







 本文介绍了预训练语言模型在NLP领域的应用,探讨了它们是否能学习到知识以及如何作为知识库使用。研究发现,预训练模型如BERT通过自监督学习确实能捕获部分事实和常识知识,但其知识获取能力受限于提示语的设计。尽管有潜力,目前预训练模型尚不能完全替代知识库。
本文介绍了预训练语言模型在NLP领域的应用,探讨了它们是否能学习到知识以及如何作为知识库使用。研究发现,预训练模型如BERT通过自监督学习确实能捕获部分事实和常识知识,但其知识获取能力受限于提示语的设计。尽管有潜力,目前预训练模型尚不能完全替代知识库。
引言
近年来,预训练语言模型在NLP领域展现出了强大的能力而被广泛采用,成为了解决NLP问题的“银弹”。借助大规模数据集、以Transformer为代表的深度神经网络模型、以及设计好的自监督预训练(pre-train)任务,预训练语言模型展现出了强大的泛化能力,经过微调(fine-tune)后在各个下游任务中得到了优秀的成果,其强大性能让人对其学习到的内容产生了兴趣:预训练语言模型是否真的在预训练过程中学习到了“知识”呢?
最近也有工作提出了prompt范式,通过构建的prompt语句,将特定的下游任务转换为预训练语言模型的预训练任务(如Mask Language Model)从而得到结果,这种形式有点类似于从知识库中使用一定的查询语句找出对应的答案。因此,有研究者开始探索是否能将预训练语言模型作为“知识库”使用。本文针对自然语言处理中的预训练语言模型如何通过预训练建模“知识”、推导知识,以及预训练语言模型是否能作为知识库这三方面进行了简单的论文导读。
预训练语言模型简述
预训练语言模型的其实可以追溯到静态词向量的研究。从最初的One-Hot向量、词袋模型、tf-idf到后来的Word2Vec[1]、FastText[2,3]等方法,研究者通过建模token的统计概率信息,或者上下文的统计概率信息来对语言进行统计学建模。
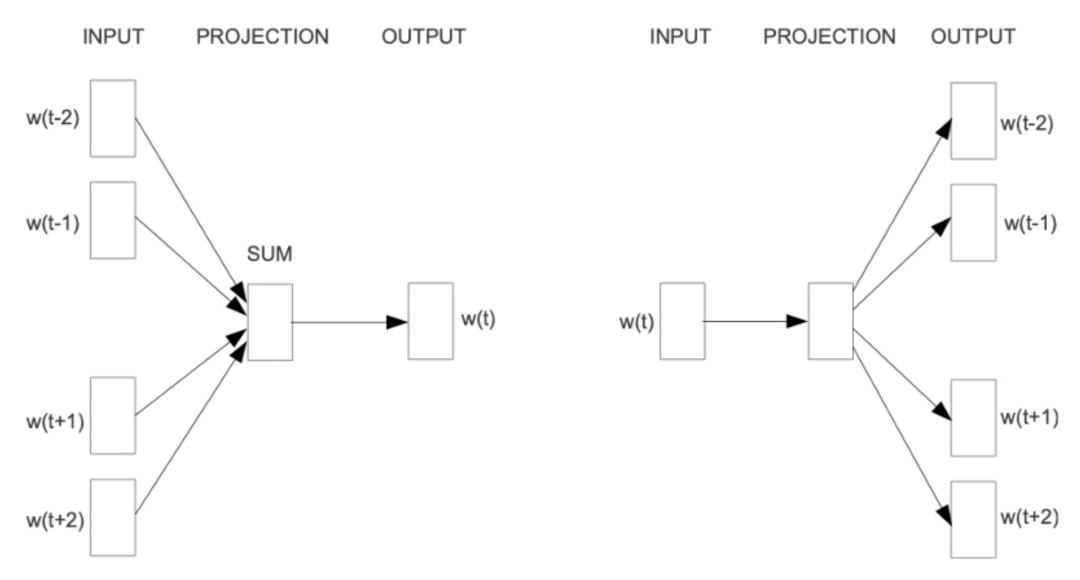
例如,上图为word2vec提出的两种经典方法CBOW与Skip-gram,它们分别通过“使用周围的词来预测中心词”以及“使用中心词来预测周围的词”这两种方法,使用滑动窗口的方法对窗口大小长度的序列进行上下文建模,最终在训练过程中通过梯度下降的方法优化句子中每个词的词嵌入(embedding)。相比于最初的One-Hot向量表示、词袋模型、tf-idf等传统统计学方法,word2vec等静态词向量方法能够更好地考虑到词的上下文语义信息,同时可以减少传统方法遇到的维度灾难问题。但是,这种静态的词嵌入表示方法也有不少的缺点,最典型的问题是词与词嵌入是一对一的表示,无法正确表示在不同上下文中出现的一词多义信息,即便到了后来研究者提出了一些效果更好的模型(Glove[4])也没能解决这种静态词向量的固有问题。
为了解决上述静态词嵌入表示的问题,研究者提出了基于语言模型嵌入(Embedding from LanguageModels, ELMo)的方法[5],使用长短时记忆神经网络(LSTM)分别对文本的正向和反向进行语言模型建模:
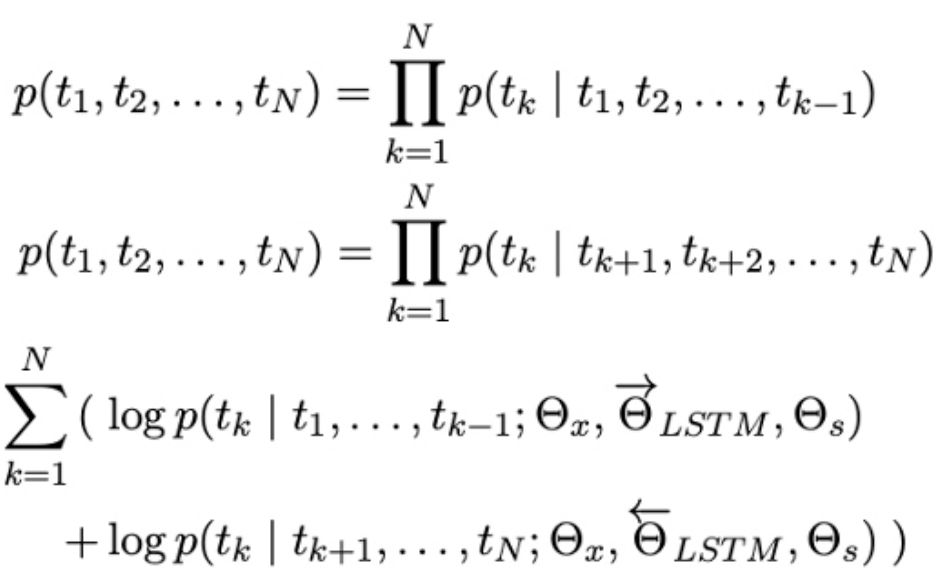
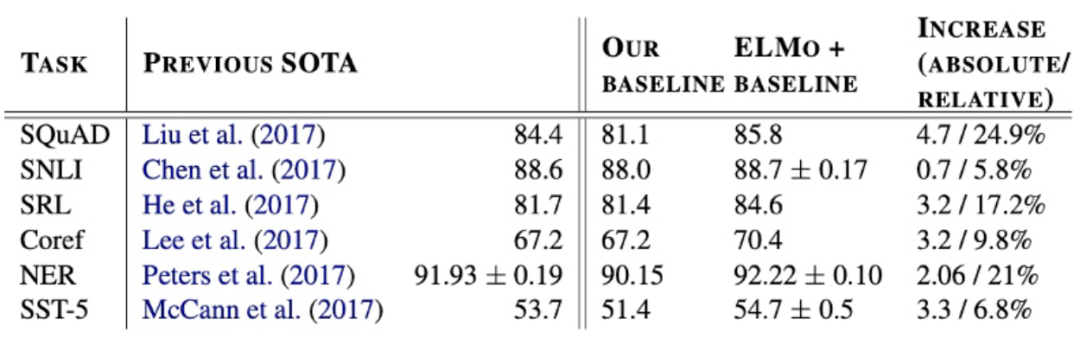
通过语言模型任务进行预训练后,迁移到其它NLP任务中进行微调,在多个benchmark数据集上都得到了显著的提升:
同时,作者也通过实验对ELMo的消岐能力进行了分析,发现ELMo能够有效地区分多义词。自此以ELMo为代表的各种预训练语言模型开始不断出现,并不断提升各个NLP子任务的效果。
2017年Google提出了用于机器翻译任务的Transformer[6],Transformer基于多头自注意力机制实现,解决了之前LSTM类型模型无法很好处理长距依赖的问题并且更易于进行并行运算,在预训练语言模型领域也展现出了强大的能力,之后的预训练语言模型代表作BERT[7]、GPT[8]均是基于Transformer模型构建的。
Google于2018提出的BERT是预训练语言模型的经典之作。BERT由多层Transformer Encoder模块堆叠构成,作者为其设置了两种预训练任务:Masked Language Model(MLM)与Next Sentence Prediction(NSP),采用两阶段预训练-微调范式,如下图所示:
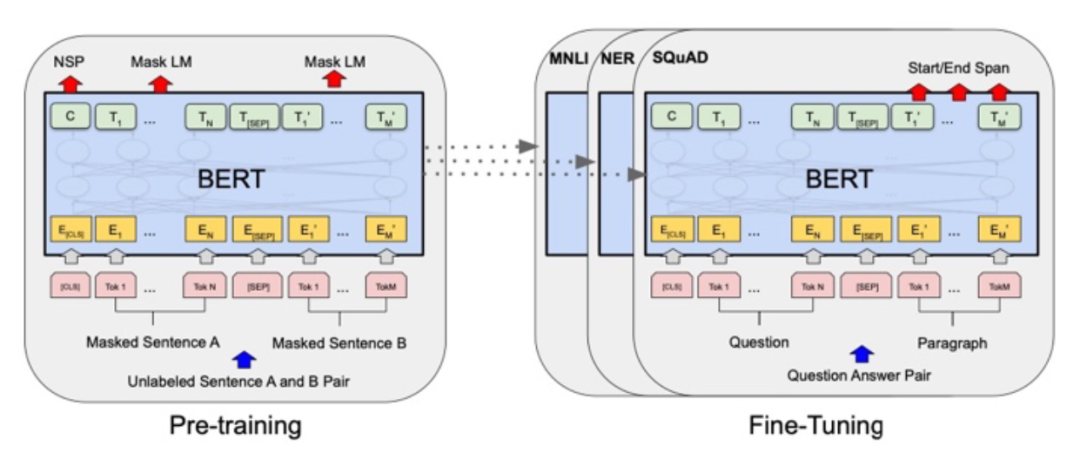
其中,MLM来自于完形填空任务(Cloze),将一句完整的话中间的某些token抹去,让模型通过上下文来还原该token;NSP为句子对匹配任务,将两个句子拼接后传入模型中,让模型判断这两个句子是否在原语料中为连续关系。得益于这两个预训练任务,BERT在token层面与sentence层面都能通过大规模的无标注语料进行自监督训练,从而获得优秀的预训练模型参数,在迁移至下游NLP任务微调时,可以取得非常好的效果。
在BERT的基础上,研究者们对预训练语言模型的可能性进行了进一步的探索:有使用更大的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









