




 超级会员免费看
超级会员免费看
微信公众号、知乎号(同名):李歪理,欢迎大家关注
1. 双深度Q网络
本章我们介绍训练深度Q网络的一些技巧。第一个技巧是双深度Q网络(double DQN,DDQN)。为什么要有DDQN呢?因为在实现上,Q 值往往是被高估的。如图 7.1 所示,这里有 4 个不同的小游戏,横轴代表迭代轮次,红色锯齿状的一直在变的线表示Q函数对不同的状态估计的平均 Q 值,有很多不同的状态,每个状态我们都进行采样,算出它们的 Q 值,然后进行平均。这条红色锯齿状的线在训练的过程中会改变,但它是不断上升的。因为Q函数是取决于策略的,在学习的过程中策略越来越强,我们得到的 Q 值会越来越大。在同一个状态, 我们得到奖励的期望会越来越大,所以一般而言,Q值都是上升的,但这是深度Q网络预估出来的值。接下来我们就用策略去玩游戏,玩很多次,比如100万次,然后计算在某一个状态下,我们得到的 Q 值是多少。我们会得到在某一个状态采取某一个动作的累积奖励是多少。预估出来的值远比真实值大,且大很多,在每一个游戏中都是这样。所以DDQN的方法可以让预估值与真实值比较接近。
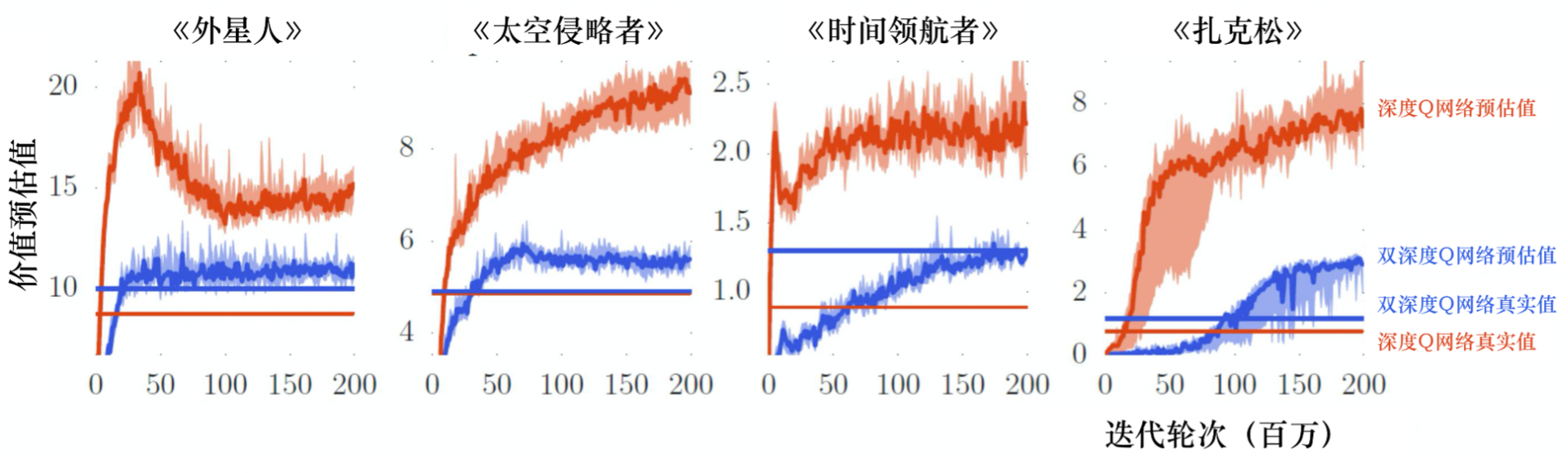
图 1 中蓝色的锯齿状的线是 DDQN 的Q网络所估测出来的 Q 值,蓝色的无锯齿状的线是真正的 Q 值,它们是比较接近的。我们不用管用网络估测的值,它比较没有参考价值。我们用DDQN得出的真正的Q值在图 1 的3 种情况下都是比原来的深度Q网络高的,代表DDQN学习出来的策略比较强,所以实际上得到的奖励是比较大的。虽然一般的 深度

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3572
3572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











