







 文章讲述了在面临高并发问题时,如何利用Kafka进行系统优化。通过创建主题和分区,结合Reactor模型提高处理速度,利用PageCache和零拷贝技术提升IO性能,以及消息的批量和压缩发送,实现了服务的稳定和高效。此外,文章还提到了Kafka的消费机制和解决消息堆积的方法。
文章讲述了在面临高并发问题时,如何利用Kafka进行系统优化。通过创建主题和分区,结合Reactor模型提高处理速度,利用PageCache和零拷贝技术提升IO性能,以及消息的批量和压缩发送,实现了服务的稳定和高效。此外,文章还提到了Kafka的消费机制和解决消息堆积的方法。
我们在项目中或多或少都会遇到并发问题,当并发数达到一定量级后,对系统的压力是很大的,所以现在我结合工作中的项目,讲解一下,使用kafka进行优化,削峰填谷。如有不足,请多多指出,感谢大家~ ~ ~
项目背景
底座平台调取python服务在并发起来的时候会出现很大的延迟,严重的情况下可以打崩我们的服务,所引引入了kafka进行优化,在java中台对python的接口进行消费,对底座只保留两个接口,一个是创建任务接口,一个是查询任务接口,今天我们就来聊一聊kafka。
进入正题
我们在创建一个消息的时候,首先我们会给一个topic,也就是主题,创建多个partition,也就是分区。(对这一块名词不理解的可以先去查阅下kafka的结构,便于理解,后期有时间我会出一期介绍kafka的文章)。topic放在partition中,这样,生产者会进一步提升吞吐量。当然也不是分区越多越好,越多的分区需要打开更多的文件句柄,经验之谈,一般有多少个topic,就采用多个分区。
一台kafka服务器叫做一个Broker,kafka集群就是多台kafka服务器。一个topic对应多个partition,partition分布在多broker上,同一个topic下,多个partition经hash到不同的broker。
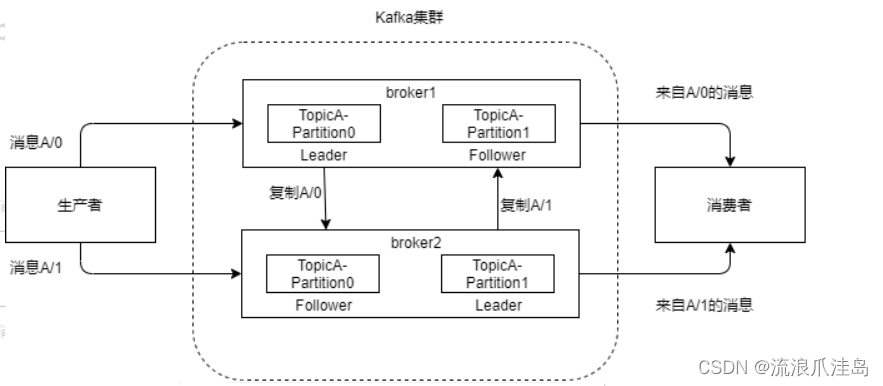
在数据的存储方面,分区是kafka并发处理数据的最小颗粒度,可以很好的解决存储扩散的问题。
消息在存储过程中,它会将消息存储到PageCache中,PageCache是内存存储的缓冲区,因为kafka的底层使用的是Java NIO,原理用到了Reactor模型进行设计,在IO效率上非常之快。
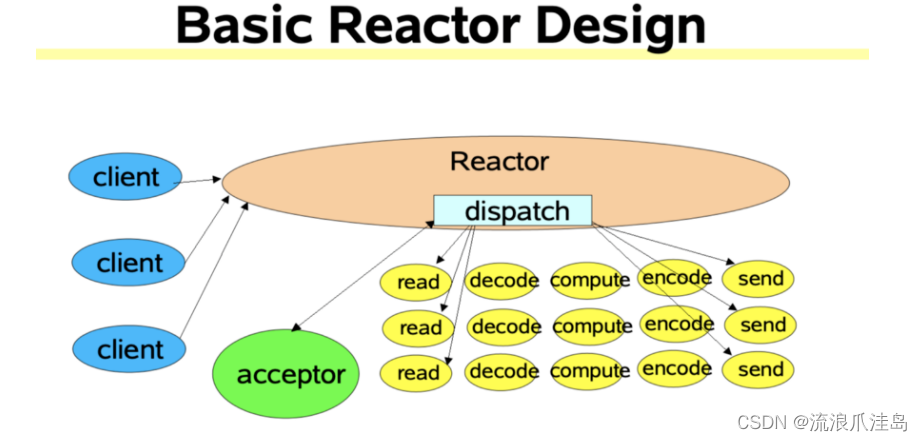
Reacotr 模型主要分为三个角色
Reactor:把 IO 事件分配给对应的 handler 处理
Acceptor:处理客户端连接事件
Handler:处理非阻塞的任务
Reactor 模型基于池化思想,避免为每个连接创建线程,连接完成后将业务处理交给线程池处理;基于 IO 复用模型,多个连接共用同一个阻塞对象,不用等待所有的连接。遍历到有新数据可以处理时,操作系统会通知程序,线程跳出阻塞状态,进行业务逻辑处理
Kafka 基于 Reactor 模型实现了多路复用和处理线程池,一个Acceptor线程,用于处理新的连接,Acceptor 有 N 个 Processor 线程 select 和 read socket 请求,N 个 Handler 线程处理请求并相应,即处理业务逻辑。
I/O 多路复用可以通过把多个 I/O 的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。它的最大优势是系统开销小,并且不需要创建新的进程或者线程,降低了系统的资源开销。
Kafka Producer 向 Broker 发送消息不是一条消息一条消息的发送,而是批量和压缩后发送的,压缩有助于提高吞吐量,降低延迟并提高磁盘利用率。
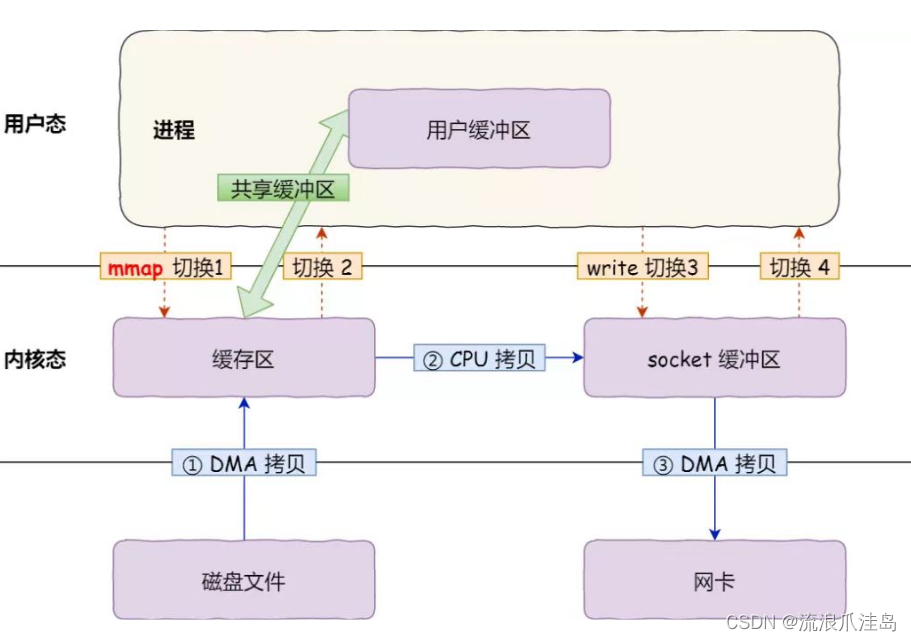
在写数据的过程中,kafka发送消息用到的是mmap+write()进行用户态和内核之间的数据交换。
消息写入到PageCache中,缓存到一定量之后(flush)刷到硬盘中,从而提高吞吐量。
mmap过程:
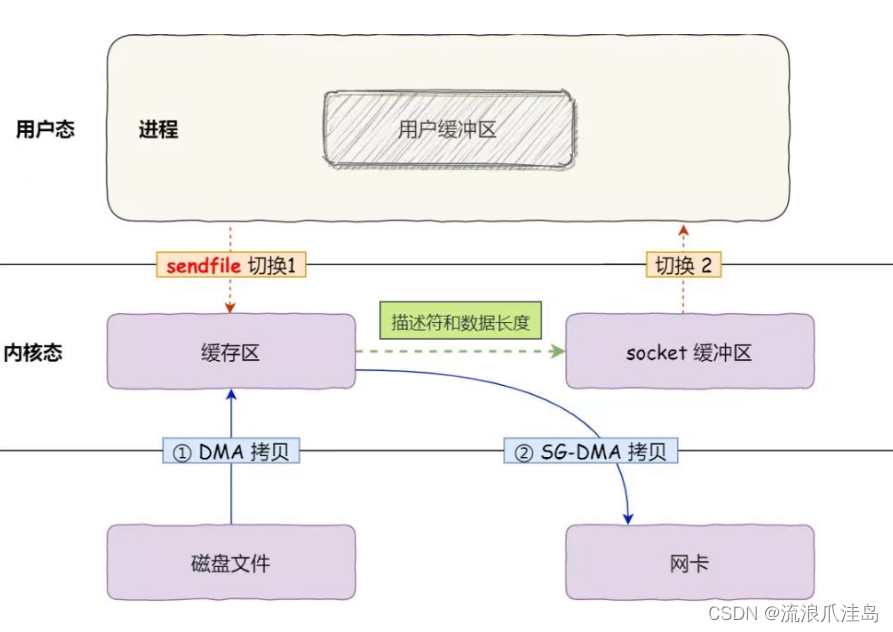
kafka如何消费数据
kafka之所以快,在消费消息的时候,通过sendfile()系统调用进行用户态和内核态的上下文切换,实现了零拷贝,学有余力的同学可以查阅下零拷贝。如果数据在PageCache中存在的话,这时候就会利用cpu拷贝将数据在PageCache中的内存地址,偏移量等描述信息复制到socket缓冲区中。MDA会通过在socket缓冲区的描述将对应的数据拷贝到网卡中,只有数据拷贝到网卡上面,消费者才能消费到这个数据。当所有的数据拷贝到网卡上,sendfile()函数就会返回,切换到用户态。(kafka消费消息会发起IO请求,若PageCache没有数据,会将磁盘中的数据拷贝到缓冲区)
sendfile
写在最后
消费者和生产者都使用到了PageCache,从而使消息的生产和消费都非常的快,除此之外,消费者还用到了零拷贝技术,大大提高IO性能,从而使消费能力进一步加强。
Tips
欢迎交流沟通,互相学习,有错误的地方还望博友指出问题所在,万分感谢,下期预告:kafka消息堆积怎么解决。再见!



















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











