




 本文介绍了腾讯音乐在全民K歌中如何进行内容推荐,特别是利用精排和粗排模型来优化用户体验。教师模型是一个复杂的全量特征模型,而学生模型简化为仅使用user和item特征。通过模型蒸馏,学生模型能效仿教师模型的输出,实现高效在线服务,用于生成用户和物品的嵌入向量,进行快速排序。
本文介绍了腾讯音乐在全民K歌中如何进行内容推荐,特别是利用精排和粗排模型来优化用户体验。教师模型是一个复杂的全量特征模型,而学生模型简化为仅使用user和item特征。通过模型蒸馏,学生模型能效仿教师模型的输出,实现高效在线服务,用于生成用户和物品的嵌入向量,进行快速排序。
业务背景:
全民K歌:
给用户进行内容推荐:
优质UGC(平台原创的优质素材)推荐
用户关注的内容
同城社交
货找人
| 阶段 |
目的 |
具体操作 |
|---|---|---|
| 召回 | 从海量的item中筛选小量级的用户可能感兴趣的内容 | 基于用户画像召回(用户感兴趣的歌曲/作者) 基于社交(用户社交圈的特点) 基于模型 |
| 粗排 | 把召回的十万量级的作品,缩减到万量级 因为算力的约束,精排的数量不大(千量级),如果直接从召回到精排,信息损失过多 |
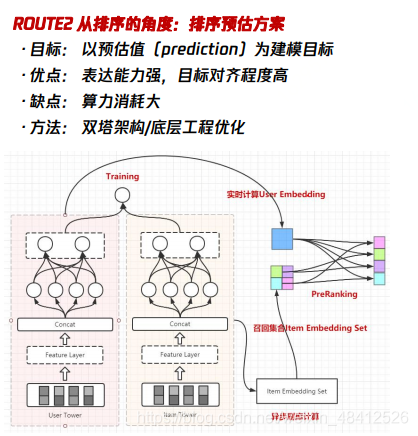
粗排的双塔模型实现
将user 和 item 的 feature进行结构解耦和分开建模。 user→ user feature → user embedding item→ item feature → item embedding user embedding跟item embedding之间做內积的运算,得到一个粗排的预估值 优点:user/item 结构解耦,内积计算算力小 缺点:特征表达缺失(难以使用user/item的交叉特征) 如何改进? 模型蒸馏 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









