







目录
一、引言
本文将并以DQN为主,依次介绍三大经典强化学习算法——Q-learning、DQN与DDQN,按网络实际运行流程,剖析其实现细节。
个人理解,学习记录,如有侵权,联系删除。
二、q-learning
强化学习在于环境交互中需要存储状态、动作到Q表中,
缺点:在现实世界中,状态的数量可能是巨大的,因此使得构建一个表在计算上很难。
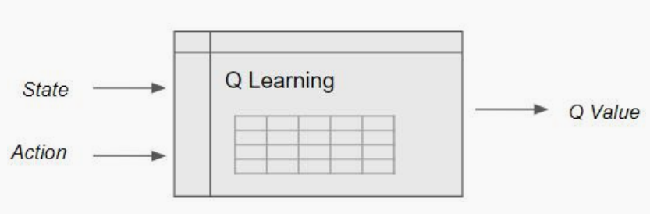
因此,用函数代替q表,即得到Q-learning算法
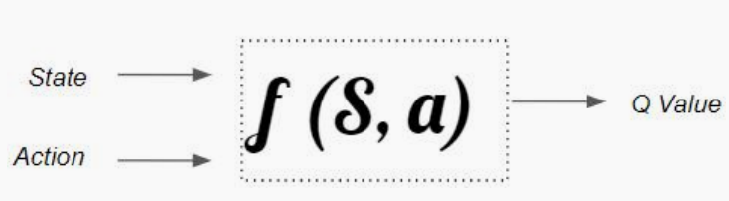
三、DQN
q-learning的缺点:函数单一,难以描述复杂的真实场景
神经网络是最佳函数逼近器,其对复杂函数的建模能力很强,所以我们可以使用一个神经网络,即深度Q网络来估计这个Q函数。

3.1 DQN具体组成
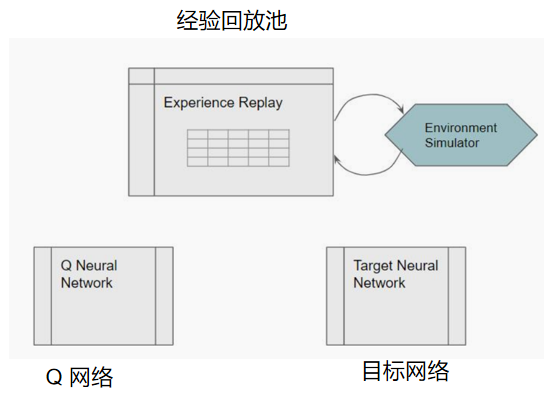
如果状态可以通过一组数字变量表示,则可以使用两个隐藏层组成网络。如果状态数据以图像或文本形式表示,则可以使用常规的CNN或RNN体系结构。
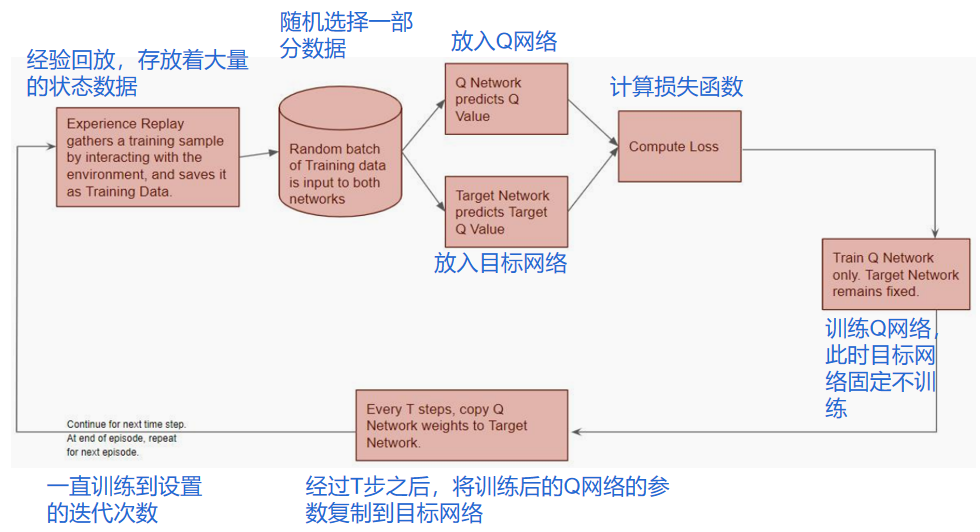
3.2 DQN工作流程
下图表示了DQN网络的数据存放与取出、样本放入两个Q网络、损失函数、训练、参数复制、存储经验的流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









