







 本文详细讲解了Spark中的RDD操作,包括Transformation(如Pair RDD)和Action(如count、collect)。通过实例展示了如何进行WordCount统计,自定义排序以及最受欢迎的老师统计方法。文中还探讨了内存管理、分区策略以及如何避免内存溢出,强调了自定义分区器在减少shuffle次数中的作用。
本文详细讲解了Spark中的RDD操作,包括Transformation(如Pair RDD)和Action(如count、collect)。通过实例展示了如何进行WordCount统计,自定义排序以及最受欢迎的老师统计方法。文中还探讨了内存管理、分区策略以及如何避免内存溢出,强调了自定义分区器在减少shuffle次数中的作用。
目录
前言
RDD 基本概念
| RDD是什么 | 为什么需要RDD | RDD特性 |
| RDD 是一个可读的可分区的分布式数据集,RDD中保存着数据的转换关系,真正的数据存储在各个分区上。分区的设计可以让RDD中的数据被并行操作。
| 数据处理模型:用户友好型
RDD 的分区设计,使得数据可以被并行处理,提高效率。同时用户体验上,感觉让用户是在操作本地的一个集合。 不需要关心具体实现细节(文件分配在那几台机器上,怎么读取,如何汇总,是否会有机器故障等问题),只关心结果就好。
操作RDD就像操作一个本地集合一样简单。不关心任务调度和容错等问题。 容错处理。 | 1、Spark的核心概念是RDD (resilient distributed dataset(弹性分布式数据集)),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。 2、RDD是一个基本的抽象。RDD中不存真正要计算的数据,而是记录了RDD的转换关系(调用什么方法,传入什么函数)RDD是被分区的,真正的数据集存在各个分区(分区有编号)上,每个分区分布在集群中的不同Worker节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)通过对RDD执行操作,其实是对RDD的各个分区中的数据同时并行执行了操作,操作RDD就像操作一个本地集合一样,降低了编程的难度。 ps:同一个stage中,RDD中的一个分区对应一个task,一个分区对应的task只能运行在一台机器上(executor),但是一台机器上可以有多个分区对应的Task. 一个executor有几个线程,就可以同时支持几个task, 而线程的数量取决于executor资源的多少。 3、RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过RDD的本地创建转换而来。 4、传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。RDD正是解决这一缺点的抽象方法。 RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。 RDD的lineage特性。 5、RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性) 注意:RDD不是真正的存储数据的单元,RDD只是一个抽象的概念,数据真正存在在RDD对应的partition分区中 |
提示:以下是本篇文章正文内容,下面案例可供参考
一、Transformation
产生新的RDD
普通RDD + pair RDD
| 函数名 | 含义 | 输入 | 示例 | 结果 |
|---|---|---|---|---|
| union() | 生成一个包含两个RDD中所有元素的RDD,包含重复数据 | rdd={1,2,3}, other={3,4,5} scala中正式写法: rdd = sc.parallelize(List(1,2,3)) other = sc.parallelize(List(3,4,5)) | rdd.union(other) | {1,2,3,3,4,5} |
| intersection() | 求两个RDD共同的元素RDD, 自动去重(需要shuffle, 性能较union差) | rdd={1,2,3}, other={3,4,5} | rdd.intersection(other) | {3} |
| subtract() | 移除一个元素的内容(需要shuffle) | rdd={1,2,3}, other={3,4,5} | rdd.subtract(other) | {1,2} |
| cartesian() | 与另一个RDD的笛卡儿积, 选取的是两个RDD的元素的所有组合,开销巨大 | rdd={1,2,3}, other={3,4,5} | rdd.cartesian(other) | {(1,3),(1,4)...(3,5)} |
| map() | 函数应用于RDD中的每个元素 | rdd={1,2,3,3} | rdd.map(x=>x+1) | {2,3,4,4} |
| flatMap()和map()的区别: map会将一个长度为N的RDD转换为另一个长度为N的RDD; flatMap会将一个长度为N的RDD转换成一个N个元素的集合,然后再把这N个元素合成到一个单个RDD的结果集。 | rdd={"zwm hyh fyr", "zwm hyh zll lw"} | rdd.map(line => line.split(" ")) | {Array("zwm","hyh","fyr"), Array("zwm","hyh","zll","lw")}
| |
| flatMap() | 将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD | rdd={"zwm hyh fyr", "zwm hyh zll lw"} | rdd.flatMap(line => line.split(" ")) | {"zwm","hyh","fyr","zwm","hyh","zll","lw"} |
| filter() | 返回一个通过传给filter()的函数的元素组成的RDD | rdd={1,2,3,3} | rdd.filter(x=>x!=1) | {2,3,3} |
| distinct() | 去重( 需要经过数据混洗shuffle, 开销大) | rdd={1,2,3,3} | rdd.distinct() | {1,2,3} |
| sample(withReplacement,fraction,[seed]) | 对RDD进行采样,以及是否替换 | rdd.sample(false,0.5) | 非确定 |
Pair RDD
以下Transformation操作只作用于Pair RDD {(key1,value1),(key 2,value 2),(key 3,value 3)} 都作用于相同key的value上
| 函数名 | 含义 | 输入 | 示例 | 结果 |
|---|---|---|---|---|
| mapValues(f) | 对键值对中的每个value应用一个函数,但不改变键key, 原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素 | rdd={(1,2),(3,4),(3,6)} | rdd.mapValues(x => x+1) | { (1,3) , (3,5) , (3,7) } |
| flatMapValues(f) | 每个一元素的Value被f映射为一系列的值 | rdd={(1,2),(3,4),(3,6)} | rdd.flatMapValues(x => ( x to 5 )) 对于每个元素中的value, 都执行从value到5间的所有元素 比如对于元素(1,2), 执行结果就是(1,2), (1,3), (1,4), (1,5) | { (1, 2) , (1, 3) , (1, 4) , (1, 5) , (3, 4) , (3, 5) } |
| reduceByKey(f) 作用于具有相同Key 的value上 | 合并key相同的值(value),返回一个由各个key以及各key归约出的结果值的新RDD (key1, result1), (key2, result2), …(keyN, resultN) | rdd={(1,2),(1,7),(1,3),(3,4),(3,6)} | rdd.reduceByKey( ( x,y) => x+y ) 将具有相同key的value相加 此处的x,y 是具有相同key的value,如果key = 1, 则x=2, y=7, z=3, ruduceByKey执行的是把xyz相加得12,若key =3, 则x=4, y=6,ruduceByKey执行的是把xy相加得10 | { (1,12) , (3,10) } |
| groupBy() | 对集合中的元素进行分组操作,结果是得到 (key1, (val1, val2)), (key2, (val1, val2)) | rdd= {(java,2), (java,3),(python,3),(python,3),(python,4)} | rdd.groupBy(_._1) 将具有相同key的value变成一个迭代器 | { (java, (2, 3)), |
| groupByKey() | 对具有相同key的值(value)分组 | rdd={(jave,2), (bigdata,4), (bigdata,6)} | rdd.groupByKey() | { (java,2) , (bigdata, [4,6] ) } |
| combineByKey( createCombiner, mergeValue, mergeCombiners, partitioner) createCombiner:分区内 创建组合函数 mergeValue:分区内 合并值函数 mergeCombiners:多分区 合并组合器函数 partitioner:自定义分区数,默认为HashPartitioner mapSideCombine:是否在map端进行Combine操作,默认为true | 使用不同的返回类型合并具有相同键的值 combineByKey会遍历分区中的所有元素,因此每个元素的key要么没遇到过,要么和之前某个元素的key相同。 如果这是一个新的元素,函数会调用createCombiner创建那个key对应的累加器初始值。 如果这是一个在处理当前分区之前已经遇到的key,会调用mergeCombiners把该key累加器对应的当前value与这个新的value合并。 | rdd={("男", "李四"), ("男", "张三"), ("女", "韩梅梅"), ("女", "李思思"), ("男", "马云")} | rdd.combineByKey( (x: String) => (List(x), 1), // 元素中的key是首次遇到时,对该key的vaule执行createCombiner (peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1), //元素中key非首次遇到,对value执行mergeValue,累加value (sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2)) //mergeCombiners 合并分区时用 这里面的x,peo,sex1全部都是value | (男, ( List( 张三, 李四, 马云),3 ) ) (女, ( List( 李思思, 韩梅梅),2 ) ) 注: elem::List 表示把elem加到List头部 List1:::List2 表示连接两个List |
| val rdd08 = sc.parallelize (List((1, 1), (1, 4), (1, 3), (3, 7), (3, 5))) | val result = rdd08.combineByKey( (v) => (v, 1), (acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), (acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) ).map{ case (key, value) => (key, value._1 / value._2.toFloat) } result.collectAsMap().map(println(_)) | (1,2.66667), (3,6) | ||
| keys() | 获取所有key | rdd={(1,2),(3,4),(3,6)} | rdd.keys | {1,3,3} |
| values() | 获取所有value | rdd={(1,2),(3,4),(3,6)} | rdd.values | {2,4,6} |
| sortByKey() | 根据key排序 | rdd={(1,2),(3,4),(3,6)} | rdd.sortByKey() | { (1,2) , (3,4) , (3,6) } |
| subtractByKey | 删掉rdd1中与rdd2的key相同的元素 | rdd1={(1,2),(3,4),(3,6)}, rdd2={(3,9)} | rdd1.subtractByKey(rdd2) | { (1,2) } |
| join | 内连接 | rdd1={(1,2),(3,4),(3,6)}, rdd2={(3,9)} | rdd1.join(rdd2) | {(3, (4, 9)), (3, (6, 9))} |
| leftOuterJoin | 左外链接,确保左边的RDD的key必须存在 | rdd1={(1,2),(3,4),(3,6)}, rdd2={(3,9)} | rdd1.leftOuterJoin (rdd2) | {(1,( 2, None)), (3, (4, Some( 9))), (3, (6, Some( 9)))} |
| rightOuterJoin | 右外链接,确保右边的RDD的key必须存在 | rdd1={(1,2),(3,4),(3,6)}, rdd2={(3,9)} | rdd1.rightOuterJoin(rdd2) | {(3,( Some( 4), 9)), (3,( Some( 6), 9))} |
| cogroup | 将两个RDD中相同key的数据分组到一起 | rdd1={(1,2),(3,4),(3,6)}, rdd2={(3,9)} | rdd1.cogroup(rdd2) | {(1,([ 2],[])), (3, ([4, 6],[ 9]))} |
二、Action 操作
可以看出 action 的所有操作都是针对数据集中 “元素” (element) 级别的动作, action 的主要内容是 存储 和 计算.
观察函数的返回类型:如果返回的是 RDD 类型,那么这是 transformation; 如果返回的是其他数据类型,那么这是 action.
| 函数名 | 含义 | 输入 | 示例 | 结果 | |
|---|---|---|---|---|---|
| 获取元素 | collect() | 在 driver program 上将数据集中的元素作为一个数组返回. 这在执行一个 filter 或是其他返回一个足够小的子数据集操作后十分有用. | |||
| first() | 返回数据集中的第一个元素 (与 take(1) 类似),没有排序 | rdd={1,3,4,5,2} | rdd.take(1) | Int =1 | |
| take(n) | 返回数据集中的前 n 个元素,没有排序 | rdd={1,3,4,5,2} | rdd.take(2) | Array(1,3) | |
| top(n) | 将数据降序排序,然后返回最大的两个(在数组中)到driver端 | rdd={1,3,4,5,2} | rdd.top(2) | Array(5,4) | |
| takeSample(withReplacement, num, [seed]) | 以数组的形式返回数据集中随机采样的 num 个元素. | ||||
| takeOrdered(n, [ordering]) | 将RDD升序排序(默认)后,返回 排序后的RDD 的前 n 元素 | rdd={1,3,4,5,2} | rdd.takeOrdered(3) | Array(1, 2, 3) | |
| 保存元素 | saveAsTextFile(path) | 将数据集中的元素写入到指定目录下的一个或多个文本文件中, 该目录可以存在于本地文件系统, HDFS 或其他 Hadoop 支持的文件系统. Spark 将会对每个元素调用 toString 将其转换为文件的一行文本. | |||
| saveAsSequenceFile(path)(Java and Scala) | 对于本地文件系统, HDFS 或其他任何 Hadoop 支持的文件系统上的一个指定路径, 将数据集中的元素写为一个 Hadoop SequenceFile. 仅适用于实现了 Hadoop Writable 接口的 kay-value pair 的 RDD. 在 Scala 中, 同样适用于能够被隐式转换成 Writable 的类型上 (Spark 包含了对于 Int, Double, String 等基本类型的转换). | ||||
| saveAsObjectFile(path)(Java and Scala) | 使用 Java 序列化将数据集中的元素简单写为格式化数据, 可以通过 SparkContext.objectFile() 进行加载. | ||||
| 计数元素 | countByValue() | 各元素在rdd中出现的次数 | RDD={1, 2, 3, 3} | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| count() | 返回数据集中的元素个数 | RDD={1, 2, 3, 3} | rdd.count() | 4 | |
| 迭代元素 | reduce(func) | 并行整合RDD中的所有数据,返回一个值 | RDD={1, 2, 3, 3} | rdd.reduce((x,y)=>x+y) | 9 |
| foreach(func) | 对数据集中的每个元素执行函数 func. | list = {'"zwm","fyr","zll"} | list.foreach(println) | zwm fyr zll |
Pair RDD
| 函数名 | 目的 | 输入 | 示例 | 结果 |
|---|---|---|---|---|
| countByKey() | 对每个键对应的元素分别计数 | RDD={(1, 2), (3, 4), (3, 6)} | rdd.countByKey() | {(1, 1), (3, 2)} |
| collectAsMap() | 将结果以映射表的形式返回,以便查询 | RDD={(1, 2), (3, 4), (3, 6)} | rdd.collectAsMap() | Map{(1, 2), (3,6)} |
| lookup(key) | lookup(key) 返回给定键对应的所有值 | RDD={(1, 2), (3, 4), (3, 6)} | rdd.lookup(3) | [4, 6] |
三、WordCount
统计文章中word及其出现的次数
object WordCount {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[3]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
//指定以后从哪里读取数据创建RDD(弹性分布式系统)
//参数1:读取文件的路径,
//参数2:RDD的最小分区数,也就是以后task的数目
//读取HDFS里面的文件,会有默认分区(有多少个数据切片parquet,就有多少个数据分区)
// Ctrl + Alt + V 可以自动生成变量名和变量类型
// 读取数据{ "zhengweiming huangyuhan fengyurun", "zhengweiming huangyuhan zhanlanglang jumingxing halokitty"}
val lines: RDD[String] = sc.textFile("D:\\学习\\Learning\\Scala\\WordCount\\wordCount.txt")
//切分压平, 把句子切成单词 {"zhengweiming","huangyuhan", "fengyurun", "zhengweiming", "huangyuhan", "zhanlanglang", "jumingxing", "halokitty"}
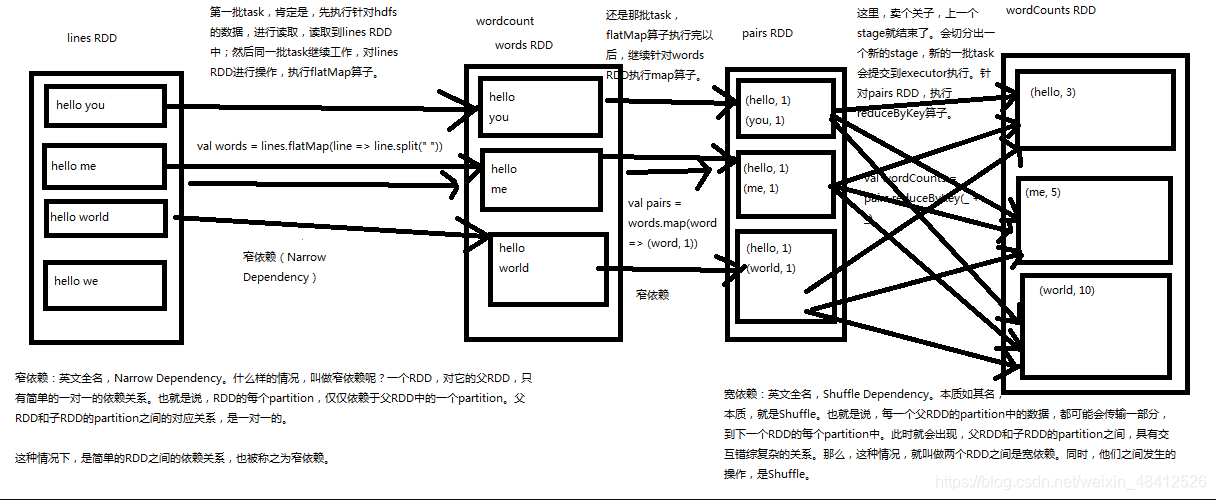
val words: RDD[String] = lines.flatMap(line => line.split(" "))
//注意如果这里用map,那么会变成 {Array("zhengweiming","huangyuhan", "fengyurun"), Array("zhengweiming", "huangyuhan", "zhanlanglang", "jumingxing", "halokitty")}
//val words: RDD[Array[String]] = lines.map(line => line.split(" "))
//将单词和1组合, word -> (word, 1)输出{("zhengweiming",1),("huangyuhan",1),("fengyurun",1),("zhengweiming",1),("huangyuhan",1),("zhanlanglang",1),("jumingxing",1),("halokitty",1)}
val wordAndOne: RDD[(String, Int)] = words.map(word => (word, 1))
//将元组(word, 1) 按key(word)进行聚合, 统计单词的次数 {("huangyuhan",2), ("jumingxing",1),("zhengweiming",2),("fengyurun",1),("halokitty",1) ,("zhanlanglang",1)}
val reduceByKey: RDD[(String, Int)] = wordAndOne.reduceByKey((value1, value2) => (value1 + value2))
//排序 {("huangyuhan",2),("zhengweiming",2), ("jumingxing",1),("fengyurun",1),("halokitty",1) ,("zhanlanglang",1)}
val sorted: RDD[(String, Int)] = reduceByKey.sortBy(keyValue => keyValue._2, false)
}
}执行过程详情
四、自定义排序
目标:先将数据集按照faceLevel从高到低排,faceLevel相同的,按照age从低到高排
数据集如下:
| name | age | faceLevel |
|---|---|---|
| laoduan | 30 | 99 |
| laozhao | 29 | 9999 |
| laozhang | 28 | 99 |
思路:
将要排序的内容封装在一个自定义的类中,在类里面重写compare函数
问题点:
- 为什么在User类中重写toString方法,可以将最后的结果转为string?
这个取决于println方法。如果println的内容是string/int,那么直接打印。如果是对象,那么就会调用对象内部的tostring方法。一般默认的toString方法输出的都是对象名。此处对toString进行重写,那么就可以println出对象的内容
- 为什么userRDD.sortBy(u=>u)可以实现排序?
sortBy函数接受的如果是基础类型,那么可以自行排序,调用的是默认的compare方法,将传入的一组数两两比较,比较A和B的时候,调用的是A.compare(B), 此时this指代的是A,that指代的是B, compare返回的是一个int,如果A.compare(B) > 0, 那么默认A比B大, A排在B后面。
但是此时是对象。那么就会调用对象内部自定义的compare算法.this 指代当前对象,that指代要比较的对象。
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
// 将要排序的数据封装于User类中。shuffle意味着封装数据的类要支持可序列化,所以将user类继承于Serializable
class User(val name:String, val age:Int, val faceLevel:Int) extends Ordered[User] with Serializable {
// 重写compare函数,自定义排序规则:首先按照faceLevel从高到低排,颜值相同的,再按照年龄从低到高排
override def compare(that: User): Int = {
if (this.faceLevel == that.faceLevel){
this.age - that.age
}else{
-(this.faceLevel - that.faceLevel)
}
}
// 将结果定义成string格式
override def toString: String = s"name: $name, age: $age, faceLeval: $faceLevel"
}
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据 "name, age, faceLevel"
val test_data: Array[String] = Array("laoduan 30 99",
"laozhao 29 9999",
"laozhang 28 99")
val data: RDD[String] = sc.parallelize(test_data)
// 从数据源中提取出name, age, faceLevel,并将其封装于User这个类中
val userRDD: RDD[User] = data.map(line => {
val fields = line.split(" ")
val name = fields(0)
val age = fields(1).toInt
val faceLevel = fields(2).toInt
new User(name, age, faceLevel)
})
val sorted: RDD[User] = userRDD.sortBy(u=>u)
val result: Array[User] = sorted.collect()
/*
name: laozhao, age: 29, faceLeval: 9999
name: laozhang, age: 28, faceLeval: 99
name: laoduan, age: 30, faceLeval: 99
*/
// result中的每个元素是User对象,println的时候会自动调用对象中的toString函数,默认的是返回对象信息如User@123,但是此处,在User对象中重写了toString方法,打印了对象中的内容
result.foreach(println)
print("hhhhhh")
}
}方法2:
将数据存在tuple中,然后在sortBy方法中定义排序规则。
在类中定义新的排序规则
sortBy 不会改变数据内容,只是按照规则排好顺序后返回
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
// 排序:首先按照faceLevel从高到低排,颜值相同的,再按照年龄从低到高排
// case class 默认继承了Serializable, 同时case class不需要new一个实例
case class Man(age:Int, faceLevel:Int) extends Ordered[Man]{
override def compare(that: Man): Int = {
if (this.faceLevel == that.faceLevel){
this.age - that.age
}else{
-(this.faceLevel - that.faceLevel)
}
}
}
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据 "name, age, faceLevel"
val test_data: Array[String] = Array("laoduan 30 99",
"laozhao 29 9999",
"laozhang 28 99")
val data: RDD[String] = sc.parallelize(test_data)
// 从数据源中提取出name, age, faceLevel
val tpRDD: RDD[(String, Int, Int)] = data.map(line => {
val fields = line.split(" ")
val name = fields(0)
val age = fields(1).toInt
val faceLevel = fields(2).toInt
(name, age, faceLevel)
})
// 排序(传入排序规则,不会改变数据格式,只会改变顺序)数据始终保存在tuple中
// 因为Man是case class, 所以实例化不需要在前面加new
val sorted: RDD[(String, Int, Int)] = tpRDD.sortBy(tp => Man(tp._2,tp._3))
val result: Array[(String, Int, Int)] = sorted.collect()
result.foreach(println)
print("hhhhhh")
}
}方法3:
首先创建一个文件object.class
在里面创建一个对象:Odered,继承类为Ordering[Man]
object Ordered {
implicit object OrderRules extends Ordering[Man] {
override def compare(x: Man, y: Man): Int = {
if (x.faceLevel == y.faceLevel) {
x.age - y.age
} else {
-(x.faceLevel - y.faceLevel)
}
}
}
}再创建一个主类
定义一个case class Man 的对象
再import Ordered内容
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
// 排序:首先按照faceLevel从高到低排,颜值相同的,再按照年龄从低到高排
// case class 默认继承了Serializable, 同时case class不需要new一个实例
case class Man(age:Int, faceLevel:Int)
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据 "name, age, faceLevel"
val test_data: Array[String] = Array("laoduan 30 99",
"laozhao 29 9999",
"laozhang 28 99")
val data: RDD[String] = sc.parallelize(test_data)
// 从数据源中提取出name, age, faceLevel
val tpRDD: RDD[(String, Int, Int)] = data.map(line => {
val fields = line.split(" ")
val name = fields(0)
val age = fields(1).toInt
val faceLevel = fields(2).toInt
(name, age, faceLevel)
})
// 排序(传入排序规则,不会改变数据格式,只会改变顺序)数据始终保存在tuple中
// 排序规则定义在Man中,而Man定义在Ordered的OrderRules中
import Ordered.OrderRules
val sorted: RDD[(String, Int, Int)] = tpRDD.sortBy(tp => Man(tp._2,tp._3))
val result: Array[(String, Int, Int)] = sorted.collect()
result.foreach(println)
print("hhhhhh")
}
}方法三
按照元组的排序规则
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
// 排序:首先按照faceLevel从高到低排,颜值相同的,再按照年龄从低到高排
// case class 默认继承了Serializable, 同时case class不需要new一个实例
case class Man(age:Int, faceLevel:Int)
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据 "name, age, faceLevel"
val test_data: Array[String] = Array("laoduan 30 99",
"laozhao 29 9999",
"laozhang 28 99")
val data: RDD[String] = sc.parallelize(test_data)
// 从数据源中提取出name, age, faceLevel
val tpRDD: RDD[(String, Int, Int)] = data.map(line => {
val fields = line.split(" ")
val name = fields(0)
val age = fields(1).toInt
val faceLevel = fields(2).toInt
(name, age, faceLevel)
})
// 排序(传入排序规则,不会改变数据格式,只会改变顺序)数据始终保存在tuple中
// 使用元祖的比较规则:首先比第一个元素,第一个元素相同,则开始比较第二个。默认升序,如果要降序,需要在前面加负号
val sorted: RDD[(String, Int, Int)] = tpRDD.sortBy(tp => (-tp._3,tp._2))
val result: Array[(String, Int, Int)] = sorted.collect()
result.foreach(println)
print("hhhhhh")
}
}方法四
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
// 排序:首先按照faceLevel从高到低排,颜值相同的,再按照年龄从低到高排
// case class 默认继承了Serializable, 同时case class不需要new一个实例
case class Man(age:Int, faceLevel:Int)
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据 "name, age, faceLevel"
val test_data: Array[String] = Array("laoduan 30 99",
"laozhao 29 9999",
"laozhang 28 99")
val data: RDD[String] = sc.parallelize(test_data)
// 从数据源中提取出name, age, faceLevel
val tpRDD = data.map(line => {
val fields = line.split(" ")
val name = fields(0)
val age = fields(1).toInt
val faceLevel = fields(2).toInt
(name, age, faceLevel )
})
// 排序(传入排序规则,不会改变数据格式,只会改变顺序)数据始终保存在tuple中
// Ordering[(Int,Int)] 最终比较的规则格式 (-faceLevel,age)
// on[(String,Int,Int)] 未比较之前的数据格式 (name,age,faceLevel)
// (t => (-t._3,t._2)) 怎样将规则转换成要比较的格式
implicit val rules = Ordering[(Int,Int)].on[(String,Int,Int)](t => (-t._3,t._2))
val sorted = tpRDD.sortBy(tp => tp)
val result = sorted.collect()
result.foreach(println)
print("hhhhhh")
}
}五、最受欢迎的老师
根据以下内容,统计出最受欢迎的老师
http://bigdata.edu365.cn/laozhang
http://bigdata.edu365.cn/laozhang
http://bigdata.edu365.cn/laozhang
http://bigdata.edu365.cn/laozhang
http://bigdata.edu365.cn/laoduan
http://bigdata.edu365.cn/laoduan
http://bigdata.edu365.cn/laozhao
http://bigdata.edu365.cn/laozhao
http://bigdata.edu365.cn/laozhang
http://bigdata.edu365.cn/laozhang
http://javaee.edu365.cn/laozhang
http://javaee.edu365.cn/laozhang
http://bigdata.edu365.cn/laozhao
http://bigdata.edu365.cn/laozhang
http://javaee.edu365.cn/laozhao
http://javaee.edu365.cn/laozhuan
http://javaee.edu365.cn/laozhuanobject Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[3]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据
val data: RDD[String] = sc.textFile("D:\\学习\\Learning\\Scala\\popularTeacher.txt")
// 对数据进行分割,返回{(teacherName1,1), (teacherName2,1)}
val teaData: RDD[(String, Int)] = data.map(line => {
val teacher = line.split('/').last
(teacher, 1)
})
// 对相同的key的数量进行聚合,统计key出现的次数
val cntData: RDD[(String, Int)] = teaData.reduceByKey((x,y) => x+y)
// 根据key出现的次数进行排序
val result: Array[String] = cntData.sortBy(value => value._2).top(3).map(value => value._1)
result.foreach(println)
}
}统计每个学科中最受欢迎的老师
分组统计
思路:先通过groupby 进行分组。同一学科的数据都收集到一个组内。(同一组内的数据肯定在同一分区/机器上,但是一个分区内可能包含多个组的数据),一个组/学科对应一个迭代器。将其读取到一台机器的内存上通过scala的sortBy方法进行全局排序。
优点:只在最后result.collect() 触发了一次action,向集群提交任务
缺点:读取到内存内再进行排序,如果某个学科下对应的数据特别特别多,那么可能会有内存溢出的风险
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//import org.apache.spark.sql.types.{DoubleType, StringType}
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据
val test_data = Array("http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhao",
"http://javaee.edu365.cn/laozhuan",
"http://javaee.edu365.cn/laozhuan")
val data = sc.parallelize(test_data)
// 从数据源中提取出subject和teacher,然后以(subject,teacher)为主键来统计个数
val subjectTeacherAndOne: RDD[((String, String), Int)] = data.map(line => {
val teacher = line.split('/').last
val subject = line.split('/')(2).split('.')(0)
//println(s"(($subject,$teacher),1)")
((subject,teacher),1)
})
// 统计每个老师在每个学科下出现的次数
val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey((x,y) => x+y)
println("----------------reduced----------------")
reduced.collect().foreach(println)
/*
----------------reduced----------------
((bigdata,laozhang),7)
((javaee,laozhuan),2)
((bigdata,laozhao),3)
((javaee,laozhao),1)
((bigdata,laoduan),2)
((javaee,laozhang),2)
*/
// 分组排序,在每个subject下根据teacher出现的次数进行排序
val grouped: RDD[(String, Iterable[((String, String), Int)])] = reduced.groupBy(_._1._1)
println("----------------grouped----------------")
grouped.collect().foreach(println)
/*
----------------grouped----------------
(javaee,CompactBuffer(((javaee,laozhuan),2), ((javaee,laozhao),1), ((javaee,laozhang),2)))
(bigdata,CompactBuffer(((bigdata,laozhang),7), ((bigdata,laozhao),3), ((bigdata,laoduan),2)))
*/
// 迭代器类似于一个指针,里面没有存储数据,但是可以通过迭代器的信息拿到数据。所以要进行排序,就需要首先将数据存到内存里面,然后排序
// 组内排序:先用groupBy进行分组,然后用mapValue在组内进行排序
val sorted: RDD[(String, List[((String, String), Int)])] = grouped.mapValues(value => value.toList.sortBy(_._2).reverse.take(3))
println("----------------sorted----------------")
sorted.collect().foreach(println)
/*
----------------sorted----------------
(javaee,List(((javaee,laozhang),2), ((javaee,laozhuan),2), ((javaee,laozhao),1)))
(bigdata,List(((bigdata,laozhang),7), ((bigdata,laozhao),3), ((bigdata,laoduan),2)))
*/
//接下来是根据排序结果,打印出老师
val result = sorted.mapValues(value => value.map(x => x._1._2))
println("----------------result----------------")
result.collect().foreach(println)
/*
----------------result----------------
(javaee,List(laozhang, laozhuan, laozhao))
(bigdata,List(laozhang, laozhao, laoduan))
*/
}
}
多次过滤
思路:首先得到所有的学科,之后对于每个学科都过滤出其对应的数据集,调用RDD的sortBy方法进行排序
优点:RDD的sortBy 方法,将数据放在内存和磁盘中,而且可以在多台机器上并行排序。 不会有内存溢出的问题
缺点:每个学科都会触发一次action 操作(take)
import org.apache.spark.ml.linalg.{Vector => mlVector}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//import org.apache.spark.sql.types.{DoubleType, StringType}
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据
val test_data = Array("http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhao",
"http://javaee.edu365.cn/laozhuan",
"http://javaee.edu365.cn/laozhuan")
val data = sc.parallelize(test_data)
// 统计出数据集中所有的学科
val subList: Array[String] = data.map(line => line.split('/')(2).split('.')(0)).collect().distinct
subList.foreach(println)
// 从数据源中提取出subject和teacher,然后以(subject,teacher)为主键来统计个数
val subjectTeacherAndOne: RDD[((String, String), Int)] = data.map(line => {
val teacher = line.split('/').last
val subject = line.split('/')(2).split('.')(0)
//println(s"(($subject,$teacher),1)")
((subject,teacher),1)
})
// 统计每个老师在每个学科下出现的次数
val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey((x,y) => x+y)
// cache到内存,方便以后反复使用
val reduced = reduced.cache()
println("----------------reduced----------------")
reduced.collect().foreach(println)
// scala的集合排序是把数据全部拉取到一台机器上,并在内存中进行排序,存在内存溢出的风险
// 可以调用rdd的排序方法:数据可以存储在内存+磁盘中,并且可在多台机器上并行排序
// 首先把每个学科的数据过滤出来。然后在过滤后的数据中调用rdd排序
println("----------------sorted----------------")
var sub =""
for (sub <- subList){
// filtered RDD 对应的数据只含有一个学科的数据
val filtered = reduced.filter(_._1._1 == sub)
// 用的是RDD的sortBy方法,take是action任务,对于每个学科都会触发任务提交
val sorted = filtered.sortBy(_._2, false).take(3)
println(sorted.toBuffer)
}
}
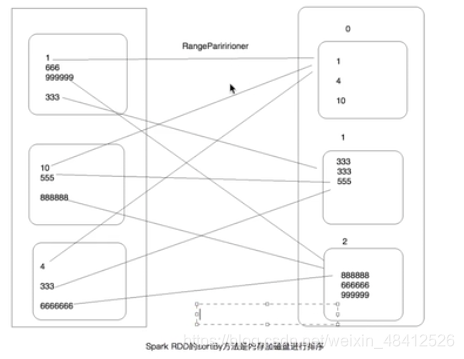
}关于RDD的sortBy:
如下图所示:首先是通过RangePartition,将数据分区,如 0-300, 300-600, 6000以上, 然后把数据分别分到相应的数据块中。在每个小数据块中排序。
自定义分区器
使用group by 进行分组排序的时候,多个学科的数据可能到一个分区中来。现在想要把同学科的数据都放到同一个分区内,使得每个分区都有且仅有一个学科中的数据
-》实现方式:自定义spark 分区器,让数据在shuffle的时候,按照自定义的规则进行分区,把同一学科的数据都搞到同一分区中。
-》在自定义分区器中制定规则,传进来一个学科名字key,返回一个分区编号
缺点:
- 在对每个分区的数据进行排序的时候,还是要把整个分区内的数据读到内存里面来。如果一个学科下对应的数据过多,依然有内存溢出的风险
- shuffle次数过多 (reduceByKey 需要一次shuffle, partitionBy 也需要一次shuffle)
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.mutable
/*
自定义分区器
*/
class SubjectPartitioner(sbs: Array[String]) extends Partitioner {
// 相当于主构造器(只有在new SubjectPartitioner 的时候会执行一次)
// 用于存放规则的一个map
val rules = new mutable.HashMap[String, Int]()
var i = 0
// 传进来一个学科,就给学科一个编号。rules中, key 为学科, value为编号
for( sb <- sbs) {
rules.put(sb,i)
i = i+1
}
// 返回分区数量(下一个RDD有多少个分区)
override def numPartitions: Int = sbs.length
// 根据传入的key计算分区编号
// key 是一个元组(String,String)
override def getPartition(key: Any): Int = {
// 获取学科名称 传进来的key是reduce的样式((subject, teacher), num)
val subject = key.asInstanceOf[(String, String)]._1
// 根据规则计算分区编号
rules(subject)
}
}
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据
val test_data = Array("http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhao",
"http://javaee.edu365.cn/laozhuan",
"http://javaee.edu365.cn/laozhuan")
val data = sc.parallelize(test_data)
// 从数据源中提取出subject和teacher,然后以(subject,teacher)为主键来统计个数
val subjectTeacherAndOne: RDD[((String, String), Int)] = data.map(line => {
val teacher = line.split('/').last
val subject = line.split('/')(2).split('.')(0)
//println(s"(($subject,$teacher),1)")
((subject,teacher),1)
})
// 统计每个老师在每个学科下出现的次数
val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey((x,y) => x+y)
println("----------------reduced----------------")
reduced.collect().foreach(println)
/*
----------------reduced----------------
((bigdata,laozhang),7)
((javaee,laozhuan),2)
((bigdata,laozhao),3)
((javaee,laozhao),1)
((bigdata,laoduan),2)
((javaee,laozhang),2)
*/
// 统计有多少学科
val subjects: Array[String] = reduced.map(line => line._1._1).distinct().collect()
// 自定义一个分区器,并且按照指定的分区器进行分区
val sbPartitioner = new SubjectPartitioner(subjects);
// partitionBy 按照指定的分区规则进行分区
// 调用partitionBy的时候,RDD的Key 是(String, String)
// 在shuffle之前,对reduced中的每条数据,都调用partitionBy方法,计算其未来分区的编号
val partitioned: RDD[((String, String), Int)] = reduced.partitionBy(sbPartitioner)
/*
----------------partitioned----------------
((bigdata,laozhang),7)
((javaee,laozhuan),2)
((bigdata,laozhao),3)
((javaee,laozhao),1)
((bigdata,laoduan),2)
((javaee,laozhang),2)
*/
// partition 中已经做到,一个分区中有且只有一个学科
// 现在遍历每个分区,拿出其中的数据进行排序
val sorted = partitioned.mapPartitions(it => {
//将迭代器转换成list,然后排序,然后再转换成迭代器返回
it.toList.sortBy(_._2).reverse.take(3).iterator
})
println("----------------sorted----------------")
sorted.collect().foreach(println)
/*
----------------sorted----------------
((javaee,laozhang),2)
((javaee,laozhuan),2)
((javaee,laozhao),1)
((bigdata,laozhang),7)
((bigdata,laozhao),3)
((bigdata,laoduan),2)
*/
print("hhhhhh")
}
}自定义分区器
为了减少shuffle次数, 在执行reduceByKey的时候,用自定义的分区器来代替默认分区器。
使得整个过程只要一次shuffle
mapPartitions, 在调用mapPartitions方法定义一个可排序的集合
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.mutable
class SubjectPartitioner(sbs: Array[String]) extends Partitioner {
// 相当于主构造器(new 的时候会执行一次)
// 用于存放规则的一个map
val rules = new mutable.HashMap[String, Int]()
var i = 0
// 传进来一个学科,就给学科一个编号。rules中, key 为学科, value为编号
for( sb <- sbs) {
rules.put(sb,i)
i = i+1
}
// 返回分区数量(下一个RDD有多少个分区)
override def numPartitions: Int = sbs.length
// 根据传入的key计算分区编号
// key 是一个元组(String,String)
override def getPartition(key: Any): Int = {
// 获取学科名称 传进来的key是reduce的样式((subject, teacher), num)
val subject = key.asInstanceOf[(String, String)]._1
// 根据规则计算分区编号
rules(subject)
}
}
object Test {
def main(args: Array[String]) {
// local[3] 代表一个进程起3个线程
val conf = new SparkConf().setAppName("applicationName").setMaster("local[1]").set("spark.testing.memory", "2147480000") // 本地环境运行
// 创建spark执行的入口
val sc = new SparkContext(conf)
// 读取数据
val test_data = Array("http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laoduan",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhang",
"http://bigdata.edu365.cn/laozhao",
"http://bigdata.edu365.cn/laozhang",
"http://javaee.edu365.cn/laozhao",
"http://javaee.edu365.cn/laozhuan",
"http://javaee.edu365.cn/laozhuan")
val data = sc.parallelize(test_data)
// 从数据源中提取出subject和teacher,然后以(subject,teacher)为主键来统计个数
val subjectTeacherAndOne: RDD[((String, String), Int)] = data.map(line => {
val teacher = line.split('/').last
val subject = line.split('/')(2).split('.')(0)
//println(s"(($subject,$teacher),1)")
((subject,teacher),1)
})
// 统计有多少学科
val subjects: Array[String] = subjectTeacherAndOne.map(line => line._1._1).distinct().collect()
println("----------------subjects----------------")
subjects.foreach(println)
/*
----------------subjects----------------
javaee
bigdata
*/
// 自定义一个分区器,并且按照指定的分区器进行分区
val sbPartitioner = new SubjectPartitioner(subjects);
// reduceByKey 会触发shuffle,并且调用默认的哈希分区器进行分区,将key相同的分到一起。
// 可以在reduceByKey中传入自定义的分区器,使得RDD一个分区内有且只有一个学科的数据,
val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey(sbPartitioner,_+_)
println("----------------reduced----------------")
reduced.collect().foreach(println)
/*
----------------reduced----------------
((javaee,laozhuan),2)
((javaee,laozhao),1)
((javaee,laozhang),2)
((bigdata,laozhang),7)
((bigdata,laozhao),3)
((bigdata,laoduan),2)
*/
// 现在遍历每个分区,拿出其中的数据进行排序
val sorted = reduced.mapPartitions(it => {
//将迭代器转换成list,然后排序,然后再转换成迭代器返回
//it.toList.sortBy(_._2).reverse.take(3).iterator
// 如果只要返回某个学科最受欢迎的头部5个老师,那么只需要建立一个自排序的长度为5的stack
})
println("----------------sorted----------------")
sorted.collect().foreach(println)
/*
----------------sorted----------------
((javaee,laozhang),2)
((javaee,laozhuan),2)
((javaee,laozhao),1)
((bigdata,laozhang),7)
((bigdata,laozhao),3)
((bigdata,laoduan),2)
*/
print("hhhhhh")
}
}
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









