




 本文对比了AutoRec的单隐层自编码,DeepCrossing的深度交叉网络和NeuralCF的神经网络增强矩阵分解,探讨了它们的结构、优点和局限性,适用于搜索广告和个性化推荐场景。
本文对比了AutoRec的单隐层自编码,DeepCrossing的深度交叉网络和NeuralCF的神经网络增强矩阵分解,探讨了它们的结构、优点和局限性,适用于搜索广告和个性化推荐场景。
| 模型 | 基本原理 | 具体细节 | 优缺点 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
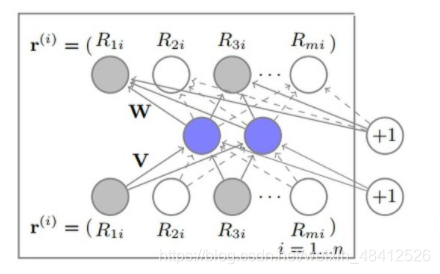
AutoRec 单隐层神经网络 |
将协同过滤中的共线矩阵的每一列(商品的初始向量),通过单隐层神经网络,完成商品向量的自编码,即商品向量的embedding (但是并没有实现降维度) 再利用自编码的结果得到用户对于物品的预估评分,进而进行推荐排序 |
|
优点:
缺点:
| ||||||||||||
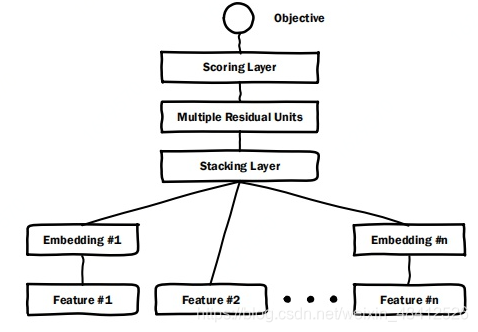
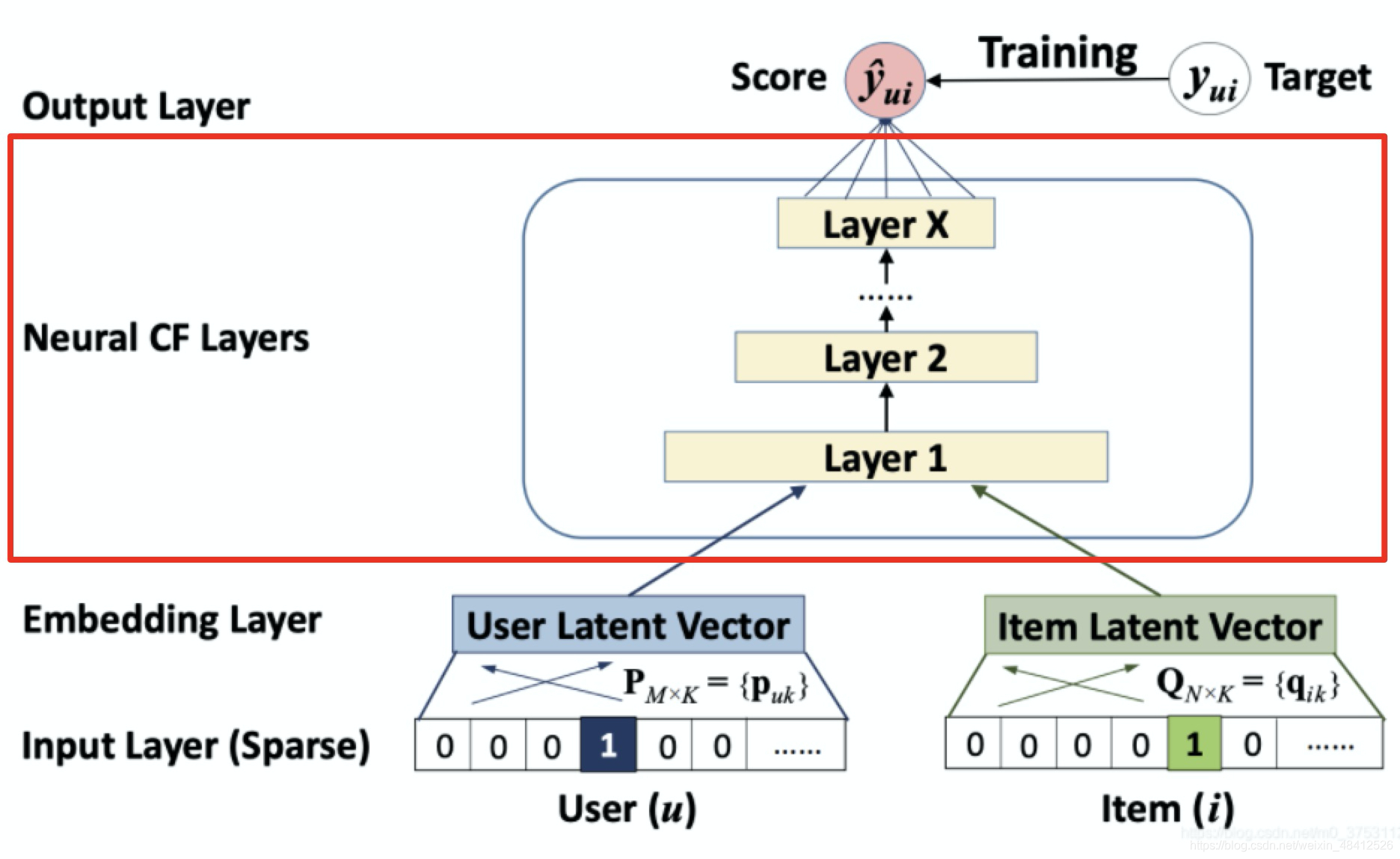
| Deep Crosssing |
利用“Embedding 层 + 多FC层 + 输出层” 的经典深度学习框架, 预完成特征的自动深度交叉 |
|
优点:
缺点:
| ||||||||||||
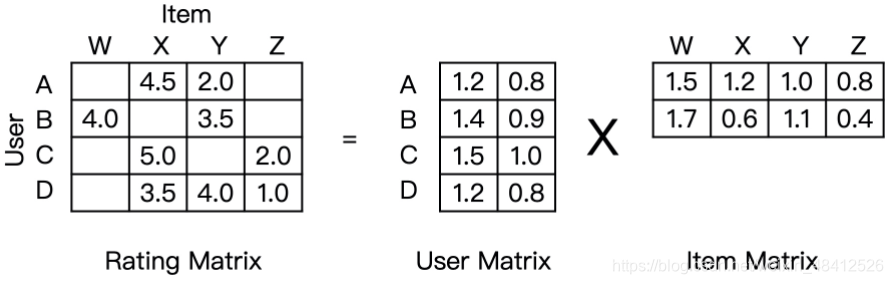
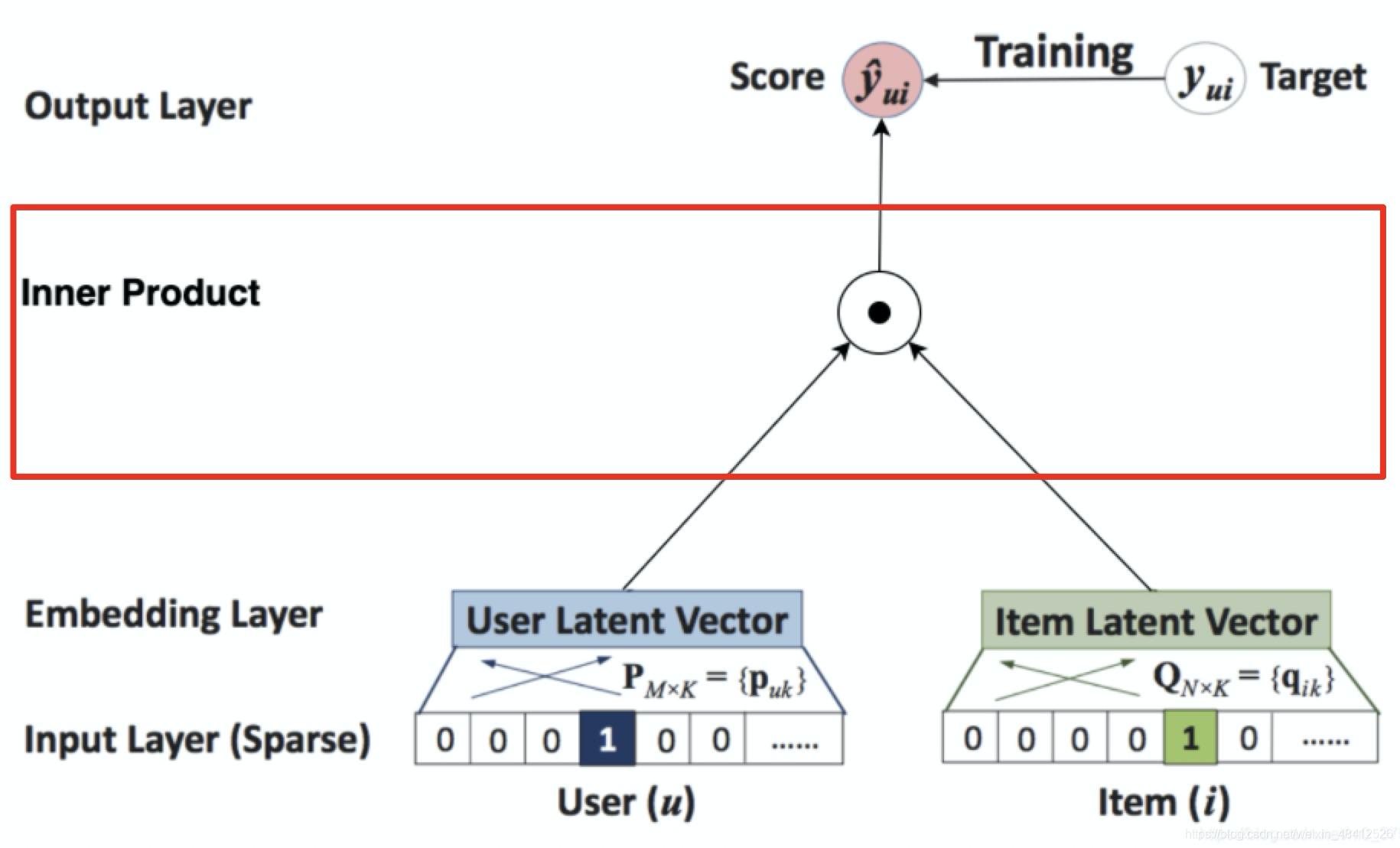
| NeuralCF | 将传统的矩阵分解中用户向量和物体向量的点积操作,换成由神经网络代替的互操作 |
|
优点:
缺点:
| ||||||||||||
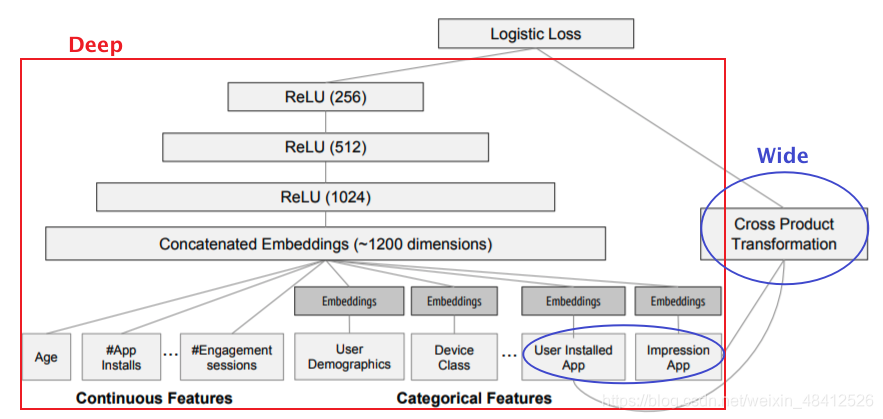
| Wide&Deep | 利用Wide部分加强模型的“记忆能力”,利用Deep部分加强模型的“泛化能力” |
|
优点:
缺点:
| ||||||||||||
| Deep&Cross | 用Cross网络替代Wide&Deep模型中的Wide部分 |
优点:
缺点:
| |||||||||||||
| FNN | 利用FM的参数来初始化深度神经网络的Embedding层参数 |
优点:
缺点:
| |||||||||||||
| DeepFM | 在Wide&Deep模型的基础上,用FM替代原来的xian |
优点:
缺点:
| |||||||||||||
| DIN | 在传统深度学习推荐模型的基础上引入注意力机制,并利用用户行为历史物品和目标广告物品的相关性计算注意力得分 |
优点:
缺点:
| |||||||||||||
| DIEN |
优点:
缺点:
| ||||||||||||||




















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









