
print('r(X,Y) = ', Cov_XY / (X_std * Y_std))
cor = np.corrcoef(X, Y)
print('X与Y的相关系数矩阵:\n', cor)
【结果】:
Cov(X,Y) = 4.5
r(X,Y) = 0.5291067161269939
X与Y的相关系数矩阵:
[[1. 0.52910672]
[0.52910672 1. ]]
7. 矩阵微分公式

二、LDA 基本思想
线性判别分析(Linear Discriminant Analysis,简称 LDA)是一种经典的线性学习方法,在二分类问题上因为最早由 Fisher 提出,亦称 “Fisher 判别分析” 。
严格来说 LDA 与 Fisher 判别分析稍有不同,前者假设了各类样本的协方差矩阵相同且满秩。
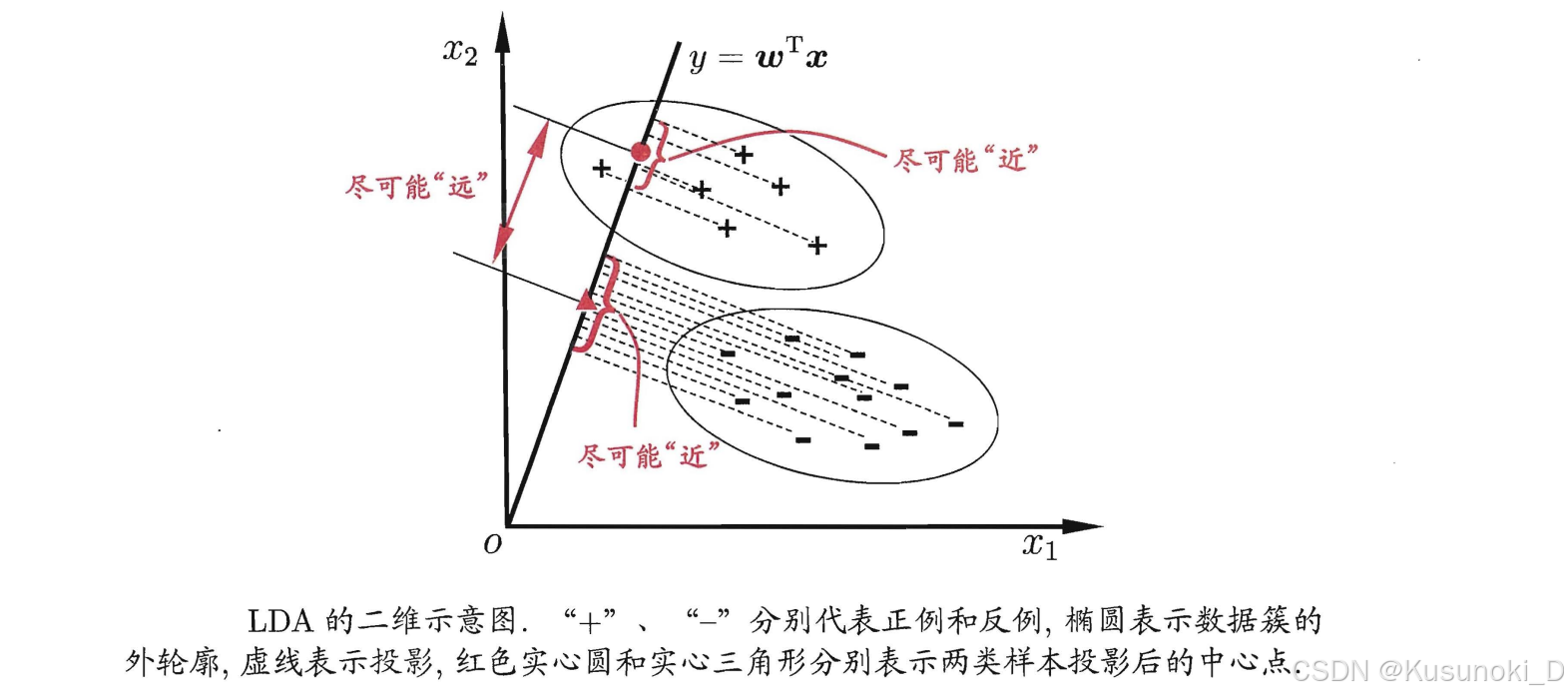
LDA 的思想(优化目标)非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离,即类内距离小、类间距离大,在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别,下图给出了一个二维示意图:
三、LDA 数学推导
1. 基本推导
给定数据集 D = {(x1, y1), (x2, y2), …, (xm, ym)} ,yi ∈ {0, 1} ,令 Xi , μi , Σi 分别为第 i ∈ {0, 1} 类数据的集合、均值向量和协方差矩阵。假设将上述数据投影到直线 ω 上,则两类样本的中心在直线上的投影分别为 ωTμ0 和 ωTμ1 ,考虑所有样本投影的情况下,假设两类样本的协方差分别为 ωTΣ0ω 和 ωTΣ1ω ,直线 ω 为一维空间,所以上述值均为实数。
LDA模型的优化目标是使同类样本的投影点尽可能接近,异类样例的投影点尽可能疏远。欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小,即 ωTΣ0ω + ωTΣ1ω 尽可能小;而欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能大,即 ||ωTμ0 - ωTμ1||22(L2 范数再求平方)尽可能大。
其中 ||X||2 表示向量的 2-范数,公式为: ∥ X ∥ 2 = ∑ i = 1 n x i 2 \small \lVert X \rVert_2 = \sqrt{\sum_{i=1}^n x_i^2} ∥X∥2=∑i=1nxi2 ,即每个元素的平方相加之后再开平方根。

定义 “类内散度矩阵” Sw(within-class scatter matrix):类内散度矩阵衡量的是每个类别内部样本的分散程度。
S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ⋅ ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ⋅ ( x − μ 1 ) T \small S_w = \Sigma_0+\Sigma_1 = \sum_{x\in X_0}(x-\mu_0)·(x-\mu_0)^T + \sum_{x\in X_1}(x-\mu_1)·(x-\mu_1)^T Sw=Σ0+Σ1=x∈X0∑(x−μ0)⋅(x−μ0)T+x∈X1∑(x−μ1)⋅(x−μ1)T
以及 “类间散度矩阵” Sb(between-class scatter matrix):类间散度矩阵衡量的是不同类别之间的分离程度。
S b = ( μ 0 − μ 1 ) ⋅ ( μ 0 − μ 1 ) T \small S_b = (\mu_0 - \mu_1) · (\mu_0 - \mu_1)^T Sb=(μ0−μ1)⋅(μ0−μ1)T
则上式可重写为:
J = ω T S b ω ω T S w ω (式 ①) \small J = \frac{\omega^TS_b\omega}{\omega^TS_w\omega}\tag{式 ①} J=ωTSwωωTSbω(式 ①)
这就是 LDA 欲最大化的目标,即 Sb 与 Sw 的 “广义瑞利商”(generalized Rayleigh quotient)。
如何确定 ω 呢?注意到式 ① 中的分子和分母都是关于 ω 的二次项,因此式 ① 的解与 ω 的长度无关,只与其方向有关.不失一般性,令 ωTSwω = 1 ,则式 ① 等价于:
min ω ( − ω T S b ω ) 且 s . t . ω T S w ω = 1 (式 ②) \small \min_\omega(-\omega^TS_b\omega)且s.t.\omega^TS_w\omega=1\tag{式 ②} ωmin(−ωTSbω)且s.t.ωTSwω=1(式 ②)
若 ω 是一个解,则对于任意常数 α ,αω 也是式 ① 的解。
由拉格朗日乘子法,式 ② 等价于:
S b ω = λ S w ω (式 ③) \small S_b\omega = \lambda S_w\omega\tag{式 ③} Sbω=λSwω(式 ③)
其中 λ 是拉格朗日乘子。

由于我们不关心最终要求解的 ω 的大小,只关心其方向,所以其大小可以任意取值。由于 μ0 和 μ1 的大小是固定的,从而 γ 这个标量的大小只受 ω 的大小影响,因此可以调整 ω 的大小使得 γ = λ ,下述的不妨令 Sbω = λ(μ0 - μ1) 也等价于令 γ = λ ,因此,此时 γ / λ = 1 。
注意到 Sbω 的方向恒为 μ0 - μ1 ,不妨令 Sbω = λ(μ0 - μ1) ,代入式 ③ 即得:
ω = S w − 1 ( μ 0 − μ 1 ) \small \omega = S_w^{-1}(\mu_0-\mu_1) ω=Sw−1(μ0−μ1)
考虑到数值解的稳定性,在实践中通常是对 Sw 进行奇异值分解,即 Sw = UΣVT ,这里 Σ 是一个实对角矩阵,其对角线上的元素是 Sw 的奇异值,然后再由 Sw-1 = VΣ-1UT 得到 Sw-1 。
2. LDA 算法流程
完整的 LDA 算法流程如下:
- 对训练集按类别进行分组
- 分别计算每组样本的均值 μ 和协方差 Cov
- 计算类间散度矩阵 Sw = Σ0 + Σ1
- 计算两类样本的均值差 μ0 - μ1
- 对类间散度矩阵 Sw 进行奇异值分解,并求其逆
- 根据 Sw-1(μ0 - μ1) 得到 ω
- 最后计算投影后的数据点 Y = ωX
3. 多分类任务
可以将 LDA 推广到多分类任务中,LDA 的目标是找到一个投影矩阵 W ,使得样本投影到低维空间后:
- 相同类别的样本尽可能地靠近(类内方差小)
- 不同类别的样本尽可能地远离(类间方差大)
假定存在 C 个类别且样本总数为 N ,Xi 表示第 i 个样本的特征列向量,我们先定义 “全局散度矩阵” :
S t = S b + S w = ∑ i = 1 N ( X i − μ ) ⋅ ( X i − μ ) T \small S_t = S_b + S_w = \sum_{i=1}^N (X_i-\mu)·(X_i-\mu)^T St=Sb+Sw=i=1∑N(Xi−μ)⋅(Xi−μ)T
其中 μ 是所有样本的总体均值,即:
μ = ∑ i = 1 N X i N = ∑ i = 1 C N i ⋅ μ i N \small \mu = \sum_{i=1}^N \frac{X_i}{N} = \sum_{i=1}^C \frac{N_i·\mu_i}{N} μ=i=1∑NNXi=i=1∑CNNi⋅μi
其中 Ni 表示第 i 个类别的样本数量,μi 表示第 i 个类别的均值。
将类内散度矩阵 Sw 重定义为每个类别的散度矩阵之和,即:
S w = ∑ i = 1 C S w i , 其中 S w i = ∑ X ∈ c l a s s i ( X − μ i ) ⋅ ( X − μ i ) T \small S_w = \sum_{i=1}^C S_{wi},其中S_{wi}=\sum_{X\in class_i} (X - μ_i)·(X-\mu_i)^T Sw=i=1∑CSwi,其中Swi=X∈classi∑(X−μi)⋅(X−μi)T
由上述可得类间散度矩阵:
S b = S t − S w = ∑ i = 1 C N i ⋅ ( μ i − μ ) ⋅ ( μ i − μ ) T (式 ④) \small S_b = S_t - S_w = \sum_{i=1}^C N_i · (\mu_i - \mu) · (\mu_i - \mu)^T\tag{式 ④} Sb=St−Sw=i=1∑CNi⋅(μi−μ)⋅(μi−μ)T(式 ④)
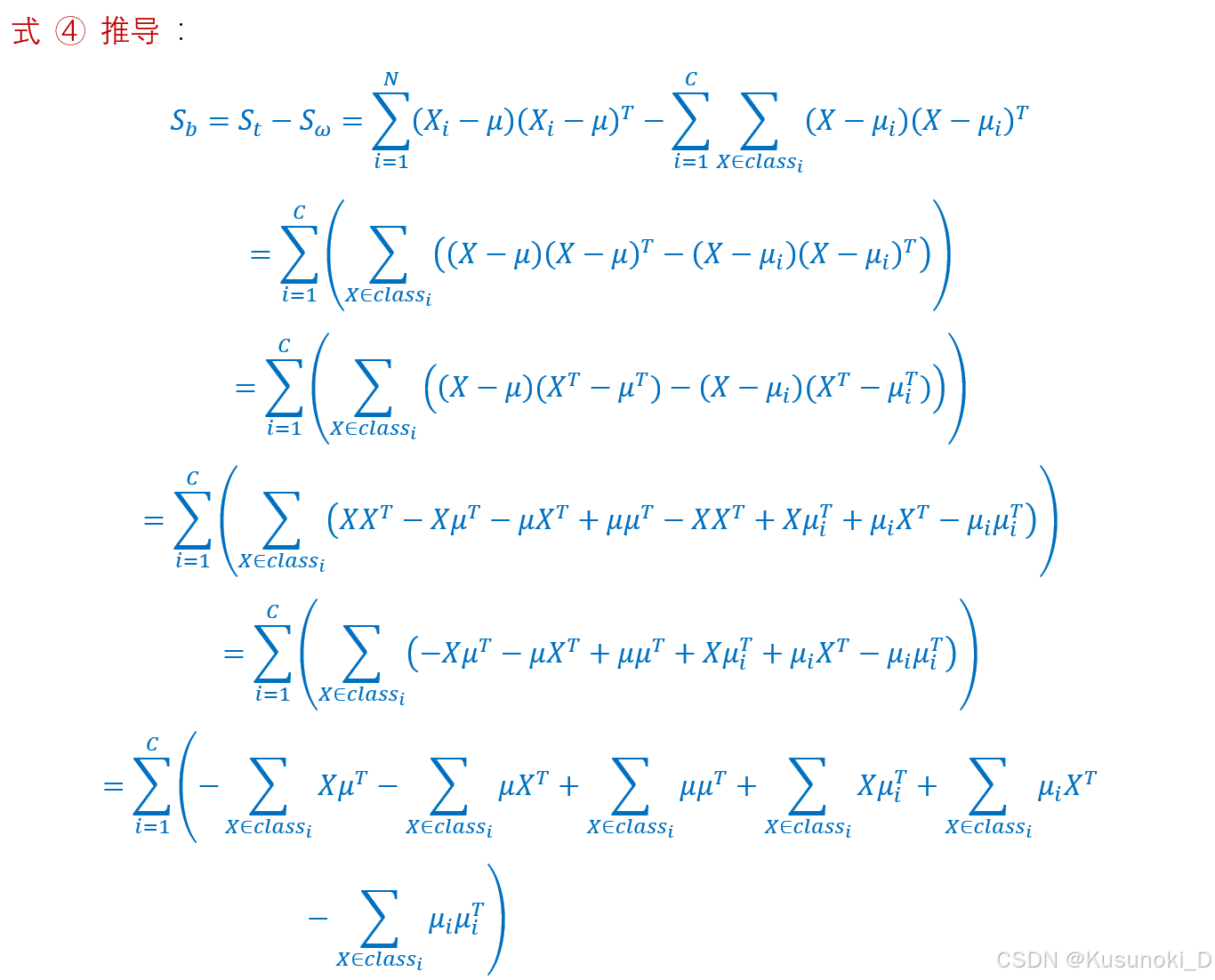
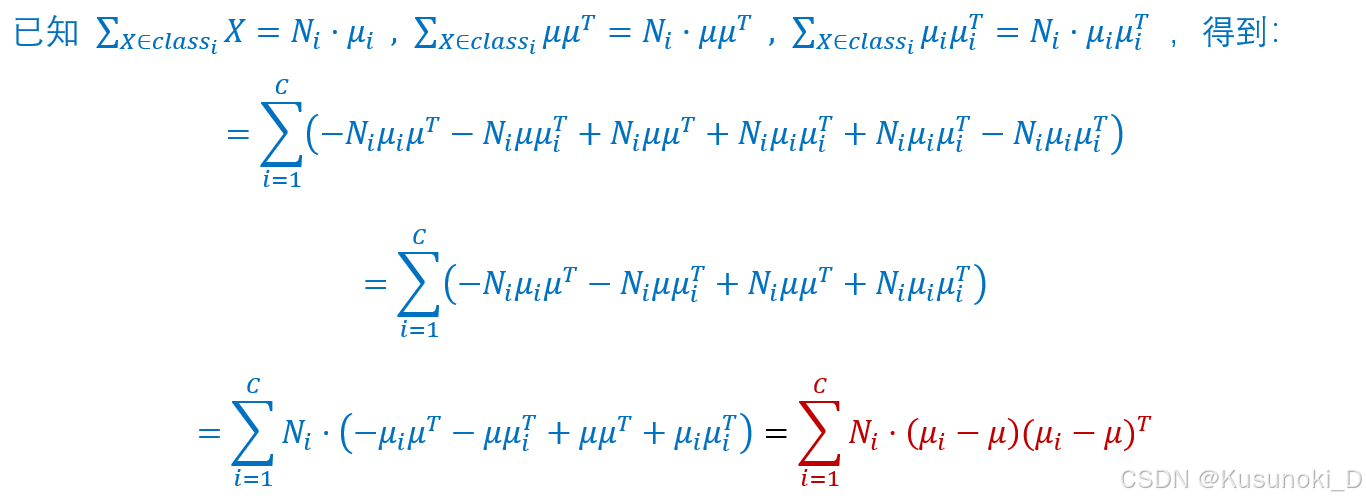
多分类 LDA 的目标是最大化类间散度,同时最小化类内散度。 因此,我们定义目标函数如下:
J ( W ) = t r ( W T S b W ) t r ( W T S w W ) \small J(W) = \frac{tr(W^TS_bW)}{tr(W^TS_wW)} J(W)=tr(WTSwW)tr(WTSbW)
其中,投影矩阵 W 可将样本从原始特征空间投影到低维空间;tr(·) 表示矩阵的迹(trace),即对角线元素的和。目标是找到一个 W 使得 J(W) 最大化。
为了最大化 J(W) ,我们需要对 W 求导,并令导数为零。 更常见的方法是求解广义特征值问题。首先,将目标函数改写为:
W ∗ = arg max W t r ( W T S b W ) t r ( W T S w W ) (式 ⑤) \small W^\ast = \argmax_W \frac{tr(W^TS_bW)}{tr(W^TS_wW)}\tag{式 ⑤} W∗=Wargmaxtr(WTSwW)tr(WTSbW)(式 ⑤)
式 ⑤ 可通过如下广义特征值问题求解,即式 ⑤ 等价于求解式 ⑥ :
S b W = λ S w W (式 ⑥) \small S_bW = \lambda S_wW\tag{式 ⑥} SbW=λSwW(式 ⑥) 或 S w − 1 S b W = λ W \small 或\quad S_w^{-1}S_bW = \lambda W 或Sw−1SbW=λW

这是一个广义特征值问题,W 的列向量是矩阵 Sw-1Sb 的广义特征向量,λ 是对应的广义特征值。
W 的闭式解是 Sw-1Sb 的 C - 1 个最大广义特征值所对应的特征向量组成的矩阵。若将 W 视为一个投影矩阵,则多分类 LDA 将样本投影到 C - 1 维空间,C - 1 通常远小于数据原有的属性数。于是,可通过这个投影来减小样本点的维数,且投影过程中使用了类别信息,因此 LDA 也常被视为一种经典的监督降维技术。
求解步骤
-
计算 Sw 和 Sb 。
-
求解广义特征值问题:Sw-1SbW = λW ,通常使用数值计算方法(如 SciPy 在 Python 中)来求解。
-
选择最大的 k 个特征值对应的特征向量(k 为降维后的目标维度),构成投影矩阵 W ,通常 k ≤ C - 1 且 k < d(d 为原始特征空间的维度),这是因为 Sb 的秩的最大值为 C - 1 。
降维和分类
① 降维:对于新的样本 X ,使用投影矩阵 W 将其投影到低维空间:Z = WTX ,其中,Z 是降维后的特征向量。
② 分类:在降维后的空间中,可以使用最近邻分类器、或其他分类器(如 SVM、逻辑回归)来进行分类。 常用的方法是计算 Z 与每个类别均值向量的距离,将 Z 分类到距离最近的类别。
注意
-
Sw 的可逆性:在求解 Sw-1 时,需要保证 Sw 是可逆的。如果 Sw 不可逆(奇异矩阵),可以使用正则化方法,例如在 Sw 的对角线上加上一个小的正数 ϵ 。
-
特征值选择:通常选择前 k 个最大的特征值对应的特征向量,其中 k 的选择需要根据具体问题进行调整。k 的最大值通常是 C - 1 ,其中 C 是类别的数量。
-
数据预处理: 在应用 LDA 之前,通常需要对数据进行标准化或归一化处理,以避免某些特征对结果产生过大的影响。
多分类 LDA 将样本投影到低维空间,降低了数据集的原有维度,并且在投影过程中使用了类别信息,所以 LDA 是一种经典的监督降维技术。
四、LDA 算法实现
1. Iris 数据集(两类四个特征)
Iris 数据集是常用的分类实验数据集,Iris 也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含 150 个数据样本,分为 3 类,每类 50 个数据,每个数据包含 4 个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度 4 个属性预测鸢尾花卉属于(Setosa—0,Versicolour—1,Virginica—2)三个种类中的哪一类。
下列代码完整地定义了一个 LDA 算法类,包括协方差矩阵计算方法的定义、数据投影方法的定义,LDA 拟合和分类预测方法的定义,其中最核心的方法就是 LDA 拟合方法 LDA.fit 。
【代码实现】:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
class LDA:
def __init__(self):
self.w = None # 初始化权重矩阵
# 协方差矩阵计算方法
def calc_cov(self, X, Y=None):
m = X.shape[0]
# 标准化数据:(X-μ)/σ
# axis=0:按行计算,得到列的性质;axis=1:按列计算,得到行的性质
X = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
if Y == None:
Y = X
else:
Y = (Y - np.mean(Y, axis=0)) / np.std(Y, axis=0)
return 1 / m * np.matmul(X.T, Y) # matmul等价于@
# LDA拟合获取模型权重
def fit(self, X0, X1):
# 分别计算两类数据自变量的协方差矩阵
sigma0 = self.calc_cov(X0)
sigma1 = self.calc_cov(X1)
# 计算类内散度矩阵
Sw = sigma0 + sigma1
# 分别计算两类数据自变量的均值和差
u0, u1 = np.mean(X0, axis=0), np.mean(X1, axis=0)
# atleast_1d:返回至少一维的NumPy数组
mean_diff = np.atleast_1d(u0 - u1)
# 对类内散度矩阵进行奇异值分解
U, S, V = np.linalg.svd(Sw)
# 计算类内散度矩阵的逆
Sw_ = np.dot(np.dot(V.T, np.linalg.pinv(np.diag(S))), U.T)
# 计算w
self.w = Sw_.dot(mean_diff)
# LDA分类预测
def predict(self, X):
# 初始化预测结果为空列表
y_predict = []
# 遍历待预测样本
for x_i in X:
# 模型预测
h = x_i.dot(self.w)
y = 1 * (h < 0)
y_predict.append(y)
return y_predict
# 数据投影方法
def project(self, X):
# 数据投影
X_projection = X.dot(self.w)
return X_projection
# 导入iris数据集
iris = datasets.load_iris()
# 数据与标签
data, target = iris.data, iris.target
print('该数据集的样本个数(m) : %d , 特征个数(n) : %d' % (data.shape[0], data.shape[1]))
print('该数据集的特征 : ', iris.feature_names)
# 取标签不为2的数据
X, y, *_ = data[target!=2], target[target!=2] # (100,4)&(100,)
# 划分训练集和测试集 (80,4)&(20,4)&(80,)&(20,)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=41)
# 按类分组
X0 = X_train[y_train == 0] # (39,4)
X1 = X_train[y_train == 1] # (41,4)
# 创建LDA模型实例
lda = LDA()
# LDA模型拟合
lda.fit(X0, X1)
# LDA模型预测
y_predict = lda.predict(X_test)
# 测试集上的分类准确率
acc = accuracy_score(y_test, y_predict)
print('Accuracy of NumPy LDA:', acc)
# 创建LDA分类器
sk_LDA = LinearDiscriminantAnalysis()
# 模型拟合,Method calculates the parameters μ and σ and saves them as internal objects
sk_LDA.fit(X_train, y_train)
# 模型预测
y_predict = sk_LDA.predict(X_test)
# 测试集上的分类准确率
acc = accuracy_score(y_test, y_predict)
print('Accuracy of Sklearn LDA:', acc)
【结果展示】:

我们用 sklearn 的 iris 数据集对模型进行测试,加载数据集后筛选标签,仅取标签为 0 或 1 的数据,然后将数据集划分为训练集和测试集。准备完数据之后,创建 LDA 模型实例,然后拟合训练集并对测试集进行预测,最后得到测试集上的分类准确率。
可以看到,基于 NumPy 的 LDA 模型分类准确率达 0.85 ,而基于 sklearn 的 LDA 算法在该数据集上分类准确率较高。
2. 西瓜数据集 3a(两类两个特征)
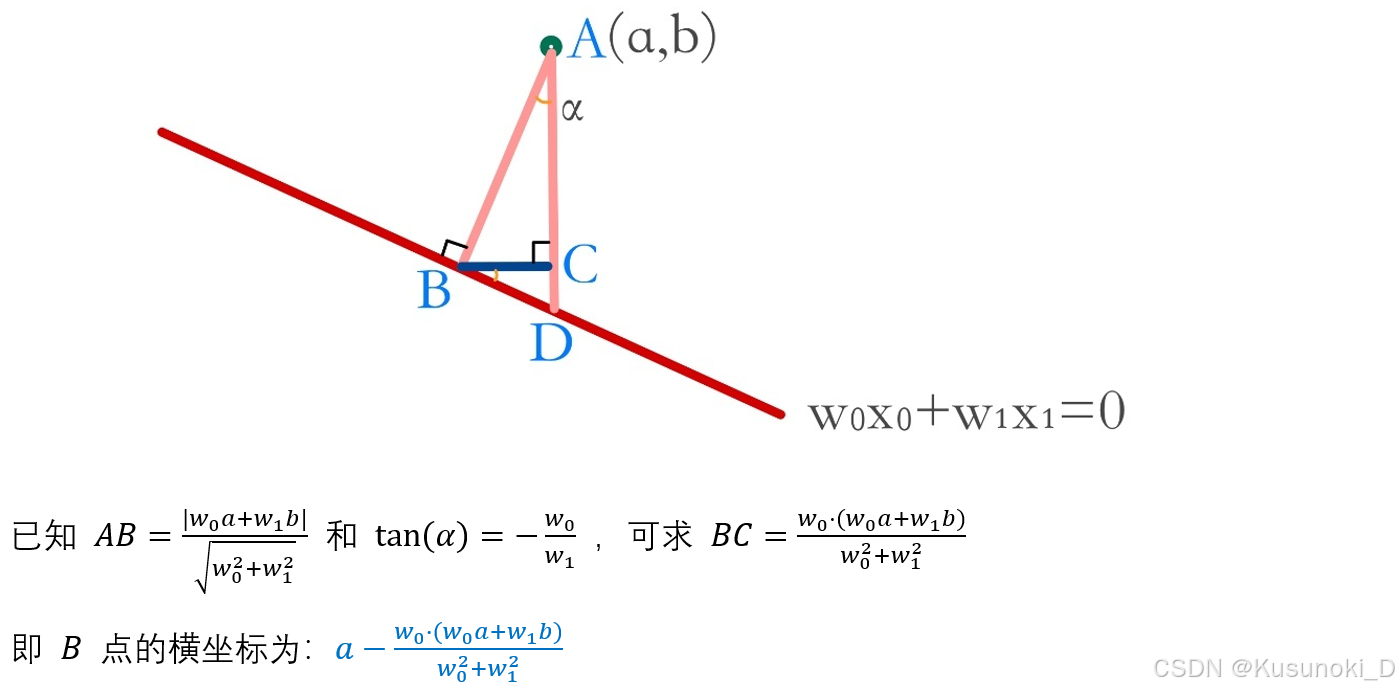
【点投影直线公式】:
【代码实现】:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 处理数据
filepath = "D:\PycharmProjects\西瓜数据集3a.csv"
df = pd.read_csv(filepath, header=0, encoding='gb2312')
data = df.loc[df['好瓜'] == 1]
X0 = np.array(data.iloc[:, :2]) # 存储好瓜的密度和含糖率(8,2)
data = df.loc[df['好瓜'] == 0]
X1 = np.array(data.iloc[:, :2]) # 存储坏瓜的密度和含糖率(9,2)
# 求正反例均值
average0 = np.mean(X0, axis=0).reshape((-1, 1)) # (2,1)
average1 = np.mean(X1, axis=0).reshape((-1, 1)) # (2,1)
# 求协方差
# rowvar默认为True,如果设定rowvar为False,则相当于给需要计算协方差的矩阵加了个转置
cov0 = np.cov(X0, rowvar=False) # (2,2)
cov1 = np.cov(X1, rowvar=False) # (2,2)
# 求出w
Sw = np.mat(cov0 + cov1) # (2,2)
w = Sw.I * (average0 - average1) # (2,1)
w0 = float(w[0])
w1 = float(w[1])
print('直线:%f·x0 + %f·x1 = 0' % (w0, w1))
# 每个数据点在W上的投影
X0_projection = []
X1_projection = []
for i in range(0, X0.shape[0]):
X0_p = []
X0_x = X0[i][0] - w0 * (w0 * X0[i][0] + w1 * X0[i][1]) / (np.power(w0, 2) + np.power(w1, 2))
X0_p.append(X0_x)
X0_y = -w0 / w1 * X0_x
X0_p.append(X0_y)
X0_projection.append(X0_p)
X0_projection = np.array(X0_projection).reshape((-1, 2))
for j in range(0, X1.shape[0]):
X1_p = []
X1_x = X1[j][0] - w0 * (w0 * X1[j][0] + w1 * X1[j][1]) / (np.power(w0, 2) + np.power(w1, 2))
X1_p.append(X1_x)
X1_y = -w0 / w1 * X1_x
X1_p.append(X1_y)
X1_projection.append(X1_p)
X1_projection = np.array(X1_projection).reshape((-1, 2))
# 画出点、直线
plt.scatter(X0[:, 0], X0[:, 1], c='b', label='label=1', marker='^')
plt.scatter(X1[:, 0], X1[:, 1], c='r', label='label=0')
# 画出投影在直线的点
plt.scatter(X0_projection[:, 0], X0_projection[:, 1], c='b')
plt.scatter(X1_projection[:, 0], X1_projection[:, 1], c='r')
# w0x0+w1x1=0
x0 = np.linspace(0, 1, 50)
x1 = -w0 / w1 * x0
plt.plot(x0, x1, label='y')
plt.xlabel('密度', fontproperties='SimHei', fontsize=15)
plt.ylabel('含糖率', fontproperties='SimHei', fontsize=15)
# 用于添加和定制图例的工具
plt.legend()
plt.show()
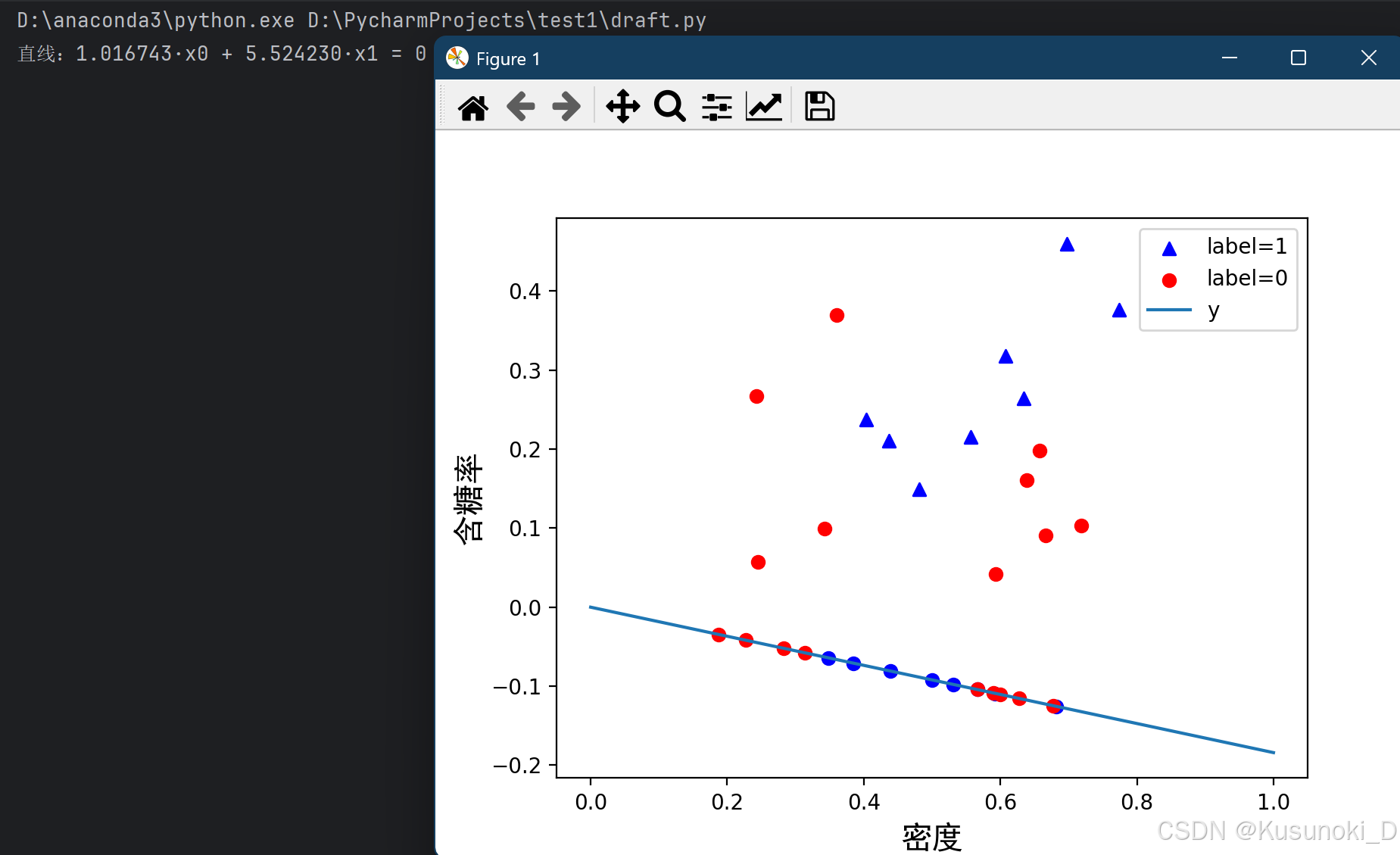
【结果展示】:
参考文章:
①【手把手教你Python编程实现线性判别分析LDA】
②【深入浅出线性判别分析(LDA,从理论到代码实现)】




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











