






作为当前主流的架构,transformer的应用非常广泛。
手搓transformer就可以让我们对该架构有着比较清晰的认知,去了解内部是如何运行的,而且在面试中能够更好的应对相关方面的提问。
本文将深入浅出的根据《All Attention is your need》论文中的配图为指导,一步一步地去剖析transformer模块是如何搭建起来的。
本文最后提供的代码是可运行的,如果有对流程不懂的地方可以直接复制到vscode调试一步步查看模型是如何运行的。
由于本文是代码实现,具体逻辑思路可以详见下面这篇文章,讲的非常详细:
https://zhuanlan.zhihu.com/p/338817680
整体框架
下图是transformer模块的总览图:
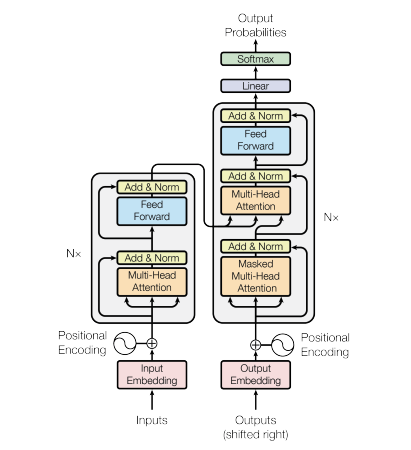
首先,对这个整体框架进行拆分,它大致是可以分为:
1.对输入输出的预处理(包含将词转换为emb的操作与加上位置信息pos_encode操作)
2.编码器 与 解码器 (图中的左右两侧*N的部分,左边为编码器,右边为解码器)
3.最后经过一个线性层,最后的头是随便添加的比如分类头,但是我们这里就不做讨论了
class Transformer(nn.Module):
def __init__(self,input_vocab_size,output_vocab_size,d_men,num_layers):
super().__init__()
# 将输入对应转换成d_men
self.input_emb = nn.Embedding(input_vocab_size,d_men)
self.output_emb = nn.Embedding(output_vocab_size,d_men)
#创建编码器与解码器
self.encode = nn.ModuleList([encodelayer() for _ in range(num_layers)])
self.decode = nn.ModuleList([decodelayer() for _ in range(num_layers)])
#最后的线性层
self.final_layer = nn.Linear(d_men,output_vocab_size)
def forward(self,src,tgt):
#对应转换emb
src = self.input_emb(src)
tgt = self.output_emb(tgt)
#编码与解码
for layer in self.encode:
layer(src)
for layer in self.decode:
layer(tgt,src)
#最后过线性层
tgt = self.final_layer(tgt)
return tgt这里由于我们是自顶向下去写的,所以有些传入的参数尚未定义,在后面有需要的话,会再在这里进行更新,此外,为了代码更加简洁明了,在这里书写过程中,省略了位置编码与加mask的相关操作。
这里先对emb操作进行解释,比如输入是i am a boy 形状为[4,]
这里就会有四个词,每个词经过emb之后就会有d_men的特征去表示它,形状变成[4,d_men]
在这里的src,tgt的形状就会从原先的 [batch,sql_len] 变成 [batch,sql_len,d_men]
编码层与解码层
然后就是看编码层与解码层
在这两层中,对应名称的模块都是相同的,为了代码的不重复性,我们在这里将相同的模块提取出来作为一个类进行书写,在这里有feedforward层与Multi-Head Attention层
所以在编码层与解码层的书写中就不具体写着两个模块了
首先观察编码层,它以src作为输入,经过多头注意力,归一化残差连接,前馈层,归一化残差连接,最后得到输出
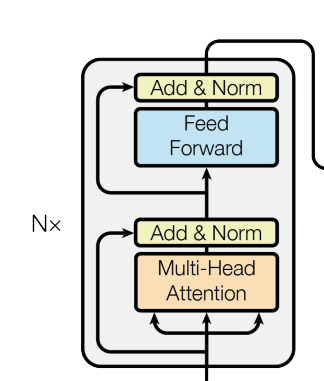
class encodelayer(nn.Module):
def __init__():
super().__init__()
self.atten = MultiHeadAttention()
self.ln1 = nn.LayerNorm(d_men)
self.ffn = FeedForward()
self.ln2 = nn.LayerNorm(d_men)
def forward(self,x):
#这里是自注意力
x = x + self.atten(x,x,x)
x = self.ln1(x)
x = x+ self.ffn(x)
x = self.ln2(x)
return x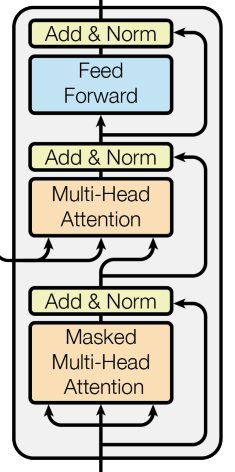
class decodelayer(nn.Module):
def __init__(self):
super().__init__()
self.atten = MultiHeadAttention()
self.ln1 = nn.LayerNorm(d_men)
self.ln2 = nn.LayerNorm(d_men)
self.ffn = FeedForward()
self.ln3 = nn.LayerNorm(d_men)
def forward(self,encode_output,tgt):
#自注意力
tgt = tgt + self.atten(tgt,tgt,tgt)
tgt = self.ln1(tgt)
#交叉注意力
tgt = tgt + self.atten(tgt,encode_output,encode_output)
tgt = self.ln2(tgt)
tgt = x + self.ffn(tgt)
return self.ln3(tgt)
同样的,上面的代码都是依据图中的结构去初始化相应模块,然后在forward层中去依次通过这些模块,并且这里的初始化由于还没定义参数就先没写,在后面写完后会补上
前馈层与多头注意力层
然后就是写FeedForward模块跟MultiHeadAttention模块:
首先是简单的FeedForward模块,结构如下,输入输出都是d_men,中间层的大小需要定义
class FeedForward(nn.Module):
def __init__(self,d_men,hidden_dim=2048):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_men,hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim,d_men)
)
def forward(self,x):
return self.net(x) 所以上面的self.ffn = FeedForward(d_men,hidden_dim)之后需要注意前面还需要传入一个hidden_dim的参数用来初始化前馈层
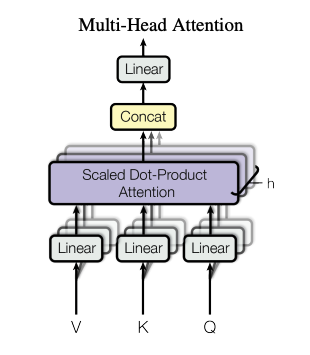
然后实现上面的多头注意力层,这里注意参数的维度的变化
q,k,v进行attention前的前置准备:
先做一次linear操作:[batch_size,sql_len,d_men]->[batch_size,sql_len,d_men]
然后把[batch_size,sql_len,d_men]转化成多头,相当于将d_men分为heads份
变成[batch_size,sql_len,heads,d_k]
然后进行多头的矩阵乘法,需要需要换一下位置[batch_size,heads,sql_len,d_k]
然后做attention ,最后还需要将分头后的维度恢复成原先的维度
class MultiHeadAttention(nn.Module):
def __init__(self,d_men,heads):
super().__init__()
#先为多头做准备
assert d_men % heads == 0
self.d_k = d_men // heads
self.heads = heads
#这里初始化了四个Linear层,分别是qkv跟最后的linear
self.linears = nn.ModuleList([nn.Linear(d_men,d_men)for _ in range(4)])
def forward(self,q,k,v):
batch_size = q.size(0)
q,k,v = [
#先做一次linear操作:[batch_size,sql_len,d_men]->[batch_size,sql_len,d_men]
#然后把[batch_size,sql_len,d_men]转化成多头,相当于将d_men分为heads份
#变成[batch_size,sql_len,heads,d_k]
#然后进行多头的矩阵乘法,需要需要换一下位置[batch_size,heads,sql_len,d_k]
lin(x).view(batch_size,-1,heads,self.d_k).transpose(1,2)
for lin,x in zip(self.linears,(q,k,v))
]
#在这里做注意力,这个写在外面作为一个函数实现
x = attention(q,k,v)
#在这里把[batch_size,heads,sql_len,d_k]->[batch_size,heads,sql_len,d_k]->[batch_size,sql_len,d_men]
x = x.transpose(1,2).contiguous().view(batch_size,-1,self.heads*self.d_k)
#最后过一次Linear
return self.linears[-1](x)
最后再实现一些Attetion函数操作
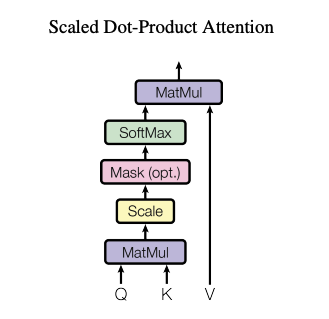
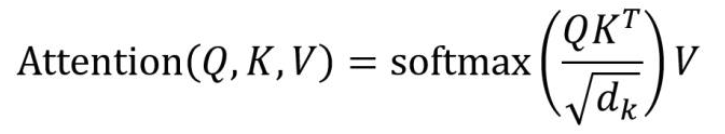
它要实现的就是完成qkv的操作
def attention(q,k,v):
d_k = q.size(-1)
#这里实现了括号里的操作,得到一个相似度矩阵
x = torch.matmul(q,k.transpose(-2,-1))/math.sqrt(d_k)
#转化为[0,1]的相似度矩阵
x = F.softmax(x,dim=-1)
return torch.matmul(x,v)至此,就完成了全部的模块,最后将原先未传入的参数一一传入
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
def attention(q,k,v):
d_k = q.size(-1)
#这里实现了括号里的操作,得到一个相似度矩阵
x = torch.matmul(q,k.transpose(-2,-1))/math.sqrt(d_k)
#转化为[0,1]的相似度矩阵
x = F.softmax(x,dim=-1)
return torch.matmul(x,v)
class MultiHeadAttention(nn.Module):
def __init__(self,d_men,heads):
super().__init__()
#先为多头做准备
assert d_men % heads == 0
self.d_k = d_men // heads
self.heads = heads
#这里初始化了四个Linear层,分别是qkv跟最后的linear
self.linears = nn.ModuleList([nn.Linear(d_men,d_men)for _ in range(4)])
def forward(self,q,k,v):
batch_size = q.size(0)
q,k,v = [
#先做一次linear操作:[batch_size,sql_len,d_men]->[batch_size,sql_len,d_men]
#然后把[batch_size,sql_len,d_men]转化成多头,相当于将d_men分为heads份
#变成[batch_size,sql_len,heads,d_k]
#然后进行多头的矩阵乘法,需要需要换一下位置[batch_size,heads,sql_len,d_k]
lin(x).view(batch_size,-1,heads,self.d_k).transpose(1,2)
for lin,x in zip(self.linears,(q,k,v))
]
#在这里做注意力,这个写在外面作为一个函数实现
x = attention(q,k,v)
#在这里把[batch_size,heads,sql_len,d_k]->[batch_size,heads,sql_len,d_k]->[batch_size,sql_len,d_men]
x = x.transpose(1,2).contiguous().view(batch_size,-1,self.heads*self.d_k)
#最后过一次Linear
return self.linears[-1](x)
class FeedForward(nn.Module):
def __init__(self,d_men,hidden_dim=2048):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_men,hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim,d_men)
)
def forward(self,x):
return self.net(x)
class encodelayer(nn.Module):
def __init__(self,d_men,heads,hidden_dim):
super().__init__()
self.atten = MultiHeadAttention(d_men,heads)
self.ln1 = nn.LayerNorm(d_men)
self.ffn = FeedForward(d_men,hidden_dim)
self.ln2 = nn.LayerNorm(d_men)
def forward(self,x):
#这里是自注意力
x = x + self.atten(x,x,x)
x = self.ln1(x)
x = x+ self.ffn(x)
x = self.ln2(x)
return x
class decodelayer(nn.Module):
def __init__(self,d_men,heads,hidden_dim):
super().__init__()
self.atten = MultiHeadAttention(d_men,heads)
self.ln1 = nn.LayerNorm(d_men)
self.ln2 = nn.LayerNorm(d_men)
self.ffn = FeedForward(d_men,hidden_dim)
self.ln3 = nn.LayerNorm(d_men)
def forward(self,encode_output,tgt):
#自注意力
tgt = tgt + self.atten(tgt,tgt,tgt)
tgt = self.ln1(tgt)
#交叉注意力
tgt = tgt + self.atten(tgt,encode_output,encode_output)
tgt = self.ln2(tgt)
tgt = tgt + self.ffn(tgt)
return self.ln3(tgt)
class Transformer(nn.Module):
def __init__(self,d_men,heads,num_layers,input_vocab_size,output_vocab_size,hidden_dim=2048):
super().__init__()
# 将输入对应转换成d_men
self.input_emb = nn.Embedding(input_vocab_size,d_men)
self.output_emb = nn.Embedding(output_vocab_size,d_men)
#创建编码器与解码器
self.encode = nn.ModuleList([encodelayer(d_men,heads,hidden_dim) for _ in range(num_layers)])
self.decode = nn.ModuleList([decodelayer(d_men,heads,hidden_dim) for _ in range(num_layers)])
#最后的线性层
self.final_layer = nn.Linear(d_men,output_vocab_size)
def forward(self,src,tgt):
#对应转换emb
src = self.input_emb(src)
tgt = self.output_emb(tgt)
#编码与解码
for layer in self.encode:
layer(src)
for layer in self.decode:
layer(tgt,src)
#最后过线性层
tgt = self.final_layer(tgt)
return tgt
d_men = 512
heads = 8
num_layers = 6
input_vocab_size = 1000
output_vocab_size = 1000
model = Transformer(d_men,heads,num_layers,input_vocab_size,output_vocab_size)
src = torch.randint(0, input_vocab_size, (32, 20)) # batch_size=32, seq_len=20
tgt = torch.randint(0, output_vocab_size, (32, 20))
output = model(src, tgt)
print(output.shape) 最后成功输出结果:
![]()

















 2326
2326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









