






人体姿态识别介绍
PoseNet:是TensorFlow和谷歌创意实验室合作发布的专门用于在小程序平台上姿态预测的一种技术方案,于 2017年发布上一代姿态预测模型,目前该算法只是对图像中的人简单的预测身体关键位置所在,提供了 17个关键点,2D坐标,x和y以及关键点的可信度分数/置信度(范围在0.0-1.0之间,越接近1.0表示识别出来的点越正确)。PoseNet也可用于估计单个姿势(检测图像/视频中的一个人)或多个姿势(检测图像/视频中的多个人)。
备注:TensorFlow可支持创建移动、web、桌面、云环境的机器学习模型。
流程主要有两个阶段:
- 输入RGB 图像通过卷积神经网络馈送。
- 单姿势或多姿势解码算法用于解码来自模型输出姿势关键点、姿势置信度分数、关键点位置和关键点置信度分数。
MoveNet:最先进的姿态预测模型,有两个版本可供选择:Lightning 和 Thunder。在以下部分可以看到这两者之间的对比。
性能基准
MoveNet 有两种版本: - MoveNet.Lightning 比 Thunder 版更小、更快,但准确率较低。它可以在当下的智能手机上实时运行。
- MoveNet.Thunder 是更准确的版本,但比 Lightning 版更大、更慢。对于需要更高准确率的用例,它非常有用。
PoseNet与MoveNet比较:
MoveNet 在各种数据集上的表现都优于 PoseNet,尤其是在包含健身动作的图像上。因此,我们建议使用 MoveNet 而不是 PoseNet。
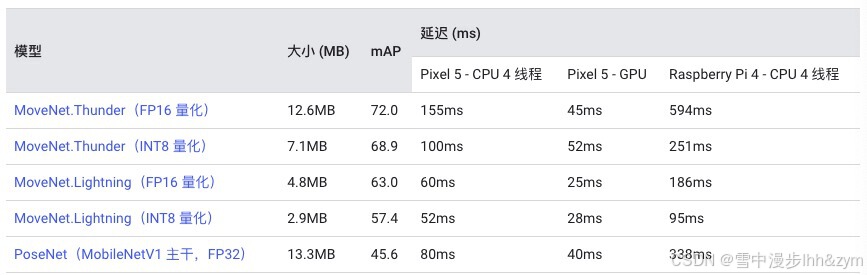
性能基准数值使用此处介绍的工具生成。准确率 (MAP) 数值在 COCO 数据集的子集上测得,在该数据集中,我们筛选并裁剪了每个图像,使其仅包含一个人。
参考地址:
- https://www.tensorflow.org/
- https://mp.weixin.qq.com/wxopen/plugindevdoc?appid=wx6afed118d9e81df9
- https://mp.weixin.qq.com/wxopen/plugindevdocappid=wx6afed118d9e81df9&token=468942979&lang=zh_CN
- https://blog.tensorflow.org/2022/01/body-segmentation.html

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









