







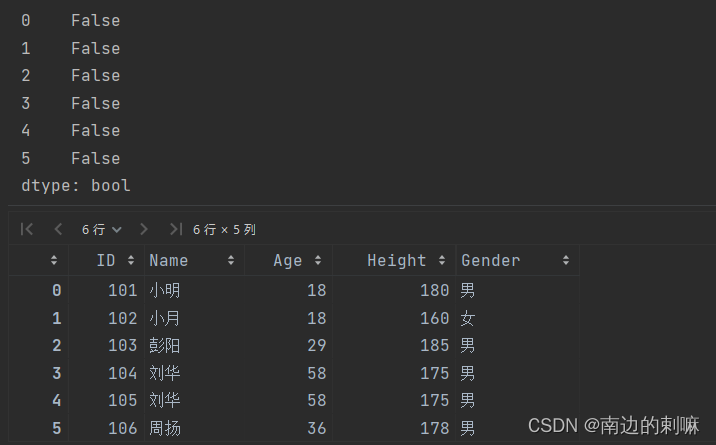
创建如下图所示DataFrame对象,并查找删除重复值,具体要求为:先查询后调用方法来处理重复值。(6分)
| ID | Name | Age | Height | Gender | |
| 0 | 101 | 小明 | 18 | 180 | 男 |
| 1 | 102 | 小月 | 18 | 160 | 女 |
| 2 | 103 | 彭阳 | 29 | 185 | 男 |
| 3 | 104 | 刘华 | 58 | 175 | 男 |
| 4 | 105 | 刘华 | 58 | 175 | 男 |
| 5 | 106 | 周扬 | 36 | 178 | 男 |
import pandas as pd
# 创建数据
data = {'ID': [101, 102, 103, 104, 105, 106],
'Name': ['小明', '小月', '彭阳', '刘华', '刘华', '周扬'],
'Age': [18, 18, 29, 58, 58, 36],
'Height': [180, 160, 185, 175, 175, 178],
'Gender': ['男', '女', '男', '男', '男', '男']}
# 创建DataFrame对象
df = pd.DataFrame(data)
# 查询重复值
duplicates = df.duplicated()
print(duplicates)
df.drop_duplicates()
df
结果:


















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









